Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
このチュートリアルでは、スケジューラの誤動作、解析エラー、レイテンシ、タスクの失敗につながるタスクのスケジューリングと解析の問題の診断とトラブルシューティングについて説明します。
はじめに
Airflow スケジューラは、主に 2 つの要素(タスクのスケジューリングと DAG の解析)の影響を受けます。これらの要素のどちらかで起こる問題は、環境の健全性とパフォーマンスに悪影響を及ぼす可能性があります。
同時にスケジュールされるタスクが多すぎる場合があります。この場合、キューがいっぱいになり、タスクが「スケジュール設定済み」状態のままになるか、キューに追加された後に再スケジュールされるため、タスクの失敗やパフォーマンスのレイテンシが発生する可能性があります。
別の一般的な問題は、DAG コードの複雑さによって発生する解析のレイテンシとエラーです。たとえば、コードの最上位レベルに Airflow 変数を含む DAG コードを使用すると、解析のレイテンシ、データベースの過負荷、スケジューリングの失敗、DAG のタイムアウトが発生する可能性があります。
このチュートリアルでは、サンプル DAG を診断し、スケジューリングと解析の問題のトラブルシューティングを行う方法、DAG スケジューリングを改善する方法、DAG コードと環境構成を最適化してパフォーマンスを改善する方法について学習します。
目標
このセクションでは、このチュートリアルのサンプルの目的について説明します。
例: タスクの同時実行が高いことによるスケジューラの誤動作とレイテンシ
複数回同時に実行されるサンプル DAG をアップロードし、Cloud Monitoring でスケジューラの誤動作とレイテンシの問題を診断します。
タスクを統合して DAG コードを最適化し、パフォーマンスへの影響を評価します。
時間の経過とともに均等にタスクを分散し、パフォーマンスへの影響を評価します。
Airflow 構成と環境構成を最適化し、影響を評価します。
例: 複雑なコードにより発生する DAG 解析エラーとレイテンシ
Airflow 変数を使用してサンプル DAG をアップロードし、Cloud Monitoring で問題を診断します。
コードの最上位レベルで Airflow 変数を使用しないようにして DAG コードを最適化し、解析時間への影響を評価します。
Airflow 構成と環境構成を最適化し、解析時間への影響を評価します。
費用
このチュートリアルでは、課金対象である次の Google Cloudコンポーネントを使用します。
このチュートリアルを終了した後、作成したリソースを削除すると、それ以上の請求は発生しません。詳しくは、クリーンアップをご覧ください。
準備
このセクションでは、チュートリアルを開始する前に必要な作業について説明します。
プロジェクトを作成して構成する
このチュートリアルでは Google Cloudプロジェクトが必要です。プロジェクトは、次のように構成します:
Google Cloud コンソールで、プロジェクトを選択または作成します:
プロジェクトに対して課金が有効になっていることを確認します。、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Google Cloud プロジェクト ユーザーに、必要なリソースを作成するための次のロールがあることを確認します。
- 環境とストレージ オブジェクトの管理者
(
roles/composer.environmentAndStorageObjectAdmin) - Compute 管理者(
roles/compute.admin)
- 環境とストレージ オブジェクトの管理者
(
プロジェクトでAPI を有効にする
Enable the Cloud Composer API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Cloud Composer 環境を作成する
環境の作成の一環として、Cloud Composer v2 API サービス エージェント拡張機能(roles/composer.ServiceAgentV2Ext)のロールを Composer サービス エージェントに付与します。Cloud Composer は、このアカウントを使用して Google Cloud プロジェクトでオペレーションを実行します。
例: タスクのスケジューリングの問題でスケジューラが誤動作し、タスクが失敗する
この例では、タスクの同時実行性が高いことによるスケジューラの誤動作とレイテンシのデバッグを示します。
サンプル DAG を環境にアップロードする
先ほどの手順で作成した環境に、次のサンプル DAG をアップロードします。このチュートリアルでは、この DAG の名前は dag_10_tasks_200_seconds_1 です。
この DAG には 200 個のタスクがあります。各タスクは 1 秒間待機して、「Complete!」を出力します。 DAG はアップロードされると自動的にトリガーされます。Cloud Composer はこの DAG を 10 回実行し、すべての DAG 実行が並行して行われます。
import time
from datetime import datetime, timedelta
from airflow import DAG
from airflow.decorators import task
tasks_amount = 200
seconds = 1
minutes = 5
with DAG(
dag_id=f"dag_10_tasks_{tasks_amount}_sec_{seconds}",
start_date=datetime(2023, 11, 22, 20, 0),
end_date=datetime(2023, 11, 22, 20, 49),
schedule_interval=timedelta(minutes=minutes),
catchup=True,
) as dag:
@task
def create_subtasks(seconds: int) -> None:
time.sleep(seconds)
for i in range(tasks_amount):
create_subtasks(seconds)
スケジューラの誤動作とタスクの失敗の問題を診断する
DAG の実行が完了したら、Airflow UI を開き、dag_10_tasks_200_seconds_1 DAG をクリックします。合計 10 個の DAG 実行が成功し、それぞれに成功したタスクが 200 個あることがわかります。
Airflow タスクのログを確認します。
Google Cloud コンソールで [環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[ログ] タブに移動してから、[すべてのログ] > [Airflow ログ] > [ワーカー] > [ログ エクスプローラで表示] に移動します。
ログのヒストグラムでは、エラーと警告が赤とオレンジ色で示されます。

サンプル DAG では、約 130 件の警告と 60 件のエラーが発生しています。黄色と赤色の棒を含む列をクリックします。ログには、次のような警告とエラーが表示されます。
State of this instance has been externally set to success. Terminating
instance.
Received SIGTERM. Terminating subprocesses.
worker: Warm shutdown (MainProcess).
これらのログは、リソース使用量が上限を超えたためにワーカーが再起動したことを示す可能性があります。
Airflow タスクがキューに長時間保持されると、スケジューラは failed および up_for_retry とマークし、実行のために再スケジュールします。この状況の症状を監視する 1 つの方法は、キューに入れられたタスクの数をグラフで確認し、このグラフのスパイクが約 10 分以内に低下しない場合は、タスクが失敗した可能性があります(ログなし)。
モニタリング情報を確認します。
[Monitoring] タブに移動し、[概要] を選択します。
[Airflow タスク] のグラフを確認します。
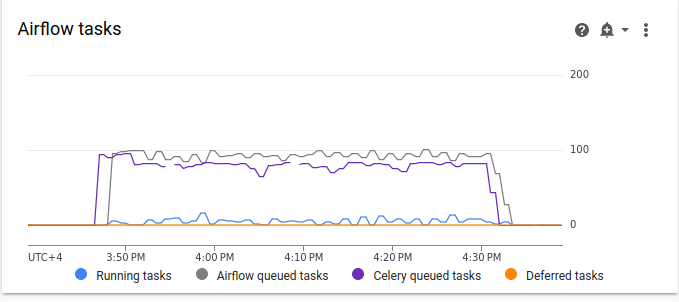
図 2.Airflow タスクのグラフ(クリックして拡大) Airflow タスクのグラフで、10 分以上続くキューに入れられたタスクの急増が発生しています。これは、スケジュールされているすべてのタスクを処理するのに十分なリソースが環境に含まれていないことを意味する可能性があります。
アクティブ ワーカーのグラフを確認します。
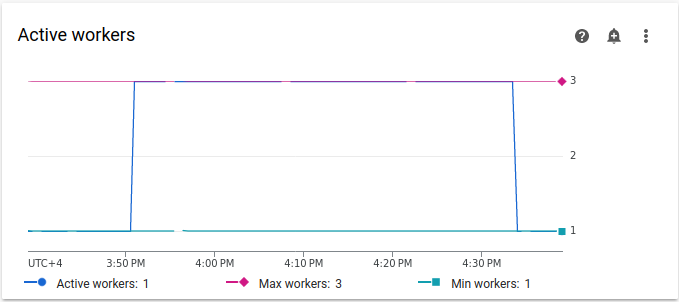
図 3.アクティブ ワーカーのグラフ(クリックして拡大) [アクティブ ワーカー] グラフは、DAG の実行中に DAG が 3 つのワーカーの上限まで自動スケーリングをトリガーしたことを示します。
リソース使用量のグラフは、キューに入れられたタスクを実行するための容量が Airflow ワーカーにない可能性があります。[モニタリング] タブで、[ワーカー] を選択し、[ワーカーの合計 CPU] と [ワーカーの合計メモリ使用量] のグラフを確認します。
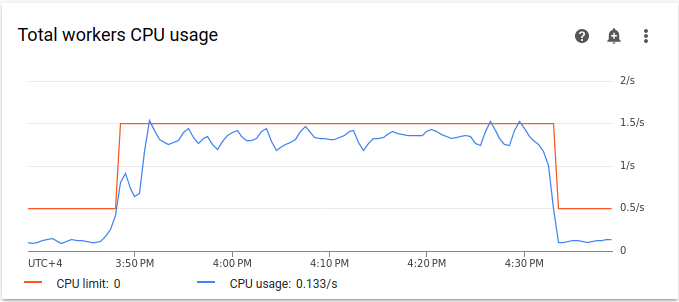
図 4.ワーカーの合計 CPU 使用率のグラフ(クリックして拡大) 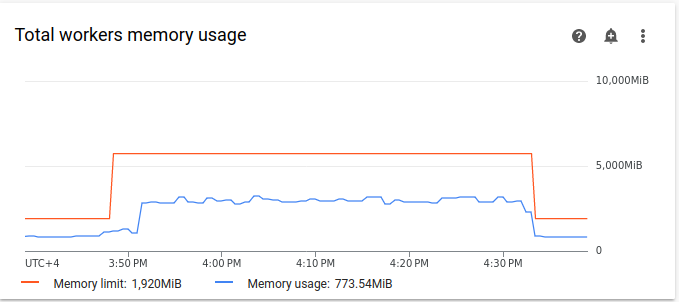
図 5.ワーカーの合計メモリ使用量のグラフ(クリックして拡大) グラフでは、過剰な数のタスクを同時に実行した結果、CPU の上限に達したことが示されています。リソースが 30 分以上使用されています。これは、10 回の DAG 実行で 1 つずつ実行される 200 回のタスクの合計時間よりも長くなっています。
これらは、キューがいっぱいになっていることと、スケジュールされたすべてのタスクを処理するためのリソースが不足していることを示すものです。
タスクを統合する
現在のコードでは、すべてのタスクを並行して処理するのに十分なリソースがない DAG とタスクが数多く作成されるため、キューがいっぱいになります。 タスクをキューに長時間保持すると、タスクのスケジュール変更や失敗が発生する可能性があります。 このような状況では、より少数の統合されたタスクを選ぶ必要があります。
次のサンプル DAG では、最初の例のタスク数を 200 から 20 に変更し、待機時間を 1 秒から 10 秒に増やして、同じ量の処理を行うより統合されたタスクをシミュレートします。
作成した環境に、次のサンプル DAG をアップロードします。このチュートリアルでは、この DAG の名前は dag_10_tasks_20_seconds_10 です。
import time
from datetime import datetime, timedelta
from airflow import DAG
from airflow.decorators import task
tasks_amount = 20
seconds = 10
minutes = 5
with DAG(
dag_id=f"dag_10_tasks_{tasks_amount}_sec_{seconds}",
start_date=datetime(2021, 12, 22, 20, 0),
end_date=datetime(2021, 12, 22, 20, 49),
schedule_interval=timedelta(minutes=minutes),
catchup=True,
) as dag:
@task
def create_subtasks(seconds: int) -> None:
time.sleep(seconds)
for i in range(tasks_amount):
create_subtasks(seconds)
より統合されたタスクがスケジューリング プロセスに与える影響を評価します。
DAG の実行が完了するまで待ちます。
Airflow UI の [DAG] ページで、
dag_10_tasks_20_seconds_10DAG をクリックします。10 個の DAG 実行が表示され、それぞれに成功したタスクが 20 個あります。Google Cloud コンソールで [環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[ログ] タブに移動してから、[すべてのログ] > [Airflow ログ] > [ワーカー] > [ログ エクスプローラで表示] に移動します。
より統合されたタスクを使用した 2 番目の例では、警告が約 10 件、エラーが 7 件でした。ヒストグラムで、最初の例(前の値)と 2 番目の例(後の値)でのエラーと警告の数を比較できます。

図 6.タスクが統合された後の Airflow ワーカーログのヒストグラム(クリックして拡大) 最初の例とより統合された例を比較すると、2 番目の例ではエラーと警告が大幅に少なくなっていることがわかります。ただし、リソースの過負荷のために、ウォーム シャットダウンに関連する同じエラーがログに引き続き表示されます。
[Monitoring] タブで [ワーカー] を選択し、グラフを確認します。
最初の例の Airflow タスクのグラフ(前の値)と、より統合されたタスクによる 2 番目の例のグラフを比較すると、キューに入れられたタスクのスパイクは、タスクが統合された場合により短い時間になっていることがわかります。しかし、スパイクは 10 分近く、これは最適ではありません。
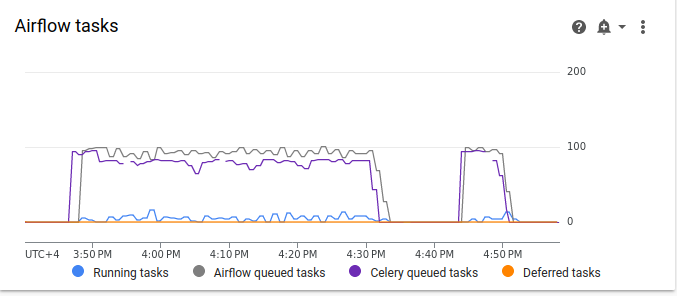
図 7.タスクが統合された後の Airflow タスクのグラフ(クリックして拡大) アクティブ ワーカーのグラフでは、両方の例が同じ量の作業をシミュレートしているにも関わらず、最初の例(グラフの左側)が 2 番目の例よりもはるかに長い時間リソースを使用したことがわかります。
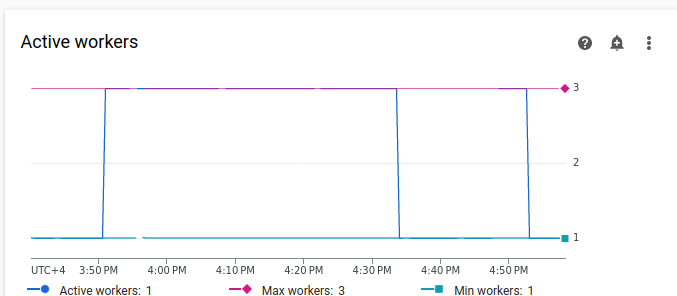
図 8.タスクが統合された後のアクティブなワーカーのグラフ(クリックして拡大) ワーカーのリソース使用量のグラフを確認します。より統合されたタスクを使用した例と最初の例で使用したリソースの間に大きな差があるにも関わらず、CPU 使用率は上限の 70% まで急上昇しています。

図 9.タスクが統合された後のワーカーの合計 CPU 使用率のグラフ(クリックして拡大) 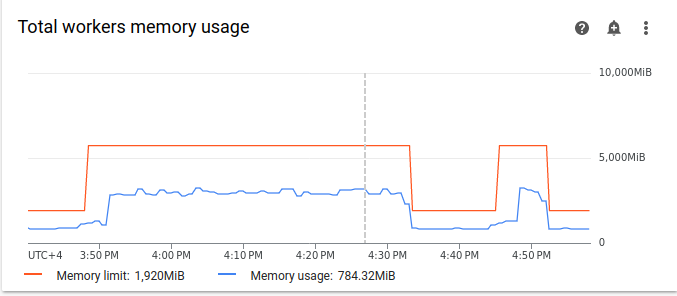
図 10.タスクが統合された後のワーカーの合計メモリ使用量のグラフ(クリックして拡大)
時間の経過とともにタスクを均等に分散する
同時実行タスクが多すぎるとキューがいっぱいになり、タスクがキューに詰まることや、再スケジュールされる可能性があります。前のステップでは、これらのタスクを統合してタスクの数を減らしましたが、出力ログとモニタリングでは、同時タスクの数が最適ではないことが示されました。
スケジュールを実装するか、同時に実行できるタスク数の上限を設定することで、同時タスクの数を制御できます。
このチュートリアルでは、DAG レベルのパラメータを dag_10_tasks_20_seconds_10 DAG に追加して、時間の経過とともにタスクをより均等に分散します。
DAG コンテキスト マネージャーに
max_active_runs=1引数を追加します。この引数により、特定の時点で DAG のインスタンスを 1 つだけ実行する制限を設定します。DAG コンテキスト マネージャーに
max_active_tasks=5引数を追加します。この引数は、各 DAG で同時に実行できるタスク インスタンスの最大数を制御します。
作成した環境に、次のサンプル DAG をアップロードします。このチュートリアルでは、この DAG の名前は dag_10_tasks_20_seconds_10_scheduled.py です。
import time
from datetime import datetime, timedelta
from airflow import DAG
from airflow.decorators import task
tasks_amount = 20
seconds = 10
minutes = 5
active_runs = 1
active_tasks = 5
with DAG(
dag_id=f"dag_10_tasks_{tasks_amount}_sec_{seconds}_runs_{active_runs}_tasks_{active_tasks}",
start_date=datetime(2021, 12, 22, 20, 0),
end_date=datetime(2021, 12, 22, 20, 49),
schedule_interval=timedelta(minutes=minutes),
max_active_runs=active_runs,
max_active_tasks=active_tasks,
catchup=True,
) as dag:
@task
def create_subtasks(seconds: int) -> None:
time.sleep(seconds)
for i in range(tasks_amount):
create_subtasks(seconds)
時間の経過とともにタスクの分散がスケジューリング プロセスに与える影響を評価します。
DAG の実行が完了するまで待ちます。
Google Cloud コンソールで [環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[ログ] タブに移動してから、[すべてのログ] > [Airflow ログ] > [ワーカー] > [ログ エクスプローラで表示] に移動します。
ヒストグラムで、アクティブなタスクの数と実行数が限られた 3 番目の DAG では、警告やエラーが生成されず、ログの分布が以前の値と比較してより均等に見えることがわかります。

図 11.タスクが統合され、時間の経過とともに分散された後の Airflow ワーカー ログのヒストグラム(クリックして拡大)
アクティブなタスクの数と実行数が限られた dag_10_tasks_20_seconds_10_scheduled の例でのタスクでは、タスクが均等にキューに入れられるため、リソース不足は発生しませんでした。
前述の手順を実施した後、小規模なタスクを統合して、時間の経過とともにより均等に分散させることで、リソース使用量を最適化しました。
環境構成を最適化する
キューに入っているタスクを実行するための容量が Airflow ワーカーに常に確保されるように、環境構成を調整できます。
ワーカーの数とワーカーの同時実行
ワーカーの最大数を調整して、Cloud Composer が設定された上限内で環境を自動的にスケーリングするようにできます。
[celery]worker_concurrency パラメータは、1 つのワーカーがタスクキューから受け取ることができるタスクの最大数を定義します。このパラメータを変更すると、1 つのワーカーが同時に実行できるタスクの数を調整できます。
この Airflow 構成オプションは、オーバーライドすることで変更できます。デフォルトでは、ワーカーの同時実行は最小値の 32, 12 * worker_CPU, 8 * worker_memory に設定されています。つまり、ワーカー リソースの上限に依存します。デフォルトのワーカー同時実行値の詳細については、環境の最適化をご覧ください。
ワーカーの数とワーカーの同時実行は互いに組み合わせられ、環境のパフォーマンスは両方のパラメータに大きく依存します。 次の点を考慮して、適切な組み合わせを選択してください。
並列で実行される複数のクイックタスク。キューで待機しているタスクがあり、同時に、ワーカーの CPU とメモリ使用率が低い場合は、ワーカーの同時実行数を増やしてください。ただし、状況によってはキューが埋まらず、自動スケーリングがトリガーされないことがあります。新しいワーカーの準備が整うまでに小規模なタスクの実行が終了した場合、既存のワーカーが残りのタスクを受け取り、新しく作成されたワーカーにタスクがなくなります。
このような状況では、過剰なスケーリングを回避するために、ワーカーの最小数を増やし、ワーカーの同時実行数を増やすことをおすすめします。
並列で実行される複数の長いタスク。ワーカーの同時実行性が高いと、システムがワーカー数のスケーリングを行えなくなります。複数のタスクがリソースを大量に消費し、完了に時間がかかる場合、ワーカーの同時実行が高いと、キューがいっぱいにならず、1 つのワーカーのみがすべてのタスクを受け取ることになり、パフォーマンスの問題が発生します。このような場合は、ワーカーの最大数を増やし、ワーカーの同時実行を減らすことをおすすめします。
並列処理の重要性
Airflow スケジューラは、DAG 実行のスケジューリングと DAG の個々のタスクを制御します。[core]parallelism Airflow 構成オプションは、これらのタスクのすべての依存関係が満たされた後に、Airflow スケジューラがエグゼキュータのキュー内にキューに入れるタスクの数を制御します。
並列処理は Airflow の保護メカニズムです。これにより、ワーカー数に関係なく、各スケジューラで同時に実行できるタスクの数が決まります。 並列処理の値にクラスタ内のスケジューラ数を掛けると、環境でキューに登録できるタスク インスタンスの最大数になります。
通常、[core]parallelism は、ワーカーの最大数と [celery]worker_concurrency の積として設定されます。また、プールの影響も受けます。この Airflow 構成オプションは、オーバーライドすることで変更できます。スケーリングに関連する Airflow 構成の調整の詳細については、Airflow 構成のスケーリングをご覧ください。
最適な環境構成を見つける
スケジューリングの問題を修正するために推奨される方法は、小さなタスクをより大きなタスクに統合し、時間の経過とともに均等にタスクを分散することです。DAG コードの最適化に加えて、複数のタスクを同時に実行するのに十分な容量を持つように環境構成を最適化することもできます。
たとえば、DAG のタスクをできる限り統合するものの、時間の経過とともに均等にタスクを分散するようアクティブなタスクを制限することは、特定のユースケースの望ましいソリューションでない場合を考えます。
並列処理、ワーカー数、ワーカー同時実行のパラメータを調整して、アクティブなタスクを制限することなく dag_10_tasks_20_seconds_10 DAG を実行できます。この例では、DAG が 10 回実行され、実行ごとに 20 個の小さなタスクが含まれています。
すべて同時に実行する場合:
環境のマネージド Cloud Composer インフラストラクチャのパフォーマンス パラメータを制御するため、環境のサイズを大きくする必要があります。
Airflow ワーカーは、20 個のタスクを同時に実行できる必要があります。つまり、ワーカーの同時実行を 20 に設定する必要があります。
ワーカーには、すべてのタスクを処理するのに十分な CPU とメモリが必要です。ワーカーの同時実行はワーカーの CPU とメモリの影響を受けます。したがって、CPU に少なくとも
worker_concurrency / 12とメモリにleast worker_concurrency / 8が必要です。ワーカーの同時実行に合わせて、並列処理を増やす必要があります。 ワーカーがキューから 20 個のタスクを受け取るためには、スケジューラは最初にその 20 個のタスクをスケジュールする必要があります。
環境構成を次のように調整します。
Google Cloud コンソールで [環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[環境の設定] タブに移動します。
[リソース] > [ワークロード] 構成から、[編集] をクリックします。
[ワーカー] セクションの [メモリ] フィールドで、Airflow ワーカーの新しいメモリ上限を指定します。このチュートリアルでは、4 GB を使用します。
[CPU] フィールドで、Airflow ワーカーの新しい CPU 上限を指定します。このチュートリアルでは、2 つの vCPU を使用します。
変更を保存し、Airflow ワーカーが再起動するまで数分待ちます。
次に、並列処理とワーカーの同時実行の Airflow 構成オプションをオーバーライドします。
[Airflow 構成のオーバーライド] タブに移動します。
[編集] をクリックしてから、[Airflow 構成のオーバーライドを追加] をクリックします。
並列処理構成をオーバーライドします。
セクション キー 値 coreparallelism20[Airflow 構成のオーバーライドを追加] をクリックして、ワーカーの同時実行構成をオーバーライドします。
セクション キー 値 celeryworker_concurrency20[保存] をクリックして、環境が構成を更新するまで待ちます。
調整した構成で同じサンプル DAG を再度トリガーします。
Airflow ツールバーで、[DAG] ページに移動します。
dag_10_tasks_20_seconds_10DAG を見つけて削除します。DAG が削除されると、Airflow は環境のバケット内の DAG フォルダをチェックし、自動的に DAG を再度実行します。
DAG の実行が完了したら、ログのヒストグラムをもう一度確認します。この図から、調整された環境の構成で実行したときに、より統合されたタスクを使用した dag_10_tasks_20_seconds_10 の例では、エラーと警告が生成されなかったことがわかります。結果を図の以前のデータと比較します。ここでは、デフォルトの環境構成で実行したときにエラーと警告が生成されています。

環境構成と Airflow 構成はタスクのスケジューリングで重要な役割を果たしますが、構成を特定の上限を超えて増やすことはできません。
パフォーマンスと効率を最適化するために、DAG コードを最適化し、タスクを統合し、スケジューリングを使用することをおすすめします。
例: 複雑な DAG コードが原因で発生する DAG 解析エラーとレイテンシ
この例では、過剰な Airflow 変数をシミュレートするサンプル DAG の解析レイテンシを調査します。
新しい Airflow 変数を作成する
サンプルコードをアップロードする前に、新しい Airflow 変数を作成します。
Google Cloud コンソールで [環境] ページに移動します。
[Airflow ウェブサーバー] 列で、ご使用の環境の [Airflow] リンクをクリックします。
[管理者] > [変数] > [新しいレコードを追加] に移動します。
次の値を設定します。
- key:
example_var - val:
test_airflow_variable
- key:
サンプル DAG を環境にアップロードする
先ほどの手順で作成した環境に、次のサンプル DAG をアップロードします。このチュートリアルでは、この DAG の名前は dag_for_loop_airflow_variable です。
この DAG には、1,000 回実行され、過剰な Airflow 変数をシミュレートする for ループが含まれています。各反復処理で example_var 変数を読み取り、タスクを生成します。各タスクには、変数の値を出力するコマンドが 1 つ含まれています。
from datetime import datetime
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.models import Variable
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 2, 17),
'retries': 0
}
dag = DAG(
'dag_for_loop_airflow_variable',
default_args=default_args,
catchup=False,
schedule_interval="@daily"
)
for i in range(1000):
a = Variable.get('example_var', 'N/A')
task = BashOperator(
task_id=f'task_{i}',
bash_command='echo variable foo=${foo_env}',
dag=dag,
env={'foo_env': a}
)
解析の問題を診断する
DAG 解析時間は、Airflow スケジューラが DAG ファイルを読み取り、解析するのにかかる時間です。Airflow スケジューラは、DAG からタスクのスケジュールを設定する前に、DAG ファイルを解析して DAG の構造と定義済みのタスクを検出する必要があります。
DAG の解析に時間がかかる場合、スケジューラの容量を消費して、DAG 実行のパフォーマンスが低下する可能性があります。
DAG の解析時間をモニタリングする手順は次のとおりです。
gcloud CLI で
dags reportAirflow CLI コマンドを実行して、すべての DAG の解析時間を確認します。gcloud composer environments run ENVIRONMENT_NAME \ --location LOCATION \ dags report以下を置き換えます。
ENVIRONMENT_NAME: 環境の名前。LOCATION: 環境が配置されているリージョン。
コマンドの出力で、
dag_for_loop_airflow_variablesDAG の継続時間の値を探します。値が大きい場合、この DAG が最適な方法で実装されていない可能性があります。DAG が複数ある場合は、出力テーブルから、解析時間が長い DAG を確認できます。例:
file | duration | dag_num | task_num | dags ====================+================+=========+==========+===================== /dag_for_loop_airfl | 0:00:14.773594 | 1 | 1000 | dag_for_loop_airflow ow_variable.py | | | | _variable /airflow_monitoring | 0:00:00.003035 | 1 | 1 | airflow_monitoring .pyGoogle Cloud コンソールで DAG の解析時間を調べる
- Google Cloud コンソールで [環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[ログ] タブに移動してから、[すべてのログ] > [DAG プロセッサ マネージャー] に移動します。
dag-processor-managerログを確認し、問題かあるかどうか確認します。
図 13.DAG 解析時間を表示する DAG プロセッサ マネージャーのログ(クリックして拡大)
DAG の解析時間の合計が約 10 秒を超える場合、スケジューラが DAG 解析で過負荷となり、DAG を効果的に実行できなくなる可能性があります。
DAG コードを最適化する
DAG で不要な「トップレベル」の Python コードを避けることをおすすめします。DAG 外部からのインポート、変数、関数が多い DAG では、Airflow スケジューラの解析時間が長くなります。これにより、Cloud Composer と Airflow のパフォーマンスとスケーラビリティが低下します。Airflow 変数の読み取りが過剰になると、解析時間が長くなり、データベースの負荷が高くなります。DAG ファイルに上記のコードが含まれている場合、すべてのスケジューラのハートビートでこれらの関数が実行され、実行が遅くなる場合があります。
Airflow のテンプレート フィールドを使用して、Airflow 変数の値と Jinja テンプレートに含まれる値を DAG に取り込むことができます。これにより、スケジューラのハートビート中に不要な関数が実行されることを防止できます。
DAG の例をより適切に実装するには、DAG のトップレベルの Python コードで Airflow 変数を使用しないでください。代わりに、Jinja テンプレートを使用して Airflow 変数を既存のオペレーターに渡します。これにより、タスクの実行まで値の読み取りを遅延させることができます。
新しいバージョンのサンプル DAG を環境にアップロードします。このチュートリアルでは、この DAG の名前は dag_for_loop_airflow_variable_optimized です。
from datetime import datetime
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 2, 17),
'retries': 0
}
dag = DAG(
'dag_for_loop_airflow_variable_optimized',
default_args=default_args,
catchup=False,
schedule_interval='@daily'
)
for i in range(1000):
task = BashOperator(
task_id=f'bash_use_variable_good_{i}',
bash_command='echo variable foo=${foo_env}',
dag=dag,
env={'foo_env': '{{ var.value.get("example_var") }}'},
)
新しい DAG の解析時間を調べます。
DAG の実行が完了するまで待ちます。
dags reportコマンドを再度実行して、すべての DAG の解析時間を表示します。file | duration | dag_num | task_num | dags ====================+================+=========+==========+===================== /dag_for_loop_airfl | 0:00:37.000369 | 1 | 1000 | dag_for_loop_airflow ow_variable.py | | | | _variable /dag_for_loop_airfl | 0:00:01.109457 | 1 | 1000 | dag_for_loop_airflow ow_variable_optimiz | | | | _variable_optimized ed.py | | | | /airflow_monitoring | 0:00:00.040510 | 1 | 1 | airflow_monitoring .py | | | |再度
dag-processor-managerログを確認して、解析時間の長さを分析します。
図 14.DAG コードが最適化された後の DAG 解析時間を表示する DAG プロセッサ マネージャーのログ(クリックして拡大)
環境変数を Airflow テンプレートに置き換えることで、DAG コードを簡素化し、解析のレイテンシを約 10 分の 1 に短縮できます。
Airflow 環境構成を最適化する
Airflow スケジューラは、常に新しいタスクをトリガーして、環境バケット内のすべての DAG を解析しようとします。DAG の解析時間が長く、スケジューラが大量のリソースを消費している場合は、スケジューラがリソースをより効率的に使用できるように Airflow スケジューラ構成を最適化できます。
このチュートリアルでは、DAG ファイルの解析に時間がかかり、解析サイクルが重複し始め、スケジューラの容量を使い果たします。この例では、最初の DAG の解析に 5 秒以上かかっているため、スケジューラをより低い頻度で実行するように構成して、リソースをより効率的に使用できるようにします。Airflow 構成オプション scheduler_heartbeat_sec をオーバーライドします。この構成では、スケジューラを実行する頻度(秒単位)を定義します。デフォルトでは、値は 5 秒に設定されています。
この Airflow 構成オプションは、オーバーライドすることで変更できます。
scheduler_heartbeat_sec Airflow 構成オプションをオーバーライドします。
Google Cloud コンソールで [環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[Airflow 構成のオーバーライド] タブに移動します。
[編集] をクリックしてから、[Airflow 構成のオーバーライドを追加] をクリックします。
Airflow 構成オプションをオーバーライドします。
セクション キー 値 schedulerscheduler_heartbeat_sec10[保存] をクリックして、環境が構成を更新するまで待ちます。
スケジューラ指標を確認します。
[Monitoring] タブに移動し、[スケジューラ] を選択します。
[スケジューラ ハートビート] のグラフで、[その他のオプション] ボタン(3 つのドット)をクリックしてから、[Metrics Explorer で表示] をクリックします。
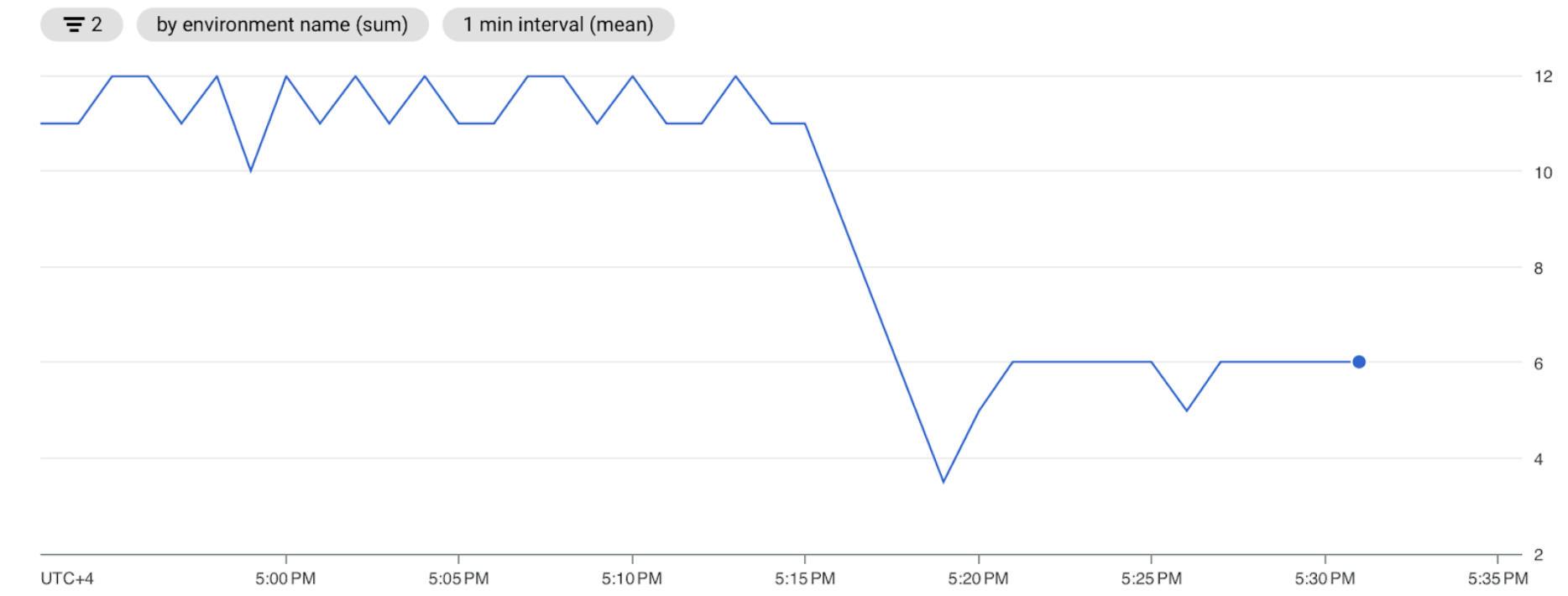
グラフでは、デフォルト構成を 5 秒から 10 秒に変更した後、スケジューラの実行頻度が 2 倍少ないことがわかります。ハートビートの頻度を減らすことで、前の解析サイクルが進行中で、スケジューラのリソース容量が不足していない場合に、スケジューラが実行を開始しないようにします。
スケジューラに追加のリソースを割り当てる
Cloud Composer 2 では、スケジューラにより多くの CPU リソースとメモリリソースを割り当てることが可能です。このようにして、スケジューラのパフォーマンスを向上させ、DAG の解析時間を加速できます。
スケジューラに追加の CPU とメモリを割り当てます。
Google Cloud コンソールで [環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[環境の設定] タブに移動します。
[リソース] > [ワークロード] 構成から、[編集] をクリックします。
[スケジューラ] セクションの [メモリ] フィールドで、新しいメモリ上限を指定します。このチュートリアルでは、4 GB を使用します。
[CPU] フィールドに、新しい CPU 上限を指定します。このチュートリアルでは、2 つの vCPU を使用します。
変更を保存し、Airflow スケジューラが再起動するまで数分待ちます。
[ログ] タブに移動してから、[すべてのログ] > [DAG プロセッサ マネージャー] に移動します。
dag-processor-managerログを確認し、サンプル DAG の解析時間を比較します。
図 16.スケジューラにより多くのリソースが割り当てられた後の DAG 解析時間を示す、DAG プロセッサ マネージャーのログ(クリックして拡大)
スケジューラにリソースをさらに割り当てることで、スケジューラの容量を増やし、デフォルトの環境構成と比較した場合の解析レイテンシを大幅に短縮しました。スケジューラがより多くの DAG をより速く解析できるようになりますが、Cloud Composer リソースに関連する費用も増加します。また、リソースを特定の上限を超えて増やすことはできません。
可能な DAG コードと Airflow 構成の最適化を実装した後にのみ、リソースを割り当てることをおすすめします。
クリーンアップ
このチュートリアルで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
プロジェクトの削除
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
リソースを個別に削除する
複数のチュートリアルとクイックスタートを実施する予定がある場合は、プロジェクトを再利用すると、プロジェクトの割り当て上限を超えないようにできます。
Cloud Composer 環境を削除します。この手順で環境のバケットも削除します。