Cloud Code pour Cloud Shell est conçu pour faciliter la configuration de Kubernetes et Cloud Build en analysant le schéma de manière à vérifier la structure et la validité des valeurs, tout en fournissant des erreurs descriptives. Cloud Code est fourni avec des solutions prêtes à l'emploi pour les fonctions courantes de schéma, de saisie intelligente et de documentation par survol de la souris.
Fichiers de configuration YAML compatibles
Cloud Code est également compatible avec les CRD (définitions de ressources personnalisées) Kubernetes courants, tels que Kubeflow, qui sont prêts à l'emploi.
Utiliser un schéma personnalisé
Avec Cloud Code, vous pouvez fournir votre propre schéma de CRD en utilisant le paramètre cloudcode.yaml.crdSchemaLocations de votre fichier settings.json.
Vous pouvez le faire pointer vers un fichier local ou une URL. Les URL pointant vers github.com sont automatiquement converties en raw.githubusercontent.com.
Extraire un schéma d'un cluster
Lorsque vous passez à un cluster exécutant Kubernetes 1.16 et versions ultérieures dans la vue Kubernetes, Cloud Code extrait automatiquement le schéma de tous les CRD installés.
Configurer avec des extraits de code
Les extraits prêts à l'emploi pour les schémas YAML courants (la combinaison Command/Ctrl+Space permettant d'afficher les options) facilitent la création de nouveaux fichiers YAML ou l'ajout de sections à des fichiers existants. Ils aident à travailler sans erreur, tout en respectant les bonnes pratiques. Cloud Code facilite le travail avec des champs répétitifs en remplissant les instances restantes après avoir rempli le premier champ.
Cloud Code propose les extraits de code suivants :
Anthos Config Management - ClusterAnthos Config Management - Cluster SelectorAnthos Config Management - Config ManagementAnthos Config Management - Namespace SelectorCloud Build - Cloud Run deploymentCloud Build - Docker container buildCloud Build - GKE deploymentCloud Build - GKE Skaffold deploymentCloud Build - Go buildCloud Build - Terraform plan + applyConfig Connector - BigQueryDatasetConfig Connector - BigQueryTableConfig Connector - BigtableClusterConfig Connector - BigtableInstanceConfig Connector - PubSubSubscriptionConfig Connector - PubSubTopicConfig Connector - RedisInstanceConfig Connector - SpannerInstanceKubernetes - ConfigMapKubernetes - DeploymentKubernetes - IngressKubernetes - PodKubernetes - SecretKubernetes - ServiceMigrate to Containers - ExportMigrate to Containers - PersistentVolumeClaimMigrate to Containers - StatefulSetSkaffold - BazelSkaffold - Getting-startedSkaffold - Helm deploymentSkaffold - Kaniko
Saisie avec contexte
Sur la base du schéma actuel, Cloud Code fournit des compléments contextuels et des documents pertinents pour vous aider à choisir la bonne option.
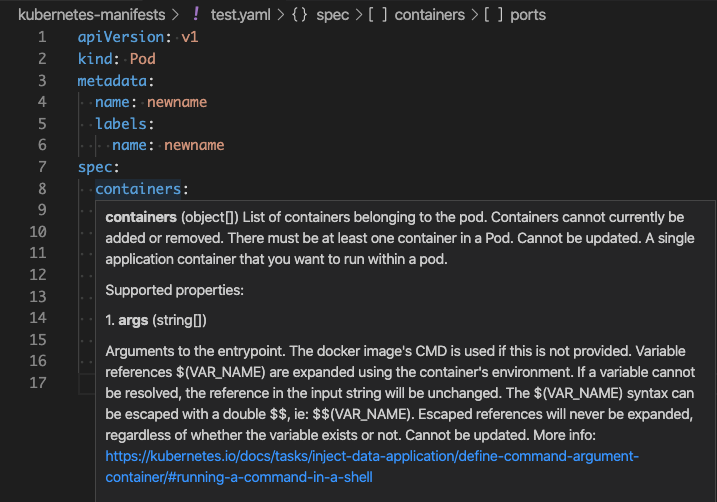
Valider le schéma YAML
Cloud Code offre une assistance pour la validation du schéma en signalant les valeurs et les tags non valides dans vos fichiers YAML, et en suggérant des corrections lorsque cela est possible.
Faire apparaître la documentation par survol de la souris
Cloud Code fournit la documentation pertinente lorsque vous maintenez le pointeur sur une valeur du schéma.

Accéder aux définitions de ressources
Pour afficher les définitions d'une ressource, effectuez un clic droit dessus, puis sélectionnez Atteindre la définition ou Aperçu de la définition.
Appliquer un fichier YAML
Pour appliquer une modification de configuration à l'aide du fichier actuel, ouvrez la palette de commandes (appuyez sur Ctrl/Cmd+Shift+P ou cliquez sur Affichage > Palette de commandes), puis exécutez Cloud Code: Apply Current JSON/YAML File to K8s Deployed Resource (Cloud Code : appliquer le fichier JSON/YAML actuel à la ressource déployée K8s).
Cette commande affiche une vue de comparaison qui vous permet d'examiner les modifications. Cliquez sur Appliquer lorsque vous êtes invité à appliquer la modification. Cela a pour effet d'exécuter kubectl apply -f.
Afficher les différences entre les fichiers YAML
Pour afficher les différences entre un fichier YAML dans le contrôle de source et un fichier YAML déployé, ouvrez la palette de commandes (appuyez sur Ctrl/Cmd+Shift+P ou cliquez sur Affichage > Palette de commandes), puis exécutez Cloud Code: Diff Current JSON/YAML File with K8s Deployed Resource (Cloud Code : Différencier le fichier JSON/YAML actuel avec la ressource déployée K8s).
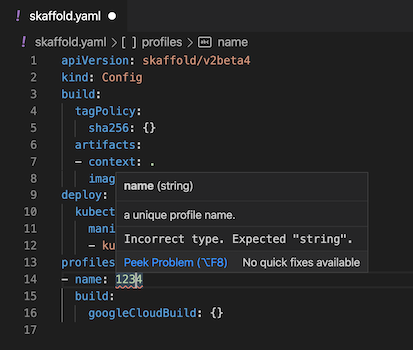
Effectuer un "dry run" (test à blanc) d'un fichier YAML
Cloud Code effectue automatiquement des "dry runs" (tests à blanc) lorsque vous saisissez des informations dans votre fichier YAML et souligne les erreurs à l'aide d'une ligne jaune en zigzag.
Des lignes jaunes en zigzag apparaissent lorsque le serveur considère qu'une partie de votre code est une erreur en fonction du résultat d'un essai sans connexion. Cela peut inclure des cas de non-respect des règles, des noms en double ou des validations que Cloud Code n'effectue pas côté client (comme les numéros de port maximum).
Pour afficher la description de l'erreur dans votre fichier YAML, maintenez le pointeur sur le code souligné en jaune.
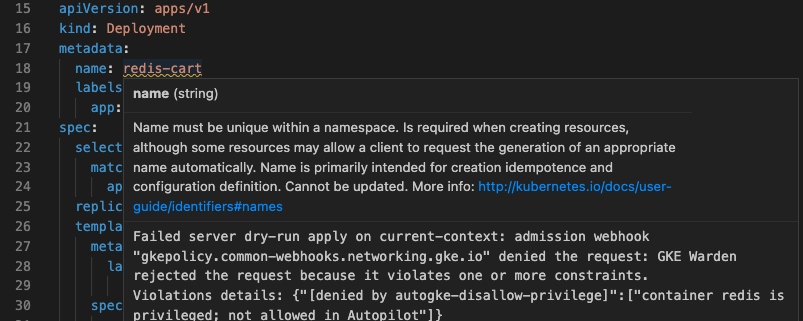
Des lignes rouges en zigzag apparaissent pour les erreurs détectées avant que Cloud Code ne vérifie auprès du serveur Kubernetes. Par exemple, si vous saisissez un nombre à la place d'une chaîne, une ligne en zigzag rouge s'affiche.
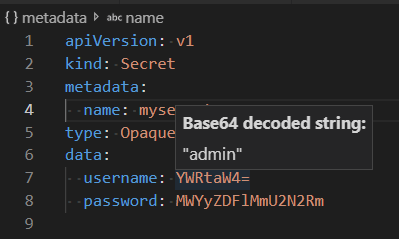
Utiliser des secrets
L'utilisation de mappages de configuration et de secrets est un élément clé de l'utilisation de Kubernetes. Pour afficher le contexte d'un secret en base64 avec Cloud Code, maintenez le pointeur sur le secret pour le décoder.
Étape suivante
- Créez un fichier
skaffold.yamlde configuration d'exécution Kubernetes Cloud Code. - Créez manuellement une configuration Skaffold pour votre application.
- Consultez la documentation de référence sur
Skaffold.yaml.