Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Nesta página, descrevemos como monitorar a integridade e o desempenho gerais do ambiente do Cloud Composer com as principais métricas no painel do Monitoring.
Introdução
Este tutorial se concentra nas principais métricas de monitoramento do Cloud Composer que podem fornecer uma boa visão geral da integridade e do desempenho no nível do ambiente.
O Cloud Composer oferece várias métricas que descrevem o estado geral do ambiente. As diretrizes de monitoramento neste tutorial são baseadas nas métricas expostas no painel do Monitoring do ambiente do Cloud Composer.
Neste tutorial, você vai aprender sobre as principais métricas que servem como indicadores primários de problemas com a performance e a integridade do seu ambiente, além das diretrizes para interpretar cada métrica em ações corretivas e manter o ambiente saudável. Você também vai configurar regras de alerta para cada métrica, executar o DAG de exemplo e usar essas métricas e alertas para otimizar a performance do seu ambiente.
Objetivos
Custos
Neste tutorial, usamos os seguintes componentes faturáveis do Google Cloud:
- Cloud Composer (consulte custos extras)
- Cloud Monitoring
Ao concluir este tutorial, exclua os recursos criados para evitar o faturamento contínuo. Para mais detalhes, consulte Limpeza.
Antes de começar
Nesta seção, descrevemos as ações necessárias antes de iniciar o tutorial.
Criar e configurar um projeto
Para este tutorial, você precisa de um projeto Google Cloud. Configure o projeto da seguinte maneira:
No console do Google Cloud , selecione ou crie um projeto:
Verifique se o faturamento foi ativado para o projeto. Saiba como verificar se o faturamento está ativado em um projeto.
Verifique se o usuário do projeto Google Cloud tem as seguintes funções para criar os recursos necessários:
- Administrador de objetos do armazenamento e do ambiente
(
roles/composer.environmentAndStorageObjectAdmin) - Administrador do Compute (
roles/compute.admin) - Editor do Monitoring (
roles/monitoring.editor)
- Administrador de objetos do armazenamento e do ambiente
(
Ativar as APIs do projeto
Enable the Cloud Composer API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Criar o ambiente do Cloud Composer
Crie um ambiente do Cloud Composer 2.
Como parte deste procedimento,
você concede o papel Extensão do agente de serviço da API Cloud Composer v2
(roles/composer.ServiceAgentV2Ext) à conta do agente de serviço do Composer. O Cloud Composer usa essa conta para realizar operações no seu projeto Google Cloud .
Analisar as principais métricas de integridade e desempenho no nível do ambiente
Este tutorial se concentra nas principais métricas que podem dar uma boa visão geral da integridade e do desempenho gerais do seu ambiente.
O painel do Monitoring no console doGoogle Cloud contém várias métricas e gráficos que permitem monitorar tendências no seu ambiente e identificar problemas com componentes do Airflow e recursos do Cloud Composer.
Cada ambiente do Cloud Composer tem um painel do Monitoring.
Conheça as principais métricas abaixo e localize cada uma delas no painel do Monitoring:
No console Google Cloud , acesse a página Ambientes.
Na lista de ambientes, clique no nome do seu ambiente. A página Detalhes do ambiente é aberta.
Acesse a guia Monitoramento.
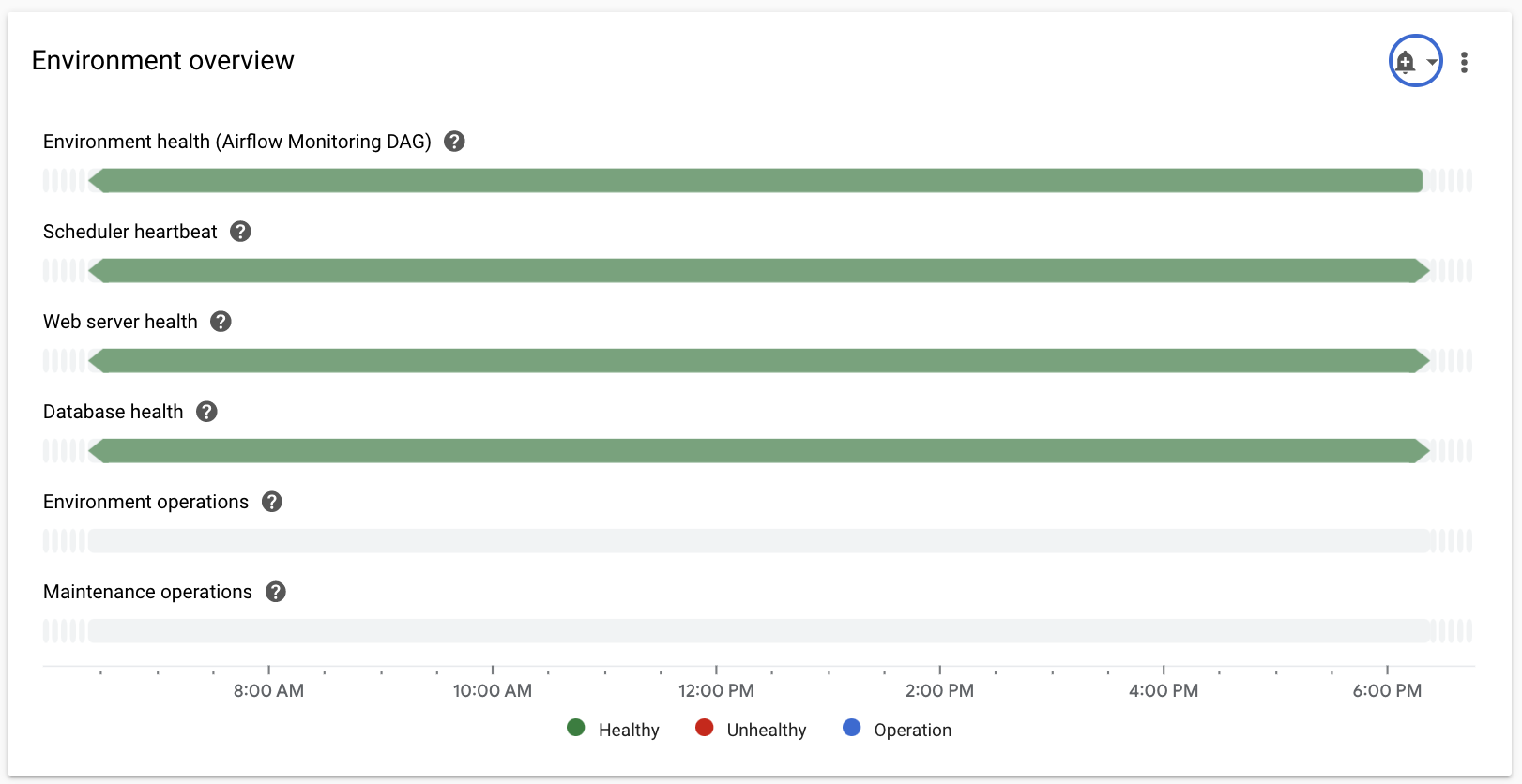
Selecione a seção Visão geral, localize o item Visão geral do ambiente no painel e observe a métrica Integridade do ambiente (DAG de monitoramento do Airflow).
Essa linha do tempo mostra a integridade do ambiente do Cloud Composer. A cor verde da barra de integridade do ambiente indica que ele está íntegro, enquanto o status de ambiente não íntegro é indicado com a cor vermelha.
A cada poucos minutos, o Cloud Composer executa um DAG de atividade chamado
airflow_monitoring. Se a execução do DAG de atividade for concluída com êxito, o status de integridade seráTrue. Se a execução do DAG de atividade falhar (por exemplo, devido à remoção do pod, encerramento do processo externo ou manutenção), o status de integridade seráFalse.
Selecione a seção Banco de dados SQL, encontre o item Integridade do banco de dados no painel e observe a métrica Integridade do banco de dados.
Essa linha do tempo mostra o status da conexão com a instância do Cloud SQL do seu ambiente. A barra verde de integridade do banco de dados indica conectividade, enquanto as falhas de conexão são indicadas com a cor vermelha.
O pod de monitoramento do Airflow dá um ping no banco de dados periodicamente e informa o status de integridade como
Truese uma conexão puder ser estabelecida ou comoFalsese não.
No item Integridade do banco de dados, observe as métricas Uso da CPU do banco de dados e Uso da memória do banco de dados.
O gráfico de uso da CPU do banco de dados indica o uso de núcleos de CPU pelas instâncias de banco de dados do Cloud SQL do seu ambiente em comparação com o limite total disponível de CPU do banco de dados.
O gráfico de uso da memória do banco de dados indica o uso da memória pelas instâncias de banco de dados do Cloud SQL do seu ambiente em comparação com o limite total disponível de memória do banco de dados.
Selecione a seção Programadores, localize o item Pulsação do programador no painel e observe a métrica Pulsação do programador.
Essa linha do tempo mostra a integridade do agendador do Airflow. Verifique se há áreas vermelhas para identificar problemas do agendador do Airflow. Se o ambiente tiver mais de um agendador, o status do sinal de funcionamento será "íntegro" enquanto pelo menos um dos agendadores estiver respondendo.
O programador é considerado não íntegro se o último heartbeat foi recebido mais de 30 segundos (valor padrão) antes da hora atual.
Selecione a seção Estatísticas do DAG, localize o item Tarefas zumbi excluídas no painel e observe a métrica Tarefas zumbi excluídas.
Esse gráfico indica o número de tarefas zumbi eliminadas em um curto período de tempo. Tarefas zumbis geralmente são causadas pelo encerramento externo dos processos do Airflow (como quando o processo de uma tarefa é encerrado).
O agendador do Airflow elimina tarefas zumbi periodicamente, o que é refletido neste gráfico.
Selecione a seção Workers, localize o item Reinicializações do contêiner do worker no painel e observe a métrica Reinicializações do contêiner do worker.
- Um gráfico indica o número total de reinicializações de contêineres de worker individuais. Muitas reinicializações de contêineres podem afetar a disponibilidade do seu serviço ou de outros serviços downstream que o usam como uma dependência.
Aprenda comparativos de mercado e possíveis ações corretivas para métricas importantes
A lista a seguir descreve valores de comparativo de mercado que podem indicar problemas e fornece ações corretivas que você pode tomar para resolver esses problemas.
Integridade do ambiente (DAG de monitoramento do Airflow)
Taxa de sucesso inferior a 90% em uma janela de quatro horas
As falhas podem significar remoções de pods ou encerramentos de workers porque o ambiente está sobrecarregado ou com mau funcionamento. As áreas vermelhas na linha do tempo de saúde do ambiente geralmente estão relacionadas às áreas vermelhas nas outras barras de saúde dos componentes individuais do ambiente. Identifique a causa raiz revisando outras métricas no painel do Monitoring.
Integridade do banco de dados
Taxa de sucesso inferior a 95% em uma janela de 4 horas
As falhas significam que há problemas de conectividade com o banco de dados do Airflow, o que pode ser resultado de uma falha ou inatividade do banco de dados porque ele está sobrecarregado (por exemplo, devido ao alto uso de CPU ou memória ou maior latência ao se conectar ao banco de dados). Esses sintomas são causados com mais frequência por DAGs abaixo do ideal, como quando eles usam muitas variáveis de ambiente ou do Airflow definidas globalmente. Identifique a causa raiz revisando as métricas de uso de recursos do banco de dados SQL. Também é possível inspecionar os registros do programador em busca de erros relacionados à conectividade do banco de dados.
Uso de CPU e memória do banco de dados
Mais de 80% de uso médio da CPU ou da memória em um período de 12 horas
O banco de dados pode estar sobrecarregado. Analise a correlação entre as execuções do DAG e os picos no uso de CPU ou memória do banco de dados.
É possível reduzir a carga do banco de dados com DAGs mais eficientes com consultas e conexões em execução otimizadas ou distribuindo a carga de maneira mais uniforme ao longo do tempo.
Como alternativa, aloque mais CPU ou memória para o banco de dados. Os recursos do banco de dados são controlados pela propriedade de tamanho do ambiente, que precisa ser aumentada.
Sinal de funcionamento do programador
Taxa de sucesso inferior a 90% em uma janela de quatro horas
Atribua mais recursos ao programador ou aumente o número de programadores de 1 para 2 (recomendado).
Tarefas zumbi excluídas
Mais de uma tarefa zumbi por 24 horas
O motivo mais comum para tarefas zumbi é a falta de recursos de CPU ou memória no cluster do seu ambiente. Analise os gráficos de uso de recursos do worker e atribua mais recursos a eles ou aumente o tempo limite das tarefas zumbi para que o programador espere mais tempo antes de considerar uma tarefa como zumbi.
Reinicializações do contêiner do worker
Mais de uma reinicialização a cada 24 horas
O motivo mais comum é a falta de memória ou armazenamento do worker. Analise o consumo de recursos do worker e aloque mais memória ou armazenamento para eles. Se a falta de recursos não for o motivo, consulte Solução de problemas de reinicialização do worker e use Consultas de geração de registros para descobrir os motivos das reinicializações.
Criar canais de notificação
Siga as instruções em Criar um canal de notificação para criar um canal de notificação por e-mail.
Para mais informações sobre canais de notificação, consulte Gerenciar canais de notificação.
Criar políticas de alerta
Crie políticas de alertas com base nos comparativos de mercado fornecidos nas seções anteriores deste tutorial para monitorar continuamente os valores das métricas e receber notificações quando elas violarem uma condição.
Console
É possível configurar alertas para cada métrica apresentada no painel do Monitoring clicando no ícone de sino no canto do item correspondente:
Encontre cada métrica que você quer monitorar no painel do Monitoring e clique no ícone de sino no canto do item da métrica. A página Criar política de alertas é aberta.
Na seção Transformar dados:
Configure a seção Em cada série temporal, conforme descrito na configuração das políticas de alerta para a métrica.
Clique em Próxima e configure a seção Configurar o gatilho de alertas conforme descrito na configuração das políticas de alertas para a métrica.
Clique em Próxima.
Configure as notificações. Expanda o menu Canais de notificação e selecione os canais que você criou na etapa anterior.
Clique em OK.
Na seção Nomear a política de alertas, preencha o campo Nome da política de alertas. Use um nome descritivo para cada uma das métricas. Use o valor "Nomeie a política de alertas", conforme descrito na configuração de políticas de alertas para a métrica.
Clique em Próxima.
Analise a política de alertas e clique em Criar política.
Métrica de integridade do ambiente (DAG de monitoramento do Airflow): configurações de política de alertas
- Nome da métrica: ambiente do Cloud Composer - íntegro
- API: composer.googleapis.com/environment/healthy
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformar dados > Em cada série temporal:
- Janela contínua: personalizada
- Valor personalizado: 4
- Unidades personalizadas: hora(s)
- Função de janela contínua: fração "true"
Configure o gatilho de alerta:
- Tipos de condição: limite
- Gatilho de alerta: qualquer série temporal causa uma violação
- Posição do limite: abaixo do limite
- Valor do limite: 90
- Nome da condição: condição de integridade do ambiente
Configure notificações e finalize o alerta:
- Nomeie a política de alertas: "Integridade do ambiente do Airflow"
Métrica de integridade do banco de dados: configurações de política de alertas
- Nome da métrica: Ambiente do Cloud Composer - Banco de dados íntegro
- API: composer.googleapis.com/environment/database_health
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformar dados > Em cada série temporal:
- Janela contínua: personalizada
- Valor personalizado: 4
- Unidades personalizadas: hora(s)
- Função de janela contínua: fração "true"
Configure o gatilho de alerta:
- Tipos de condição: limite
- Gatilho de alerta: qualquer série temporal causa uma violação
- Posição do limite: abaixo do limite
- Valor do limite: 95
- Nome da condição: condição de integridade do banco de dados
Configure notificações e finalize o alerta:
- Nomeie a política de alertas: "Integridade do banco de dados do Airflow"
Métrica de uso da CPU do banco de dados: configurações de política de alertas
- Nome da métrica: ambiente do Cloud Composer - utilização da CPU do banco de dados
- API: composer.googleapis.com/environment/database/cpu/utilization
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformar dados > Em cada série temporal:
- Janela contínua: personalizada
- Valor personalizado: 12
- Unidades personalizadas: hora(s)
- Função de janela contínua: média
Configure o gatilho de alerta:
- Tipos de condição: limite
- Gatilho de alerta: qualquer série temporal causa uma violação
- Posição do limite: acima do limite
- Valor do limite: 80
- Nome da condição: condição de uso da CPU do banco de dados
Configure notificações e finalize o alerta:
- Nomeie a política de alertas: "Uso da CPU do banco de dados do Airflow"
Métrica de uso da memória do banco de dados: configurações da política de alertas
- Nome da métrica: Ambiente do Cloud Composer - Uso da memória do banco de dados
- API: composer.googleapis.com/environment/database/memory/utilization
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformar dados > Em cada série temporal:
- Janela contínua: personalizada
- Valor personalizado: 12
- Unidades personalizadas: hora(s)
- Função de janela contínua: média
Configure o gatilho de alerta:
- Tipos de condição: limite
- Gatilho de alerta: qualquer série temporal causa uma violação
- Posição do limite: acima do limite
- Valor do limite: 80
- Nome da condição: condição de uso da memória do banco de dados
Configure notificações e finalize o alerta:
- Dê o nome "Uso da memória do banco de dados do Airflow" à política de alertas.
Métrica de sinais de funcionamento do programador: configurações de política de alertas
- Nome da métrica: ambiente do Cloud Composer - pulsações do programador
- API: composer.googleapis.com/environment/scheduler_heartbeat_count
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformar dados > Em cada série temporal:
- Janela contínua: personalizada
- Valor personalizado: 4
- Unidades personalizadas: hora(s)
- Função de janela contínua: contagem
Configure o gatilho de alerta:
- Tipos de condição: limite
- Gatilho de alerta: qualquer série temporal causa uma violação
- Posição do limite: abaixo do limite
Valor do limite: 216
- Para saber esse número, execute uma consulta que agregue o valor
_scheduler_heartbeat_count_meanno Editor de consultas do Metrics Explorer.
- Para saber esse número, execute uma consulta que agregue o valor
Nome da condição: condição de sinal de funcionamento do programador
Configure notificações e finalize o alerta:
- Nomeie a política de alertas: "Sinal de funcionamento do programador do Airflow"
Métrica de tarefas zumbi eliminadas: configurações de política de alertas
- Nome da métrica: Ambiente do Cloud Composer - Tarefas zumbi excluídas
- API: composer.googleapis.com/environment/zombie_task_killed_count
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformar dados > Em cada série temporal:
- Janela contínua: 1 dia
- Função de janela contínua: soma
Configure o gatilho de alerta:
- Tipos de condição: limite
- Gatilho de alerta: qualquer série temporal causa uma violação
- Posição do limite: acima do limite
- Valor do limite: 1
- Nome da condição: condição de tarefas zumbi
Configure notificações e finalize o alerta:
- Nomeie a política de alertas: Tarefas zumbi do Airflow
Métrica de reinicializações do contêiner do worker: configurações da política de alertas
- Nome da métrica: contêiner do Kubernetes: contagem de reinicializações
- API: kubernetes.io/container/restart_count
Filtros:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION] pod_name =~ airflow-worker-.*|airflow-k8s-worker-.* container_name =~ airflow-worker|base cluster_name = [CLUSTER_NAME]CLUSTER_NAMEé o nome do cluster do seu ambiente, que pode ser encontrado em Configuração do ambiente > Recursos > Cluster do GKE no console Google Cloud .Transformar dados > Em cada série temporal:
- Janela contínua: 1 dia
- Função de janela contínua: taxa
Configure o gatilho de alerta:
- Tipos de condição: limite
- Gatilho de alerta: qualquer série temporal causa uma violação
- Posição do limite: acima do limite
- Valor do limite: 1
- Nome da condição: condição de reinicializações do contêiner do worker
Configure notificações e finalize o alerta:
- Nomeie a política de alertas: Airflow Worker Restarts
Terraform
Execute um script do Terraform que cria um canal de notificação por e-mail e faz upload de políticas de alertas para as principais métricas fornecidas neste tutorial com base nos respectivos comparativos de mercado:
- Salve o exemplo de arquivo do Terraform no seu computador local.
Substitua:
PROJECT_ID: o ID do projeto do seu projeto. Por exemplo,example-project.EMAIL_ADDRESS: o endereço de e-mail que precisa ser notificado caso um alerta seja acionado.ENVIRONMENT_NAME: o nome do seu ambiente do Cloud Composer. Por exemplo,example-composer-environment.CLUSTER_NAME: o nome do cluster do ambiente, que pode ser encontrado em Configuração do ambiente > Recursos > Cluster do GKE no console Google Cloud .
resource "google_monitoring_notification_channel" "basic" {
project = "PROJECT_ID"
display_name = "Test Notification Channel"
type = "email"
labels = {
email_address = "EMAIL_ADDRESS"
}
# force_delete = false
}
resource "google_monitoring_alert_policy" "environment_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Environment Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Environment health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/healthy\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.9
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "database_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Database Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database_health\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.95
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_cpu_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database CPU Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database CPU usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/cpu/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_memory_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database Memory Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database memory usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/memory/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_scheduler_heartbeat" {
project = "PROJECT_ID"
display_name = "Airflow Scheduler Heartbeat"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Scheduler heartbeat condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/scheduler_heartbeat_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 216 // Threshold is 90% of the average for composer.googleapis.com/environment/scheduler_heartbeat_count metric in an idle environment
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_COUNT"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_zombie_task" {
project = "PROJECT_ID"
display_name = "Airflow Zombie Tasks"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Zombie tasks condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/zombie_task_killed_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_SUM"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_worker_restarts" {
project = "PROJECT_ID"
display_name = "Airflow Worker Restarts"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Worker container restarts condition"
condition_threshold {
filter = "resource.type = \"k8s_container\" AND (resource.labels.cluster_name = \"CLUSTER_NAME\" AND resource.labels.container_name = monitoring.regex.full_match(\"airflow-worker|base\") AND resource.labels.pod_name = monitoring.regex.full_match(\"airflow-worker-.*|airflow-k8s-worker-.*\")) AND metric.type = \"kubernetes.io/container/restart_count\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_RATE"
}
}
}
}
Testar as políticas de alertas
Nesta seção, descrevemos como testar as políticas de alertas criadas e interpretar os resultados.
Fazer upload de um exemplo de DAG
O DAG de exemplo memory_consumption_dag.py fornecido neste tutorial imita
o uso intensivo da memória do worker. O DAG contém quatro tarefas, e cada uma delas grava dados em uma string de amostra, consumindo 380 MB de memória. O DAG de exemplo está programado para ser executado a cada dois minutos e será iniciado automaticamente assim que você o fizer upload para o ambiente do Composer.
Faça upload do seguinte DAG de amostra para o ambiente criado nas etapas anteriores:
from datetime import datetime
import sys
import time
from airflow import DAG
from airflow.operators.python import PythonOperator
def ram_function():
data = ""
start = time.time()
for i in range(38):
data += "a" * 10 * 1000**2
time.sleep(0.2)
print(f"{i}, {round(time.time() - start, 4)}, {sys.getsizeof(data) / (1000 ** 3)}")
print(f"Size={sys.getsizeof(data) / (1000 ** 3)}GB")
time.sleep(30 - (time.time() - start))
print(f"Complete in {round(time.time() - start, 2)} seconds!")
with DAG(
dag_id="memory_consumption_dag",
start_date=datetime(2023, 1, 1, 1, 1, 1),
schedule="1/2 * * * *",
catchup=False,
) as dag:
for i in range(4):
PythonOperator(
task_id=f"task_{i+1}",
python_callable=ram_function,
retries=0,
dag=dag,
)
Interpretar alertas e métricas no Monitoring
Aguarde cerca de 10 minutos após o início da execução do DAG de exemplo e avalie os resultados do teste:
Verifique sua caixa de entrada para confirmar se você recebeu uma notificação do sistema de alertas doGoogle Cloud com o assunto que começa com
[ALERT]. O conteúdo desta mensagem contém os detalhes do incidente da política de alertas.Clique no botão Ver incidente na notificação por e-mail. Você será redirecionado para o Metrics Explorer. Revise os detalhes do incidente de alerta:

Figura 2. Detalhes do incidente de alerta (clique para ampliar) O gráfico de métricas de incidentes indica que as métricas criadas excederam o limite de 1, o que significa que o Airflow detectou e encerrou mais de uma tarefa zumbi.
No ambiente do Cloud Composer, acesse a guia Monitoring, abra a seção Estatísticas do DAG e encontre o gráfico Tarefas zumbi encerradas:

Figura 3. Gráfico de tarefas zumbi (clique para ampliar) O gráfico indica que o Airflow eliminou cerca de 20 tarefas zumbi nos primeiros 10 minutos de execução do DAG de exemplo.
De acordo com os comparativos e as ações corretivas, o motivo mais comum para tarefas zumbi é a falta de memória ou CPU do worker. Identifique a causa raiz das tarefas zumbi analisando a utilização dos recursos do worker.
Abra a seção "Workers" no painel do Monitoring e analise as métricas de uso de CPU e memória do worker:
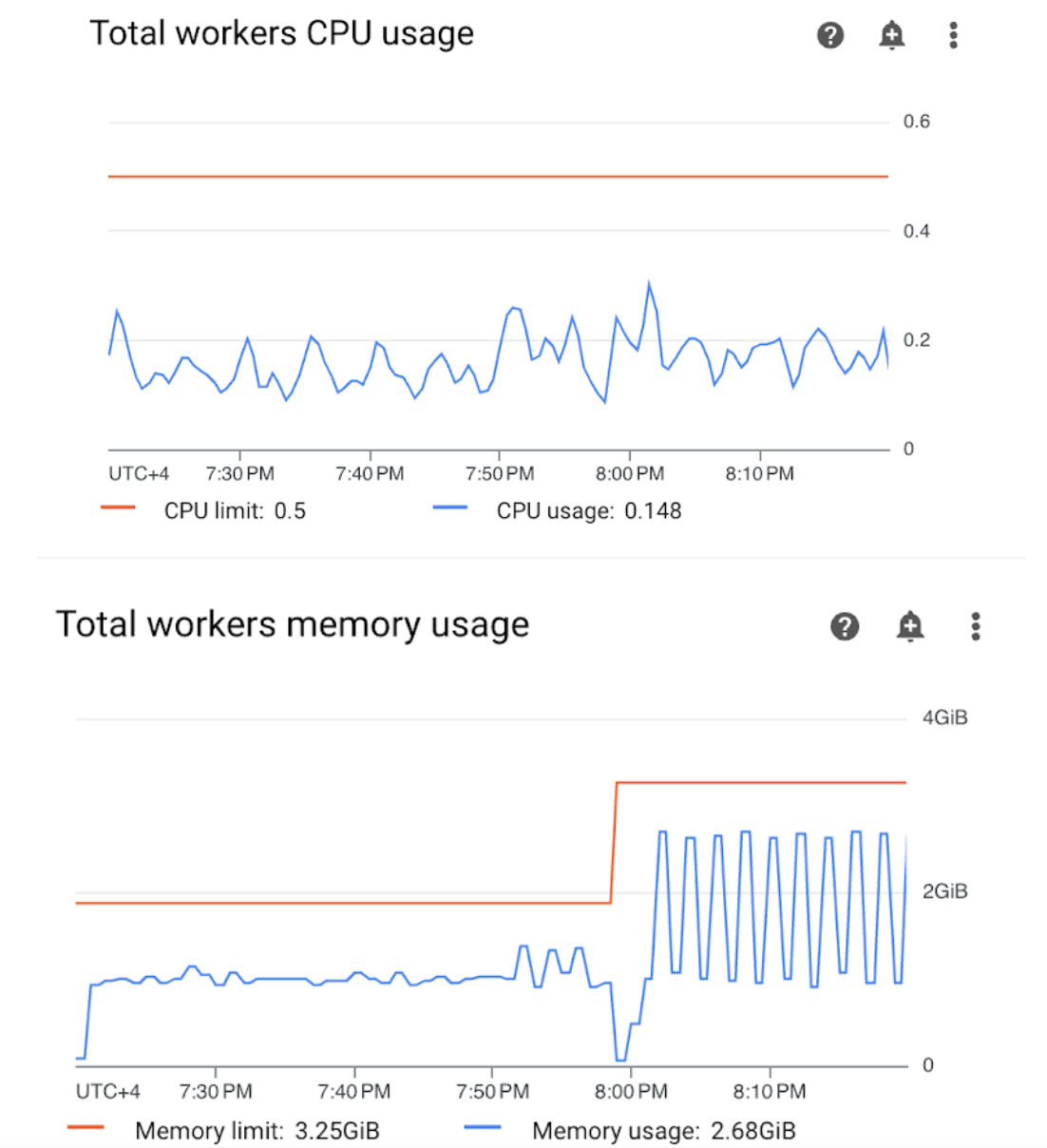
Figura 4.Métricas de uso de CPU e memória do worker (clique para ampliar) O gráfico "Uso total da CPU dos workers" indica que o uso da CPU dos workers ficou abaixo de 50% do limite total disponível em todos os momentos. Portanto, a CPU disponível é suficiente. O gráfico "Uso total de memória de workers" mostra que a execução do DAG de exemplo atingiu o limite de memória alocável, que equivale a quase 75% do limite total de memória mostrado no gráfico. O GKE reserva 25% dos primeiros 4 GiB de memória e mais 100 MiB de memória em cada nó para lidar com a remoção de pods.
Concluímos que os workers não têm os recursos de memória necessários para executar o DAG de exemplo com êxito.
Otimizar o ambiente e avaliar a performance
Com base na análise da utilização de recursos do worker, você precisa alocar mais memória para que todas as tarefas no DAG sejam concluídas.
No ambiente do Composer, abra a guia DAGs, clique no nome do DAG de exemplo (
memory_consumption_dag) e em Pausar DAG.Alocar mais memória para o worker:
Na guia "Configuração do ambiente", encontre a configuração Recursos > Cargas de trabalho e clique em Editar.
No item Worker, aumente o limite de Memória. Neste tutorial, use 3,25 GB.
Salve as mudanças e aguarde alguns minutos para que o worker seja reiniciado.
Abra a guia "DAGs", clique no nome do DAG de exemplo (
memory_consumption_dag) e em Retomar DAG.
Acesse Monitoring e verifique se não apareceram novas tarefas zumbi depois que você atualizou os limites de recursos do worker:

Resumo
Neste tutorial, você aprendeu sobre as principais métricas de integridade e desempenho no nível do ambiente, como configurar políticas de alertas para cada métrica e como interpretar cada uma delas em ações corretivas. Em seguida, você executou um DAG de amostra, identificou a causa raiz dos problemas de integridade do ambiente com a ajuda de alertas e gráficos do Monitoring e otimizou o ambiente alocando mais memória aos workers. No entanto, é recomendável otimizar seus DAGs para reduzir o consumo de recursos do worker, porque não é possível aumentar os recursos além de um determinado limite.
Limpar
Para evitar cobranças na sua conta do Google Cloud pelos recursos usados neste tutorial, exclua o projeto que os contém ou mantenha o projeto e exclua os recursos individuais.
Excluir o projeto
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Excluir recursos individuais
Se você planeja ver vários tutoriais e guias de início rápido, a reutilização de projetos pode evitar que você exceda os limites da cota do projeto.
Console
- Exclua o ambiente do Cloud Composer. Você também exclui o bucket do ambiente durante esse procedimento.
- Exclua cada uma das políticas de alertas que você criou no Cloud Monitoring.
Terraform
- Verifique se o script do Terraform não contém entradas para recursos que ainda são necessários para seu projeto. Por exemplo, talvez você queira manter algumas APIs ativadas e permissões do IAM ainda atribuídas (se você adicionou essas definições ao script do Terraform).
- Execute
terraform destroy. - Exclua manualmente o bucket do ambiente. O Cloud Composer não o exclui automaticamente. É possível fazer isso no console Google Cloud ou na Google Cloud CLI.