Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
이 페이지에서는 Monitoring 대시보드에서 주요 측정항목을 사용하여 전반적인 Cloud Composer 환경 상태와 성능을 모니터링하는 방법을 설명합니다.
소개
이 튜토리얼에서는 환경 수준의 상태 및 성능에 대한 유용한 개요를 제공할 수 있는 주요 Cloud Composer 모니터링 측정항목에 대해 중점적으로 설명합니다.
Cloud Composer는 환경의 전반적인 상태를 설명하는 측정항목을 여러 개 제공합니다. 이 튜토리얼의 모니터링 가이드라인은 Cloud Composer 환경의 모니터링 대시보드에 노출된 측정항목을 기반으로 합니다.
이 튜토리얼에서는 환경 성능 및 상태의 주요 문제 지표 역할을 하는 주요 측정항목과 각 측정항목을 해석하여 환경을 정상으로 유지하기 위한 수정 작업을 파악하는 방법에 대해 알아봅니다. 또한 각 측정항목에 대한 알림 규칙을 설정하고, 예시 DAG를 실행하고, 이러한 측정항목과 알림을 사용하여 환경 성능을 최적화합니다.
목표
비용
이 튜토리얼에서는 비용이 청구될 수 있는 다음과 같은 Google Cloud구성요소를 사용합니다.
이 튜토리얼을 마치면 만든 리소스를 삭제하여 비용이 계속 청구되지 않도록 할 수 있습니다. 자세한 내용은 삭제를 참조하세요.
시작하기 전에
이 섹션에서는 튜토리얼을 시작하기 전에 필요한 작업을 설명합니다.
프로젝트 생성 및 구성
이 튜토리얼을 진행하려면 Google Cloud 프로젝트가 필요합니다. 다음과 같은 방법으로 프로젝트를 구성합니다.
Google Cloud 콘솔에서 프로젝트를 선택하거나 만듭니다.
프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Google Cloud 프로젝트 사용자에게 필요한 리소스를 만들 수 있는 다음 역할이 있는지 확인합니다.
- 환경 및 스토리지 객체 관리자(
roles/composer.environmentAndStorageObjectAdmin) - Compute 관리자(
roles/compute.admin) - 모니터링 편집자 (
roles/monitoring.editor)
- 환경 및 스토리지 객체 관리자(
프로젝트에 API 사용 설정
Enable the Cloud Composer API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Cloud Composer 환경 만들기
이 절차의 일부로 Cloud Composer v2 API 서비스 에이전트 확장(roles/composer.ServiceAgentV2Ext) 역할을 Composer 서비스 에이전트 계정에 부여합니다. Cloud Composer는 이 계정을 사용하여 Google Cloud 프로젝트에서 작업을 수행합니다.
환경 수준 상태와 성능에 대한 주요 측정항목 살펴보기
이 튜토리얼에서는 환경의 전반적인 상태와 성능을 간략하게 설명할 수 있는 주요 측정항목을 중점적으로 설명합니다.
Google Cloud 콘솔의 Monitoring 대시보드에는 환경의 추세를 모니터링하고 Airflow 구성요소와 Cloud Composer 리소스의 문제를 식별할 수 있는 다양한 측정항목과 차트가 포함되어 있습니다.
각 Cloud Composer 환경에는 자체 Monitoring 대시보드가 있습니다.
아래의 주요 측정항목을 숙지하고 Monitoring 대시보드에서 각 측정항목을 찾으세요.
Google Cloud 콘솔에서 환경 페이지로 이동합니다.
환경 목록에서 환경 이름을 클릭합니다. 환경 세부정보 페이지가 열립니다.
Monitoring 탭으로 이동합니다.
개요 섹션을 선택하고 대시보드에서 환경 개요 항목을 찾은 다음 환경 상태(Airflow 모니터링 DAG) 측정항목을 관찰합니다.
이 타임라인에서는 Cloud Composer 환경 상태를 보여줍니다. 환경 상태 표시줄의 녹색은 환경이 정상임을 나타내며 비정상적인 환경 상태는 빨간색으로 표시됩니다.
몇 분마다 Cloud Composer는
airflow_monitoring이라는 활성 DAG를 실행합니다. 활성 DAG 실행이 성공적으로 완료되면 상태는True입니다. 예를 들어 포드 제거, 외부 프로세스 종료 또는 유지보수로 인해 활성 DAG 실행이 실패하면 상태는False입니다.
SQL 데이터베이스 섹션을 선택하고 대시보드에서 데이터베이스 상태 항목을 찾은 후 데이터베이스 상태 측정항목을 관찰합니다.
이 타임라인에서는 환경의 Cloud SQL 인스턴스 연결 상태를 보여줍니다. 녹색 데이터베이스 상태 표시줄은 연결 상태를 나타내며 연결 실패는 빨간색으로 표시됩니다.
Airflow 모니터링 포드가 데이터베이스를 주기적으로 핑하고 연결을 설정할 수 있으면
True로, 설정할 수 없으면False로 상태를 보고합니다.
데이터베이스 상태 항목에서 데이터베이스 CPU 사용량 및 데이터베이스 메모리 사용량 측정항목을 관찰합니다.
데이터베이스 CPU 사용량 그래프는 환경의 Cloud SQL 데이터베이스 인스턴스에서 사용한 CPU 코어와 사용 가능한 총 데이터베이스 CPU 한도를 보여줍니다.
데이터베이스 메모리 사용량 그래프는 환경의 Cloud SQL 데이터베이스 인스턴스에서 사용한 메모리와 사용 가능한 총 데이터베이스 메모리 한도를 보여줍니다.
스케줄러 섹션을 선택하고 대시보드에서 스케줄러 하트비트 항목을 찾은 후 스케줄러 하트비트 측정항목을 관찰합니다.
이 타임라인에서는 Airflow 스케줄러 상태를 보여줍니다. Airflow 스케줄러 문제를 식별하기 위해 빨간색 영역을 확인합니다. 환경에 둘 이상의 스케줄러가 있는 경우 하나 이상의 스케줄러가 응답하는 한 하트비트 상태는 정상입니다.
현재 시간보다 마지막 하트비트가 30초(기본값) 이상 수신되면 비정상 스케줄러로 간주됩니다.
DAG 통계 섹션을 선택하고 대시보드에서 좀비 태스크 종료됨 항목을 찾은 다음 좀비 태스크 종료됨 측정항목을 관찰합니다.
이 그래프는 단기간에 종료된 좀비 태스크 수를 나타냅니다. 좀비 태스크은 종종 Airflow 프로세스의 외부 종료로 인해 발생합니다(예: 작업 프로세스가 종료되는 경우).
Airflow 스케줄러는 좀비 태스크를 주기적으로 종료하며 이는 이 차트에 반영됩니다.
작업자 섹션을 선택하고 대시보드에서 작업자 컨테이너 재시작 수 항목을 찾은 후 작업자 컨테이너 재시작 수 측정항목을 관찰합니다.
- 그래프는 개별 작업자 컨테이너의 총 재시작 수를 나타냅니다. 컨테이너를 지나치게 많이 다시 시작하면 서비스 또는 서비스를 종속 항목으로 사용하는 다른 서비스 다운스트림의 가용성이 영향을 받을 수 있습니다.
주요 측정항목에 대한 벤치마크 및 가능한 수정 작업 알아보기
다음 목록은 문제를 나타낼 수 있는 벤치마크 값을 설명하고 이러한 문제를 해결하기 위해 취할 수 있는 수정 작업을 제공합니다.
환경 상태(Airflow 모니터링 DAG)
4시간 동안의 성공률이 90% 미만임
오류는 환경 과부하나 오작동으로 인한 포드 제거 또는 작업자 종료일 수 있습니다. 환경 상태 타임라인의 빨간색 영역은 일반적으로 개별 환경 구성요소의 다른 상태 표시줄에 있는 빨간색 영역과 상관관계가 있습니다. Monitoring 대시보드에서 다른 측정항목을 검토하여 근본 원인을 식별하세요.
데이터베이스 상태
4시간 동안의 성공률이 95% 미만임
오류가 발생한다는 것은 Airflow 데이터베이스에 연결하는 데 문제가 있음을 의미합니다. 이는 데이터베이스 과부하로 인한 데이터베이스 비정상 종료 또는 다운타임이 원인일 수 있습니다(예를 들어, 데이터베이스에 연결하는 동안의 높은 CPU 또는 메모리 사용량, 또는 긴 지연시간). 이러한 증상은 DAG가 전역적으로 정의된 여러 Airflow 또는 환경 변수를 사용하는 경우와 같이 최적이 아닌 DAG로 인해 가장 자주 발생합니다. SQL 데이터베이스 리소스 사용량 측정항목을 검토하여 근본 원인을 식별하세요. 또한 스케줄러 로그에서 데이터베이스 연결과 관련된 오류를 검사할 수 있습니다.
데이터베이스 CPU 및 메모리 사용량
12시간 동안 평균 CPU 또는 메모리 사용량 80% 초과
데이터베이스에 과부하가 발생했을 수 있습니다. DAG 실행과 데이터베이스 CPU 또는 메모리 사용량 급증의 상관관계를 분석하세요.
최적화된 실행 중인 쿼리 및 연결을 사용하여 더 효율적인 DAG를 통해 또는 시간 경과에 따라 부하를 더 고르게 분산하여 데이터베이스 부하를 줄일 수 있습니다.
대안으로 데이터베이스에 더 많은 CPU나 메모리를 할당할 수 있습니다. 데이터베이스 리소스는 환경의 환경 크기 속성에 따라 제어되며 환경은 더 큰 크기로 확장되어야 합니다.
스케줄러 하트비트
4시간 동안의 성공률이 90% 미만임
스케줄러에 리소스를 할당하거나 스케줄러 수를 1에서 2로 늘립니다(권장).
좀비 태스크 종료됨
24시간당 좀비 태스크 2개 이상
좀비 태스크의 가장 일반적인 이유는 환경 클러스터의 CPU 및 메모리 리소스 부족입니다. 작업자 리소스 사용량 그래프를 검토하고 작업자에 리소스를 더 할당하거나 좀비 태스크 제한 시간을 늘려 스케줄러가 태스크를 좀비로 간주하기 전에 더 오래 기다리게 합니다.
작업자 컨테이너 재시작 수
24시간당 재시작 횟수가 1회 이상
가장 일반적인 이유는 작업자 메모리나 스토리지 부족입니다. 작업자 리소스 소비를 확인하고 작업자에 더 많은 메모리나 스토리지를 할당하세요. 리소스 부족이 원인이 아닌 경우 작업자 재시작 이슈 해결을 살펴보고 Logging 쿼리를 사용하여 작업자 재시작의 이유를 알아보세요.
알림 채널 만들기
알림 채널 만들기에 설명된 안내에 따라 이메일 알림 채널을 만듭니다.
알림 채널에 대한 자세한 내용은 알림 채널 관리를 참조하세요.
알림 정책 만들기
이 튜토리얼의 이전 섹션에서 제공된 벤치마크를 기반으로 알림 정책을 만들어 측정항목 값을 지속적으로 모니터링하고 측정항목이 조건을 위반하면 알림을 받습니다.
콘솔
해당 항목의 모서리에 있는 종 모양 아이콘을 클릭하여 Monitoring 대시보드에 표시된 각 측정항목에 대해 알림을 설정할 수 있습니다.
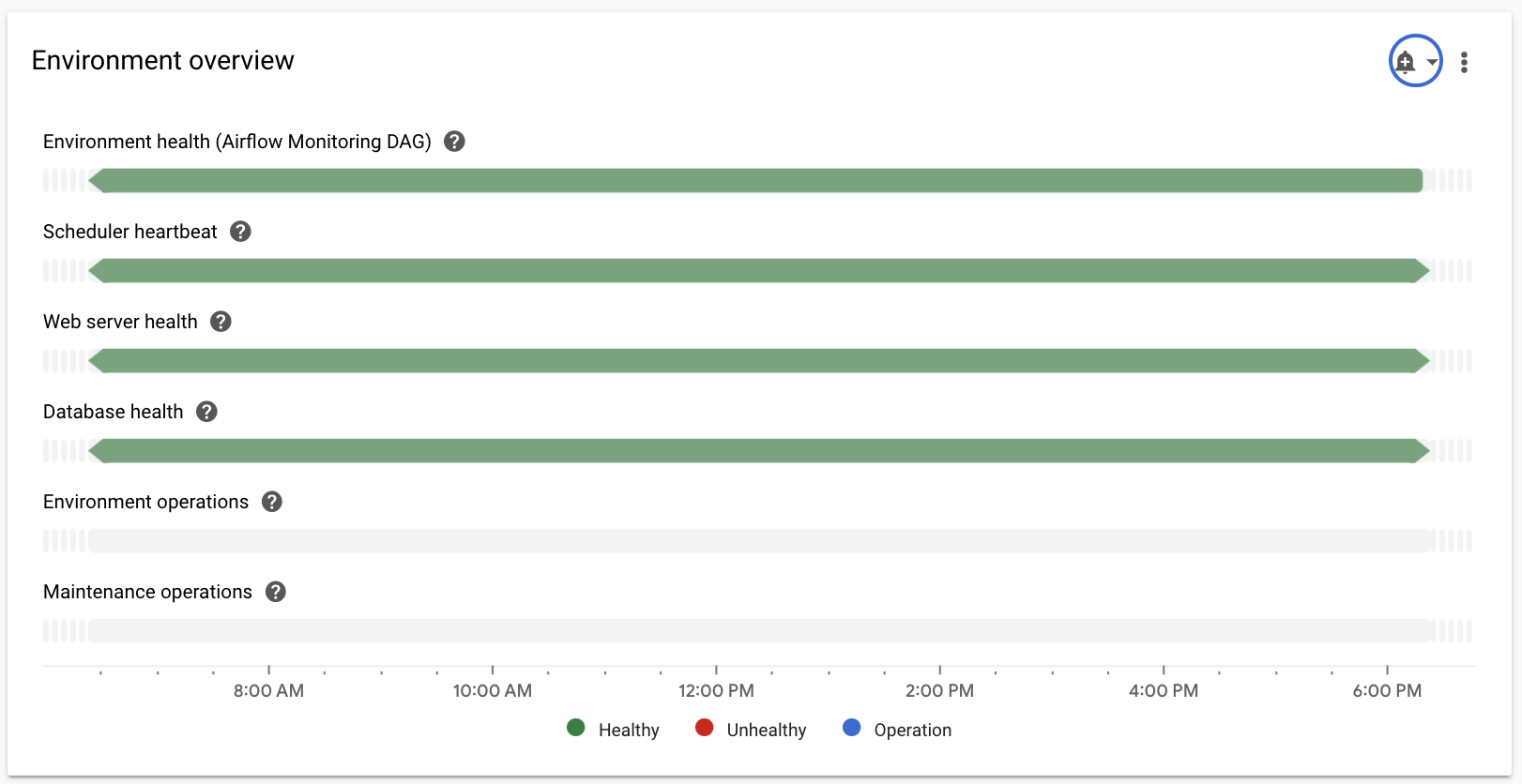
Monitoring 대시보드에서 모니터링할 각 측정항목을 찾아 측정항목 항목 모서리에 있는 종 모양 아이콘을 클릭합니다. 알림 정책 만들기 페이지가 열립니다.
데이터 변환 섹션에서 다음을 수행합니다.
측정항목의 알림 정책 구성에 설명된 대로 각 시계열 내 섹션을 구성하세요.
다음을 클릭한 후 측정항목의 알림 정책 구성의 설명대로 알림 트리거 구성 섹션을 구성합니다.
다음을 클릭합니다.
알림을 구성합니다. 알림 채널 메뉴를 펼치고 이전 단계에서 만든 알림 채널을 선택합니다.
확인을 클릭합니다.
알림 정책 이름 지정 섹션에서 알림 정책 이름 필드를 작성합니다. 각 측정항목에 대해 설명적인 이름을 사용합니다. 측정항목의 알림 정책 구성에 설명된 대로 '알림 정책 이름 지정' 값을 사용합니다.
다음을 클릭합니다.
알림 정책을 검토한 후 정책 만들기를 클릭합니다.
환경 상태(Airflow 모니터링 DAG) 측정항목 - 알림 정책 구성
- 측정항목 이름: Cloud Composer Environment - Healthy
- API: composer.googleapis.com/environment/healthy
필터:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]데이터 변환 > 각 시계열 내:
- 순환 기간: 커스텀
- 커스텀 값: 4
- 커스텀 단위: 시간
- 순환 기간 함수: 참 비율
알림 트리거 구성:
- 조건 유형: 기준점
- 알림 트리거: 모든 시계열 위반
- 기준 위치: 기준점 미만
- 기준 값: 90
- 조건 이름: 환경 상태 조건
알림 구성 및 완료:
- 알림 정책 이름 지정: Airflow 환경 상태
데이터베이스 상태 측정항목 - 알림 정책 구성
- 측정항목 이름: Cloud Composer Environment - Database Healthy
- API: composer.googleapis.com/environment/database_health
필터:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]데이터 변환 > 각 시계열 내:
- 순환 기간: 커스텀
- 커스텀 값: 4
- 커스텀 단위: 시간
- 순환 기간 함수: 참 비율
알림 트리거 구성:
- 조건 유형: 기준점
- 알림 트리거: 모든 시계열 위반
- 기준 위치: 기준점 미만
- 기준 값: 95
- 조건 이름: 데이터베이스 상태 조건
알림 구성 및 완료:
- 알림 정책 이름 지정: Airflow 환경 상태
데이터베이스 CPU 사용량 측정항목 - 알림 정책 구성
- 측정항목 이름: Cloud Composer Environment - Database CPU Utilization
- API: composer.googleapis.com/environment/database/cpu/utilization
필터:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]데이터 변환 > 각 시계열 내:
- 순환 기간: 커스텀
- 커스텀 값: 12
- 커스텀 단위: 시간
- 순환 기간 함수: 평균
알림 트리거 구성:
- 조건 유형: 기준점
- 알림 트리거: 모든 시계열 위반
- 기준 위치: 기준점 초과
- 기준 값: 80
- 조건 이름: 데이터베이스 CPU 사용량 조건
알림 구성 및 완료:
- 알림 정책 이름 지정: Airflow 데이터베이스 CPU 사용량
데이터베이스 메모리 사용량 측정항목 - 알림 정책 구성
- 측정항목 이름: Cloud Composer Environment - Database Memory Utilization
- API: composer.googleapis.com/environment/database/memory/utilization
필터:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]데이터 변환 > 각 시계열 내:
- 순환 기간: 커스텀
- 커스텀 값: 12
- 커스텀 단위: 시간
- 순환 기간 함수: 평균
알림 트리거 구성:
- 조건 유형: 기준점
- 알림 트리거: 모든 시계열 위반
- 기준 위치: 기준점 초과
- 기준 값: 80
- 조건 이름: 데이터베이스 메모리 사용량 조건
알림 구성 및 완료:
- 알림 정책 이름 지정: Airflow 데이터베이스 메모리 사용량
스케줄러 하트비트 측정항목 - 알림 정책 구성
- 측정항목 이름: Cloud Composer Environment - Scheduler Heartbeats
- API: composer.googleapis.com/environment/scheduler_heartbeat_count
필터:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]데이터 변환 > 각 시계열 내:
- 순환 기간: 커스텀
- 커스텀 값: 4
- 커스텀 단위: 시간
- 순환 기간 함수: 개수
알림 트리거 구성:
- 조건 유형: 기준점
- 알림 트리거: 모든 시계열 위반
- 기준 위치: 기준점 미만
기준 값: 216
- 측정항목 탐색기 쿼리 편집기에서
_scheduler_heartbeat_count_mean값을 집계하는 쿼리를 실행하여 이 수를 가져올 수 있습니다.
- 측정항목 탐색기 쿼리 편집기에서
조건 이름: 스케줄러 하트비트 조건
알림 구성 및 완료:
- 알림 정책 이름 지정: Airflow 스케줄러 하트비트
좀비 태스크 종료됨 측정항목 - 알림 정책 구성
- 측정항목 이름: Cloud Composer Environment - Zombie Tasks Killed
- API: composer.googleapis.com/environment/zombie_task_killed_count
필터:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]데이터 변환 > 각 시계열 내:
- 순환 기간: 1일
- 순환 기간 함수: 합계
알림 트리거 구성:
- 조건 유형: 기준점
- 알림 트리거: 모든 시계열 위반
- 기준 위치: 기준점 초과
- 기준 값: 1
- 조건 이름: 좀비 태스크 조건
알림 구성 및 완료:
- 알림 정책 이름 지정: Airflow 좀비 태스크
작업자 컨테이너 재시작 측정항목 - 알림 정책 구성
- 측정항목 이름: Kubernetes 컨테이너 - 다시 시작 횟수
- API: kubernetes.io/container/restart_count
필터:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION] pod_name =~ airflow-worker-.*|airflow-k8s-worker-.* container_name =~ airflow-worker|base cluster_name = [CLUSTER_NAME]CLUSTER_NAME은 환경의 클러스터 이름으로, Google Cloud 콘솔의 환경 구성 > 리소스 > GKE 클러스터에서 찾을 수 있습니다.데이터 변환 > 각 시계열 내:
- 순환 기간: 1일
- 순환 기간 함수: 비율
알림 트리거 구성:
- 조건 유형: 기준점
- 알림 트리거: 모든 시계열 위반
- 기준 위치: 기준점 초과
- 기준 값: 1
- 조건 이름: 작업자 컨테이너 재시작 조건
알림 구성 및 완료:
- 알림 정책 이름 지정: Airflow 작업자 다시 시작
Terraform
이메일 알림 채널을 만들고 이 튜토리얼에 제공된 주요 측정항목의 알림 정책을 각 벤치마크에 따라 업로드하는 Terraform 스크립트를 실행합니다.
- 예시 Terraform 파일을 로컬 컴퓨터에 저장합니다.
다음을 바꿉니다.
PROJECT_ID: 프로젝트의 프로젝트 ID. 예를 들면example-project입니다.EMAIL_ADDRESS: 알림이 트리거될 때 알림을 보내야 하는 이메일 주소입니다.ENVIRONMENT_NAME: Cloud Composer 환경 이름입니다. 예를 들면example-composer-environment입니다.CLUSTER_NAME: Google Cloud 콘솔의 환경 구성 > 리소스 > GKE 클러스터에서 찾을 수 있는 환경 클러스터 이름입니다.
resource "google_monitoring_notification_channel" "basic" {
project = "PROJECT_ID"
display_name = "Test Notification Channel"
type = "email"
labels = {
email_address = "EMAIL_ADDRESS"
}
# force_delete = false
}
resource "google_monitoring_alert_policy" "environment_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Environment Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Environment health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/healthy\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.9
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "database_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Database Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database_health\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.95
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_cpu_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database CPU Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database CPU usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/cpu/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_memory_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database Memory Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database memory usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/memory/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_scheduler_heartbeat" {
project = "PROJECT_ID"
display_name = "Airflow Scheduler Heartbeat"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Scheduler heartbeat condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/scheduler_heartbeat_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 216 // Threshold is 90% of the average for composer.googleapis.com/environment/scheduler_heartbeat_count metric in an idle environment
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_COUNT"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_zombie_task" {
project = "PROJECT_ID"
display_name = "Airflow Zombie Tasks"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Zombie tasks condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/zombie_task_killed_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_SUM"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_worker_restarts" {
project = "PROJECT_ID"
display_name = "Airflow Worker Restarts"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Worker container restarts condition"
condition_threshold {
filter = "resource.type = \"k8s_container\" AND (resource.labels.cluster_name = \"CLUSTER_NAME\" AND resource.labels.container_name = monitoring.regex.full_match(\"airflow-worker|base\") AND resource.labels.pod_name = monitoring.regex.full_match(\"airflow-worker-.*|airflow-k8s-worker-.*\")) AND metric.type = \"kubernetes.io/container/restart_count\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_RATE"
}
}
}
}
알림 정책 테스트
이 섹션에서는 생성된 알림 정책을 테스트하고 결과를 해석하는 방법을 설명합니다.
샘플 DAG 업로드
이 튜토리얼에서 제공하는 샘플 DAG memory_consumption_dag.py는 집중적인 작업자 메모리 사용률을 모방합니다. DAG에는 태스크 4개가 포함되어 있으며 각 태스크는 데이터를 샘플 문자열에 쓰고 메모리 380MB를 사용합니다. 샘플 DAG는 2분마다 실행되도록 예약되며 Composer 환경에 업로드되면 자동으로 실행됩니다.
다음 샘플 DAG를 이전 단계에서 만든 환경에 업로드합니다.
from datetime import datetime
import sys
import time
from airflow import DAG
from airflow.operators.python import PythonOperator
def ram_function():
data = ""
start = time.time()
for i in range(38):
data += "a" * 10 * 1000**2
time.sleep(0.2)
print(f"{i}, {round(time.time() - start, 4)}, {sys.getsizeof(data) / (1000 ** 3)}")
print(f"Size={sys.getsizeof(data) / (1000 ** 3)}GB")
time.sleep(30 - (time.time() - start))
print(f"Complete in {round(time.time() - start, 2)} seconds!")
with DAG(
dag_id="memory_consumption_dag",
start_date=datetime(2023, 1, 1, 1, 1, 1),
schedule="1/2 * * * *",
catchup=False,
) as dag:
for i in range(4):
PythonOperator(
task_id=f"task_{i+1}",
python_callable=ram_function,
retries=0,
dag=dag,
)
Monitoring에서 알림 및 측정항목 해석
샘플 DAG 실행이 시작된 후 약 10분 정도 기다렸다가 테스트 결과를 평가합니다.
이메일 편지함을 확인하여Google Cloud Alerting에서
[ALERT]로 시작하는 제목의 알림을 받았는지 확인합니다. 이 메시지에는 알림 정책 이슈 세부정보가 포함되어 있습니다.이메일 알림에서 이슈 보기 버튼을 클릭합니다. 측정항목 탐색기로 리디렉션됩니다. 알림 이슈 세부정보를 검토합니다.
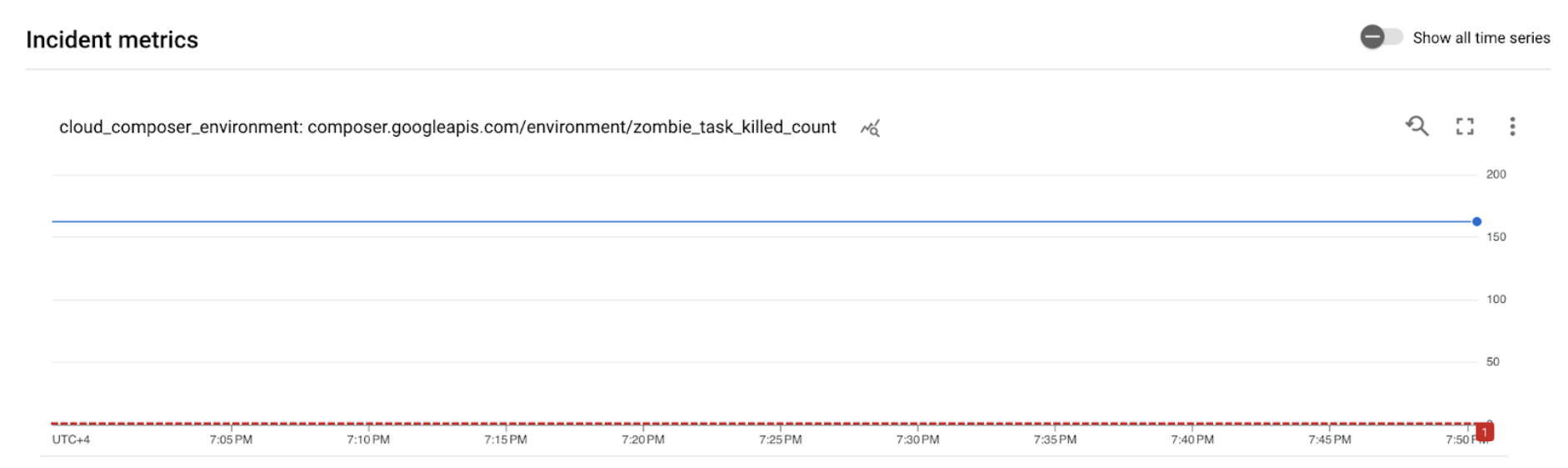
그림 2. 알림 이슈 세부정보(확대하려면 클릭) 이슈 측정항목 그래프에 따르면 생성된 측정항목이 1이라는 기준을 초과했습니다. 즉, Airflow에서 좀비 태스크를 1개 이상 감지하고 종료했습니다.
Cloud Composer 환경에서 모니터링 탭 > DAG 통계 섹션 > 좀비 태스크 종료됨 그래프를 찾습니다.
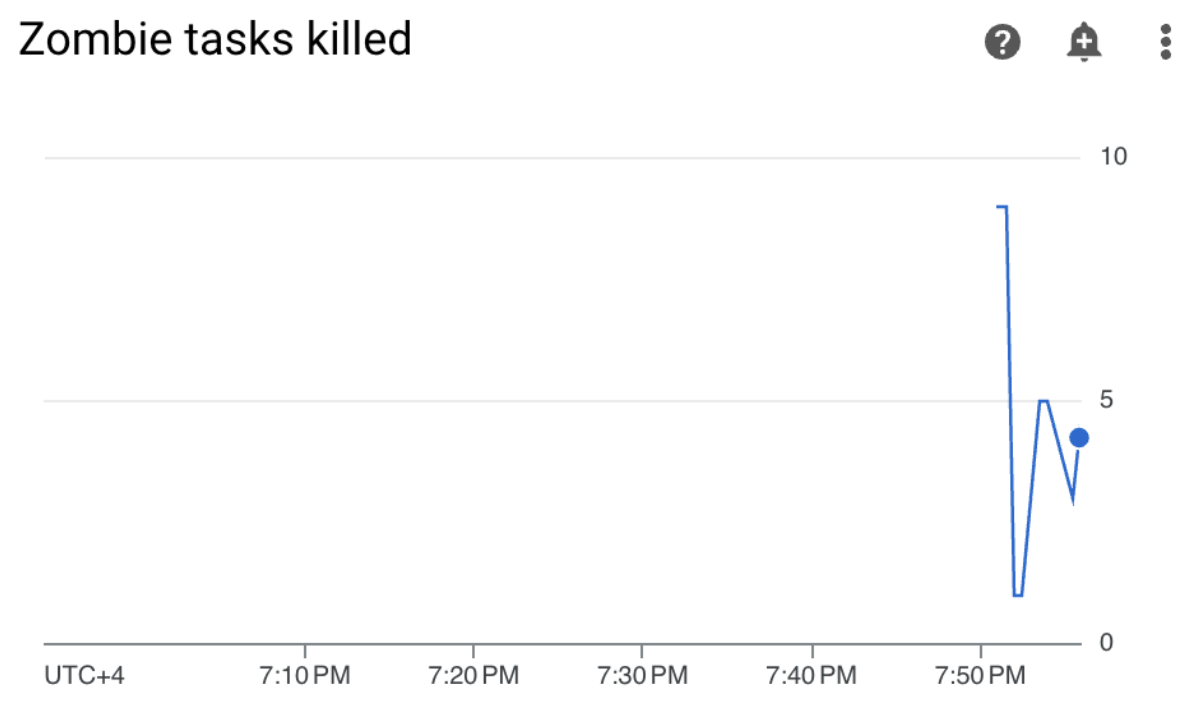
그림 3. 좀비 태스크 그래프(확대하려면 클릭) 이 그래프는 샘플 DAG를 실행한 지 10분 만에 Airflow에서 좀비 태스크를 약 20개 정도 종료했음을 나타냅니다.
벤치마크 및 수정 작업에 따르면 좀비 태스크의 가장 일반적인 이유는 작업자 메모리 또는 CPU 부족입니다. 작업자 리소스 사용률을 분석하여 좀비 태스크의 근본 원인을 파악합니다.
Monitoring 대시보드에서 작업자 섹션을 열고 작업자 CPU 및 메모리 사용량 측정항목을 검토합니다.
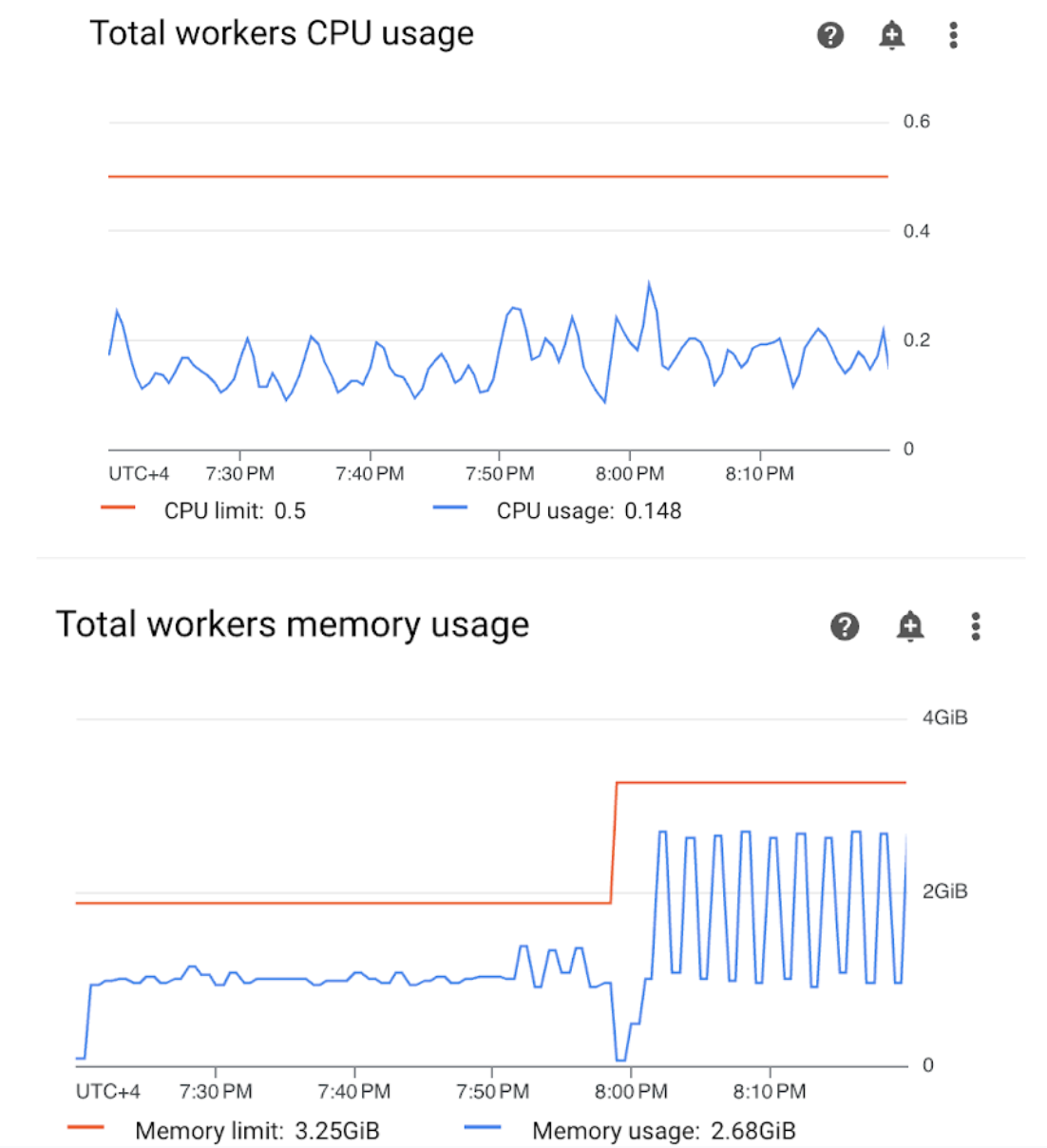
그림 4.작업자 CPU 및 메모리 사용량 측정항목(클릭 확대) 총 작업자 CPU 사용량 그래프는 작업자 CPU 사용량이 항상 사용 가능한 총 한도의 50% 미만이므로 사용 가능한 CPU가 충분함을 나타냅니다. 총 작업자 메모리 사용량 그래프는 샘플 DAG를 실행한 결과 그래프에 표시된 총 메모리 한도의 약 75%에 해당하는 할당 가능한 메모리 한도에 도달한 것을 보여줍니다(GKE는 처음 총 메모리 4GiB 중 25%를 예약하며, 포드 제거를 처리하기 위한 모든 노드에서 추가로 100MiB의 메모리를 예약합니다).
사용자는 샘플 DAG를 성공적으로 실행하기 위한 메모리 리소스가 작업자에 부족하다고 결론을 내릴 수 있습니다.
환경 최적화 및 성능 평가
작업자 리소스 사용률 분석에 따라 DAG의 모든 태스크가 성공할 수 있도록 작업자에게 더 많은 메모리를 할당해야 합니다.
Composer 환경에서 DAG 탭을 열고 샘플 DAG(
memory_consumption_dag) 이름을 클릭한 후 DAG 일시중지를 클릭합니다.추가 작업자 메모리를 할당합니다.
환경 구성 탭에서 리소스 > 워크로드 구성을 찾고 수정을 클릭합니다.
작업자 항목에서 메모리 한도를 늘립니다. 이 튜토리얼에서는 3.25GB를 사용합니다.
변경사항을 저장하고 작업자가 다시 시작될 때까지 몇 분 정도 기다립니다.
DAG 탭을 열고 샘플 DAG 이름(
memory_consumption_dag)을 클릭한 후 DAG 재개를 클릭합니다.
Monitoring으로 이동하여 작업자 리소스 한도를 업데이트한 이후에 새 좀비 태스크가 발견되지 않았는지 확인합니다.

요약
이 튜토리얼에서 지금까지 주요 환경 수준 상태 및 성능 측정항목, 각 측정항목에 대한 알림 정책 설정 방법, 각 측정항목을 수정 작업으로 해석하는 방법을 알아보았습니다. 그런 다음 샘플 DAG를 실행하고 알림 및 Monitoring 차트를 사용하여 환경 상태 문제의 근본 원인을 파악하고 작업자에게 더 많은 메모리를 할당하여 환경을 최적화했습니다. 그러나 특정 기준점 이상으로 리소스를 늘릴 수 없으므로 애초에 작업자 리소스 소비를 줄이려면 DAG를 최적화하는 것이 좋습니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트는 유지하되 개별 리소스를 삭제하세요.
프로젝트 삭제
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
개별 리소스 삭제
여러 튜토리얼과 빠른 시작을 살펴보려는 경우 프로젝트를 재사용하면 프로젝트 할당량 한도 초과를 방지할 수 있습니다.
콘솔
- Cloud Composer 환경을 삭제합니다. 이 절차 동안의 환경 버킷도 삭제합니다.
- Cloud Monitoring에서 만든 각 알림 정책을 삭제합니다.
Terraform
- 프로젝트에 여전히 필요한 리소스 항목이 Terraform 스크립트에 포함되어 있지 않은지 확인합니다. 예를 들어 일부 API를 사용하도록 설정하고 IAM 권한을 계속 할당된 상태로 유지할 수 있습니다(Terraform 스크립트에 이러한 정의를 추가한 경우).
terraform destroy를 실행합니다.- 환경의 버킷을 수동으로 삭제합니다. Cloud Composer는 자동으로 삭제하지 않습니다. 이 작업은 Google Cloud 콘솔 또는 Google Cloud CLI에서 수행할 수 있습니다.