Einbindung in SAP
Auf dieser Seite werden die Integrationsschritte für operative SAP-Arbeitslasten (SAP ECC und SAP S/4HANA) in der Cortex Framework Data Foundation beschrieben. Das Cortex Framework kann die Integration von SAP-Daten in BigQuery beschleunigen. Dazu werden vordefinierte Datenverarbeitungsvorlagen mit Dataflow-Pipelines bis hin zu BigQuery verwendet. Cloud Composer plant und überwacht diese Dataflow-Pipelines, um Erkenntnisse aus Ihren operativen SAP-Daten zu gewinnen.
Die Datei config.json im Cortex Framework Data Foundation-Repository konfiguriert die Einstellungen, die für die Übertragung von Daten aus einer beliebigen Datenquelle, einschließlich SAP, erforderlich sind. Diese Datei enthält die folgenden Parameter für operative SAP-Arbeitslasten:
"SAP": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING"
},
"SQLFlavor": "ecc",
"mandt": "100"
}
In der folgenden Tabelle wird der Wert für jeden SAP-Betriebsparameter beschrieben:
| Parameter | Bedeutung | Standardwert | Beschreibung |
SAP.deployCDC
|
CDC bereitstellen | true
|
CDC-Verarbeitungsskripts generieren, die als DAGs in Cloud Composer ausgeführt werden. |
SAP.datasets.raw
|
Rohdaten-Dataset für die Landingpage | - | Hier werden die Daten aus SAP vom Replikationstool abgelegt. Wenn Sie Testdaten verwenden, erstellen Sie ein leeres Dataset. |
SAP.datasets.cdc
|
CDC-Dataset | - | Dataset, das als Quelle für die Berichtsansichten und als Ziel für die DAGs für die Verarbeitung von Datensätzen dient. Wenn Sie Testdaten verwenden, erstellen Sie ein leeres Dataset. |
SAP.datasets.reporting
|
Berichts-Dataset SAP | "REPORTING"
|
Name des Datasets, auf das Endnutzer für Berichte zugreifen können und in dem Ansichten und nutzerorientierte Tabellen bereitgestellt werden. |
SAP.SQLFlavor
|
SQL-Dialekt für das Quellsystem | "ecc"
|
s4 oder ecc.
Behalten Sie für Testdaten den Standardwert (ecc) bei.
|
SAP.mandt
|
Mandant oder Kunde | "100"
|
Standardmandant oder ‑client für SAP.
Behalten Sie für Testdaten den Standardwert (100) bei.
|
SAP.languages
|
Sprachfilter | ["E","S"]
|
SAP-Sprachcodes (SPRAS), die für relevante Felder (z. B. Namen) verwendet werden sollen. |
SAP.currencies
|
Währungsfilter | ["USD"]
|
SAP-Zielwährungscodes (TCURR) für die Währungsumrechnung. |
Es ist keine Mindestversion von SAP erforderlich. Die ECC-Modelle wurden jedoch auf der aktuellen frühesten unterstützten Version von SAP ECC entwickelt. Unabhängig von der Version sind Unterschiede bei den Feldern zwischen unserem System und anderen Systemen zu erwarten.
Datenmodell
In diesem Abschnitt werden die SAP-Datenmodelle (ECC und S/4HANA) anhand von Entity-Relationship-Diagrammen (ERD) beschrieben.
SAP ECC

SAP S/4 HANA
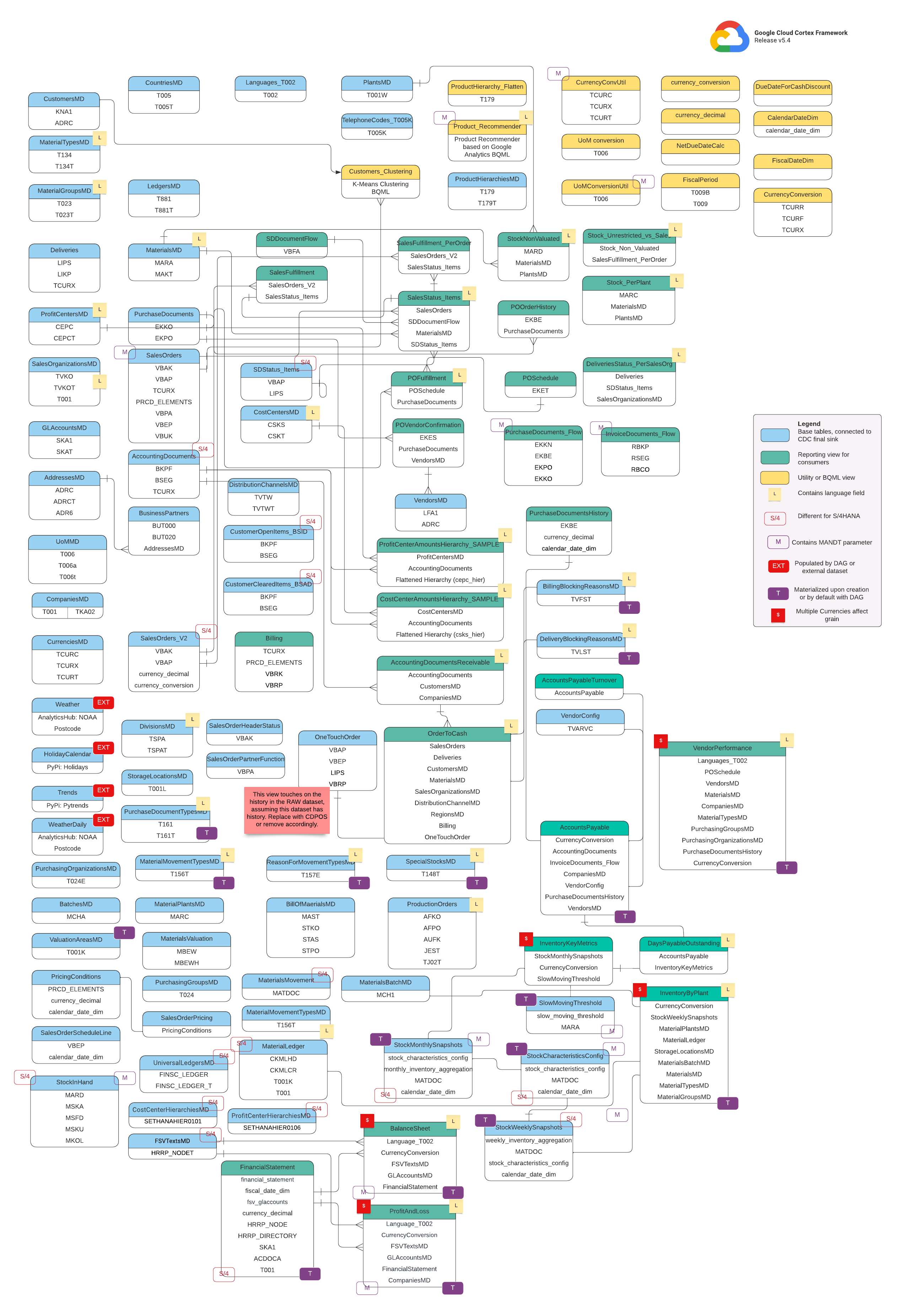
Basisansichten
Das sind die blauen Objekte im ERD. Sie sind Ansichten von CDC-Tabellen ohne Transformationen, abgesehen von einigen Aliasen für Spaltennamen. Scripts finden Sie unter src/SAP/SAP_REPORTING.
Berichtsdatenansichten
Das sind die grünen Objekte im ERD, die die relevanten Dimensionsattribute enthalten, die von den Berichtstabellen verwendet werden. Scripts finden Sie unter src/SAP/SAP_REPORTING.
Hilfs- oder BQML-Ansicht
Das sind die gelben Objekte im ERD. Sie enthalten die verknüpften Fakten und Dimensionen des spezifischen Typs von Ansicht, die für die Datenanalyse und Berichterstellung verwendet wird. Scripts finden Sie unter src/SAP/SAP_REPORTING.
Zusätzliche Tags
Die farbcodierten Tags in diesem ERD stehen für die folgenden Funktionen der Berichtstabellen:
| Tag | Farbe | Beschreibung |
L
|
Gelb | Dieses Tag bezieht sich auf ein Datenelement oder Attribut, das die Sprache angibt, in der die Daten gespeichert oder angezeigt werden. |
S/4
|
Rot | Dieses Tag gibt an, dass bestimmte Attribute spezifisch für SAP S/4HANA sind (dieses Objekt ist möglicherweise nicht in SAP ECC vorhanden). |
MANDT
|
Lila | Dieses Tag gibt an, dass bestimmte Attribute den Parameter „MANDT“ (steht für den Mandanten oder die Mandanten-ID) enthalten, um zu bestimmen, zu welcher Mandanten- oder Unternehmensinstanz ein bestimmter Datensatz gehört. |
EXT
|
Rot | Dieses Tag gibt an, dass bestimmte Objekte durch DAGs oder externe Datasets gefüllt werden. Das bedeutet, dass die markierte Einheit oder Tabelle nicht direkt im SAP-System selbst gespeichert ist, sondern mit einem DAG oder einem anderen Mechanismus extrahiert und in SAP geladen werden kann. |
T
|
Lila | Dieses Tag gibt an, dass bestimmte Attribute automatisch mithilfe des konfigurierten DAG materialisiert werden. |
S
|
Rot | Dieses Tag weist darauf hin, dass die Daten in einer Einheit oder in Tabellen von mehreren Währungen beeinflusst werden. |
Voraussetzungen für die SAP-Replikation
Beachten Sie die folgenden Voraussetzungen für die SAP-Replikationsdaten mit Cortex Framework Data Foundation:
- Datenintegrität: Bei Cortex Framework Data Foundation wird davon ausgegangen, dass SAP-Tabellen mit identischen Feldnamen, ‑typen und Datenstrukturen wie in SAP repliziert werden. Solange die Tabellen im selben Format, mit denselben Feldnamen und derselben Granularität wie in der Quelle repliziert werden, ist kein bestimmtes Replikationstool erforderlich.
- Tabellennamen: BigQuery-Tabellennamen müssen in Kleinbuchstaben erstellt werden.
- Tabellenkonfiguration: Die Liste der von SAP-Modellen verwendeten Tabellen ist in der CDC-Datei (Change Data Capture)
cdc_settings.yamlverfügbar und konfigurierbar. Wenn eine Tabelle während der Bereitstellung nicht aufgeführt ist, schlägt die Bereitstellung der davon abhängigen Modelle fehl. Andere, nicht abhängige Modelle werden jedoch erfolgreich bereitgestellt. - Besondere Überlegungen für BigQuery-Connector für SAP:
- Tabellenzuordnung: Informationen zur Conversion-Option finden Sie in der Dokumentation zur Standardtabellenzuordnung.
- Datensatzkomprimierung deaktivieren: Wir empfehlen, die Datensatzkomprimierung zu deaktivieren, da sie sich sowohl auf die Cortex CDC-Ebene als auch auf das Cortex-Berichtsdataset auswirken kann.
- Metadatenreplikation: Wenn Sie keine Testdaten bereitstellen und während der Bereitstellung keine CDC-DAG-Scripts generieren, muss die Tabelle
DD03Lfür SAP-Metadaten aus SAP im Quellprojekt repliziert werden. Diese Tabelle enthält Metadaten zu Tabellen, z. B. die Liste der Schlüssel, und ist erforderlich, damit der CDC-Generator und der Abhängigkeitsresolver funktionieren. In dieser Tabelle können Sie auch Tabellen hinzufügen, die nicht vom Modell abgedeckt werden, z. B. benutzerdefinierte Tabellen oder Z-Tabellen, damit CDC-Scripts generiert werden können. Umgang mit geringfügigen Abweichungen bei Tabellennamen: Wenn es geringfügige Abweichungen bei einem Tabellennamen gibt, können bei einigen Ansichten Fehler auftreten, weil erforderliche Felder nicht gefunden werden. Das liegt daran, dass SAP-Systeme aufgrund von Versionen oder Add-ons geringfügige Abweichungen aufweisen können oder dass einige Replikationstools Sonderzeichen etwas anders verarbeiten. Wir empfehlen, die Bereitstellung mit
turboMode : falseauszuführen, um die meisten Fehler in einem Versuch zu erkennen. Häufige Probleme:- Bei Feldern, die mit
_beginnen (z. B._DATAAGING), wird das_entfernt. - Felder dürfen in BigQuery nicht mit
/beginnen.
In diesem Fall können Sie die fehlerhafte Ansicht anpassen, um das Feld so auszuwählen, wie es von Ihrem Replikationstool Ihrer Wahl übernommen wird.
- Bei Feldern, die mit
Rohdaten aus SAP replizieren
Die Data Foundation dient dazu, Daten- und Analysemodelle für Berichte und Anwendungen verfügbar zu machen. Die Modelle verwenden die Daten, die aus einem SAP-System mit einem bevorzugten Replikationstool repliziert wurden, z. B. mit den Tools, die in den Leitfäden zur Datenintegration für SAP aufgeführt sind.
Daten aus dem SAP-System (entweder ECC oder S/4HANA) werden in Rohform repliziert.
Die Daten werden direkt von SAP nach BigQuery kopiert, ohne dass sich die Struktur ändert. Sie sind im Wesentlichen ein Spiegelbild der Tabellen in Ihrem SAP-System. In BigQuery werden für das Datenmodell Tabellennamen in Kleinbuchstaben verwendet. Auch wenn Ihre SAP-Tabellen Namen in Großbuchstaben haben (z. B. MANDT), werden sie in BigQuery in Kleinbuchstaben umgewandelt (z. B. mandt).
Verarbeitung von Change Data Capture (CDC)
Wählen Sie einen der folgenden CDC-Verarbeitungsmodi aus, die das Cortex Framework für Replikationstools zum Laden von Datensätzen aus SAP bietet:
- Immer anhängen: Jede Änderung an einem Datensatz wird mit einem Zeitstempel und einem Vorgangsflag (Einfügen, Aktualisieren, Löschen) eingefügt, sodass die letzte Version identifiziert werden kann.
- Update when landing (merge or upsert) (Beim Eintreffen aktualisieren (zusammenführen oder Upsert)): Erstellen Sie beim Eintreffen in der
change data capture processedeine aktualisierte Version eines Datensatzes. Sie führt den CDC-Vorgang in BigQuery aus.
Die Data Foundation von Cortex Framework unterstützt beide Modi. Für „Nur anhängen“ werden jedoch CDC-Verarbeitungsvorlagen bereitgestellt. Einige Funktionen müssen für die Aktualisierung auf der Landingpage auskommentiert werden. Beispiel: OneTouchOrder.sql und alle zugehörigen abhängigen Abfragen. Die Funktion kann durch Tabellen wie CDPOS ersetzt werden.

CDC-Vorlagen für Tools konfigurieren, die im Modus „Immer anhängen“ replizieren
Wir empfehlen dringend, die cdc_settings.yaml entsprechend Ihren Anforderungen zu konfigurieren.
Einige Standardhäufigkeiten können zu unnötigen Kosten führen, wenn das Unternehmen keine so hohe Datenaktualität benötigt. Wenn Sie ein Tool verwenden, das im Append-Always-Modus ausgeführt wird, bietet Cortex Framework Data Foundation CDC-Vorlagen, mit denen die Aktualisierungen automatisiert und eine aktuelle Version der Wahrheit oder des digitalen Zwillings im CDC-verarbeiteten Dataset erstellt werden kann.
Sie können die Konfiguration in der Datei cdc_settings.yaml verwenden, wenn Sie CDC-Verarbeitungsskripts generieren müssen. Informationen zu den Optionen finden Sie unter CDC-Verarbeitung einrichten. Für Testdaten können Sie diese Datei als Standard beibehalten.
Nehmen Sie alle erforderlichen Änderungen an den DAG-Vorlagen entsprechend Ihrer Airflow- oder Cloud Composer-Instanz vor. Weitere Informationen finden Sie unter Cloud Composer-Einstellungen erfassen.
Optional: Wenn Sie Tabellen nach der Bereitstellung einzeln hinzufügen und verarbeiten möchten, können Sie die Datei cdc_settings.yaml so ändern, dass nur die benötigten Tabellen verarbeitet werden. Führen Sie dann den angegebenen Modulaufruf src/SAP_CDC/cloudbuild.cdc.yaml direkt noch einmal aus.
CDC-Verarbeitung einrichten
Während der Bereitstellung können Sie Änderungen in Echtzeit zusammenführen. Dazu verwenden Sie eine Ansicht in BigQuery oder planen einen Zusammenführungs-Vorgang in Cloud Composer (oder einer anderen Instanz von Apache Airflow). Cloud Composer kann die Skripts so planen, dass die Zusammenführungen regelmäßig verarbeitet werden. Die Daten werden bei jeder Ausführung der Zusammenführungsoperationen auf die neueste Version aktualisiert. Häufigere Zusammenführungsoperationen führen jedoch zu höheren Kosten. Passen Sie die geplante Häufigkeit an Ihre geschäftlichen Anforderungen an. Weitere Informationen finden Sie unter Von Apache Airflow unterstützte Zeitplanung.
Das folgende Beispielskript zeigt einen Auszug aus der Konfigurationsdatei:
data_to_replicate:
- base_table: adrc
load_frequency: "@hourly"
- base_table: adr6
target_table: adr6_cdc
load_frequency: "@daily"
Diese Beispielkonfigurationsdatei hat folgende Auswirkungen:
- Erstellen Sie eine Kopie von
SOURCE_PROJECT_ID.REPLICATED_DATASET.adrcinTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adrc, fallsTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adrcnicht vorhanden ist. - Erstellen Sie ein CDC-Skript im angegebenen Bucket.
- Erstellen Sie eine Kopie von
SOURCE_PROJECT_ID.REPLICATED_DATASET.adr6inTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adr6_cdc, fallsTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adr6_cdcnicht vorhanden ist. - Erstellen Sie ein CDC-Skript im angegebenen Bucket.
Wenn Sie DAGs oder Laufzeitansichten erstellen möchten, um Änderungen für Tabellen zu verarbeiten, die in SAP vorhanden sind und nicht in der Datei aufgeführt werden, fügen Sie sie vor der Bereitstellung in diese Datei ein. Das funktioniert, solange die Tabelle DD03L im Quelldataset repliziert wird und das Schema der benutzerdefinierten Tabelle in dieser Tabelle vorhanden ist.
Mit der folgenden Konfiguration wird beispielsweise ein CDC-Script für die benutzerdefinierte Tabelle zztable_customer und eine Laufzeitansicht zum Scannen von Änderungen in Echtzeit für eine andere benutzerdefinierte Tabelle namens zzspecial_table erstellt:
- base_table: zztable_customer
load_frequency: "@daily"
- base_table: zzspecial_table
load_frequency: "RUNTIME"
Beispiel für eine generierte Vorlage
Mit der folgenden Vorlage wird die Verarbeitung von Änderungen generiert. Änderungen wie der Name des Zeitstempelfelds oder zusätzliche Vorgänge können an dieser Stelle vorgenommen werden:
MERGE `${target_table}` T
USING (
SELECT *
FROM `${base_table}`
WHERE
recordstamp > (
SELECT IF(
MAX(recordstamp) IS NOT NULL,
MAX(recordstamp),
TIMESTAMP("1940-12-25 05:30:00+00"))
FROM `${target_table}` )
) S
ON ${p_key}
WHEN MATCHED AND S.operation_flag='D' AND S.is_deleted = true THEN
DELETE
WHEN NOT MATCHED AND S.operation_flag='I' THEN
INSERT (${fields})
VALUES
(${fields})
WHEN MATCHED AND S.operation_flag='U' THEN
UPDATE SET
${update_fields}
Wenn Ihr Unternehmen Erkenntnisse in Echtzeit benötigt und das Replikationstool dies unterstützt, akzeptiert das Bereitstellungstool die Option RUNTIME.
Das bedeutet, dass kein CDC-Script generiert wird. Stattdessen würde eine Ansicht den neuesten verfügbaren Datensatz zur Laufzeit für sofortige Konsistenz scannen und abrufen.
Verzeichnisstruktur für CDC-DAGs und ‑Skripts
Die Cloud Storage-Bucket-Struktur für SAP CDC-DAGs erwartet, dass die SQL-Dateien in /data/bq_data_replication generiert werden, wie im folgenden Beispiel.
Sie können diesen Pfad vor der Bereitstellung ändern. Wenn Sie noch keine Cloud Composer-Umgebung haben, können Sie sie später erstellen und die Dateien in den DAG-Bucket verschieben.
with airflow.DAG("CDC_BigQuery_${base table}",
template_searchpath=['/home/airflow/gcs/data/bq_data_replication/'], ##example
default_args=default_dag_args,
schedule_interval="${load_frequency}") as dag:
start_task = DummyOperator(task_id="start")
copy_records = BigQueryOperator(
task_id='merge_query_records',
sql="${query_file}",
create_disposition='CREATE_IF_NEEDED',
bigquery_conn_id="sap_cdc_bq", ## example
use_legacy_sql=False)
stop_task = DummyOperator (task_id="stop")
start_task >> copy_records >> stop_task
Die Skripts, mit denen Daten in Airflow oder Cloud Composer verarbeitet werden, werden bewusst separat von den Airflow-spezifischen Skripts generiert. So können Sie diese Skripts in ein anderes Tool Ihrer Wahl übertragen.
Für MERGE-Vorgänge erforderliche CDC-Felder
Geben Sie die folgenden Parameter für die automatische Generierung von CDC-Batchprozessen an:
- Quellprojekt + Dataset:Dataset, in das die SAP-Daten gestreamt oder repliziert werden. Damit die CDC-Skripts standardmäßig funktionieren, müssen die Tabellen ein Zeitstempelfeld (mit dem Namen „recordstamp“) und ein Vorgangsfeld mit den folgenden Werten haben, die alle während der Replikation festgelegt werden:
- I: für „Einfügen“.
- U: für „Update“ (Aktualisieren).
- D: für „Löschen“.
- Zielprojekt + Dataset für die CDC-Verarbeitung: Das standardmäßig generierte Skript erstellt die Tabellen aus einer Kopie des Quelldatasets, sofern sie nicht vorhanden sind.
- Replizierte Tabellen: Tabellen, für die die Skripts generiert werden müssen
- Verarbeitungsfrequenz: Gibt in Cron-Notation an, wie häufig die DAGs ausgeführt werden sollen:
- Der Cloud Storage-Ziel-Bucket, in den die CDC-Ausgabedateien kopiert werden.
- Name der Verbindung: Der Name der Verbindung, die von Cloud Composer verwendet wird.
- (Optional) Name der Zieltabelle:Verfügbar, wenn das Ergebnis der CDC-Verarbeitung im selben Dataset wie das Ziel verbleibt.
Leistungsoptimierung für CDC-Tabellen
Bei bestimmten CDC-Datasets kann es sinnvoll sein, die Tabellenpartitionierung und/oder das Tabellenclustering von BigQuery zu nutzen. Diese Entscheidung hängt von den folgenden Faktoren ab:
- Größe und Daten der Tabelle.
- In der Tabelle verfügbare Spalten.
- Echtzeitdaten mit Ansichten sind erforderlich.
- Daten, die als Tabellen materialisiert werden.
Standardmäßig werden bei CDC-Einstellungen keine Tabellenpartitionierung oder Tabellen-Clustering angewendet.
Sie können die Konfiguration selbst vornehmen und an Ihre Bedürfnisse anpassen. Wenn Sie Tabellen mit Partitionen oder Clustern erstellen möchten, aktualisieren Sie die Datei cdc_settings.yaml mit den entsprechenden Konfigurationen. Weitere Informationen finden Sie unter Tabellenpartition und Clustereinstellungen.
- Diese Funktion wird nur angewendet, wenn ein Dataset in
cdc_settings.yamlals Tabelle (z. B.load_frequency = "@daily") und nicht als Ansicht (load_frequency = "RUNTIME") für die Replikation konfiguriert ist. - Eine Tabelle kann sowohl eine partitionierte als auch eine geclusterte Tabelle sein.
Wenn Sie ein Replikationstool verwenden, das Partitionen im Rohdatensatz zulässt, z. B. den BigQuery-Connector für SAP, empfiehlt es sich, zeitbasierte Partitionen in den Rohdatentabellen festzulegen. Der Partitionstyp funktioniert besser, wenn er der Häufigkeit für CDC-DAGs in der cdc_settings.yaml-Konfiguration entspricht. Weitere Informationen finden Sie unter Designüberlegungen für die SAP-Datenmodellierung in BigQuery.
Optional: SAP Inventory Module konfigurieren
Das SAP Inventory-Modul des Cortex Framework enthält die Ansichten InventoryKeyMetrics und InventoryByPlant, die wichtige Informationen zu Ihrem Inventar liefern.
Diesen Ansichten liegen monatliche und wöchentliche Snapshot-Tabellen zugrunde, für die spezielle DAGs verwendet werden. Beide können gleichzeitig ausgeführt werden und beeinträchtigen sich nicht gegenseitig.
So aktualisieren Sie eine oder beide Snapshot-Tabellen:
Aktualisieren Sie
SlowMovingThreshold.sqlundStockCharacteristicsConfig.sql, um den Schwellenwert für langsam drehende Artikel und die Lagerbestandsmerkmale für verschiedene Materialtypen entsprechend Ihren Anforderungen zu definieren.Führen Sie für den anfänglichen Ladevorgang oder die vollständige Aktualisierung die DAGs
Stock_Monthly_Snapshots_InitialundStock_Weekly_Snapshots_Initialaus.Planen oder führen Sie für nachfolgende Aktualisierungen die folgenden DAGs aus:
- Monatliche und wöchentliche Updates:
Stock_Monthly_Snapshots_Periodical_UpdateStock_Weekly_Snapshots_periodical_Update
- Tägliches Update:
Stock_Monthly_Snapshots_Daily_UpdateStock_Weekly_Snapshots_Update_Daily
- Monatliche und wöchentliche Updates:
Aktualisieren Sie zuerst die Zwischenansichten
StockMonthlySnapshotsundStockWeeklySnapshotsund dann die AnsichtenInventoryKeyMetricsundInventoryByPlants, um die aktualisierten Daten zu sehen.
Optional: Ansicht „Texte der Produkthierarchie“ konfigurieren
In der Ansicht „Texte der Produkthierarchie“ werden Materialien und ihre Produkthierarchien zusammengefasst. Die resultierende Tabelle kann verwendet werden, um dem Trends-Add-on eine Liste von Begriffen zu übergeben, für die Interesse im Zeitverlauf abgerufen werden soll. Konfigurieren Sie diese Ansicht so:
- Passen Sie die Ebenen der Hierarchie und die Sprache in der Datei
prod_hierarchy_texts.sqlunter den Markierungen für## CORTEX-CUSTOMERan. Wenn Ihre Produkthierarchie weitere Ebenen enthält, müssen Sie möglicherweise eine zusätzliche SELECT-Anweisung hinzufügen, die der Common Table Expression
h1_h2_h3ähnelt.Je nach Quellsystem sind möglicherweise zusätzliche Anpassungen erforderlich. Wir empfehlen, die Geschäftsanwender oder Analysten frühzeitig in den Prozess einzubeziehen, damit sie diese Probleme erkennen können.
Optional: Ansichten zum Reduzieren der Hierarchie konfigurieren
Ab Version v6.0 unterstützt Cortex Framework das Reduzieren von Hierarchien als Reporting-Ansichten. Dies ist eine erhebliche Verbesserung gegenüber dem alten Hierarchie-Flattener, da jetzt die gesamte Hierarchie vereinfacht wird. Außerdem wird die Leistung durch die Verwendung von S/4-spezifischen Tabellen anstelle von alten ECC-Tabellen deutlich verbessert.
Zusammenfassung der Berichtsdatenansichten
Die folgenden Ansichten beziehen sich auf das Reduzieren von Hierarchien:
| Art der Hierarchie | Tabelle mit nur einer vereinfachten Hierarchie | Ansichten zum Visualisieren einer vereinfachten Hierarchie | Logik für die Integration von Gewinn und Verlust mit dieser Hierarchie |
| Version des Finanzberichts (Financial Statement Version, FSV) | fsv_glaccounts
|
FSVHierarchyFlattened
|
ProfitAndLossOverview
|
| Profitcenter | profit_centers
|
ProfitCenterHierarchyFlattened
|
ProfitAndLossOverview_ProfitCenterHierarchy
|
| Kostenstelle | cost_centers
|
CostCenterHierarchyFlattened
|
ProfitAndLossOverview_CostCenterHierarchy
|
Beachten Sie Folgendes, wenn Sie Ansichten zum Reduzieren der Hierarchie verwenden:
- Die Ansichten mit vereinfachter Hierarchie sind funktional mit den Tabellen identisch, die von der alten Lösung zum Vereinfachen von Hierarchien generiert werden.
- Die Übersichtsansichten werden nicht standardmäßig bereitgestellt, da sie nur die BI-Logik veranschaulichen sollen. Der Quellcode befindet sich im Verzeichnis
src/SAP/SAP_REPORTING.
Hierarchie zusammenführen
Je nach Hierarchie, mit der Sie arbeiten, sind die folgenden Eingabeparameter erforderlich:
| Art der Hierarchie | Erforderlicher Parameter | Quellfeld (ECC) | Quellfeld (S4) |
| Version des Finanzberichts (Financial Statement Version, FSV) | Kontenplan | ktopl
|
nodecls
|
| Hierarchiename | versn
|
hryid
|
|
| Gewinncenter | Klasse des Sets | setclass
|
setclass
|
| Organisationseinheit: Kontrollbereich oder zusätzlicher Schlüssel für den Satz. | subclass
|
subclass
|
|
| Kostenstelle | Klasse des Sets | setclass
|
setclass
|
| Organisationseinheit: Kontrollbereich oder zusätzlicher Schlüssel für den Satz. | subclass
|
subclass
|
Wenn Sie sich nicht sicher sind, welche Parameter Sie verwenden sollen, fragen Sie einen SAP-Berater für Finanzwesen oder Controlling.
Nachdem die Parameter erfasst wurden, aktualisieren Sie die ## CORTEX-CUSTOMER-Kommentare in den entsprechenden Verzeichnissen entsprechend Ihren Anforderungen:
| Art der Hierarchie | Code-Speicherort |
| Version des Finanzberichts (Financial Statement Version, FSV) | src/SAP/SAP_REPORTING/local_k9/fsv_hierarchy
|
| Profitcenter | src/SAP/SAP_REPORTING/local_k9/profitcenter_hierarchy
|
| Kostenstelle | src/SAP/SAP_REPORTING/local_k9/costcenter_hierarchy
|
Aktualisieren Sie gegebenenfalls die ## CORTEX-CUSTOMER-Kommentare in den relevanten Berichtsansichten im Verzeichnis src/SAP/SAP_REPORTING.
Lösungsdetails
Die folgenden Quelltabellen werden für die Hierarchievereinfachung verwendet:
| Art der Hierarchie | Quelltabelle (ECC) | Quelltabelle (S4) |
| Version des Finanzberichts (Financial Statement Version, FSV) |
|
|
| Profitcenter |
|
|
| Kostenstelle |
|
|
Hierarchien visualisieren
Mit der Lösung zum Vereinfachen der SAP-Hierarchie von Cortex wird die gesamte Hierarchie vereinfacht. Wenn Sie eine visuelle Darstellung der geladenen Hierarchie erstellen möchten, die mit der Darstellung in der SAP-Benutzeroberfläche vergleichbar ist, fragen Sie eine der Ansichten zum Visualisieren von vereinfachten Hierarchien mit der Bedingung IsLeafNode=True ab.
Von der alten Lösung zum Reduzieren der Hierarchie migrieren
Wenn Sie von der Legacy-Lösung zum Reduzieren der Hierarchie vor Cortex v6.0 migrieren möchten, ersetzen Sie die Tabellen wie in der folgenden Tabelle dargestellt. Prüfen Sie die Feldnamen auf Richtigkeit, da einige Feldnamen leicht geändert wurden. Beispiel: prctr in cepc_hier ist jetzt profitcenter in der Tabelle profit_centers.
| Art der Hierarchie | Ersetzen Sie diese Tabelle: | Mit: |
| Version des Finanzberichts (Financial Statement Version, FSV) | ska1_hier
|
fsv_glaccounts
|
| Profitcenter | cepc_hier
|
profit_centers
|
| Kostenstelle | csks_hier
|
cost_centers
|
Optional: SAP-Finanzmodul konfigurieren
Das SAP Finance-Modul des Cortex Framework umfasst die Ansichten FinancialStatement, BalanceSheet und ProfitAndLoss, die wichtige Finanzinformationen liefern.
So aktualisieren Sie diese Finanztabellen:
Für den anfänglichen Ladevorgang
- Prüfen Sie nach der Bereitstellung, ob Ihr CDC-Dataset richtig gefüllt ist. Führen Sie dazu bei Bedarf alle CDC-DAGs aus.
- Achten Sie darauf, dass Ansichten zum Reduzieren der Hierarchieebenen für die von Ihnen verwendeten Hierarchietypen (FSV, Kostenstelle und Gewinnzentrum) richtig konfiguriert sind.
Führen Sie den DAG
financial_statement_initial_loadaus.Wenn sie als Tabellen bereitgestellt werden (empfohlen), aktualisieren Sie die folgenden Elemente in der angegebenen Reihenfolge, indem Sie die entsprechenden DAGs ausführen:
Financial_StatementsBalanceSheetsProfitAndLoss
Regelmäßige Aktualisierung
- Achten Sie darauf, dass Ansichten zum Reduzieren der Hierarchieebenen für die von Ihnen verwendeten Hierarchietypen (FSV, Kostenstelle und Gewinnzentrum) richtig konfiguriert und auf dem neuesten Stand sind.
Planen oder führen Sie den DAG
financial_statement_periodical_loadaus.Wenn sie als Tabellen bereitgestellt werden (empfohlen), aktualisieren Sie die folgenden Elemente in der angegebenen Reihenfolge, indem Sie die entsprechenden DAGs ausführen:
Financial_StatementsBalanceSheetsProfitAndLoss
Wenn Sie die Daten aus diesen Tabellen visualisieren möchten, sehen Sie sich die folgenden Übersichtsansichten an:
ProfitAndLossOverview.sql, wenn Sie die FSV-Hierarchie verwenden.ProfitAndLossOverview_CostCenter.sql, wenn Sie die Kostenstellenhierarchie verwenden.ProfitAndLossOverview_ProfitCenter.sql, wenn Sie die Profitcenter-Hierarchie verwenden.
Optional: Taskabhängige DAGs aktivieren
Das Cortex Framework bietet optional empfohlene Abhängigkeitseinstellungen für die meisten SAP-SQL-Tabellen (ECC und S/4 HANA), wobei alle abhängigen Tabellen durch einen einzelnen DAG aktualisiert werden können. Sie können sie weiter anpassen. Weitere Informationen finden Sie unter Aufgabenabhängige DAGs.
Nächste Schritte
- Weitere Informationen zu anderen Datenquellen und Arbeitslasten finden Sie unter Datenquellen und Arbeitslasten.
- Weitere Informationen zu den Schritten für die Bereitstellung in Produktionsumgebungen finden Sie unter Voraussetzungen für die Bereitstellung der Cortex Framework Data Foundation.