Integration mit Oracle EBS
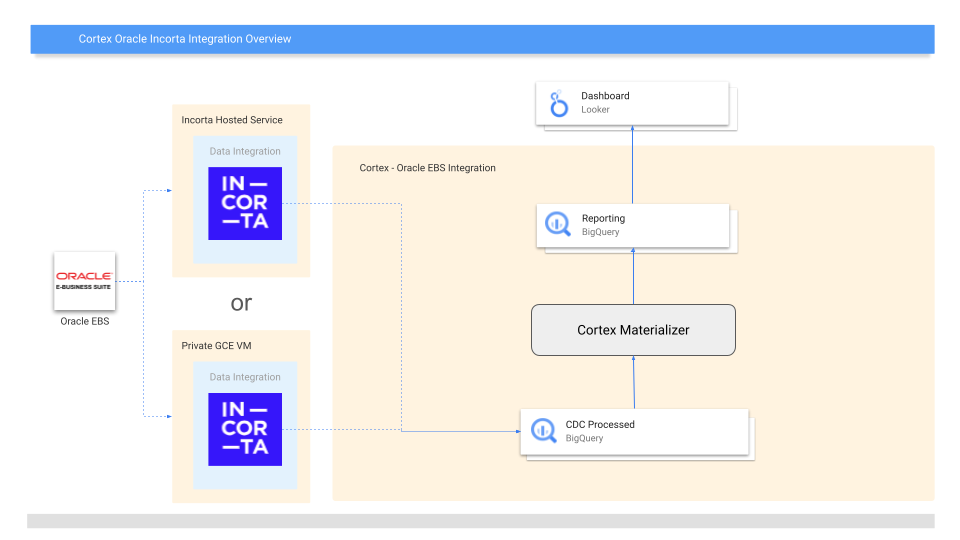
Die Oracle EBS-Integration (E-Business Suite) unterstützt Order-to-Cash-Datenmodelle mit Datenaufnahme mit Incorta. Incorta verwendet eine gehostete oder private Instanz, um die Daten aus Oracle in ein BigQuery-CDC-Dataset aufzunehmen und die CDC-Verarbeitung zu verarbeiten. Anschließend transformiert und materialisiert das Cortex-Framework die CDC-Daten mithilfe von Cloud Composer in Berichts-Assets, um BigQuery-Jobs zu orchestrieren.
Das folgende Diagramm zeigt, wie Oracle EBS-Daten über die Oracle EBS-Betriebslast verfügbar sind:
Konfiguration des Deployments
In der folgenden Tabelle finden Sie die Parameter für die Konfiguration der Oracle EBS-Arbeitslast:
In der Datei config.json werden die Einstellungen konfiguriert, die für die Übertragung von Daten aus einer beliebigen Datenquelle erforderlich sind, einschließlich Oracle EBS. Diese Datei enthält die folgenden Parameter für Oracle EBS:
| Parameter | Bedeutung | Standardwert | Beschreibung | Übereinstimmendes Oracle-Quellfeld |
|---|---|---|---|---|
OracleEBS.itemCategorySetIDs |
Artikelkategoriengruppen | [1100000425] |
Liste der Sets, die zur Kategorisierung von Elementen verwendet werden sollen. | MTL_ITEM_CATEGORIES.CATEGORY_SET_ID |
OracleEBS.currencyConversionType |
Art der Währungsumrechnung | "Corporate" |
Art der Währungsumrechnung, die in zusammengefassten Tabellen verwendet werden soll. | GL_DAILY_RATES.CONVERSION_TYPE |
OracleEBS.currencyConversionTargets |
Zielvorhaben für die Währungsumrechnung | ["USD"] |
Liste der Zielwährungen, die in zusammengefasste Tabellen aufgenommen werden sollen. | GL_DAILY_RATES.TO_CURRENCY |
OracleEBS.languages |
Sprachen | ["US"] |
Liste der Sprachen, in denen Übersetzungen von Feldern wie Artikelbeschreibungen angezeigt werden sollen. | FND_LANGUAGES.LANGUAGE_CODE |
OracleEBS.datasets.cdc |
CDC-Dataset | - | CDC-Dataset | - |
OracleEBS.datasets.reporting |
Dataset für die Berichterstellung | "REPORTING_OracleEBS" |
Dataset für die Berichterstellung | - |
Datenaufnahme
Wenden Sie sich an einen Incorta-Kundenbetreuer und lesen Sie den Einrichtungsleitfaden für Oracle EBS für Google Cortex. Dort finden Sie weitere Informationen zum Aufnehmen von Daten aus Oracle in BigQuery.
Empfohlene Konfigurationen
In Incorta können Datenaufnahmejobs in verschiedenen Intervallen geplant werden. Für eine optimale Leistung und Datenaktualität empfehlen wir jedoch, die Ausführung von Incorta-Datenaufnahmejobs täglich zu planen. Wenn für Ihren Anwendungsfall gelöschte Daten verarbeitet werden müssen, aktivieren Sie diese. Folgen Sie dazu der Anleitung im Abschnitt Handling source deletes (Löschen von Quellen verwalten) der Incorta-Dokumentation.
Berichtskonfigurationen
In diesem Abschnitt werden die erforderlichen Berichtskonfigurationen für Ihre Umgebung beschrieben.
Cloud Composer Airflow-Verbindung
Erstellen Sie eine BigQuery Airflow-Verbindung mit dem Namen oracleebs_reporting_bq, die vom BigQuery-Bearbeiter zum Ausführen von Berichtstransformationen verwendet wird. Weitere Informationen finden Sie in der Dokumentation zum Verwalten von Airflow-Verbindungen.
Materializer-Einstellungen
Die Einstellungen für die Materialisierung finden Sie unter src/OracleEBS/config/reporting_settings.yaml.
Standardmäßig werden die Tabellen Dimension, Header und Zusammenfassung täglich materialisiert. Die Tabellen der Berichtsebene sind ebenfalls nach Datum partitioniert.
Partitionen und Clustering können bei Bedarf angepasst werden. Weitere Informationen finden Sie unter Clustereinstellungen und Tabellenpartition.
Datenmodell
In diesem Abschnitt wird das logische Datenmodell „Order to Cash“ von Oracle EBS beschrieben. In den einzelnen Unterabschnitten wird das folgende ERD (Entity Relationship Diagram, Entitätsbeziehungsdiagramm) für Oracle EBS erläutert.
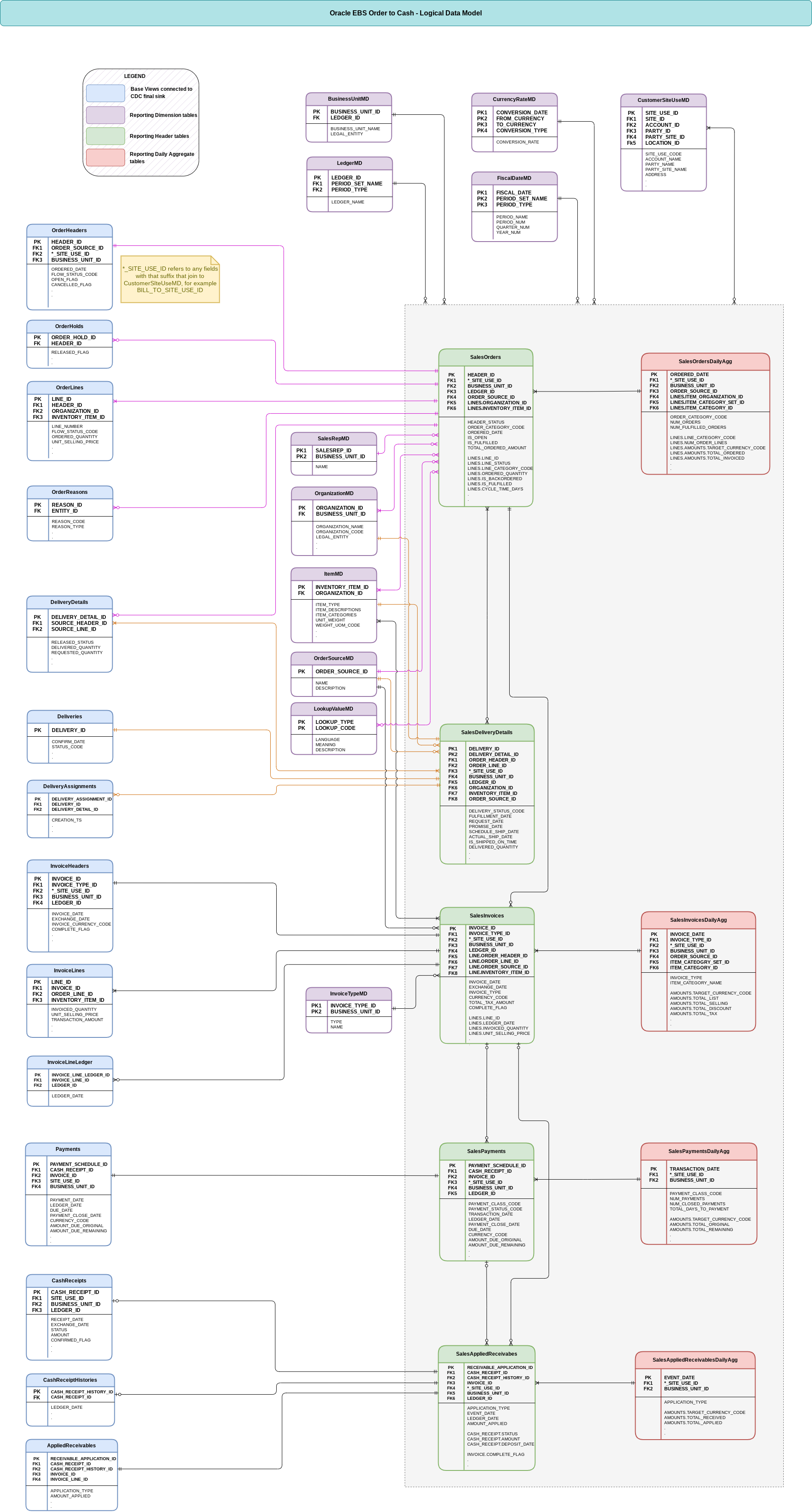
Ansichten mit Basisdaten
Dies sind die blauen Objekte in der ERD. Sie sind Ansichten auf CDC-Tabellen ohne andere Transformationen als einige Aliasse für Spaltennamen.
Dimensionstabellen
Das sind die lilafarbenen Objekte in der ERD. Sie enthalten die relevanten Dimensionsattribute, die in den Berichtstabellen verwendet werden. Standardmäßig werden diese Dimensionen gegebenenfalls anhand der Parameterwerte der Bereitstellungskonfiguration gefiltert. Bei dieser Einbindung wird auch die standardmäßig bereitgestellte Cortex K9-Dimension „Gregorianischer Kalender“ für Datumsattribute verwendet.
Kopfzeilentabellen
Dies sind die grünen Objekte in der ERD. Sie enthalten die zusammengeführten Fakten und Dimensionen, die Geschäftsentitäten wie Bestellungen und Rechnungen auf Headerebene beschreiben. Die Kopftabellen sind nach einem primären Ereignisdatum partitioniert, das jedem Rechtssubjekt entspricht, z. B. ORDERED_DATE oder INVOICE_DATE.
Verschachtelte und wiederkehrende Zeilen
Die Tabellen SalesOrders und SalesInvoices enthalten verschachtelte wiederkehrende Felder mit dem Namen LINES. In diesen Feldern werden die verschiedenen Bestellzeilen und Rechnungszeilen unter den zugehörigen Überschriften gruppiert. Verwenden Sie den Operator UNNEST, um diese verschachtelten Felder abzufragen und die Elemente in Zeilen zusammenzufassen, wie in den bereitgestellten Beispielscripts (src/OracleEBS/src/reporting/ddls/samples/) gezeigt.
Verschachtelte und wiederkehrende Attribute
Einige Tabellen enthalten zusätzliche verschachtelte wiederkehrende Felder wie ITEM_CATEGORIES oder ITEM_DESCRIPTIONS, für die mehrere Werte desselben Attributs auf die Entität zutreffen können. Wenn Sie diese verschachtelten Attribute aufheben, sollten Sie auf einen einzelnen Attributwert filtern, um eine zu hohe Anzahl von Messwerten zu vermeiden.
Angewandte Forderungen
SalesAppliedReceivables ist eine einzigartige Tabelle, da die Entitäten entweder auf einzelne Rechnungen oder auf eine Rechnung mit einem Beleg verweisen können. Daher gibt es verschachtelte (aber nicht wiederholte) Felder vom Typ INVOICE und CASH_RECEIPT, wobei das Feld CASH_RECEIPT nur ausgefüllt wird, wenn APPLICATION_TYPE = 'CASH'.
Aggregierte Tabellen
Dies sind die roten Objekte in der ERD. Sie werden aus den Kopftabellen bis zu täglichen Messwerten aggregiert. Jede dieser Tabellen wird außerdem nach einem primären Ereignisdatum partitioniert. Die zusammengefassten Tabellen enthalten nur additive Messwerte (z. B. Anzahl, Summen) und keine Messwerte wie Durchschnittswerte und Verhältnisse. Das bedeutet, dass Nutzer die nicht additiven Messwerte ableiten müssen, damit sie bei der Aggregation auf eine höhere Granularität, z. B. auf Monatsbasis, korrekt abgeleitet werden können.
Sehen Sie sich Beispielscripts wie src/OracleEBS/src/reporting/ddls/samples/SalesOrderAggMetrics.sql an.
Beträge der Währungsumrechnung
In jeder zusammengefassten Tabelle wird mithilfe der Dimension CurrencyRateMD ein verschachteltes wiederholtes Feld von AMOUNTS erstellt, das Währungsmesswerte enthält, die in jede der in der Bereitstellungskonfiguration angegebenen Zielwährungen umgerechnet wurden.
Wenn Sie diese Messwerte verwenden, sollten Sie für Berichte eine einzelne Zielwährung oder eine Gruppe von Zielwährungen filtern, um eine Überzählung zu vermeiden. Das ist auch in den Beispielscripts wie src/OracleEBS/src/reporting/ddls/samples/SalesOrderAggMetrics.sql zu sehen.
Verschachtelte Zeilenattribute und ‑messwerte
Die Tabelle SalesOrdersDailyAgg enthält ein verschachteltes wiederholtes Feld namens LINES, um zwischen Attributen und Messwerten auf Zeilenebene (z. B. ITEM_CATEGORY_NAME und AMOUNTS) und Attributen und Messwerten auf Headerebene (z. B. BILL_TO_CUSTOMER_NAME und NUM_ORDERS) zu unterscheiden. Achten Sie darauf, diese Granularitäten separat abzufragen, um eine Überzählung zu vermeiden.
Auch in Rechnungen gibt es Überschriften und Zeilen. Die Tabelle SalesInvoicesDailyAgg enthält jedoch nur Messwerte auf Zeilenebene und folgt daher nicht derselben Struktur wie SalesOrdersDailyAgg.
Nächste Schritte
- Weitere Informationen zu anderen Datenquellen und Arbeitslasten finden Sie unter Datenquellen und Arbeitslasten.
- Weitere Informationen zu den Schritten für die Bereitstellung in Produktionsumgebungen finden Sie unter Voraussetzungen für die Bereitstellung der Cortex Framework Data Foundation.