Em 15 de setembro de 2026, todas as versões do Cloud Composer 1 e as versões 2.0.x do Cloud Composer 2 vão atingir o fim da vida útil planejado. Não será possível usar ambientes com essas versões. Recomendamos planejar a migração para o Cloud Composer 3. As versões 2.1.x e mais recentes do Cloud Composer 2 ainda são compatíveis e não são afetadas por essa mudança.
Nesta página, descrevemos como usar os operadores do Google Kubernetes Engine para criar
clusters no Google Kubernetes Engine e iniciar
pods do Kubernetes
nesses clusters.
Os operadores do Google Kubernetes Engine executam pods do Kubernetes em um cluster especificado,
que pode ser um cluster separado não relacionado ao seu ambiente.
Em comparação, o KubernetesPodOperatorexecuta pods do Kubernetes
no cluster do ambiente.
Nesta página, você verá um exemplo de DAG que cria um cluster do Google Kubernetes Engine
com o GKECreateClusterOperator, usa o GKEStartPodOperator
com as configurações a seguir e o exclui com
o GKEDeleteClusterOperator depois:
Para acompanhar este exemplo, coloque todo o arquivo gke_operator.py
na pasta dags/ do ambiente ou
adicione o código relevante a um DAG.
Crie um cluster
O código mostrado aqui cria um cluster do Google Kubernetes Engine com dois pools de nós,
pool-0 e pool-1, cada um com um nó. Se necessário, defina outros
parâmetros da API Google Kubernetes Engine como parte do body.
Recomendamos o uso de clusters regionais no Airflow 2. Os clusters zonais estão mais expostos a falhas zonais. Por exemplo, talvez você queira usar a região
us-central1 para seu cluster em vez da zona us-central1-a.
Para mais informações sobre considerações específicas de cada região, consulte
Geografia e regiões.
Antes do lançamento da versão 5.1.0 do apache-airflow-providers-google,
não era possível transmitir o objeto node_pools no
GKECreateClusterOperator. Se você usa o Airflow 2, verifique se o ambiente
usa o apache-airflow-providers-google versão 5.1.0 ou posterior. É possível
instalar uma versão mais recente desse pacote PyPI
especificando apache-airflow-providers-google e >=5.1.0 como a
versão obrigatória.
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"CLUSTER={"name":CLUSTER_NAME,"node_pools":[{"name":"pool-0","initial_node_count":1},{"name":"pool-1","initial_node_count":1},],}create_cluster=GKECreateClusterOperator(task_id="create_cluster",project_id=PROJECT_ID,location=CLUSTER_REGION,body=CLUSTER,)
Iniciar cargas de trabalho no cluster
As seções a seguir explicam cada configuração GKEStartPodOperator no exemplo. Para informações sobre cada variável de configuração, consulte
a referência do Airflow para operadores do GKE.
fromairflowimportmodelsfromairflow.providers.google.cloud.operators.kubernetes_engineimport(GKECreateClusterOperator,GKEDeleteClusterOperator,GKEStartPodOperator,)fromairflow.utils.datesimportdays_agofromkubernetes.clientimportmodelsask8s_modelswithmodels.DAG("example_gcp_gke",schedule_interval=None,# Override to match your needsstart_date=days_ago(1),tags=["example"],)asdag:# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"CLUSTER={"name":CLUSTER_NAME,"node_pools":[{"name":"pool-0","initial_node_count":1},{"name":"pool-1","initial_node_count":1},],}create_cluster=GKECreateClusterOperator(task_id="create_cluster",project_id=PROJECT_ID,location=CLUSTER_REGION,body=CLUSTER,)kubernetes_min_pod=GKEStartPodOperator(# The ID specified for the task.task_id="pod-ex-minimum",# Name of task you want to run, used to generate Pod ID.name="pod-ex-minimum",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# The namespace to run within Kubernetes, default namespace is# `default`.namespace="default",# Docker image specified. Defaults to hub.docker.com, but any fully# qualified URLs will point to a custom repository. Supports private# gcr.io images if the Composer Environment is under the same# project-id as the gcr.io images and the service account that Composer# uses has permission to access the Google Container Registry# (the default service account has permission)image="gcr.io/gcp-runtimes/ubuntu_18_0_4",)kubenetes_template_ex=GKEStartPodOperator(task_id="ex-kube-templates",name="ex-kube-templates",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,namespace="default",image="bash",# All parameters below are able to be templated with jinja -- cmds,# arguments, env_vars, and config_file. For more information visit:# https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# DS in jinja is the execution date as YYYY-MM-DD, this docker image# will echo the execution date. Arguments to the entrypoint. The docker# image's CMD is used if this is not provided. The arguments parameter# is templated.arguments=["{{ ds }}"],# The var template variable allows you to access variables defined in# Airflow UI. In this case we are getting the value of my_value and# setting the environment variable `MY_VALUE`. The pod will fail if# `my_value` is not set in the Airflow UI.env_vars={"MY_VALUE":"{{ var.value.my_value }}"},)kubernetes_affinity_ex=GKEStartPodOperator(task_id="ex-pod-affinity",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,name="ex-pod-affinity",namespace="default",image="perl",cmds=["perl"],arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# affinity allows you to constrain which nodes your pod is eligible to# be scheduled on, based on labels on the node. In this case, if the# label 'cloud.google.com/gke-nodepool' with value# 'nodepool-label-value' or 'nodepool-label-value2' is not found on any# nodes, it will fail to schedule.affinity={"nodeAffinity":{# requiredDuringSchedulingIgnoredDuringExecution means in order# for a pod to be scheduled on a node, the node must have the# specified labels. However, if labels on a node change at# runtime such that the affinity rules on a pod are no longer# met, the pod will still continue to run on the node."requiredDuringSchedulingIgnoredDuringExecution":{"nodeSelectorTerms":[{"matchExpressions":[{# When nodepools are created in Google Kubernetes# Engine, the nodes inside of that nodepool are# automatically assigned the label# 'cloud.google.com/gke-nodepool' with the value of# the nodepool's name."key":"cloud.google.com/gke-nodepool","operator":"In",# The label key's value that pods can be scheduled# on."values":["pool-1",],}]}]}}},)kubernetes_full_pod=GKEStartPodOperator(task_id="ex-all-configs",name="full",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,namespace="default",image="perl:5.34.0",# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["perl"],# Arguments to the entrypoint. The docker image's CMD is used if this# is not provided. The arguments parameter is templated.arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# The secrets to pass to Pod, the Pod will fail to create if the# secrets you specify in a Secret object do not exist in Kubernetes.secrets=[],# Labels to apply to the Pod.labels={"pod-label":"label-name"},# Timeout to start up the Pod, default is 120.startup_timeout_seconds=120,# The environment variables to be initialized in the container# env_vars are templated.env_vars={"EXAMPLE_VAR":"/example/value"},# If true, logs stdout output of container. Defaults to True.get_logs=True,# Determines when to pull a fresh image, if 'IfNotPresent' will cause# the Kubelet to skip pulling an image if it already exists. If you# want to always pull a new image, set it to 'Always'.image_pull_policy="Always",# Annotations are non-identifying metadata you can attach to the Pod.# Can be a large range of data, and can include characters that are not# permitted by labels.annotations={"key1":"value1"},# Optional resource specifications for Pod, this will allow you to# set both cpu and memory limits and requirements.# Prior to Airflow 2.3 and the cncf providers package 5.0.0# resources were passed as a dictionary. This change was made in# https://github.com/apache/airflow/pull/27197# Additionally, "memory" and "cpu" were previously named# "limit_memory" and "limit_cpu"# resources={'limit_memory': "250M", 'limit_cpu': "100m"},container_resources=k8s_models.V1ResourceRequirements(limits={"memory":"250M","cpu":"100m"},),# If true, the content of /airflow/xcom/return.json from container will# also be pushed to an XCom when the container ends.do_xcom_push=False,# List of Volume objects to pass to the Pod.volumes=[],# List of VolumeMount objects to pass to the Pod.volume_mounts=[],# Affinity determines which nodes the Pod can run on based on the# config. For more information see:# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/affinity={},)delete_cluster=GKEDeleteClusterOperator(task_id="delete_cluster",name=CLUSTER_NAME,project_id=PROJECT_ID,location=CLUSTER_REGION,)create_cluster >> kubernetes_min_pod >> delete_clustercreate_cluster >> kubernetes_full_pod >> delete_clustercreate_cluster >> kubernetes_affinity_ex >> delete_clustercreate_cluster >> kubenetes_template_ex >> delete_cluster
Configuração mínima
Para iniciar um pod no cluster do GKE com
o GKEStartPodOperator, apenas as opções project_id, location, cluster_name,
name, namespace, image e task_id são obrigatórias.
Ao colocar o snippet de código a seguir em um DAG, a tarefa pod-ex-minimum é
bem-sucedida, desde que os parâmetros listados anteriormente sejam definidos e válidos.
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"kubernetes_min_pod=GKEStartPodOperator(# The ID specified for the task.task_id="pod-ex-minimum",# Name of task you want to run, used to generate Pod ID.name="pod-ex-minimum",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# The namespace to run within Kubernetes, default namespace is# `default`.namespace="default",# Docker image specified. Defaults to hub.docker.com, but any fully# qualified URLs will point to a custom repository. Supports private# gcr.io images if the Composer Environment is under the same# project-id as the gcr.io images and the service account that Composer# uses has permission to access the Google Container Registry# (the default service account has permission)image="gcr.io/gcp-runtimes/ubuntu_18_0_4",)
Configuração do modelo
O Airflow é compatível com o
modelo Jinja.
Você precisa declarar as variáveis necessárias (task_id, name, namespace
e image) com o operador. Como mostra o exemplo a seguir, é possível
criar modelos de todos os outros parâmetros com o Jinja, incluindo cmds, arguments
e env_vars.
Sem alterar o DAG ou o ambiente, a tarefa ex-kube-templates
falha. Defina uma variável do Airflow chamada my_value para fazer com que esse DAG seja bem-sucedido.
Para definir my_value com gcloud ou a IU do Airflow:
LOCATION pela região em que o ambiente está localizado;
IU do Airflow
Na IU do Airflow 2:
Na barra de ferramentas, selecione Administrador > Variáveis.
Na página Listar variáveis, clique em Adicionar um novo registro.
Na página Adicionar variável, digite as seguintes informações:
Chave: my_value
Val: example_value
Clique em Save.
Configuração do modelo:
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"kubenetes_template_ex=GKEStartPodOperator(task_id="ex-kube-templates",name="ex-kube-templates",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,namespace="default",image="bash",# All parameters below are able to be templated with jinja -- cmds,# arguments, env_vars, and config_file. For more information visit:# https://airflow.apache.org/docs/apache-airflow/stable/macros-ref.html# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["echo"],# DS in jinja is the execution date as YYYY-MM-DD, this docker image# will echo the execution date. Arguments to the entrypoint. The docker# image's CMD is used if this is not provided. The arguments parameter# is templated.arguments=["{{ ds }}"],# The var template variable allows you to access variables defined in# Airflow UI. In this case we are getting the value of my_value and# setting the environment variable `MY_VALUE`. The pod will fail if# `my_value` is not set in the Airflow UI.env_vars={"MY_VALUE":"{{ var.value.my_value }}"},)
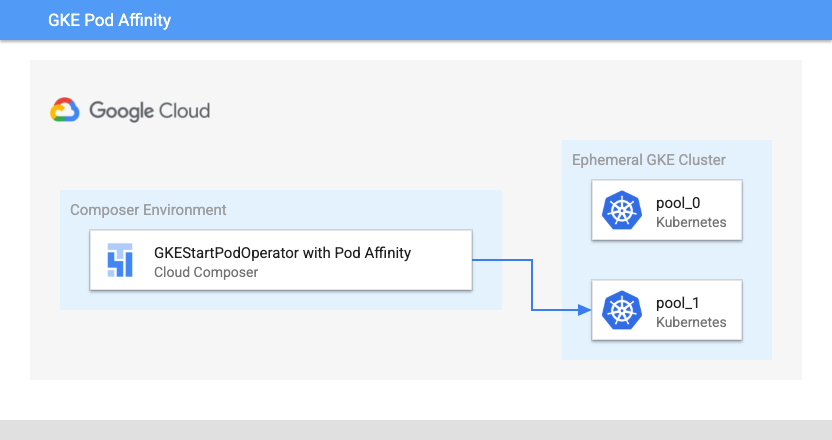
Configuração de afinidade do Pod
Ao configurar o parâmetro affinity em GKEStartPodOperator, você
controla em quais nós os pods serão programados, como, por exemplo, nós apenas em um determinado
pool de nós. Ao criar o cluster, você criou dois pools de nós chamados
pool-0 e pool-1. Esse operador determina que os pods precisam ser executados apenas em
pool-1.
Local de lançamento do pod do Kubernetes do Cloud Composer com afinidade de pods (clique para ampliar)
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"kubernetes_affinity_ex=GKEStartPodOperator(task_id="ex-pod-affinity",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,name="ex-pod-affinity",namespace="default",image="perl",cmds=["perl"],arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# affinity allows you to constrain which nodes your pod is eligible to# be scheduled on, based on labels on the node. In this case, if the# label 'cloud.google.com/gke-nodepool' with value# 'nodepool-label-value' or 'nodepool-label-value2' is not found on any# nodes, it will fail to schedule.affinity={"nodeAffinity":{# requiredDuringSchedulingIgnoredDuringExecution means in order# for a pod to be scheduled on a node, the node must have the# specified labels. However, if labels on a node change at# runtime such that the affinity rules on a pod are no longer# met, the pod will still continue to run on the node."requiredDuringSchedulingIgnoredDuringExecution":{"nodeSelectorTerms":[{"matchExpressions":[{# When nodepools are created in Google Kubernetes# Engine, the nodes inside of that nodepool are# automatically assigned the label# 'cloud.google.com/gke-nodepool' with the value of# the nodepool's name."key":"cloud.google.com/gke-nodepool","operator":"In",# The label key's value that pods can be scheduled# on."values":["pool-1",],}]}]}}},)
Configuração completa
Este exemplo mostra todas as variáveis que você pode configurar em
GKEStartPodOperator. Não é necessário modificar o código para que
a tarefa ex-all-configs seja bem-sucedida.
# TODO(developer): update with your valuesPROJECT_ID="my-project-id"# It is recommended to use regional clusters for increased reliability# though passing a zone in the location parameter is also validCLUSTER_REGION="us-west1"CLUSTER_NAME="example-cluster"kubernetes_full_pod=GKEStartPodOperator(task_id="ex-all-configs",name="full",project_id=PROJECT_ID,location=CLUSTER_REGION,cluster_name=CLUSTER_NAME,namespace="default",image="perl:5.34.0",# Entrypoint of the container, if not specified the Docker container's# entrypoint is used. The cmds parameter is templated.cmds=["perl"],# Arguments to the entrypoint. The docker image's CMD is used if this# is not provided. The arguments parameter is templated.arguments=["-Mbignum=bpi","-wle","print bpi(2000)"],# The secrets to pass to Pod, the Pod will fail to create if the# secrets you specify in a Secret object do not exist in Kubernetes.secrets=[],# Labels to apply to the Pod.labels={"pod-label":"label-name"},# Timeout to start up the Pod, default is 120.startup_timeout_seconds=120,# The environment variables to be initialized in the container# env_vars are templated.env_vars={"EXAMPLE_VAR":"/example/value"},# If true, logs stdout output of container. Defaults to True.get_logs=True,# Determines when to pull a fresh image, if 'IfNotPresent' will cause# the Kubelet to skip pulling an image if it already exists. If you# want to always pull a new image, set it to 'Always'.image_pull_policy="Always",# Annotations are non-identifying metadata you can attach to the Pod.# Can be a large range of data, and can include characters that are not# permitted by labels.annotations={"key1":"value1"},# Optional resource specifications for Pod, this will allow you to# set both cpu and memory limits and requirements.# Prior to Airflow 2.3 and the cncf providers package 5.0.0# resources were passed as a dictionary. This change was made in# https://github.com/apache/airflow/pull/27197# Additionally, "memory" and "cpu" were previously named# "limit_memory" and "limit_cpu"# resources={'limit_memory': "250M", 'limit_cpu': "100m"},container_resources=k8s_models.V1ResourceRequirements(limits={"memory":"250M","cpu":"100m"},),# If true, the content of /airflow/xcom/return.json from container will# also be pushed to an XCom when the container ends.do_xcom_push=False,# List of Volume objects to pass to the Pod.volumes=[],# List of VolumeMount objects to pass to the Pod.volume_mounts=[],# Affinity determines which nodes the Pod can run on based on the# config. For more information see:# https://kubernetes.io/docs/concepts/configuration/assign-pod-node/affinity={},)
excluir o cluster
O código mostrado aqui exclui o cluster que foi criado no início
do guia.
[[["Fácil de entender","easyToUnderstand","thumb-up"],["Meu problema foi resolvido","solvedMyProblem","thumb-up"],["Outro","otherUp","thumb-up"]],[["Difícil de entender","hardToUnderstand","thumb-down"],["Informações incorretas ou exemplo de código","incorrectInformationOrSampleCode","thumb-down"],["Não contém as informações/amostras de que eu preciso","missingTheInformationSamplesINeed","thumb-down"],["Problema na tradução","translationIssue","thumb-down"],["Outro","otherDown","thumb-down"]],["Última atualização 2025-10-19 UTC."],[],[]]