本页面介绍如何解决 Cloud Data Fusion 的问题。
排查批处理流水线问题
并发流水线卡住
在 Cloud Data Fusion 中,运行多个并发批处理流水线可能会给实例带来压力,导致作业卡在 Starting、Provisioning 或 Running 状态。因此,无法通过网页界面或 API 调用停止流水线。同时运行多个流水线时,网页界面可能会变得缓慢或无响应。出现此问题是因为向后端中的 HTTP 处理程序发出了多个界面请求。
建议
如需解决此问题,请使用 Cloud Data Fusion 流控制(适用于运行在 6.6 及更高版本实例中的实例)控制新请求的数量。
在运行流水线时,SSH 连接超时
运行批处理流水线时会发生以下错误:
`java.io.IOException: com.jcraft.jsch.JSchException:
java.net.ConnectException: Connection timed out (Connection timed out)`
建议
如需解决该错误,请检查是否存在以下问题:
- 检查是否缺少防火墙规则(通常是端口 22)。如需创建新的防火墙规则,请参阅 Dataproc 集群网络配置
- 检查 Compute Engine Enforcementr 是否允许在 Cloud Data Fusion 实例与 Dataproc 集群之间建立连接。
响应代码:401。错误:未知错误
运行批处理流水线时会发生以下错误:
`java.io.IOException: Failed to send message for program run program_run:
Response code: 401. Error: unknown error`
建议
如需解决此错误,您必须将 Cloud Data Fusion Runner 角色 (roles/datafusion.runner) 授予 Dataproc 使用的服务帐号。
使用 BigQuery 插件的流水线失败并显示 Access Denied 错误
存在一个已知问题,即在运行 BigQuery 作业时流水线失败并显示 Access Denied 错误。这会影响使用以下插件的流水线:
- BigQuery 来源
- BigQuery 接收器
- BigQuery 多表接收器
- 转换推送
日志中的示例错误(可能因您使用的插件而异):
POST https://bigquery.googleapis.com/bigquery/v2/projects/PROJECT_ID/jobs
{
"code" : 403,
"errors" : [ {
"domain" : "global",
"message" : "Access Denied: Project xxxx: User does not have bigquery.jobs.create permission in project PROJECT_ID",
"reason" : "accessDenied"
} ],
"message" : "Access Denied: Project PROJECT_ID: User does not have bigquery.jobs.create permission in project PROJECT_ID.",
"status" : "PERMISSION_DENIED"
}
在此示例中,PROJECT_ID 是您在插件中指定的项目 ID。在插件中指定的项目的服务账号无权执行以下至少一项操作:
- 运行 BigQuery 作业
- 读取 BigQuery 数据集
- 创建临时存储桶
- 创建 BigQuery 数据集
- 创建 BigQuery 表
建议
为解决此问题,请将缺失的角色授予您在插件中指定的项目 (PROJECT_ID):
如需运行 BigQuery 作业,请授予 BigQuery Job User (
roles/bigquery.jobUser) 角色。如需读取 BigQuery 数据集,请授予 BigQuery Data Viewer (
roles/bigquery.dataViewer) 角色。如需创建临时存储桶,请授予 Storage Admin (
roles/storage.admin) 角色。如需创建 BigQuery 数据集或表,请授予 BigQuery Data Editor (
roles/bigquery.dataEditor) 角色。
如需了解详情,请参阅插件的问题排查文档(Google BigQuery 多表接收器问题排查)。
在达到错误阈值时,流水线不会停止
即使您将错误阈值设置为 1,流水线也可能不会在出现多次错误后停止。
错误阈值适用于在发生未以其他方式处理的故障时,指令引发的任何异常。如果该指令已使用 emitError API,则不会激活错误阈值。
建议
如需设计在达到特定阈值时失败的流水线,请使用 FAIL 指令。
每当满足传递给 FAIL 指令的条件时,系统就会根据错误阈值进行计数,达到阈值后流水线就会失败。
Oracle 批量源插件将 NUMBER 转换为 string
在 Oracle 批量源代码版本 1.9.0、1.8.3 及更低版本中,精度和规模未定义的 Oracle NUMBER 数据类型会映射到 CDAP decimal(38,0) 数据类型。
插件版本 1.9.1、1.8.4 和 1.8.5 向后不兼容,如果由于输出架构发生更改而导致流水线中的下游阶段依赖于来源的输出架构,那么使用早期版本的流水线在升级到版本 1.9.1、1.8.5 和 1.8.4 后可能无法正常运行。如果在之前的插件版本中为 Oracle NUMBER 数据类型定义了输出架构,但未定义精度和扩缩,那么升级到版本 1.9.1、1.8.5 或 1.8.4 后,Oracle 批量源插件会针对这些类型抛出以下架构不匹配错误:Schema field '<field name>' is expected to
have type 'decimal with precision <precision> and scale <scale> but found
'string'. Change the data type of field <field name> to string.
版本 1.9.1、1.8.5 和 1.8.4 支持在没有精度和规模的情况下定义的 Oracle NUMBER 数据类型为 CDAP string 数据类型的输出架构。如果 Oracle 源输出架构中定义了任何不含精度和缩放比例的 Oracle NUMBER 数据类型,则不建议使用旧版 Oracle 插件,因为这可能会导致舍入错误。
特殊情况是,如果您对数据库名称、架构名称或表名称使用宏,并且尚未手动指定输出架构。系统会在运行时检测并映射架构。旧版 Oracle 批量来源插件会将没有精度定义的 Oracle NUMBER 数据类型映射到 CDAP decimal(38,0) 数据类型,而 1.9.1、1.8.5 和 1.8.4 版及更高版本会在运行时将这些数据类型映射到 string。
建议
如需解决在使用精度和规模未定义的 Oracle NUMBER 数据类型时可能出现的精度损失问题,请升级您的流水线以使用 Oracle 批量源插件版本 1.9.1、1.8.5 或 1.8.4。
升级后,定义的没有精度和规模的 Oracle NUMBER 数据类型会在运行时映射到 CDAP string 数据类型。如果您的下游阶段或接收器使用原始 CDAP decimal 数据类型(对于 Oracle NUMBER 数据类型,但未将其映射到该数据类型,但未定义精度和缩放比例),请进行更新或预期其使用字符串数据。
如果您了解舍入错误可能导致数据丢失的风险,但您选择使用没有精度定义的 Oracle NUMBER 数据类型,并按 CDAP decimal(38,0) 数据类型进行扩缩,请从 Hub 中部署 Oracle 插件版本 1.8.6(适用于 Cloud Data Fusion 6.7.3)或 1.9.2(适用于 Cloud Data Fusion 6.8.1),并进行更新。
如需了解详情,请参阅 Oracle 批处理来源参考文档。
删除临时 Dataproc 集群
如果 Cloud Data Fusion 在流水线运行预配期间创建临时 Dataproc 集群,则该集群将在流水线运行完成后删除。在极少数情况下,集群删除失败。
强烈建议:升级到最新的 Cloud Data Fusion 版本,以确保正确维护集群。
设置空闲时间上限
如需解决此问题,请配置 Max Idle Time 选项。这允许 Dataproc 自动删除集群,即使对流水线完成的显式调用失败也是如此。
Max Idle Time 在 Cloud Data Fusion 6.4 及更高版本中提供。
建议:对于 6.6 之前的版本,将 Max Idle Time 手动设置为 30 分钟或更长时间。
手动删除集群
如果您无法升级版本或配置 Max Idle Time 选项,请改为手动删除过时集群:
获取创建集群所在的每个项目 ID:
在流水线的运行时参数中,检查是否针对运行自定义了 Dataproc 项目 ID。

如果未明确指定 Dataproc 项目 ID,请确定使用的是哪个预配工具,然后检查项目 ID:
在流水线运行时参数中,检查
system.profile.name值。
打开预配工具设置,并检查是否已设置 Dataproc 项目 ID。如果此设置不存在或该字段为空,系统会使用运行 Cloud Data Fusion 实例的项目。
对于每个项目:
在 Google Cloud 控制台中打开项目,然后转到 Dataproc 集群页面。
按集群的创建日期(从最旧到最新的)对集群进行排序。
如果信息面板隐藏,请点击显示信息面板,然后转到标签标签页。
对于每个未使用的集群(例如,已超过一天),请检查该集群是否具有 Cloud Data Fusion 版本标签。这表明它是由 Cloud Data Fusion 创建的。
选中集群名称旁边的复选框,然后点击删除。
无法创建 Cloud Data Fusion 实例
创建 Cloud Data Fusion 实例时,您可能会遇到以下问题:
Read access to project PROJECT_NAME was denied.
建议
如需解决此问题,请停用 Cloud Data Fusion API,然后再重新启用。然后创建实例。
在具有辅助工作器的 Dataproc 集群上运行时,流水线会失败
在 Cloud Data Fusion 6.8 和 6.9 版中,会发生一个问题,即如果流水线在启用了辅助工作器的 Dataproc 集群上运行,则会导致流水线失败:
ERROR [provisioning-task-2:i.c.c.i.p.t.ProvisioningTask@161] - PROVISION task failed in REQUESTING_CREATE state for program run program_run:default.APP_NAME.UUID.workflow.DataPipelineWorkflow.RUN_ID due to
Caused by: io.grpc.StatusRuntimeException: CANCELLED: Failed to read message.
Caused by: com.google.protobuf.GeneratedMessageV3$Builder.parseUnknownField(Lcom/google/protobuf/CodedInputStream;Lcom/google/protobuf/ExtensionRegistryLite;I)Z.
建议
如需解决此问题,请按以下方式移除辅助工作器节点。
如果您使用临时 Dataproc 预配工具,请按照以下步骤解决错误:
- 转到 Cloud Data Fusion 网页界面中的流水线。
- 在流水线运行时参数中,将
system.profile.properties.secondaryWorkerNumNodes设置为0。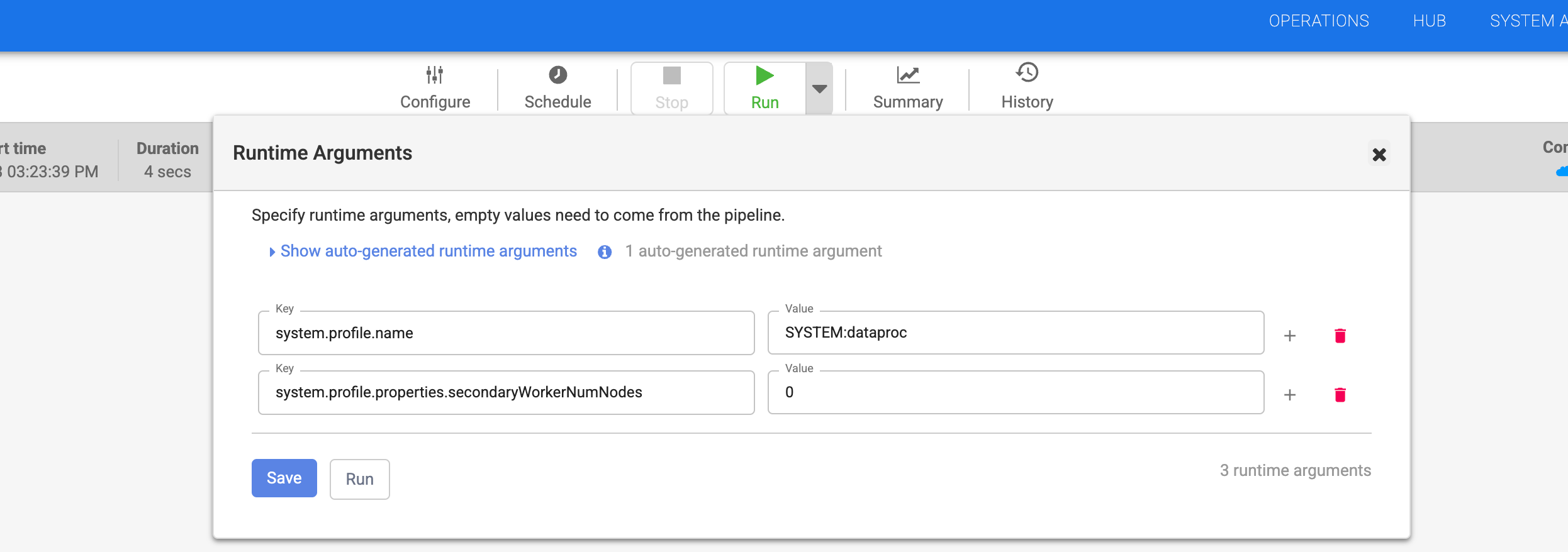
- 点击保存。
- 如果您使用命名空间,请停用该命名空间中的辅助工作器:
- 点击系统管理员 > 命名空间,然后选择命名空间。
- 依次点击偏好设置 > 修改。
- 将
system.profile.properties.secondaryWorkerNumNodes的值设置为0。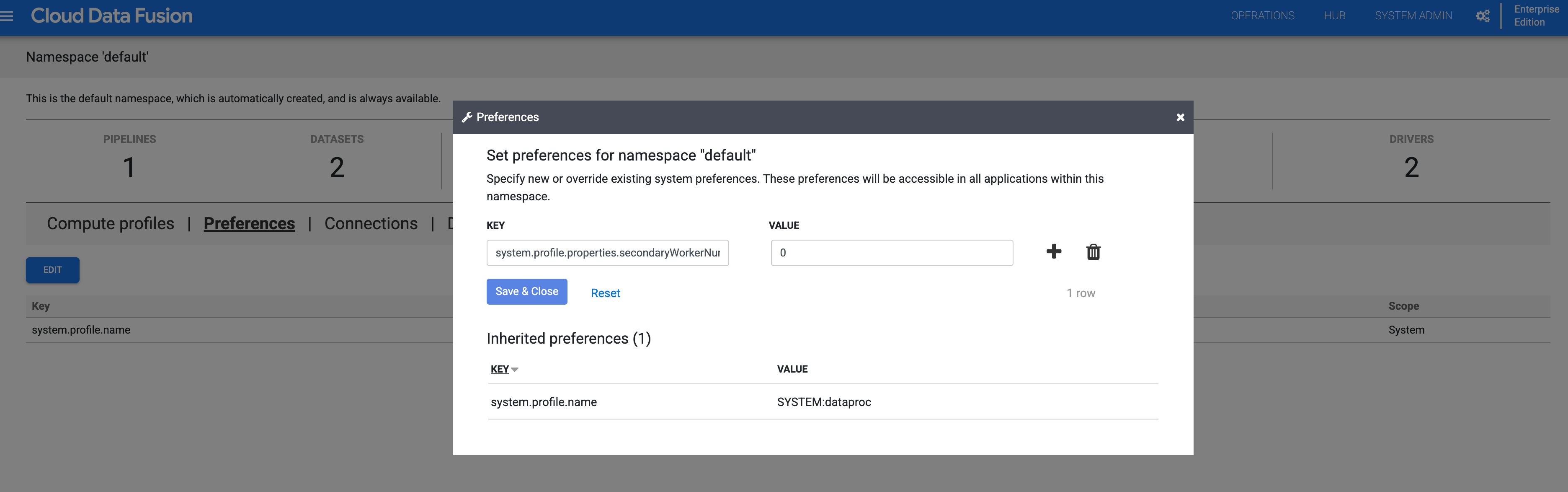
- 点击保存并关闭。
如果您使用现有的 Dataproc 预配工具,请按照以下步骤解决错误:
在 Google Cloud 控制台中,转到 Dataproc 集群页面。
选择相应集群,然后点击 修改。
在辅助工作器节点字段中,输入
0。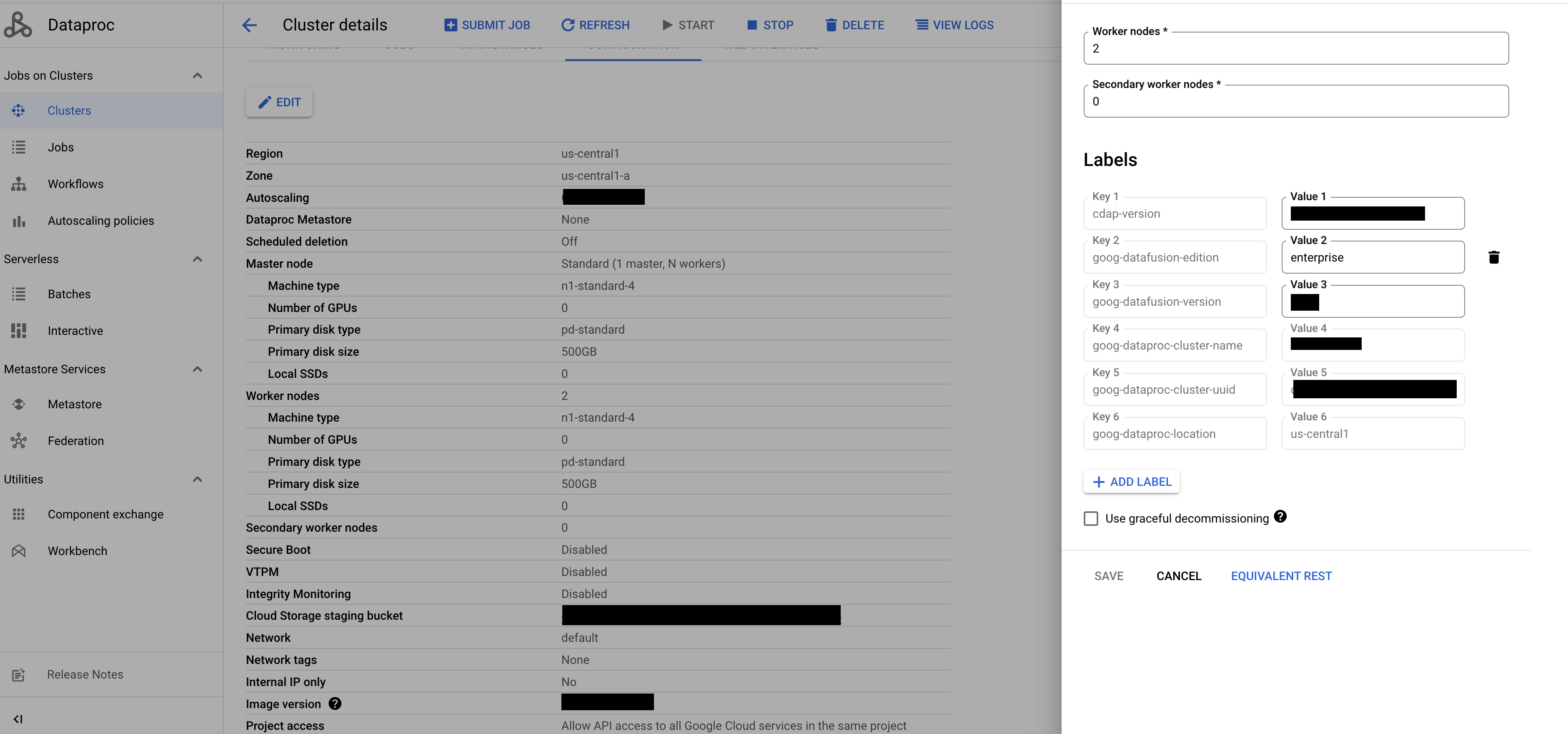
点击保存。