Integration mit Meta
Auf dieser Seite werden die erforderlichen Konfigurationen beschrieben, um Daten von Meta (Facebook und Instagram Ads) als Datenquelle der Marketing-Arbeitslast der Cortex Framework Data Foundation zu verwenden.
Meta ist ein Technologieunternehmen, das mehrere beliebte Onlineplattformen besitzt. Cortex Framework integriert Anzeigendaten von Instagram und Facebook, um sie zu analysieren, mit anderen Datenquellen zu kombinieren und mithilfe von KI detailliertere Informationen zu erhalten und Ihre Marketingstrategie zu optimieren.
Das folgende Diagramm zeigt, wie Meta-Marketingdaten über die Marketing-Arbeitslast der Cortex Framework Data Foundation verfügbar sind:
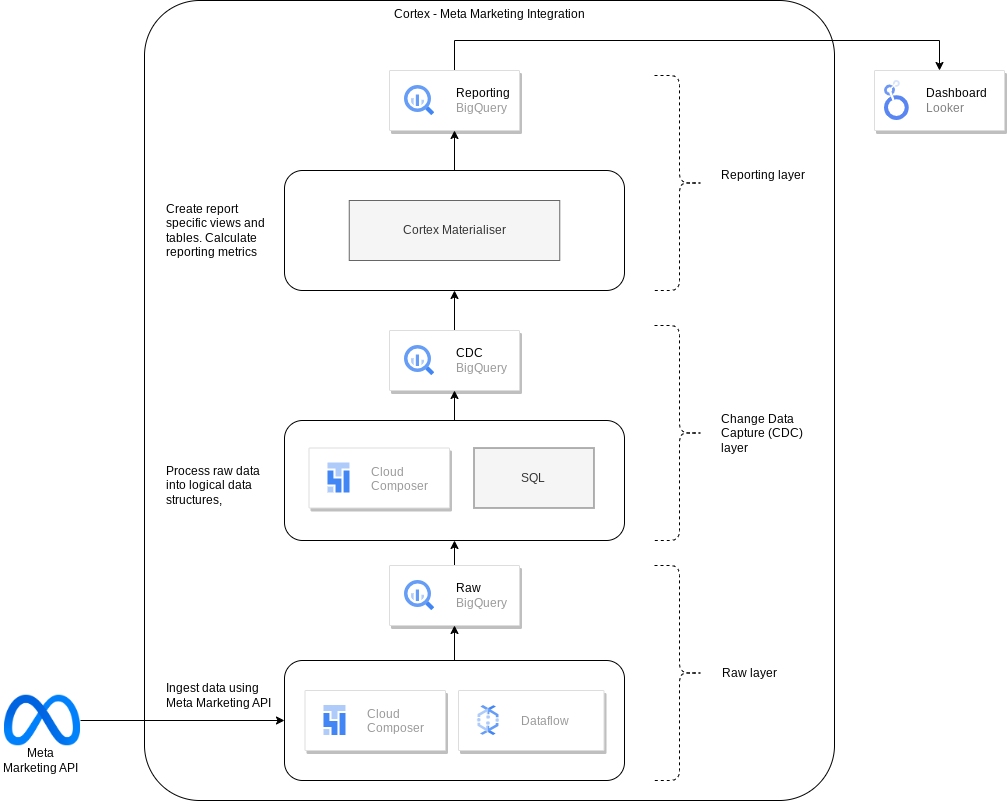
Konfigurationsdatei
In der Datei config.json werden die Einstellungen konfiguriert, die für die Verbindung zu Datenquellen zur Übertragung von Daten aus verschiedenen Arbeitslasten erforderlich sind. Diese Datei enthält die folgenden Parameter für Meta:
"marketing": {
"deployMeta": true,
"Meta": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_Meta"
}
}
}
In der folgenden Tabelle wird der Wert für jeden Marketingparameter beschrieben:
| Parameter | Bedeutung | Standardwert | Beschreibung |
marketing.deployMeta
|
Metadaten bereitstellen | true
|
Führen Sie die Bereitstellung für die Datenquelle von Meta aus. |
marketing.Meta.deployCDC
|
CDC-Scripts für Meta bereitstellen | true
|
Meta CDC-Verarbeitungsscripts generieren, die als DAGs in Cloud Composer ausgeführt werden |
marketing.Meta.datasets.cdc
|
CDC-Datensatz für Meta | CDC-Datensatz für Meta. | |
marketing.Meta.datasets.raw
|
Rohdatensatz für Meta | Rohdatensatz für Meta. | |
marketing.Meta.datasets.reporting
|
Datensatz für Meta-Berichte | "REPORTING_Meta"
|
Datensatz für Meta-Berichte. |
Datenmodell
In diesem Abschnitt wird das Datenmodell von Meta anhand eines Entitätsbeziehungsdiagramms (ERD) beschrieben.
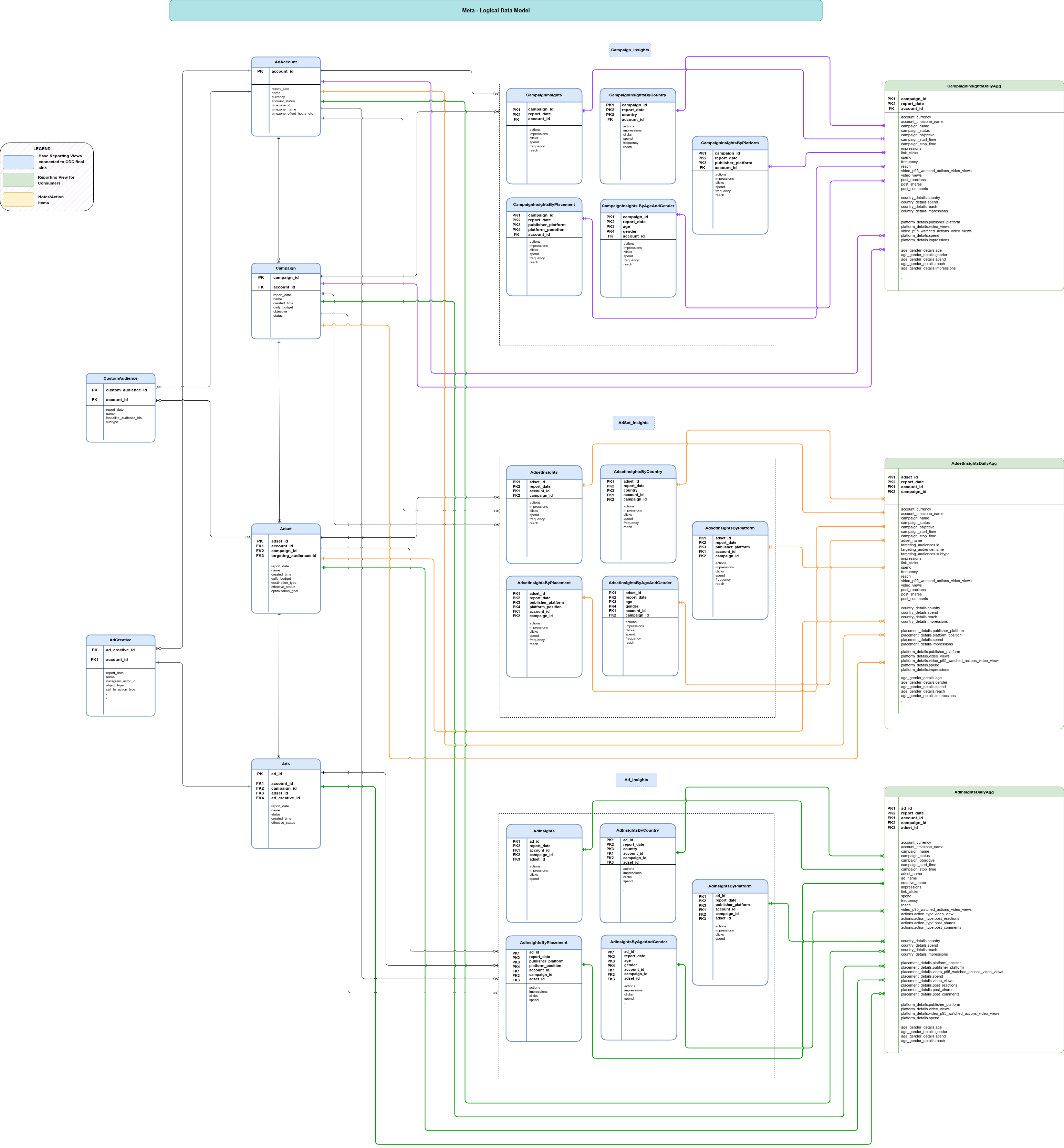
Basisansichten
Dies sind die blauen Objekte in der ERD und sind Ansichten auf CDC-Tabellen mit minimalen Transformationen, um komplexe Datenstrukturen zu entpacken. Scripts in src/marketing/src/Meta/src/reporting/ddls ansehen
Berichtsdatenansichten
Dies sind die grünen Objekte in der ERD und Berichtsansichten, die zusammengefasste Messwerte enthalten. Scripts in src/marketing/src/Meta/src/reporting/ddls ansehen
API-Verbindung
Die Datenaufnahmevorlagen im Cortex-Framework für Meta verwenden die Meta Marketing API, um Berichtsattribute und ‑messwerte abzurufen. Die aktuellen Vorlagen verwenden die Version 21.0.
Meta erzwingt eine dynamische Ratenbegrenzung bei Abfragen der Marketing API. Wenn das Ratenlimit erreicht wird, werden DAGs für die Datenaufnahme von der Quelle in den Rohdatenspeicher möglicherweise nicht erfolgreich abgeschlossen. In solchen Fällen werden im Protokoll entsprechende Fehlermeldungen angezeigt. Bei der nächsten Ausführung der DAGs werden dann alle fehlenden Daten nachträglich geladen.
Die Meta Marketing API bietet zwei Zugriffsebenen: „Basic“ und „Standard“. Die Standardstufe bietet ein viel höheres Limit und wird empfohlen, wenn Sie die Datenaufnahme von „Quelle zu Rohdaten“ intensiv nutzen möchten. Weitere Informationen zu diesen Limits und dazu, wie Sie eine höhere Zugriffsebene erhalten, finden Sie in der Meta-Dokumentation.
Wenn Sie Zugriff auf die Standardstufe haben, können Sie den Wert der Einstellung next_request_delay_sec unter src/Meta/src/raw/pipelines/config.ini senken, um die Ladezeiten zu verkürzen.
API-Zugriff und Zugriffstoken
Die folgenden Schritte sind im Meta Business Manager und in der Developer Console erforderlich, um Daten aus Meta in das Cortex Framework zu übertragen.
- Eine App auswählen. Sie können eine neue App erstellen, die mit dem Unternehmenskonto verknüpft ist. Ihre App muss vom Typ
Businesssein. - App-Berechtigungen einrichten Sie müssen der App als Administrator zugewiesen sein, bevor Sie damit Tokens erstellen können. Weitere Informationen finden Sie in der Dokumentation zu App-Rollen. Weisen Sie Ihrer App relevante Assets (Konten) zu.
Erstellen Sie ein Zugriffstoken. Zugriffstokens sind für den Zugriff auf die Meta Marketing API erforderlich. Sie sind immer mit einer App und einem Nutzer verknüpft. Sie können das Token entweder mit einem Systemnutzer oder mit Ihrer eigenen Anmeldung erstellen.
- Erstellen Sie einen Administrator-Systemnutzer.
- Generiere ein Token. Notieren Sie sich das Token, sobald es generiert wurde, da es nicht wieder abgerufen werden kann, wenn Sie die Seite verlassen.
- Gewähren Sie Ihrem Token die Berechtigungen
ads_readundbusiness_management, um auf die unterstützten Objekte zuzugreifen.
Folgen Sie der Cloud Composer-Dokumentation, um Secret Manager in Cloud Composer zu aktivieren. Erstellen Sie dann ein Secret mit dem Namen
cortex_meta_access_tokenund speichern Sie das im vorherigen Schritt generierte Token als Inhalt.
Datenaktualität und Verzögerung
Im Allgemeinen ist die Datenaktualität für Cortex Framework-Datenquellen durch die Möglichkeiten der Upstream-Verbindung und die Häufigkeit der DAG-Ausführung begrenzt. Passen Sie die Ausführungshäufigkeit des DAG an die Upstream-Frequenz, die Ressourcenbeschränkungen und Ihre Geschäftsanforderungen an.
Mit der Meta Marketing API sind die meisten Daten (außer Conversions) nahezu in Echtzeit verfügbar. Sie können jedoch bis zu 28 Tage nach dem Ereignis angepasst werden.
Berechtigungen für Cloud Composer-Verbindungen
Erstellen Sie die folgenden Verbindungen in Cloud Composer. Weitere Informationen finden Sie in der Dokumentation zum Verwalten von Airflow-Verbindungen.
| Verbindungsname | Purpose |
meta_raw_dataflow
|
Für Meta Marketing API > BigQuery-Raw-Dataset |
meta_cdc_bq
|
Für die Übertragung von Rohdatensätzen > CDC-Datensätzen |
meta_reporting_bq
|
Für CDC-Datensatz > Datenübertragung für Berichtsdatensatz |
Berechtigungen für das Cloud Composer-Dienstkonto
Gewähren Sie dem in Cloud Composer verwendeten Dienstkonto (wie in der meta_raw_dataflow-Verbindung konfiguriert) Dataflow-Berechtigungen.
Weitere Informationen finden Sie in der Dataflow-Dokumentation. Das Dienstkonto benötigt außerdem die Berechtigung Secret Manager Secret Accessor. Weitere Informationen finden Sie in der Dokumentation zur Zugriffssteuerung.
Anfrageparameter
Das Verzeichnis src/Meta/config/request_parameters enthält eine API-Anfragespezifikationsdatei für jedes Entitätselement, das aus der Meta Marketing API extrahiert wird. Jede Anfragedatei enthält eine Liste der Felder, die aus der Meta Marketing API abgerufen werden sollen, ein Feld pro Zeile. Weitere Informationen finden Sie in der Meta Marketing API-Referenz.
Aufnahmeeinstellungen
Sie können die Source to Raw- und Raw to CDC-Datenpipelines über die Einstellungen in der Datei src/Meta/config/ingestion_settings.yaml steuern.
In diesem Abschnitt werden die Parameter der einzelnen Datenpipelines beschrieben.
Von der Quelle zu Rohtabellen
In diesem Abschnitt finden Sie Einträge, mit denen gesteuert wird, welche Entitäten von APIs abgerufen werden und wie. Jeder Eintrag entspricht einer Meta Marketing API-Entität. Basierend auf dieser Konfiguration erstellt das Cortex-Framework Airflow-DAGs, die Dataflow-Pipelines ausführen, um Daten mithilfe von Meta Marketing APIs abzurufen.
Datei src/Meta/src/raw/pipelines/config.ini steuert einige Verhaltensweisen des Cloud Composer-DAG und die Verwendung von Meta Marketing APIs.
Beschreibungen der einzelnen Parameter in der Datei
Die folgenden Parameter steuern die Einstellungen für Source to Raw für jeden Eintrag:
| Parameter | Beschreibung |
base_table
|
Tabelle im Rohdatensatz, in der die abgerufenen Daten gespeichert werden (z. B. customer).
|
load_frequency
|
Wie oft wird ein DAG für diese Aktion ausgeführt, um Daten von Meta abzurufen. Weitere Informationen zu den möglichen Werten finden Sie in der Airflow-Dokumentation. |
object_endpoint
|
API-Endpunktpfad (z. B. campaigns für den Endpunkt /{account_id}/campaigns)
|
entity_type
|
Tabellentyp (muss einer der folgenden sein: fact, dimension oder addaccount)).
|
object_id_column
|
Spalten (durch Komma getrennt), die einen eindeutigen Datensatz für diese Tabelle bilden. Nur erforderlich, wenn entity_type fact ist.
|
breakdowns
|
Optional:Aufschlüsselungsspalten (durch Komma getrennt) für Statistikendpunkte. Gilt nur, wenn entity_type fact ist.
|
action_breakdowns
|
Optional:Spalten für die Aufschlüsselung von Aktionen (durch Kommas getrennt) für Statistikendpunkte. Gilt nur, wenn entity_type fact ist.
|
partition_details
|
Optional:Wenn diese Tabelle aus Leistungsgründen partitioniert werden soll. Weitere Informationen finden Sie unter Tabellenpartition. |
cluster_details
|
Optional:Wenn Sie möchten, dass diese Tabelle aus Gründen der Leistung gruppiert wird. Weitere Informationen finden Sie unter Clustereinstellungen. |
Rohdaten in CDC-Tabellen
In diesem Abschnitt werden die Einträge beschrieben, mit denen gesteuert wird, wie Daten aus Rohtabellen in CDC-Tabellen verschoben werden. Jeder Eintrag entspricht einer Rohtabelle, die wiederum dem Meta API-Entitätstyp entspricht.
Die folgenden Parameter steuern die Einstellungen für Raw to CDC für jeden Eintrag:
| Parameter | Beschreibung |
base_table
|
Tabelle, in der Rohdaten repliziert wurden. In einer Tabelle mit demselben Namen im CDC-Dataset werden die Rohdaten nach der CDC-Transformation gespeichert (z. B. campaign_insights).
|
row_identifiers
|
Spalten (durch Komma getrennt), die einen eindeutigen Datensatz für diese Tabelle bilden. |
load_frequency
|
Gibt an, wie oft ein DAG für diese Entität ausgeführt wird, um die CDC-Tabelle zu füllen. Weitere Informationen zu den möglichen Werten finden Sie in der Airflow-Dokumentation. |
partition_details
|
Optional:Wenn diese Tabelle aus Leistungsgründen partitioniert werden soll. Weitere Informationen finden Sie unter Tabellenpartition. |
cluster_details
|
Optional:Wenn Sie möchten, dass diese Tabelle aus Gründen der Leistung gruppiert wird. Weitere Informationen finden Sie unter Clustereinstellungen. |
CDC-Tabellenschema
Bei Metadaten werden alle Felder in der Rohdatenebene im Stringformat gespeichert. In der CDC-Ebene werden primitive Typen in relevante Geschäftsdatentypen konvertiert und alle komplexen Typen werden im BigQuery-JSON-Format gespeichert.
Um diese Konvertierung zu ermöglichen, enthält das Verzeichnis src/Meta/config/table_schema eine Schemadatei für jedes im Abschnitt raw_to_cdc_tables angegebene Element. Darin wird erläutert, wie jede BigQuery-Raw-Tabelle in eine CDC-Tabelle umgewandelt wird.
Jede Schemadatei enthält drei Spalten:
SourceField: Feldname der Rohtabelle für diese Entität.TargetField: Spaltenname in der CDC-Tabelle für diese Entität.DataType: Datentyp jedes Felds der CDC-Tabelle.
Berichtseinstellungen
Mit der Datei „Berichtseinstellungen“ (src/Meta/config/reporting_settings.yaml) können Sie konfigurieren und steuern, wie Cortex Daten für die Meta-Schicht der endgültigen Berichterstellung generiert. In dieser Datei wird festgelegt, wie BigQuery-Objekte der Berichtsschicht (Tabellen, Ansichten, Funktionen oder gespeicherte Prozeduren) generiert werden.
Weitere Informationen finden Sie unter Datei mit Berichtseinstellungen anpassen.
Nächste Schritte
- Weitere Informationen zu anderen Datenquellen und Arbeitslasten finden Sie unter Datenquellen und Arbeitslasten.
- Weitere Informationen zu den Schritten für die Bereitstellung in Produktionsumgebungen finden Sie unter Voraussetzungen für die Bereitstellung der Cortex Framework Data Foundation.