En esta página, se explica cómo consultar datos y escribir resultados de consultas mediante Dataflow SQL.
Dataflow SQL puede consultar las siguientes fuentes:
- Transmisión de datos de temas de Pub/Sub
- Transmisión y datos por lotes de conjuntos de archivos de Cloud Storage
- Datos por lotes de las tablas de BigQuery
Dataflow SQL puede escribir resultados de consultas en los siguientes destinos:
Pub/Sub
Consulta temas de Pub/Sub
Para consultar un tema de Pub/Sub con Dataflow SQL, completa los siguientes pasos:
Agrega el tema de Pub/Sub como fuente de Dataflow.
Asigna un esquema al tema de Pub/Sub.
Usa el tema de Pub/Sub en una consulta de Dataflow SQL.
Agrega un tema de Pub/Sub
Puedes agregar un tema de Pub/Sub como una fuente de Dataflow mediante la IU web de BigQuery.
En Google Cloud Console, ve a la página de BigQuery, en la que puedes usar Dataflow SQL.
En el panel de navegación, haz clic en la lista desplegable Add Data (Agregar datos) y selecciona Cloud Dataflow sources (Fuentes de Cloud Dataflow).
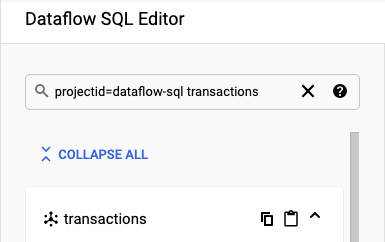
En el panel Add Cloud Dataflow source (Agregar fuente de Cloud Dataflow), selecciona Cloud Pub/Sub topics (Temas de Cloud Pub/Sub) y busca el tema.
En la siguiente captura de pantalla, se muestra una búsqueda del tema
transactionsde Pub/Sub: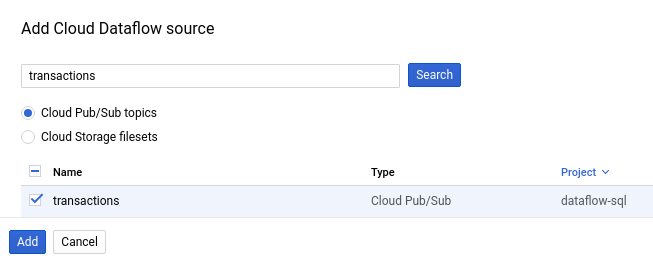
Haga clic en Add.
Después de agregar el tema de Pub/Sub como una fuente de Dataflow, el tema de Pub/Sub aparece en la sección Recursos del menú de navegación.
Para encontrar el tema, expande Fuentes de Cloud Dataflow > Temas de Cloud Pub/Sub.
Asigna un esquema del tema de Pub/Sub
Esquemas de temas de Pub/Sub constan de los siguientes campos:
Un campo
event_timestamp.Las marcas de tiempo del evento de Pub/Sub identifican cuándo se publican los mensajes. Las marcas de tiempo se agregan a los mensajes de Pub/Sub de forma automática.
Un campo para cada par clave-valor en los mensajes de Pub/Sub.
Por ejemplo, el esquema para el mensaje
{"k1":"v1", "k2":"v2"}incluye dos camposSTRING, llamadosk1yk2.
Puedes asignar un esquema a un tema de Pub/Sub mediante Cloud Console o Google Cloud CLI.
Console
Para asignar un esquema a un tema de Pub/Sub, completa los siguientes pasos:
Selecciona el tema en el panel Resources (Recursos).
En la pestaña Schema (Esquema), haz clic en Edit schema (Editar esquema) para abrir el panel lateral Schema (Esquema) que muestra los campos del esquema.
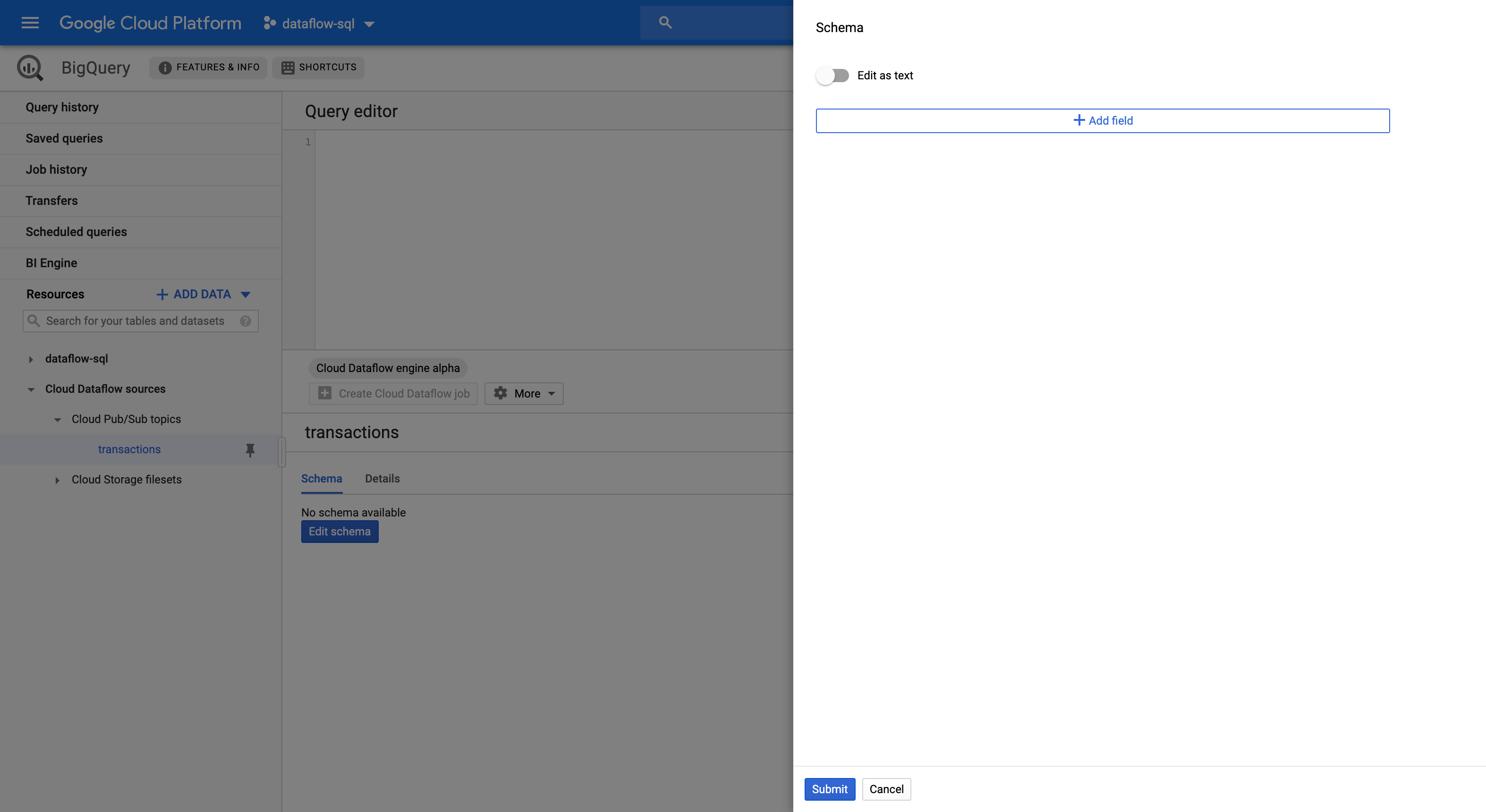
Haz clic en Add field (Agregar campo) a fin de agregar un campo al esquema o puedes activar o desactivar el botón Edit as text (Editar como texto) para copiar y pegar todo el texto del esquema.
Por ejemplo, el siguiente es el texto del esquema para un tema de Pub/Sub con transacciones de venta:
[ { "description": "Pub/Sub event timestamp", "name": "event_timestamp", "mode": "REQUIRED", "type": "TIMESTAMP" }, { "description": "Transaction time string", "name": "tr_time_str", "mode": "NULLABLE", "type": "STRING" }, { "description": "First name", "name": "first_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "Last name", "name": "last_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "City", "name": "city", "mode": "NULLABLE", "type": "STRING" }, { "description": "State", "name": "state", "mode": "NULLABLE", "type": "STRING" }, { "description": "Product", "name": "product", "mode": "NULLABLE", "type": "STRING" }, { "description": "Amount of transaction", "name": "amount", "mode": "NULLABLE", "type": "FLOAT64" } ]Haga clic en Enviar.
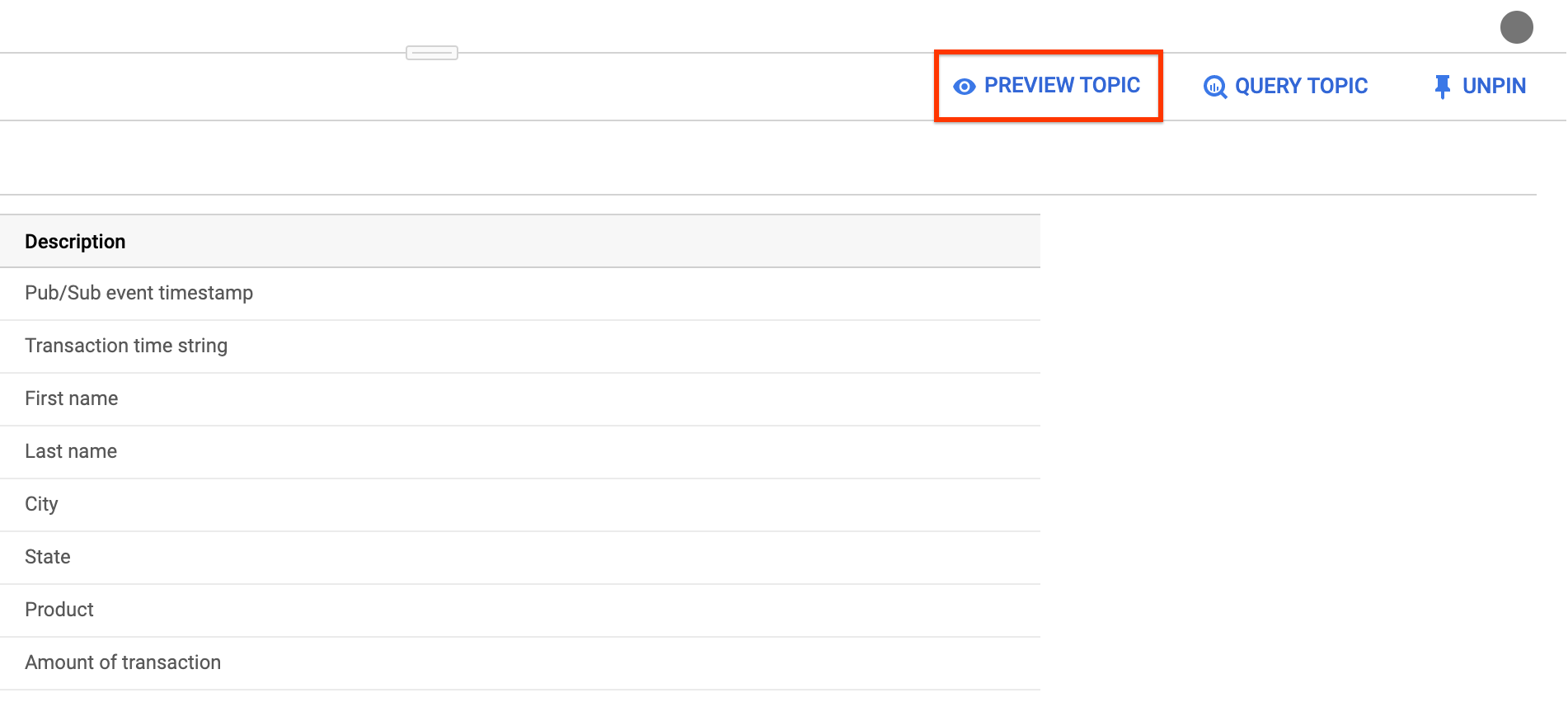
Haz clic en Preview topic (Vista previa del tema) para examinar el contenido de tus mensajes y confirmar que coincidan con el esquema que definiste (opcional).
gcloud
Para asignar un esquema a un tema de Pub/Sub, completa los siguientes pasos:
Crea un archivo JSON con el texto del esquema.
Por ejemplo, el siguiente es el texto del esquema para un tema de Pub/Sub con transacciones de venta:
[ { "description": "Pub/Sub event timestamp", "column": "event_timestamp", "mode": "REQUIRED", "type": "TIMESTAMP" }, { "description": "Transaction time string", "column": "tr_time_str", "mode": "NULLABLE", "type": "STRING" }, { "description": "First name", "column": "first_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "Last name", "column": "last_name", "mode": "NULLABLE", "type": "STRING" }, { "description": "City", "column": "city", "mode": "NULLABLE", "type": "STRING" }, { "description": "State", "column": "state", "mode": "NULLABLE", "type": "STRING" }, { "description": "Product", "column": "product", "mode": "NULLABLE", "type": "STRING" }, { "description": "Amount of transaction", "column": "amount", "mode": "NULLABLE", "type": "FLOAT64" } ]Asigna el esquema al tema de Pub/Sub mediante el comando
gcloud data-catalog entries:gcloud data-catalog entries update \ --lookup-entry='pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`' \ --schema-from-file=FILE_PATH
Reemplaza lo siguiente:
PROJECT_ID: El ID de tu proyectoTOPIC_NAME: Es el nombre del tema de Pub/Sub.FILE_PATH: La ruta del archivo JSON con el texto del esquema
(Opcional) Ejecuta el siguiente comando para confirmar que tu esquema se asignó de forma correcta al tema de Pub/Sub:
gcloud data-catalog entries lookup \ 'pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`'
Usa un tema de Pub/Sub
Para hacer referencia a un tema de Pub/Sub en una consulta de Dataflow SQL, usa los siguientes identificadores:
pubsub.topic.`PROJECT_ID`.`TOPIC_NAME`
Reemplaza lo siguiente:
PROJECT_ID: El ID de tu proyectoTOPIC_NAME: Es el nombre del tema de Pub/Sub.
Por ejemplo, la siguiente consulta hace una selección en el tema de Dataflow daily.transactions en el proyecto dataflow-sql:
SELECT *
FROM pubsub.topic.`dataflow-sql`.`daily.transactions`
Escribe en temas de Pub/Sub
Puedes escribir los resultados de las consultas en un tema de Pub/Sub mediante Cloud Console o Google Cloud CLI.
Console
Para escribir resultados de consulta en un tema de Pub/Sub, ejecuta la consulta con Dataflow SQL:
En Cloud Console, ve a la página de BigQuery, en la que puedes usar Dataflow SQL.
Ingresa la consulta de Dataflow SQL en el editor de consultas.
Haz clic en Crear trabajo de Cloud Dataflow para abrir un panel de opciones de trabajo.
En la sección Destino del panel, selecciona Tipo de resultado > Tema de Cloud Pub/Sub.
Haz clic en Seleccionar un tema de Cloud Pub/Sub y elige un tema.
Haz clic en Crear.
gcloud
Para escribir los resultados de las consultas en un tema de Pub/Sub, usa la marca --pubsub-topic del comando gcloud dataflow sql query:
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --pubsub-project=PROJECT_ID \ --pubsub-topic=TOPIC_NAME \ 'QUERY'
Reemplaza lo siguiente:
JOB_NAME: Es el nombre del trabajo que elijasREGION: Es el extremo regional (por ejemplo,us-west1).PROJECT_ID: El ID de tu proyectoTOPIC_NAME: Es el nombre del tema de Pub/Sub.QUERY: Es la consulta de SQL de Dataflow.
El esquema de los temas de Pub/Sub de destino debe coincidir con el esquema de los resultados de la consulta. Si un tema de Pub/Sub de destino no tiene un esquema, se asigna un esquema que coincida con los resultados de la consulta de forma automática.
Cloud Storage
Consulta conjuntos de archivos de Cloud Storage
Para consultar un conjunto de archivos de Cloud Storage con Dataflow SQL, completa los siguientes pasos:
Crea un conjunto de archivos de Data Catalog para Dataflow SQL.
Agrega el conjunto de archivos de Cloud Storage como fuente de Dataflow.
Usa el conjunto de archivos de Cloud Storage en una consulta de Dataflow SQL.
Crea conjuntos de archivos de Cloud Storage
Para crear un conjunto de archivos de Cloud Storage, consulta Crea grupos de entradas y conjuntos de archivos.
El conjunto de archivos de Cloud Storage debe tener un esquema y solo contener archivos CSV sin filas de encabezado.
Agrega conjuntos de archivos de Cloud Storage
Puedes agregar un conjunto de archivos de Cloud Storage como fuente de Dataflow mediante Dataflow SQL:
En Cloud Console, ve a la página de BigQuery, en la que puedes usar Dataflow SQL.
En el panel de navegación, haz clic en la lista desplegable Add Data (Agregar datos) y selecciona Cloud Dataflow sources (Fuentes de Cloud Dataflow).
En el panel Agregar fuente de Cloud Dataflow, selecciona Conjuntos de archivos de Cloud Storage y busca el tema.
Haga clic en Agregar.
Después de agregar el conjunto de archivos de Cloud Storage como fuente de Dataflow, el conjunto de archivos de Cloud Storage aparece en la sección Recursos del menú de navegación.
Para encontrar el conjunto de archivos, expande Fuentes de Cloud Dataflow > Temas de Cloud Storage.
Usa un conjunto de archivos de Cloud Storage
Para hacer referencia a una tabla de Cloud Storage en una consulta de Dataflow SQL, usa los siguientes identificadores:
datacatalog.entry.`PROJECT_ID`.REGION.`ENTRY_GROUP`.`FILESET_NAME`
Reemplaza lo siguiente:
PROJECT_ID: El ID de tu proyectoREGION: Es el extremo regional (por ejemplo,us-west1).ENTRY_GROUP: Es el grupo de entrada del conjunto de archivos de Cloud Storage.FILESET_NAME: Es el nombre del conjunto de archivos de Cloud Storage.
Por ejemplo, en la siguiente consulta, se hace una selección en el conjunto de archivos de Cloud Storage daily.registrations en el proyecto dataflow-sql y el grupo de entrada my-fileset-group:
SELECT *
FROM datacatalog.entry.`dataflow-sql`.`us-central1`.`my-fileset-group`.`daily.registrations`
BigQuery
Consulta tablas de BigQuery
Para consultar una tabla de BigQuery con Dataflow SQL, completa los siguientes pasos:
Crea una tabla de BigQuery para Dataflow SQL.
Usa la tabla de BigQuery en una consulta de Dataflow SQL.
No es necesario agregar una tabla de BigQuery como fuente de Dataflow.
Crea una tabla de BigQuery
Si deseas crear una tabla de BigQuery para Dataflow SQL, consulta Crea una tabla vacía con una definición de esquema.
Usa una tabla de BigQuery en una consulta
Para hacer referencia a una tabla de BigQuery en una consulta de Dataflow SQL, usa los siguientes identificadores:
bigquery.table.`PROJECT_ID`.`DATASET_NAME`.`TABLE_NAME`
Los identificadores deben seguir la estructura léxica de Dataflow SQL. Usa acentos graves para incluir identificadores con caracteres que no sean letras, números o guiones bajos.
Por ejemplo, la siguiente consulta hace una selección en la tabla de BigQuery us_state_salesregions en el conjunto de datos dataflow_sql_dataset y el proyecto dataflow-sql:
SELECT *
FROM bigquery.table.`dataflow-sql`.dataflow_sql_dataset.us_state_salesregions
Escribe en una tabla de BigQuery
Puedes escribir los resultados de las consultas en una consulta de Dataflow SQL mediante Cloud Console o Google Cloud CLI.
Console
Para escribir los resultados de la consulta en una consulta de Dataflow SQL, ejecuta la consulta mediante Dataflow SQL:
En Cloud Console, ve a la página de BigQuery, en la que puedes usar Dataflow SQL.
Ingresa la consulta de Dataflow SQL en el editor de consultas.
Haz clic en Crear trabajo de Cloud Dataflow para abrir un panel de opciones de trabajo.
En la sección Destino del panel, selecciona Tipo de salida > BigQuery.
Haz clic en ID del conjunto de datos y selecciona un Conjunto de datos cargado o Crear conjunto de datos nuevo.
En el campo Nombre de la tabla, ingresa una tabla de destino.
Elige cómo cargar datos en una tabla de BigQuery (opcional).
- Escribir si está vacía: Escribe los datos solo si la tabla está vacía (predeterminado).
- Agregar a la tabla: Agrega los datos al final de la tabla.
- Reemplazar tabla: Borra todos los datos existentes en una tabla antes de escribir los datos nuevos.
Haz clic en Crear.
gcloud
Para escribir resultados de consultas en una tabla de BigQuery, usa la marca --bigquery-table del comando gcloud dataflow sql query:
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --bigquery-dataset=DATASET_NAME \ --bigquery-table=TABLE_NAME \ 'QUERY'
Reemplaza lo siguiente:
JOB_NAME: Es el nombre del trabajo que elijasREGION: Es el extremo regional (por ejemplo,us-west1).DATASET_NAME: Es el nombre de tu conjunto de datos de BigQueryTABLE_NAME: Es el nombre de la tabla de BigQuery.QUERY: Es la consulta de SQL de Dataflow.
Para elegir cómo escribir datos en una tabla de BigQuery, puedes usar la marca --bigquery-write-disposition y los siguientes valores:
write-empty: Escribe los datos solo si la tabla está vacía (predeterminado).write-append: Agrega los datos al final de la tabla.write-truncate: Borra todos los datos existentes de una tabla antes de escribir los datos nuevos.
gcloud dataflow sql query \ --job-name=JOB_NAME \ --region=REGION \ --bigquery-dataset=DATASET_NAME \ --bigquery-table=TABLE_NAME \ --bigquery-write-disposition=WRITE_MODE 'QUERY'
Reemplaza WRITE_MODE por el valor de disposición de escritura de BigQuery.
El esquema de la tabla de BigQuery de destino debe coincidir con el esquema de los resultados de la consulta. Si una tabla de BigQuery de destino no tiene un esquema, se asigna un esquema que coincida con los resultados de la consulta de forma automática.