Questa pagina spiega come eseguire query sui dati e scrivere i risultati delle query con SQL di Dataflow.
Dataflow SQL può eseguire query sulle seguenti origini:
- Flusso di dati di argomenti Pub/Sub
- Flusso di dati e batch di set di file di Cloud Storage
- Dati batch da tabelle BigQuery
Dataflow SQL può scrivere risultati di query nelle seguenti destinazioni:
Pub/Sub
Esecuzione di query su argomenti Pub/Sub
Per eseguire una query su un argomento Pub/Sub con Dataflow SQL, completa i seguenti passaggi:
Aggiungi l'argomento Pub/Sub come origine Dataflow.
Assegna uno schema all'argomento Pub/Sub.
Utilizza l'argomento Pub/Sub in una query SQL Dataflow.
Aggiunta di un argomento Pub/Sub
Puoi aggiungere un argomento Pub/Sub come origine Dataflow utilizzando l'interfaccia utente web di BigQuery.
In Google Cloud Console, vai alla pagina BigQuery, dove puoi utilizzare Dataflow SQL.
Nel pannello di navigazione, fai clic sull'elenco a discesa Aggiungi dati e seleziona Origini Cloud Dataflow.

Nel riquadro Aggiungi origine Cloud Dataflow, seleziona Argomenti Cloud Pub/Sub e cerca l'argomento.
Il seguente screenshot mostra una ricerca dell'argomento
transactionsPub/Sub: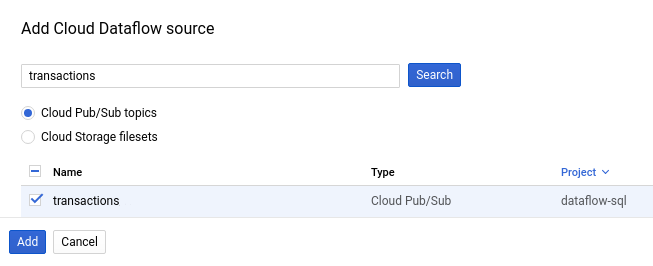
Fai clic su Aggiungi.
Dopo aver aggiunto l'argomento Pub/Sub come origine Dataflow, l'argomento Pub/Sub viene visualizzato nella sezione Risorse del menu di navigazione.
Per trovare l'argomento, espandi Origini Cloud Dataflow > Argomenti Cloud Pub/Sub.
Assegnazione di uno schema di argomento Pub/Sub
Gli schemi di argomenti Pub/Sub sono i seguenti:
Un campo
event_timestamp.I timestamp eventi Pub/Sub identificano quando i messaggi vengono pubblicati. I timestamp vengono aggiunti automaticamente ai messaggi Pub/Sub.
Un campo per ogni coppia chiave-valore nei messaggi Pub/Sub.
Ad esempio, lo schema per il messaggio
{"k1":"v1", "k2":"v2"}include due campiSTRING, chiamatik1ek2.
Puoi assegnare uno schema a un argomento Pub/Sub utilizzando Cloud Console o l'interfaccia a riga di comando di Google Cloud.
Console
Per assegnare uno schema a un argomento Pub/Sub, completa i seguenti passaggi:
Seleziona l'argomento nel riquadro Risorse.
Nella scheda Schema, fai clic su Modifica schema per aprire il riquadro laterale Schema che mostra i campi dello schema.
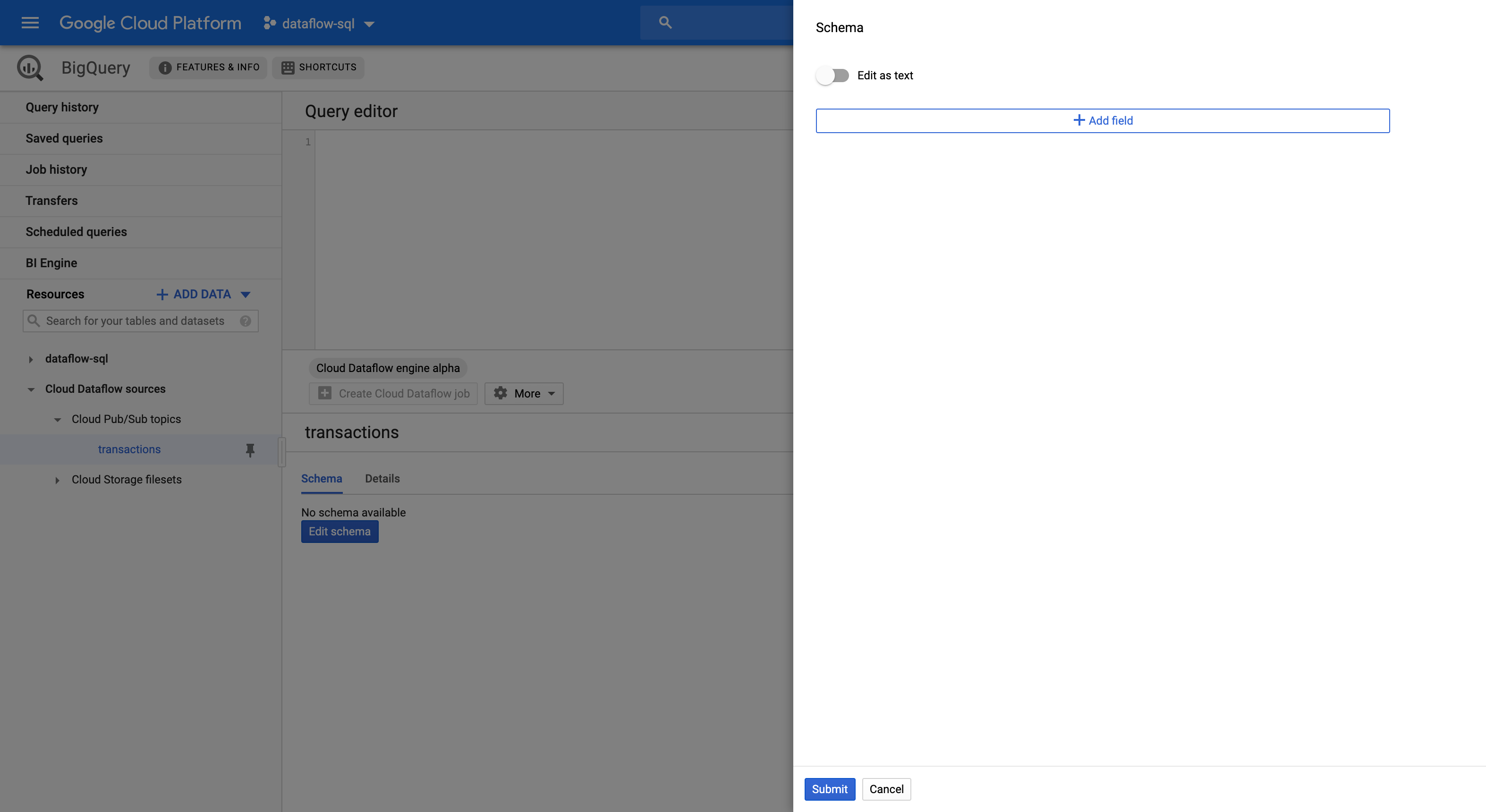
Fai clic su Aggiungi campo per aggiungere un campo allo schema o attivare il pulsante Modifica come testo per copiare e incollare l'intero testo dello schema.
Ad esempio, di seguito è riportato il testo dello schema per un argomento Pub/Sub con transazioni di vendita:
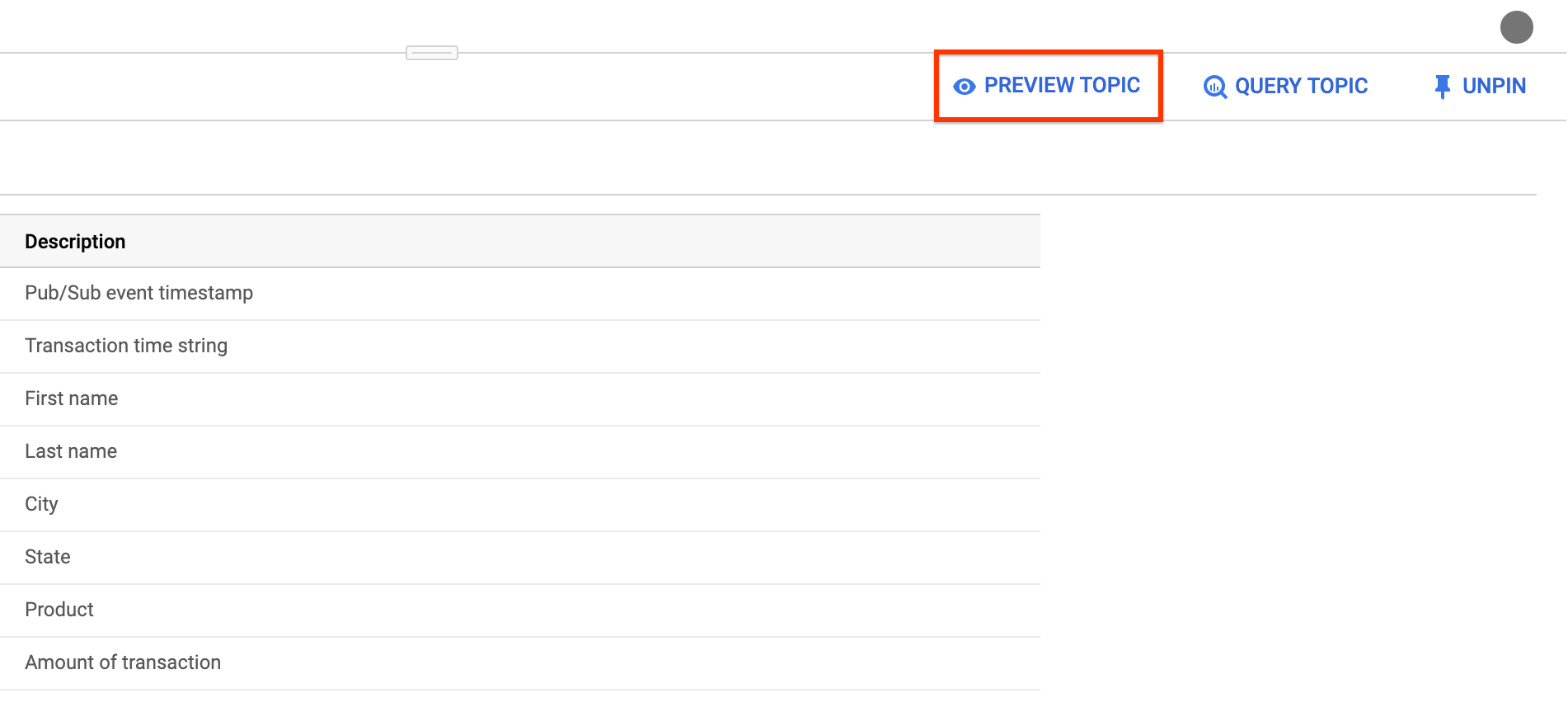
[ { "description": "Pub/Sub event timestamp", "name": "event_timestamp", "mode": "REQUIRED", "type": "TIMESTAMP" }, { "description": "Transaction time string", "name": "tr_time_str", "mode": "NULLABLE", "type": "STRING" }, { "description": "First name", "name": "first_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "Last name", "name": "last_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "City", "name": "city", "mode": "NULLABLE", "type": "STRING" }, { "description": "State", "name": "state", "mode": "NULLABLE", "type": "STRING" }, { "description": "Product", "name": "product", "mode": "NULLABLE", "type": "STRING" }, { "description": "Amount of transaction", "name": "amount", "mode": "NULLABLE", "type": "FLOAT64" } ]Fai clic su Invia.
(Facoltativo) Fai clic su Anteprima argomento per esaminare i contenuti dei messaggi e confermare che corrispondano allo schema definito.
gcloud
Per assegnare uno schema a un argomento Pub/Sub, completa i seguenti passaggi:
Crea un file JSON con il testo dello schema.
Ad esempio, di seguito è riportato il testo dello schema per un argomento Pub/Sub con transazioni di vendita:
[ { "description": "Pub/Sub event timestamp", "column": "event_timestamp", "mode": "REQUIRED", "type": "TIMESTAMP" }, { "description": "Transaction time string", "column": "tr_time_str", "mode": "NULLABLE", "type": "STRING" }, { "description": "First name", "column": "first_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "Last name", "column": "last_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "City", "column": "city", "mode": "NULLABLE", "type": "STRING" }, { "description": "State", "column": "state", "mode": "NULLABLE", "type": "STRING" }, { "description": "Product", "column": "product", "mode": "NULLABLE", "type": "STRING" }, { "description": "Amount of transaction", "column": "amount", "mode": "NULLABLE", "type": "FLOAT64" } ]Assegna lo schema all'argomento Pub/Sub utilizzando il comando
gcloud data-catalog entries:gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`' \ --schema-from-file=FILE_PATH
Sostituisci quanto segue:
PROJECT_ID: ID progettoTOPIC_NAME: nome dell'argomento Pub/SubFILE_PATH: percorso del file JSON con il testo dello schema
(Facoltativo) Verifica che lo schema sia assegnato correttamente all'argomento Pub/Sub eseguendo questo comando:
gcloud data-catalog entries lookup \ 'pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`'
Utilizzo di un argomento Pub/Sub
Per fare riferimento a un elemento Pub/Sub in una query SQL di Dataflow, utilizza i seguenti identificatori:
pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`
Sostituisci quanto segue:
PROJECT_ID: ID progettoTOPIC_NAME: nome dell'argomento Pub/Sub
Ad esempio, la seguente query seleziona dall'argomento Dataflow
daily.transactions nel progetto dataflow-sql:
SELECT *
FROM pubsub.topic.`dataflow-sql`.`daily.transactions`
Scrittura su argomenti Pub/Sub
Puoi scrivere risultati di query in un argomento Pub/Sub utilizzando Cloud Console o l'interfaccia a riga di comando di Google Cloud.
Console
Per scrivere i risultati della query in un argomento Pub/Sub, esegui la query con Dataflow SQL:
In Cloud Console, vai alla pagina BigQuery, dove puoi utilizzare Dataflow SQL.
Inserisci la query SQL Dataflow nell'editor delle query.
Fai clic su Crea job Cloud Dataflow per aprire un riquadro di opzioni di job.
Nella sezione Destinazione del riquadro, seleziona Tipo di output > Argomento Cloud Pub/Sub.
Fai clic su Seleziona un argomento Cloud Pub/Sub e scegli un argomento.
Fai clic su Crea.
gcloud
Per scrivere i risultati della query in un argomento Pub/Sub, utilizza il flag
--pubsub-topic del comando
gcloud dataflow sql query:
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --pubsub-project=PROJECT_ID \ --pubsub-topic=TOPIC_NAME \ 'QUERY'
Sostituisci quanto segue:
JOB_NAME: un nome per il lavoro a tua scelta.REGION: endpoint a livello di area geografica (ad esempious-west1)PROJECT_ID: ID progettoTOPIC_NAME: nome dell'argomento Pub/SubQUERY: la query SQL Dataflow
Lo schema degli argomenti Pub/Sub di destinazione deve corrispondere allo schema dei risultati della query. Se un argomento Pub/Sub di destinazione non ha uno schema, viene assegnato automaticamente uno schema corrispondente ai risultati della query.
Cloud Storage
Query dei set di file di Cloud Storage
Per eseguire una query su un set di file Cloud Storage con Dataflow SQL, completa i seguenti passaggi:
Crea un set di file Data Catalog per Dataflow SQL.
Aggiungi il set di file Cloud Storage come origine Dataflow.
Utilizza il set di file Cloud Storage in una query SQL Dataflow.
Creazione dei set di file di Cloud Storage
Per creare un set di file Cloud Storage, consulta Creazione di gruppi di file e set di file.
Il set di file Cloud Storage deve avere uno schema e contenere solo file CSV senza righe di intestazione.
Aggiunta di set di file Cloud Storage
Puoi aggiungere un set di file Cloud Storage come origine Dataflow utilizzando Dataflow SQL:
In Cloud Console, vai alla pagina BigQuery, dove puoi utilizzare Dataflow SQL.
Nel pannello di navigazione, fai clic sull'elenco a discesa Aggiungi dati e seleziona Origini Cloud Dataflow.
Nel riquadro Aggiungi origine Cloud Dataflow, seleziona i set di file Cloud Storage e cerca l'argomento.
Fai clic su Aggiungi.
Dopo aver aggiunto il set di file Cloud Storage come origine di Dataflow, il set di file Cloud Storage viene visualizzato nella sezione Risorse del menu di navigazione.
Per trovare il set di file, espandi le origini Cloud Dataflow egt; argomenti Cloud Storage.
Utilizzo di un set di file Cloud Storage
Per fare riferimento a una tabella Cloud Storage in una query SQL Dataflow, utilizza i seguenti identificatori:
datacatalog.entry.`PROJECT_ID`.REGION.`ENTRY_GROUP`.`FILESET_NAME`
Sostituisci quanto segue:
PROJECT_ID: ID progettoREGION: endpoint a livello di area geografica (ad esempious-west1)ENTRY_GROUP: il gruppo di voci del set di file Cloud StorageFILESET_NAME: il nome del set di file Cloud Storage
Ad esempio, la seguente query seleziona dal set di file Cloud Storage
daily.registrations nel progetto dataflow-sql e nel gruppo di voci my-fileset-group:
SELECT *
FROM datacatalog.entry.`dataflow-sql`.`us-central1`.`my-fileset-group`.`daily.registrations`
BigQuery
Esecuzione di query sulle tabelle BigQuery
Per eseguire una query su una tabella BigQuery con Dataflow SQL, completa i seguenti passaggi:
Crea una tabella BigQuery per Dataflow SQL.
Utilizza la tabella BigQuery in una query SQL Dataflow.
Non è necessario aggiungere una tabella BigQuery come origine dati Dataflow.
Creazione di una tabella BigQuery
Per creare una tabella BigQuery per SQL SQL, consulta Creazione di una tabella vuota con definizione di schema.
Utilizzo di una tabella BigQuery in una query
Per fare riferimento a una tabella BigQuery in una query SQL di Dataflow, utilizza i seguenti identificatori:
bigquery.table.`PROJECT_ID`.`DATASET_NAME`.`TABLE_NAME`
Gli identificatori devono seguire la struttura lessicale SQL di Dataflow. Utilizza i accenti gravi per racchiudere gli identificatori con caratteri che non sono lettere, numeri o trattini bassi.
Ad esempio, la seguente query seleziona dalla tabella BigQuery us_state_salesregions nel set di dati dataflow_sql_dataset e nel progetto dataflow-sql:
SELECT *
FROM bigquery.table.`dataflow-sql`.dataflow_sql_dataset.us_state_salesregions
Scrittura in una tabella BigQuery
Puoi scrivere risultati di query in una query Dataflow SQL con l'interfaccia a riga di comando di Cloud Console o Google Cloud.
Console
Per scrivere i risultati della query in una query Dataflow SQL, esegui la query con SQL SQL:
In Cloud Console, vai alla pagina BigQuery, dove puoi utilizzare Dataflow SQL.
Inserisci la query SQL Dataflow nell'editor delle query.
Fai clic su Crea job Cloud Dataflow per aprire un riquadro di opzioni di job.
Nella sezione Destinazione del riquadro, seleziona Tipo di output > BigQuery.
Fai clic su ID set di dati e seleziona un Set di dati caricato o Crea nuovo set di dati.
Nel campo Nome tabella, inserisci una tabella di destinazione.
(Facoltativo) Scegli come caricare i dati in una tabella BigQuery.
- Scrivi se vuoto: (impostazione predefinita) scrive i dati solo se la tabella è vuota.
- Aggiungi alla tabella: aggiunge i dati alla fine della tabella.
- Sovrascrivi tabella: cancella tutti i dati esistenti in una tabella prima di scrivere i nuovi dati.
Fai clic su Crea.
gcloud
Per scrivere i risultati della query in una tabella BigQuery, utilizza il flag --bigquery-table del comando gcloud dataflow sql query:
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --bigquery-dataset=DATASET_NAME \ --bigquery-table=TABLE_NAME \ 'QUERY'
Sostituisci quanto segue:
JOB_NAME: un nome per il lavoro a tua scelta.REGION: endpoint a livello di area geografica (ad esempious-west1)DATASET_NAME: nome del set di dati BigQueryTABLE_NAME: nome della tabella BigQueryQUERY: la query SQL Dataflow
Per scegliere come scrivere i dati in una tabella BigQuery, puoi utilizzare il flag --bigquery-write-disposition e i seguenti valori:
write-empty: (valore predefinito) scrive i dati solo se la tabella è vuota.write-append: aggiunge i dati alla fine della tabella.write-truncate: cancella tutti i dati esistenti in una tabella prima di scrivere i nuovi dati.
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --bigquery-dataset=DATASET_NAME \ --bigquery-table=TABLE_NAME \ --bigquery-write-disposition=WRITE_MODE 'QUERY'
Sostituisci WRITE_MODE con il valore di scrittura di BigQuery.
Lo schema della tabella BigQuery di destinazione deve corrispondere allo schema dei risultati della query. Se una tabella BigQuery di destinazione non dispone di uno schema, viene assegnato automaticamente uno schema corrispondente ai risultati della query.