Einbindung in LiveRamp
Auf dieser Seite werden die erforderlichen Konfigurationen beschrieben, um Daten von LiveRamp als Datenquelle der Marketing-Arbeitslast der Cortex Framework Data Foundation zu verwenden.
LiveRamp ist eine Plattform für die datenbasierte Zusammenarbeit, mit der Unternehmen ihre Daten verknüpfen, steuern und aktivieren können, um die Kundenerfahrung zu verbessern und bessere Geschäftsergebnisse zu erzielen. Cortex Framework bietet die Tools und die Plattform, um diese Daten zu analysieren, mit anderen Datenquellen zu kombinieren und mithilfe von KI detailliertere Informationen zu gewinnen und Ihre Marketingstrategie zu optimieren.
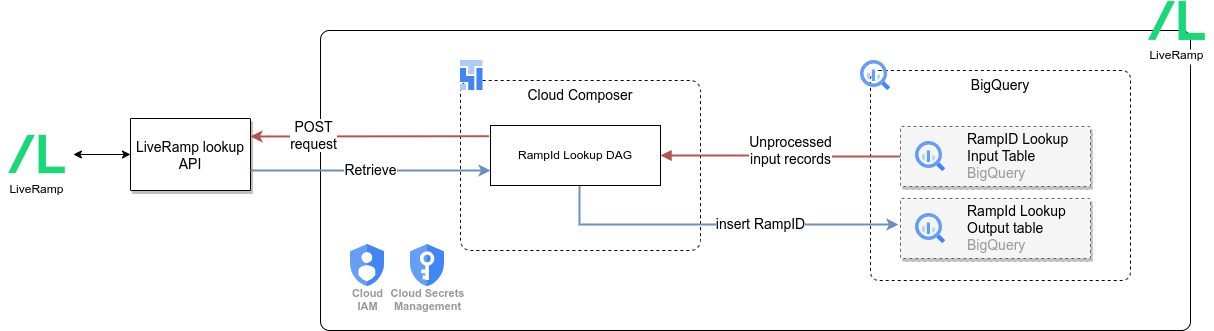
Das folgende Diagramm zeigt, wie die LiveRamp-Datenquelle über die Marketing-Arbeitslast der Cortex Framework Data Foundation verfügbar ist:
Konfigurationsdatei
In der Datei config.json werden die Einstellungen konfiguriert, die für die Verbindung zu Datenquellen zur Übertragung von Daten aus verschiedenen Arbeitslasten erforderlich sind. Diese Datei enthält die folgenden Parameter für LiveRamp:
"marketing": {
"deployLiveRamp": true,
"LiveRamp": {
"datasets": {
"cdc": ""
}
}
}
In der folgenden Tabelle wird der Wert für jeden LiveRamp-Parameter beschrieben:
| Parameter | Bedeutung | Standardwert | Beschreibung |
marketing.LiveRamp
|
LiveRamp bereitstellen | true
|
Führen Sie die Bereitstellung für die LiveRamp-Datenquelle aus. |
marketing.LiveRamp.datasets.cdc
|
CDC-Datensatz für LiveRamp | CDC-Dataset für LiveRamp. |
API-Verbindung
Die Cortex Framework Data Foundation ermöglicht die Identitätsauflösung durch Verknüpfung mit LiveRamp.Mit Cortex Frameworks kann eine RampID-Suche durchgeführt werden, mit der Unternehmen bekannte Zielgruppen oder Kundensegmente aus ihren CRM-Systemen identifizieren können.
Die RampID ist eine Kennung, die von der LiveRamp API anhand personenidentifizierbarer Informationen wie E-Mail-Adresse, Telefonnummer und Name generiert wird. Mit dieser RampID können Unternehmen Einträge in mehreren Systemen identifizieren und konsolidieren, z. B. Zielgruppen verschiedener Kampagnen. Durch die Einbindung von LiveRamp können Unternehmen ihre Zielgruppen besser identifizieren und ansprechen. Das führt zu effektiveren und personalisierten Marketingkampagnen.
Mit der LiveRamp Identity Resolution Retrieval API können Unternehmen personenidentifizierbare Daten programmatisch auf Personen zurückführen. Das Cortex-Framework verwendet den Lookup-Endpunkt von LiveRamp, indem gehashte personenidentifizierbare Daten über den API-Aufruf gesendet werden.
Eingabe- und Ausgabetabellen
Nach der Bereitstellung von Cortex Framework erstellt das System die folgenden beiden BigQuery-Tabellen im entsprechenden Dataset in config.json.
rampid_lookup_input Tabelle
Die Tabelle rampid_lookup_input ist die Eingabe für den RampID-Suchvorgang.
| Spalte | Datentyp | Beschreibung | Beispiel | Primärschlüssel |
| id | STRING | Die eindeutige ID dieses Eintrags. | „123“ | Ja |
| segment_name | STRING | Name der Zielgruppe/CRM-Datei/des Kundensegments. | „Hoher Wert“ | Nein |
| source_system_name | STRING | Quellsystem, aus dem der Datensatz stammt. | „Salesforce“ | Nein |
| Name | STRING | Kundenname | „Max Mustermann“ | Nein |
| STRING | E-Mail-Adresse des Kunden | „beispiel@beispiel.de“ | Nein | |
| phone_number | STRING | Kundentelefon | „1234567890“ | Nein |
| postal_code | STRING | Postleitzahl des Kunden | „12345“ | Nein |
| is_processed | BOOL |
Gibt an, ob ein Datensatz bereits verarbeitet wurde.
Geben Sie für neue Einträge „FALSE“ ein. Das System aktualisiert diesen Wert nach der Verarbeitung auf „TRUE“. |
FALSE | Nein |
| load_timestamp | TIMESTAMP | Zeitstempel, zu dem der Datensatz in das System eingefügt wurde. Dies dient ausschließlich Prüfzwecken. | „2020-01-01 00:00:00 UTC“ | Nein |
| processed_timestamp | TIMESTAMP | Zeitstempel, zu dem das System die API-Suche für diesen Eintrag durchgeführt hat. Dieser Wert wird immer vom System ausgefüllt. | „2020-01-01 00:00:00 UTC“ | Nein |
Die Tabelle rampid_lookup_input muss regelmäßig (je nach Ihren geschäftlichen Anforderungen) mit den personenbezogenen Daten Ihrer Kunden wie
Cortex Framework bietet keine automatisierte Möglichkeit dazu, aber ein Beispielscript ddls/samples/populate_rampid_lookup_input.sql, das zeigt, wie Sie diese Tabelle mit Daten aus Ihrem Salesforce-System füllen können, das bereits mit Cortex Framework bereitgestellt wurde. Sie können diese Datei als Leitfaden verwenden, falls Ihre Daten aus einem anderen System stammen.
Achten Sie darauf, dass in der Tabelle rampid_lookup_input keine doppelten Einträge vorhanden sind. Das bedeutet, dass beispielsweise dieselbe Person nicht mehrmals mit denselben personenidentifizierbaren Informationen vorhanden sein darf, auch wenn ihre ID unterschiedlich sein kann. Der Cortex-Framework-Such-DAG schlägt fehl, wenn ein Segment viele doppelte Einträge enthält. Dies wird von den LiveRamp APIs erzwungen.
Die Tabelle rampid_lookup
Die Tabelle rampid_lookup ist eine Ausgabetabelle mit RampIDs für jedes Segment im Eingabedatensatz. Bei LiveRamp ist es nicht möglich, die RampID einem einzelnen Datensatz zuzuordnen.
| Spalte | Datentyp | Beschreibung |
| segment_name | STRING | Segmentname aus der Eingabetabelle. |
| ramp_id | STRING | LiveRamp-RampID |
| Datumsstempel | TIMESTAMP | Zeitstempel für den Zeitpunkt, zu dem diese RampID-Suche ausgeführt wurde. |
LiveRamp-RampIDs können sich im Laufe der Zeit ändern, und zwar für dieselbe Person. Das bedeutet, dass Sie von Zeit zu Zeit eine neue Suche für bereits verarbeitete Daten durchführen müssen. Im Cortex Framework finden Sie ein Beispielskript ddls/samples/clean_up_segment_matching.sql, das zeigt, wie Sie dies auf Segmentebene tun können. So können Sie ein ganzes Segment zurücksetzen. Das System führt dann eine Suche für dieses Segment durch und gibt Ihnen aktuelle RampIDs zurück.
Die Tabelle rampid_lookup (Ausgabetabelle) enthält möglicherweise etwas weniger Datensätze als die Eingabetabelle. Das ist beabsichtigt, da das Cortex-Framework versucht, die Eingabedatensätze mithilfe von personenidentifizierbaren Daten zu debuggen, damit die Suche in der LiveRamp API nicht fehlschlägt.
Kontoauthentifizierung
- Wenden Sie sich an LiveRamp, um Anmeldedaten für die Authentifizierung zu erhalten. Dazu gehören die Client-ID und das Client-Secret.
Erstellen Sie mit Secret Manager ein Secret mit dem Namen
cortex-framework-liverampund verwenden Sie Folgendes als Wert. Eine Anleitung finden Sie in der Secret Manager-Dokumentation.{ 'client_id':'CLIENT_ID', 'client_secret':'CLIENT_SECRET', 'grant_type':'client_credentials' }Ersetzen Sie Folgendes:
- Ersetzen Sie „CLIENT_ID“ durch die Client-ID aus Schritt 1.
- „CLIENT_SECRET“ durch den Clientschlüssel aus Schritt 1.
Cloud Composer-Verbindungen
Erstellen Sie die folgenden Verbindungen in Cloud Composer. Weitere Informationen finden Sie in der Dokumentation zum Verwalten von Airflow-Verbindungen.
| Verbindungsname | Purpose |
liveramp_cdc_bq
|
Für LiveRamp API > CDC-Datensatzübertragung |
Konfiguration
Die Datei config.ini steuert einige Verhaltensweisen des Cloud Composer-DAG sowie die Verwendung von LiveRamp APIs. Konfigurieren Sie die Datei LiveRamp/src/pipelines/config.ini nach Ihren Anforderungen. Diese Parameter sind bereits in der Datei beschrieben. Achten Sie jedoch auf liveramp_api_base_url. Dieser Parameter verweist standardmäßig auf die Produktions-API-URL von LiveRamp. Je nach Konfiguration müssen Sie ihn möglicherweise auf die Staging-Version verweisen.
Nächste Schritte
- Weitere Informationen zu anderen Datenquellen und Arbeitslasten finden Sie unter Datenquellen und Arbeitslasten.
- Weitere Informationen zu den Schritten für die Bereitstellung in Produktionsumgebungen finden Sie unter Voraussetzungen für die Bereitstellung der Cortex Framework Data Foundation.