You can use the Data Catalog API to create and search for Cloud Storage fileset entries (referred to as filesets in this document).
Filesets
A Cloud Storage fileset is an entry within a user-created entry group. For more information, see Entries and entry groups.
It is defined by one or more file patterns that specify a set of one or more Cloud Storage files.
- A file pattern must begin with
gs://bucket_name/. - The bucket name must follow Cloud Storage bucket name requirements.
- Wildcards are allowed in the folder and file portions of file patterns, but
wildcards are not allowed in bucket names. For examples, see:
- Wildcard Names
- GcsFilesetSpec.filePatterns API reference documentation
- A fileset must have one, and may have no more than 5, fileset patterns.
You can query Data Catalog filesets with Dataflow SQL but only if they have a defined schema and contain only CSV files without header rows.
Create entry groups and filesets
Filesets must be placed within a user-created entry group. If you have not created an entry group, first create the entry group, then create the fileset within the entry group. You can set IAM policies on the entry group to define who has access to filesets and other entries within the entry group.
Console
Go to the Data Catalog Entry groups page. Click Create entry group. Complete the Create Entry Group form, then click CREATE. The Entry group details page opens. With the ENTRIES tab selected,
click CREATE. Complete the Create Fileset form.
Click Create to create the fileset.Console



gcloud
Use the
gcloud data-catalog entry-groups create command to create an entry group with an attached schema and description. Example: Use the
gcloud data-catalog entries create
command to create a fileset within an entry group. This Google Cloud CLI command
example, below, creates a fileset entry that includes schema of fileset data. Flag notes:gcloud
1. Create an entry group
gcloud data-catalog entry-groups create my_entrygroup \
--location=us-central1
2. Create a fileset within the entry group
gcloud data-catalog entries create my_fileset_entry \
--location=us-central1 \
--entry-group=my_entrygroup \
--type=FILESET \
--gcs-file-patterns=gs://my-bucket/*.csv \
--schema-from-file=path_to_schema_file \
--description="Fileset description ..."
--gcs-file-patterns: See
File pattern requirements.--schema-from-file: The following sample shows the
JSON format of the schema text file accepted by the
--schema-from-file flag.
[
{
"column": "first_name",
"description": "First name",
"mode": "REQUIRED",
"type": "STRING"
},
{
"column": "last_name",
"description": "Last name",
"mode": "REQUIRED",
"type": "STRING"
},
{
"column": "address",
"description": "Address",
"mode": "REPEATED",
"type": "STRING"
}
]
Java
Before trying this sample, follow the Java setup instructions in the
Data Catalog quickstart using
client libraries.
For more information, see the
Data Catalog Java API
reference documentation.
To authenticate to Data Catalog, set up Application Default Credentials.
For more information, see
Set up authentication for a local development environment.
Node.js
Before trying this sample, follow the Node.js setup instructions in the
Data Catalog quickstart using
client libraries.
For more information, see the
Data Catalog Node.js API
reference documentation.
To authenticate to Data Catalog, set up Application Default Credentials.
For more information, see
Set up authentication for a local development environment.
Python
Before trying this sample, follow the Python setup instructions in the
Data Catalog quickstart using
client libraries.
For more information, see the
Data Catalog Python API
reference documentation.
To authenticate to Data Catalog, set up Application Default Credentials.
For more information, see
Set up authentication for a local development environment.
REST and Command line
If you don't have access to Cloud Client libraries for your language or
want to test the API using REST requests, see the following examples
and refer to the Data Catalog REST API
entryGroups.create
and
entryGroups.entries.create
documentation.
Before using any of the request data,
make the following replacements:
HTTP method and URL:
Request JSON body:
To send your request, expand one of these options: You should receive a JSON response similar to the following:
Before using any of the request data,
make the following replacements:
HTTP method and URL:
Request JSON body:
To send your request, expand one of these options: You should receive a JSON response similar to the following:REST
POST https://datacatalog.googleapis.com/v1/projects/project-id/locations/region/entryGroups?entryGroupId=entryGroupId
{
"displayName": "Entry Group display name"
}
{
"name": "projects/my_projectid/locations/us-central1/entryGroups/my_entry_group",
"displayName": "Entry Group display name",
"dataCatalogTimestamps": {
"createTime": "2019-10-19T16:35:50.135Z",
"updateTime": "2019-10-19T16:35:50.135Z"
}
}
{ ...
"schema": {
"columns": [
{
"column": "first_name",
"description": "First name",
"mode": "REQUIRED",
"type": "STRING"
},
{
"column": "last_name",
"description": "Last name",
"mode": "REQUIRED",
"type": "STRING"
},
{
"column": "address",
"description": "Address",
"mode": "REPEATED",
"subcolumns": [
{
"column": "city",
"description": "City",
"mode": "NULLABLE",
"type": "STRING"
},
{
"column": "state",
"description": "State",
"mode": "NULLABLE",
"type": "STRING"
}
],
"type": "RECORD"
}
]
}
...
}
POST https://datacatalog.googleapis.com/v1/projects/project_id/locations/region/entryGroups/entryGroupId/entries?entryId=entryId
{
"description": "Fileset description.",
"displayName": "Display name",
"gcsFilesetSpec": {
"filePatterns": [
"gs://bucket_name/file_pattern"
]
},
"type": "FILESET",
"schema": { schema }
}
{
"name": "projects/my_project_id/locations/us-central1/entryGroups/my_entryGroup_id/entries/my_entry_id",
"type": "FILESET",
"displayName": "My Fileset",
"description": "My Fileset description.",
"schema": {
"columns": [
{
"type": "STRING",
"description": "First name",
"mode": "REQUIRED",
"column": "first_name"
},
{
"type": "STRING",
"description": "Last name",
"mode": "REQUIRED",
"column": "last_name"
},
{
"type": "RECORD",
"description": "Address",
"mode": "REPEATED",
"column": "address",
"subcolumns": [
{
"type": "STRING",
"description": "City",
"mode": "NULLABLE",
"column": "city"
},
{
"type": "STRING",
"description": "State",
"mode": "NULLABLE",
"column": "state"
}
]
}
]
},
"gcsFilesetSpec": {
"filePatterns": [
"gs://my_bucket_name/chicago_taxi_trips/csv/shard-*.csv"
]
},
"sourceSystemTimestamps": {
"createTime": "2019-10-23T23:11:26.326Z",
"updateTime": "2019-10-23T23:11:26.326Z"
},
"linkedResource": "//datacatalog.googleapis.com/projects/my_project_id/locations/us-central1/entryGroups/my_entryGroup_id/entries/my_entry_id"
}
IAM roles, permissions, and policies
Data Catalog defines entry and entry group roles to facilitate permission management of filesets and other Data Catalog resources.
| Entry roles | Description |
|---|---|
dataCatalog.entryOwner |
Owner of a particular entry or group of entries.
|
dataCatalog.entryViewer |
Can view details of entry and entryGroup.
|
| Entry group roles | Description |
|---|---|
dataCatalog.entryGroupOwner |
Owner of a particular entryGroup.
|
dataCatalog.entryGroupCreator |
Can create entryGroups within a project. The creator of an entryGroup is automatically granted the dataCatalog.entryGroupOwner role.
|
Set IAM policies
Users with datacatalog.<resource>.setIamPolicy permission
can set IAM policies on Data Catalog entry groups
and other Data Catalog resources (see
Data Catalog roles).
Console
Navigate to the Entry group details page in the Data Catalog UI then use the IAM panel located on the right side to grant or revoke permissions.
gcloud
Set the IAM policy of an entry group with Google Cloud CLI data-catalog entry-groups set-iam-policy:
gcloud data-catalog entry-groups set-iam-policy my_entrygroup \ --location=us-central1 \ policy file
Get the IAM policy of an entry group with Google Cloud CLI data-catalog entry-groups get-iam-policy
gcloud data-catalog entry-groups get-iam-policy my_entrygroup \ --location=us-central1
Grant entry group roles
Example 1
A company with different business contexts for its filesets
creates separate order-files and user-files entry groups:
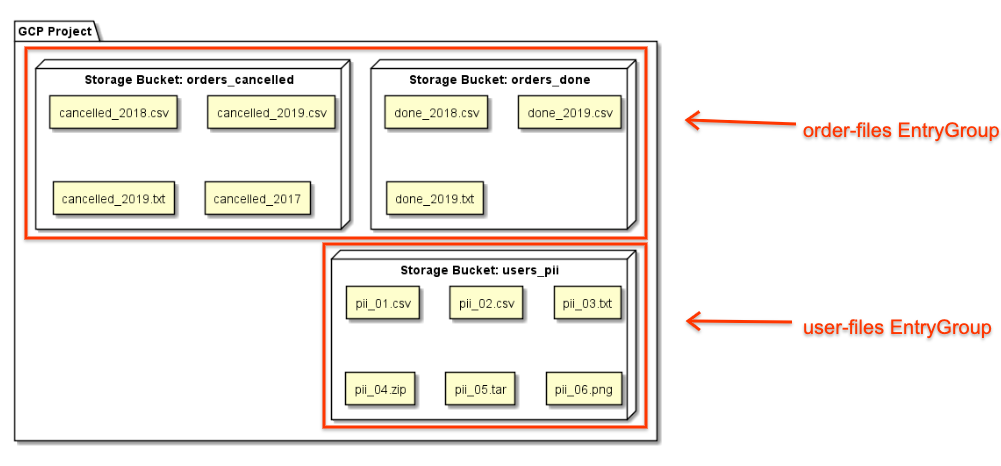
The company grants users the entry group viewer role for order-files, meaning
they can only search for entries contained in that entry group. Their search
results don't return entries in user-files entry group.
Example 2
A company grants the entry group viewer role to a user only in the
project_entry_group project. The user will only be able to view
entries within that project.
Search filesets
Users can restrict the scope of search in Data Catalog by using
the type facet. type=entry_group restricts the search query to
entry groups while type=fileset searches only for filesets.
type facets can be used in conjunction with other facets, such as projectid.
gcloud
Search for entry groups in a project:
gcloud data-catalog search \ --include-project-ids=my-project "projectid=my-project type=entry_group"
Search for all entry groups you can access:
gcloud data-catalog search \ --include-project-ids=my-project "type=entry_group"
Search for filesets in a project:
gcloud data-catalog search \ --include-project-ids=my-project "type=entry.fileset"
Search for filesets in a project (simplified syntax):
gcloud data-catalog search \ --include-project-ids=my-project "type=fileset"