Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
このページでは、Monitoring ダッシュボードの主な指標を使用して、Cloud Composer 環境全体の健全性とパフォーマンスをモニタリングする方法について説明します。
はじめに
このチュートリアルでは、環境レベルの健全性とパフォーマンスの概要を示すことができる重要な Cloud Composer のモニタリング指標に焦点を当てています。
Cloud Composer には、環境の全体的な状態を記述する複数の指標が用意されています。このチュートリアルのモニタリング ガイドラインは、Cloud Composer 環境のモニタリング ダッシュボードに公開されている指標に基づいています。
このチュートリアルでは、環境のパフォーマンスと健全性に関する問題の主な指標として機能する主要な指標と、各指標を是正措置として解釈して、環境を健全に保つためのガイドラインについて説明します。また、各指標のアラートルールを設定し、サンプル DAG を実行し、これらの指標とアラートを使用して環境のパフォーマンスを最適化します。
目標
費用
このチュートリアルでは、課金対象である次の Google Cloudコンポーネントを使用します。
このチュートリアルを終了した後、作成したリソースを削除すると、それ以上の請求は発生しません。詳しくは、クリーンアップをご覧ください。
準備
このセクションでは、チュートリアルを開始する前に必要な作業について説明します。
プロジェクトを作成して構成する
このチュートリアルでは Google Cloudプロジェクトが必要です。プロジェクトは、次のように構成します:
Google Cloud コンソールで、プロジェクトを選択または作成します:
プロジェクトに対して課金が有効になっていることを確認します。、プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Google Cloud プロジェクト ユーザーに、必要なリソースを作成するための次のロールがあることを確認します。
- 環境とストレージ オブジェクトの管理者
(
roles/composer.environmentAndStorageObjectAdmin) - Compute 管理者(
roles/compute.admin) - Monitoring 編集者(
roles/monitoring.editor)
- 環境とストレージ オブジェクトの管理者
(
プロジェクトでAPI を有効にする
Enable the Cloud Composer API.
Cloud Composer 環境を作成する
この手順の一環として、Cloud Composer v2 API サービス エージェント拡張機能(roles/composer.ServiceAgentV2Ext)ロールを Composer サービス エージェント アカウントに付与します。Cloud Composer は、このアカウントを使用して Google Cloud プロジェクトでオペレーションを実行します。
環境レベルの健全性とパフォーマンスに関する主要な指標を確認する
このチュートリアルでは、環境の全体的な健全性とパフォーマンスの概要を良好に示すことができる主要な指標に焦点を当てています。
Google Cloud コンソールの Monitoring ダッシュボードには、環境の傾向をモニタリングし、Airflow コンポーネントと Cloud Composer リソースに関する問題を特定するためのさまざまな指標とグラフが用意されています。
各 Cloud Composer 環境には独自の Monitoring ダッシュボードがあります。
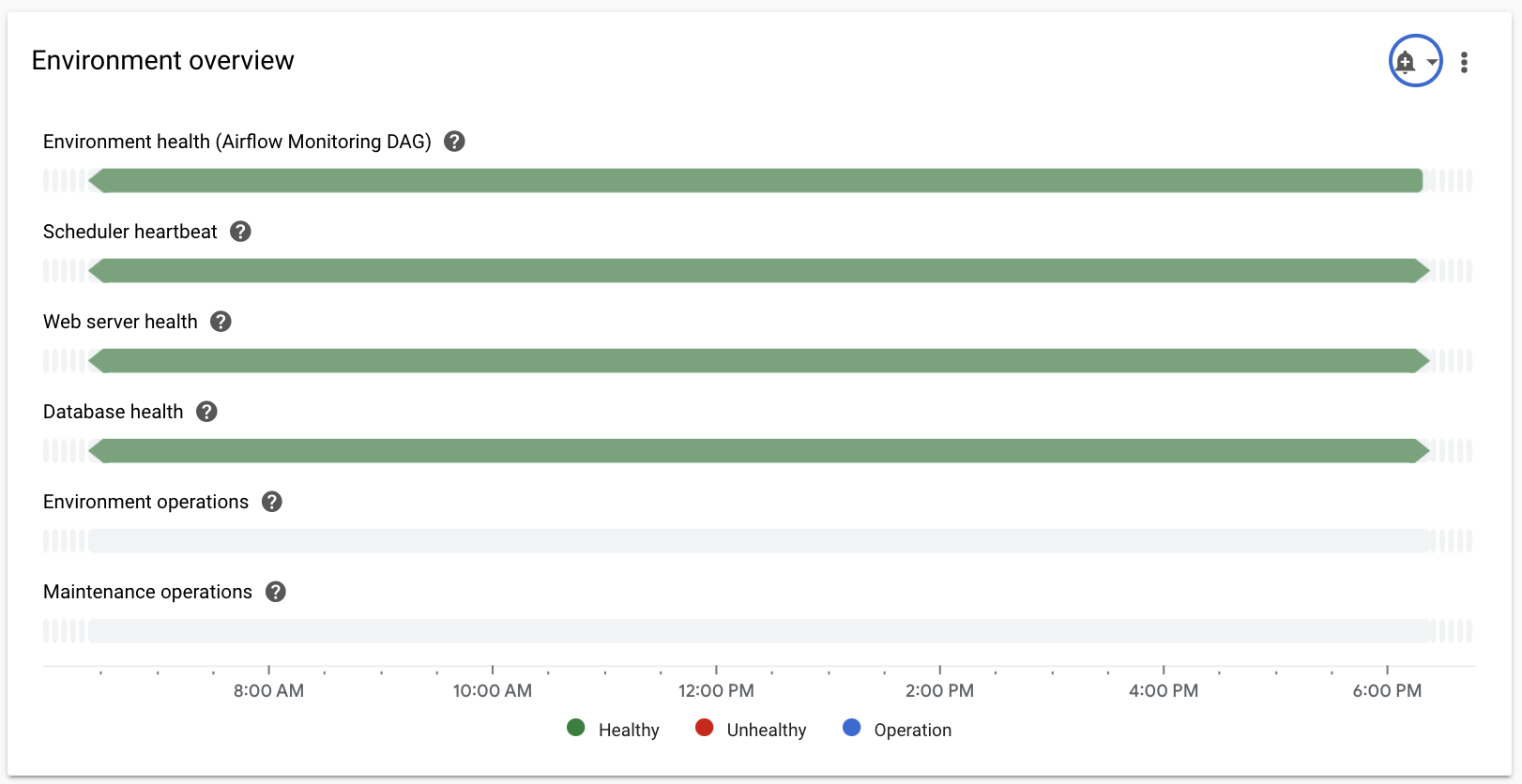
以下の主要な指標を把握し、Monitoring ダッシュボードで各指標を確認します。
Google Cloud コンソールで [環境] ページに移動します。
環境のリストで、ご利用の環境の名前をクリックします。[環境の詳細] ページが開きます。
[Monitoring] タブに移動します。
[概要] セクションを選択し、ダッシュボードの [環境の概要] 項目を見つけて、[環境の健全性(Airflow モニタリング DAG)] 指標を確認します。
このタイムラインは、Cloud Composer 環境の健全性を示します。緑色の環境の健全性バーは、環境が正常であることを示し、異常な環境のステータスは赤で示されます。
Cloud Composer は、
airflow_monitoringという名前の liveness DAG を数分ごとに実行します。liveness DAG の実行が正常に終了すると、健全性のステータスはTrueになります。liveness DAG の実行に失敗した場合(Pod のエビクション、外部のプロセスの終了、メンテナンスなど)、健全性のステータスはFalseになります。
[SQL データベース] セクションを選択し、ダッシュボードの [データベースの健全性] 項目を見つけて、[データベースの健全性] 指標を確認します。
このタイムラインには、環境の Cloud SQL インスタンスへの接続のステータスが表示されます。緑色のデータベースの健全性バーは接続を示し、接続に失敗した場合は赤色で表示されます。
Airflow Monitoring Pod はデータベースを定期的に ping し、接続を確立できる場合は
True、確立できない場合はFalseとして健全性のステータスを報告します。
[データベースの状態] 項目で、[データベースの CPU 使用量] と [データベースのメモリ使用量] の指標を確認します。
データベースの CPU 使用率のグラフは、環境の Cloud SQL データベース インスタンスによる CPU コアの使用率と、使用可能なデータベースの CPU 上限の合計を示します。
データベースのメモリ使用量のグラフは、環境の Cloud SQL データベース インスタンスによるメモリ使用量と、使用可能なデータベースのメモリ上限の合計を示します。
[スケジューラ] セクションを選択し、ダッシュボードで [スケジューラのハートビート] 項目を見つけて、[スケジューラのハートビート] の指標を確認します。
このタイムラインには、Airflow スケジューラの正常性が表示されます。 Airflow スケジューラの問題を特定するには、赤い領域を確認します。 環境に複数のスケジューラがある場合、少なくとも 1 つのスケジューラが応答している限り、ハートビートのステータスは正常です。
最後のハートビートの受信が現在の時刻の 30 秒(デフォルト値)を超えた場合、スケジューラは異常とみなされます。
[DAG の統計情報] セクションを選択し、ダッシュボードで [強制終了されたゾンビタスク] 項目を見つけて、[強制終了されたゾンビタスク] の指標を確認します。
このグラフは、短い時間枠で強制終了されたゾンビタスクの数を示しています。ゾンビタスクは、多くの場合、外部での Airflow プロセスの終了によって発生します(タスクのプロセスが強制終了された場合など)。
Airflow スケジューラは、ゾンビタスクを定期的に強制終了します。それは、このグラフに反映されています。
[ワーカー] セクションを選択し、ダッシュボードで [ワーカー コンテナの再起動] 項目を見つけて、[ワーカー コンテナの再起動] の指標を確認します。
- グラフは、個々のワーカー コンテナが再起動する合計回数を示します。過剰なコンテナの再起動は、サービスまたはサービスを依存関係として使用するダウンストリームの他のサービスの可用性に影響する可能性があります。
主な指標に関するベンチマークと可能な是正措置について確認する
次のリストに、問題を示唆するベンチマーク値と、これらの問題に対処するために実施できる修正措置を示します。
環境の健全性(Airflow モニタリング DAG)
4 時間の時間枠で 90% 未満の成功率
障害は、環境が過負荷であるか、誤動作することによる Pod の強制排除やワーカーの終了を示している可能性があります。環境の健全性タイムラインの赤色の領域は、通常、個々の環境コンポーネントの他の健全性バーにある赤色の領域と相関しています。Monitoring ダッシュボードで他の指標を確認して、根本原因を特定します。
データベースのヘルス
4 時間の時間枠で 95% 未満の成功率
障害とは、Airflow データベースへの接続に問題があることを意味します。これは、データベースが過負荷状態(たとえば、データベース接続中の CPU 使用率が高い、またはやメモリ使用量が多いなど)であることによる、データベースのクラッシュやダウンタイムが考えられます。最適ではない DAG(例: DAG がグローバルに定義された多くの Airflow 変数または環境変数を使用している)が、このような現象の最も頻繁に見られる原因です。SQL データベースのリソース使用率の指標を確認して、根本原因を特定します。スケジュール設定ログで、データベース接続に関連するエラーを確認することもできます。
データベースの CPU とメモリの使用率
12 時間の期間における平均 CPU 使用率またはメモリ使用率が 80% を超えている
データベースが過負荷状態になっている可能性があります。DAG の実行とデータベースの CPU またはメモリ使用量の急増との相関を分析します。
実行中のクエリと接続の最適化による効率的な DAG を通じて、または負荷を時間の経過とともに均等に分散させることで、データベースの負荷を軽減できます。
または、データベースに CPU またはメモリをさらに割り当てることもできます。データベース リソースは環境の環境サイズ プロパティで制御されます。環境は大きなサイズにスケーリングする必要があります。
スケジューラのハートビート
4 時間の時間枠で 90% 未満の成功率
スケジューラにリソースを追加するか、スケジューラの数を 1 から 2 に増やします(推奨)。
強制終了したゾンビタスク
24 時間に複数のゾンビタスク
ゾンビタスクの最も一般的な理由は、環境のクラスタ内の CPU リソースやメモリリソースが不足していることです。ワーカー リソースの使用状況のグラフを確認し、ワーカーにより多くのリソースを割り当てます。または、タスクをゾンビと見なす前にスケジューラが待機する時間を長くするように、ゾンビタスクのタイムアウトを増やします。
ワーカー コンテナの再起動
24 時間に複数回の再起動
最も一般的な理由は、ワーカーのメモリまたはストレージが不足していることです。ワーカーのリソース使用量を確認し、ワーカーにメモリまたはストレージをさらに割り当てます。リソース不足が理由でない場合は、ワーカーの再起動インシデントのトラブルシューティングを確認し、Logging クエリを使用して、ワーカーの再起動の理由を見つけます。
通知チャンネルを作成する
通知チャンネルを作成するの手順に従って、メール通知チャンネルを作成します。
通知チャンネルの詳細については、通知チャンネルを管理するをご覧ください。
アラート ポリシーを作成する
このチュートリアルの前のセクションで説明したベンチマークに基づいてアラート ポリシーを作成し、指標の値を継続的にモニタリングして、指標が条件に違反した場合に通知を受け取ります。
コンソール
Monitoring ダッシュボードに表示される各指標のアラートを設定するには、対応する項目の隅にあるベルのアイコンをクリックします。
Monitoring ダッシュボードでモニタリングする各指標を見つけ、指標アイテムの隅にあるベルアイコンをクリックします。[アラート ポリシーを作成] ページが開きます。
[データを変換する] セクションで、次の操作を行います。
指標のアラート ポリシー構成の説明に従って、[時系列内] セクションを構成します。
[次へ] をクリックしてから、指標のアラート ポリシー構成の説明に従って、[アラート トリガーを構成] セクションを構成します。
[次へ] をクリックします。
通知を構成します。[通知チャンネル] メニューを展開して、前の手順で作成した通知チャンネルを選択します。
[OK] をクリックします。
[アラート ポリシーの命名] セクションで、[アラート ポリシー名] フィールドに入力します。各指標にわかりやすい名前を付けます。指標のアラート ポリシー構成の説明に従って、「アラート ポリシーの命名」の値を使用します。
[次へ] をクリックします。
アラート ポリシーを確認し、[ポリシーを作成] をクリックします。
環境の健全性(Airflow モニタリング DAG)指標 - アラート ポリシーの構成
- 指標名: Cloud Composer Environment - Healthy
- API: composer.googleapis.com/environment/healthy
フィルタ:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]データの変換 > 時系列内:
- ローリング ウィンドウ: カスタム
- カスタム値: 4
- カスタム単位: 時間
- ローリング ウィンドウ関数: friction true
アラート トリガーの構成:
- 条件タイプ: しきい値
- アラート トリガー: 任意の時系列の違反
- しきい値の位置: しきい値より下
- しきい値: 90
- 条件名: 環境の健全性条件
通知を構成してアラートを確定:
- アラート ポリシーの命名: Airflow Environment Health
データベースの健康指標 - アラート ポリシーの構成
- 指標名: Cloud Composer Environment - Database Healthy
- API: composer.googleapis.com/environment/database_health
フィルタ:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]データの変換 > 時系列内:
- ローリング ウィンドウ: カスタム
- カスタム値: 4
- カスタム単位: 時間
- ローリング ウィンドウ関数: friction true
アラート トリガーの構成:
- 条件タイプ: しきい値
- アラート トリガー: 任意の時系列の違反
- しきい値の位置: しきい値より下
- しきい値: 95
- 条件名: データベースの健全性条件
通知を構成してアラートを確定:
- アラート ポリシーの命名: Airflow Database Health
データベースの CPU 使用率の指標 - アラート ポリシーの構成
- 指標名: Cloud Composer Environment - Database CPU Utilization
- API: composer.googleapis.com/environment/database/cpu/utilization
フィルタ:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]データの変換 > 時系列内:
- ローリング ウィンドウ: カスタム
- カスタム値: 12
- カスタム単位: 時間
- ローリング ウィンドウ関数: mean
アラート トリガーの構成:
- 条件タイプ: しきい値
- アラート トリガー: 任意の時系列の違反
- しきい値の位置: しきい値より上
- しきい値: 80
- 条件名: データベースの CPU 使用量条件
通知を構成してアラートを確定:
- アラート ポリシーの命名: Airflow Database CPU Usage
データベースの CPU 使用率の指標 - アラート ポリシーの構成
- 指標名: Cloud Composer Environment - Database Memory Utilization
- API: composer.googleapis.com/environment/database/memory/utilization
フィルタ:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]データの変換 > 時系列内:
- ローリング ウィンドウ: カスタム
- カスタム値: 12
- カスタム単位: 時間
- ローリング ウィンドウ関数: mean
アラート トリガーの構成:
- 条件タイプ: しきい値
- アラート トリガー: 任意の時系列の違反
- しきい値の位置: しきい値より上
- しきい値: 80
- 条件名: データベースのメモリ使用量条件
通知を構成してアラートを確定:
- アラート ポリシーの命名: Airflow Database Memory Usage
スケジューラのハートビート指標 - アラート ポリシーの構成
- 指標名 Cloud Composer Environment - Scheduler Heartbeats
- API: composer.googleapis.com/environment/scheduler_heartbeat_count
フィルタ:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]データの変換 > 時系列内:
- ローリング ウィンドウ: カスタム
- カスタム値: 4
- カスタム単位: 時間
- ローリング ウィンドウ関数: count
アラート トリガーの構成:
- 条件タイプ: しきい値
- アラート トリガー: 任意の時系列の違反
- しきい値の位置: しきい値より下
しきい値: 216
- この数値は、Metrics Explorer Query Editor で値
_scheduler_heartbeat_count_meanを集計するクエリを実行して取得できます。
- この数値は、Metrics Explorer Query Editor で値
条件名: スケジューラ ハートビート条件
通知を構成してアラートを確定:
- アラートポリシーの命名: Airflow Scheduler Heartbeat
強制終了されたゾンビタスク指標 - アラート ポリシーの構成
- 指標名: Cloud Composer 環境 - 強制終了されたゾンビタスク
- API: composer.googleapis.com/environment/zombie_task_killed_count
フィルタ:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]データの変換 > 時系列内:
- ローリング ウィンドウ: 1 日
- ローリング ウィンドウ関数: sum
アラート トリガーの構成:
- 条件タイプ: しきい値
- アラート トリガー: 任意の時系列の違反
- しきい値の位置: しきい値より上
- しきい値: 1
- 条件名: ゾンビタスクの条件
通知を構成してアラートを確定:
- アラート ポリシーの命名: Airflow Zombie Tasks
ワーカー コンテナの再起動指標 - アラート ポリシーの構成
- 指標名: Cloud Composer 環境 - 強制終了されたゾンビタスク
- API: composer.googleapis.com/environment/zombie_task_killed_count
フィルタ:
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]データの変換 > 時系列内:
- ローリング ウィンドウ: 1 日
- ローリング ウィンドウ関数: sum
アラート トリガーの構成:
- 条件タイプ: しきい値
- アラート トリガー: 任意の時系列の違反
- しきい値の位置: しきい値より上
- しきい値: 1
- 条件名: ゾンビタスクの条件
通知を構成してアラートを確定:
- アラート ポリシーの命名: Airflow Zombie Tasks
Terraform
メール通知チャンネルを作成し、それぞれのベンチマークに基づいて、このチュートリアルの主要な指標のアラート ポリシーをアップロードする Terraform スクリプトを実行します。
- Terraform のサンプル ファイルをローカル コンピュータに保存します。
以下を置き換えます。
PROJECT_ID: プロジェクトのプロジェクト ID。例:example-projectEMAIL_ADDRESS: アラートがトリガーされた場合に通知される必要があるメールアドレス。ENVIRONMENT_NAME: Cloud Composer 環境の名前。 例:example-composer-environmentCLUSTER_NAME: 環境クラスタ名。Google Cloud コンソールの [環境構成] > [リソース] > [GKE クラスタ] で確認できます。
resource "google_monitoring_notification_channel" "basic" {
project = "PROJECT_ID"
display_name = "Test Notification Channel"
type = "email"
labels = {
email_address = "EMAIL_ADDRESS"
}
# force_delete = false
}
resource "google_monitoring_alert_policy" "environment_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Environment Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Environment health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/healthy\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.9
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "database_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Database Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database_health\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.95
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_cpu_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database CPU Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database CPU usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/cpu/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_memory_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database Memory Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database memory usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/memory/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_scheduler_heartbeat" {
project = "PROJECT_ID"
display_name = "Airflow Scheduler Heartbeat"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Scheduler heartbeat condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/scheduler_heartbeat_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 216 // Threshold is 90% of the average for composer.googleapis.com/environment/scheduler_heartbeat_count metric in an idle environment
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_COUNT"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_zombie_task" {
project = "PROJECT_ID"
display_name = "Airflow Zombie Tasks"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Zombie tasks condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/zombie_task_killed_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_SUM"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_worker_restarts" {
project = "PROJECT_ID"
display_name = "Airflow Worker Restarts"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Worker container restarts condition"
condition_threshold {
filter = "resource.type = \"k8s_container\" AND (resource.labels.cluster_name = \"CLUSTER_NAME\" AND resource.labels.container_name = monitoring.regex.full_match(\"airflow-worker|base\") AND resource.labels.pod_name = monitoring.regex.full_match(\"airflow-worker-.*|airflow-k8s-worker-.*\")) AND metric.type = \"kubernetes.io/container/restart_count\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_RATE"
}
}
}
}
アラート ポリシーをテストする
このセクションでは、作成したアラート ポリシーをテストして結果を解釈する方法について説明します。
サンプル DAG をアップロードする
このチュートリアルで提供されているサンプル DAG memory_consumption_dag.py は、ワーカーのメモリ使用率が上昇している状態を模倣します。DAG には 4 つのタスクが含まれ、各タスクはサンプル文字列にデータを書き込み、380 MB のメモリを使用します。サンプル DAG は 2 分ごとに実行されるようにスケジュール設定されており、Composer 環境にアップロードされると自動的に実行を開始します。
先ほどの手順で作成した環境に、次のサンプル DAG をアップロードします。
from datetime import datetime
import sys
import time
from airflow import DAG
from airflow.operators.python import PythonOperator
def ram_function():
data = ""
start = time.time()
for i in range(38):
data += "a" * 10 * 1000**2
time.sleep(0.2)
print(f"{i}, {round(time.time() - start, 4)}, {sys.getsizeof(data) / (1000 ** 3)}")
print(f"Size={sys.getsizeof(data) / (1000 ** 3)}GB")
time.sleep(30 - (time.time() - start))
print(f"Complete in {round(time.time() - start, 2)} seconds!")
with DAG(
dag_id="memory_consumption_dag",
start_date=datetime(2023, 1, 1, 1, 1, 1),
schedule="1/2 * * * *",
catchup=False,
) as dag:
for i in range(4):
PythonOperator(
task_id=f"task_{i+1}",
python_callable=ram_function,
retries=0,
dag=dag,
)
Monitoring でアラートと指標を解釈する
サンプル DAG の実行が開始してから 10 分ほど待ってから、テスト結果を評価します。
メールのメールボックスをチェックして、
[ALERT]で始まる件名の通知をGoogle Cloud Alerting から受信していることを確認します。このメッセージの内容には、アラート ポリシーのインシデントの詳細が含まれています。メール通知の [インシデントを表示] ボタンをクリックします。Metrics Explorer にリダイレクトされます。アラート インシデントの詳細を確認します。
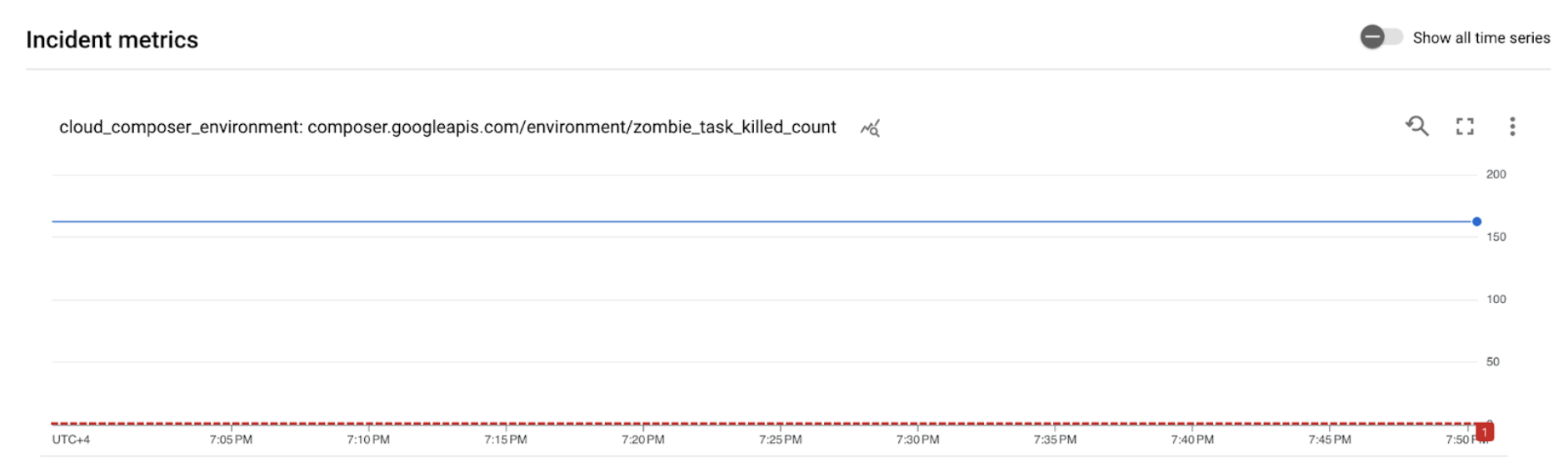
図 2.アラート インシデントの詳細(クリックして拡大) インシデント指標グラフは、作成した指標がしきい値 1 を超えていることを示しています。これは、Airflow が複数のゾンビタスクを検出して強制終了したことを表します。
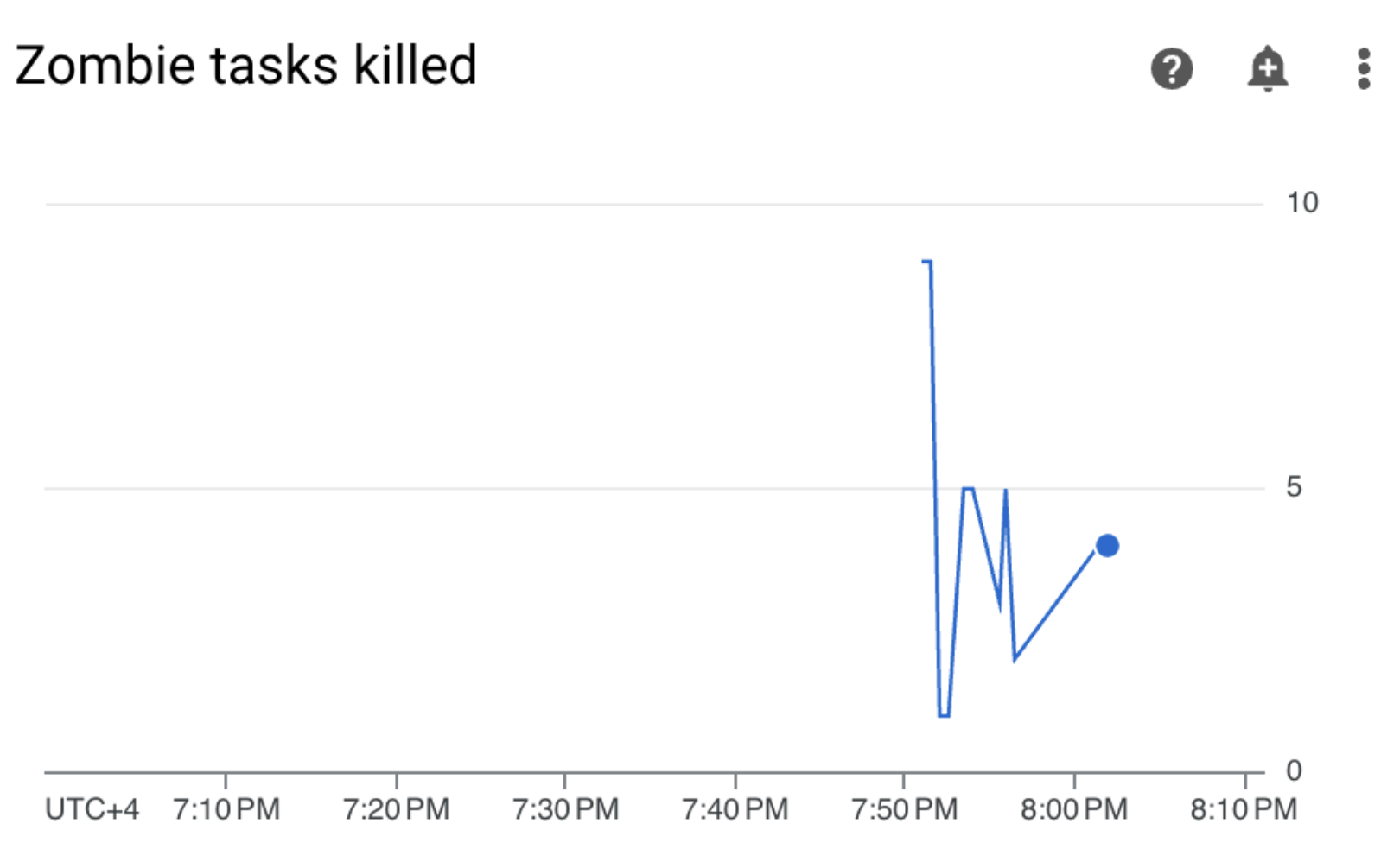
Cloud Composer 環境で、[Monitoring] タブに移動し、[DAG の統計情報] セクションを開き、[強制終了したゾンビタスク] のグラフを見つけます。
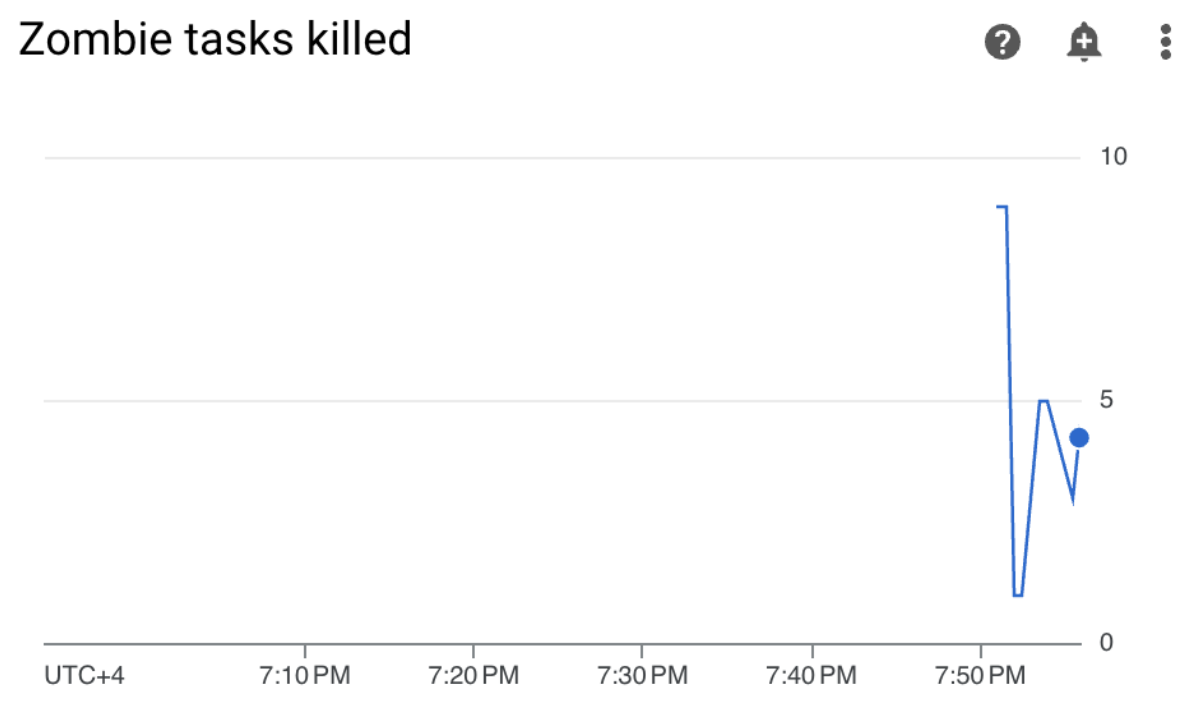
図 3.ゾンビタスクのグラフ(クリックして拡大) このグラフは、サンプル DAG の実行から最初の 10 分以内に約 20 個のゾンビタスクを Airflow が強制終了したことを示しています。
ベンチマークと是正措置によると、ゾンビタスクの最も一般的な理由は、ワーカーのメモリや CPU が不足していることです。ワーカーのリソース使用率を分析して、ゾンビタスクの根本原因を特定します。
Monitoring ダッシュボードで [ワーカー] セクションを開き、ワーカーの CPU とメモリの使用率に関する指標を確認します。
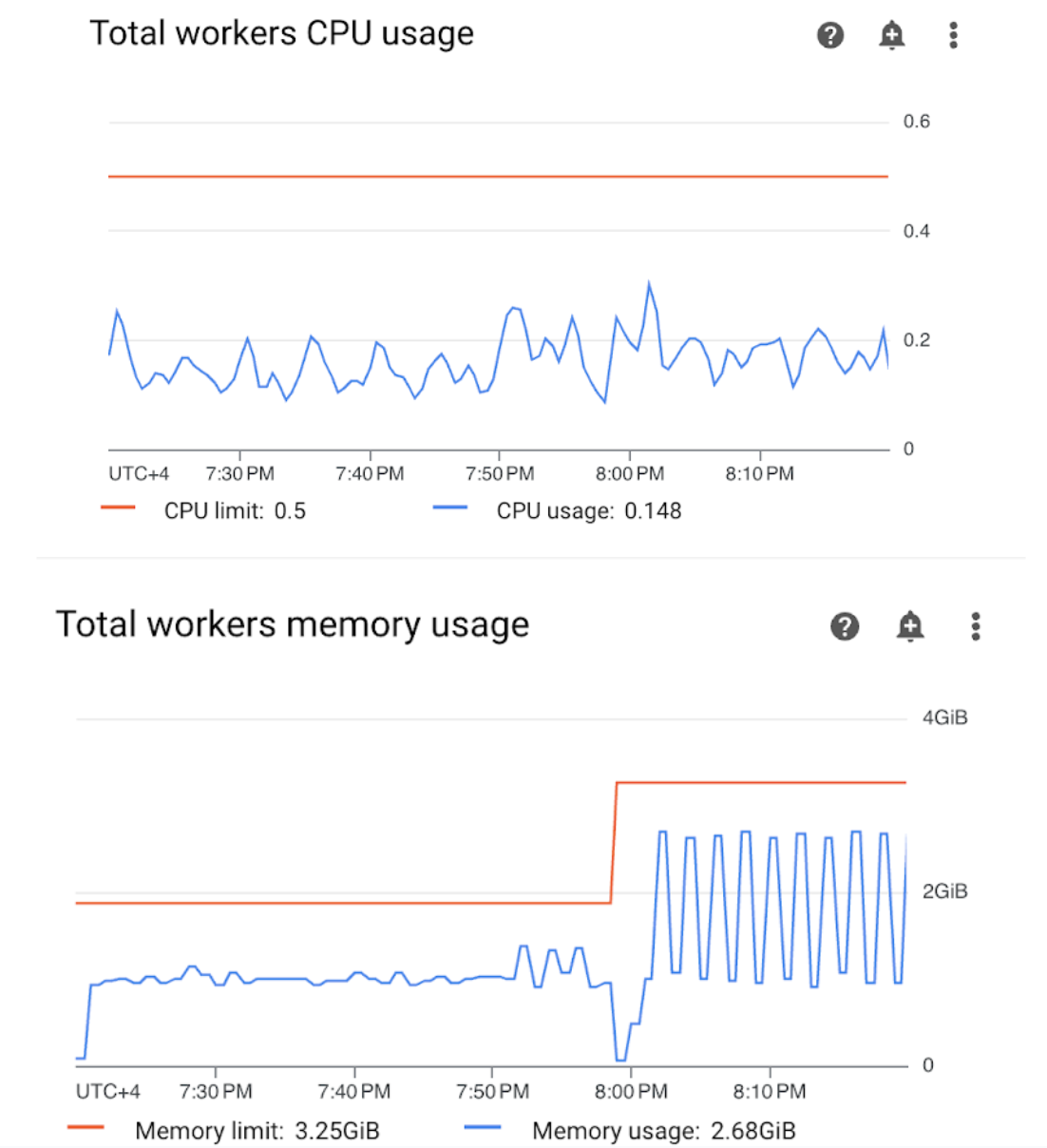
図 4. ワーカーの CPU とメモリ使用量の指標(クリックして拡大) ワーカーの合計 CPU 使用率のグラフは、ワーカーの CPU 使用率が使用可能な合計上限の 50% を常に下回っていることを示しており、使用可能な CPU は十分な容量です。ワーカーの合計メモリ使用量のグラフは、サンプル DAG を実行すると、割り当て可能なメモリ制限に達したことを示しています。これは、グラフに表示される合計メモリ上限の約 75% に相当します(GKE は最初の 4 GiB メモリの 25% と、Pod のエビクションを処理するため、各ノードで追加の 100 MiB のメモリを予約しています)。
サンプル DAG を正常に実行するためのメモリリソースがワーカーに不足していると結論付けることができます。
環境を最適化し、パフォーマンスを評価する
ワーカーのリソース使用率の分析に基づいて、DAG 内のすべてのタスクが成功するように、ワーカーに追加のメモリを割り当てる必要があります。
Composer 環境で [DAG] タブを開き、サンプル DAG の名前(
memory_consumption_dag)をクリックして、[DAG を一時停止] をクリックします。追加のワーカーメモリを割り当てます。
[Environment configuration] タブで、[リソース] > [ワークロード] 構成を見つけて、[編集] をクリックします。
[ワーカー] 項目で、[メモリ] 上限を引き上げます。このチュートリアルでは、3.25 GB を使用します。
変更を保存し、ワーカーが再起動するまで数分待ちます。
[DAG] タブを開き、サンプル DAG(
memory_consumption_dag)の名前をクリックし、[DAG の一時停止を解除] をクリックします。
[Monitoring] に移動し、ワーカーのリソース上限を更新した後に新しいゾンビタスクが表示されていないことを確認します。
概要
このチュートリアルでは、環境レベルの健全性とパフォーマンスの主要な指標、各指標にアラート ポリシーを設定する方法、各指標を是正措置として解釈する方法を学習しました。次に、サンプル DAG を実行し、アラートと Monitoring のグラフを使用して環境の健全性の根本原因を特定し、ワーカーにより多くのメモリを割り当てて、環境を最適化しました。ただし、最初の段階ではワーカーのリソース消費量を削減するために DAG を最適化することをおすすめします。これは、特定のしきい値を超えてリソースを増やすことができないためです。
クリーンアップ
このチュートリアルで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、リソースを含むプロジェクトを削除するか、プロジェクトを維持して個々のリソースを削除します。
プロジェクトの削除
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
リソースを個別に削除する
複数のチュートリアルとクイックスタートを実施する予定がある場合は、プロジェクトを再利用すると、プロジェクトの割り当て上限を超えないようにできます。
コンソール
- Cloud Composer 環境を削除します。この手順で環境のバケットも削除します。
- Cloud Monitoring で作成したアラート ポリシーを削除します。
Terraform
- Terraform スクリプトに、プロジェクトで依然として必要とされるリソースのエントリが含まれていないことを確認します。たとえば、一部の API を有効にしたまま、IAM 権限をまだ割り当てておくことができます(Terraform スクリプトにこのような定義を追加した場合)。
terraform destroyを実行します。- 環境のバケットを手動で削除します。Cloud Composer では自動的に削除されません。これは Google Cloud コンソールまたは Google Cloud CLI から行うことができます。