The top 5 launches of 2021 (so far)
Stephanie Wong
Head of Developer Skills & Community, Google Cloud
And just like that, seven months are under our belts. I’m guessing I’m not the only one who feels like 2021 is flying by.
Even so, much has already happened at Google Cloud. We launched more products and features than I can count, hosted our first virtual Google I/O, and organized Cloud OnAir events each month, including our Applied ML Summit, Cloud Data Summit, and Security Summit. It’s not exactly easy to keep up with the milestones floating around press releases, blogs, and social media. So I’ll spare you the drudgery of a web hunt with a list of my top five product launches of 2021 (so far). Plus, I’ll throw in snippets of where I think these launches fit within the rest of our offerings and the industry at large.
1. Vertex AI
At Google I/O in May, we announced the general availability of Vertex AI, a managed machine learning platform that enables companies to accelerate the deployment and maintenance of artificial intelligence models.
You might remember that back in 2018 we released AI Platform, which included a training, prediction, and data labeling service, along with managed notebooks and more. It helped you handle all steps of the ML workflow, from sourcing data to managing models and versions. Alongside we had popular AutoML offerings, like AutoML’s Vision, Video Intelligence, and Natural Language APIs.
The feedback we’ve gotten is that data scientists have grappled with the challenge of manually piecing together ML point solutions. This has increased lag time in model development and experimentation, and greatly reduced the number of models making it into production.
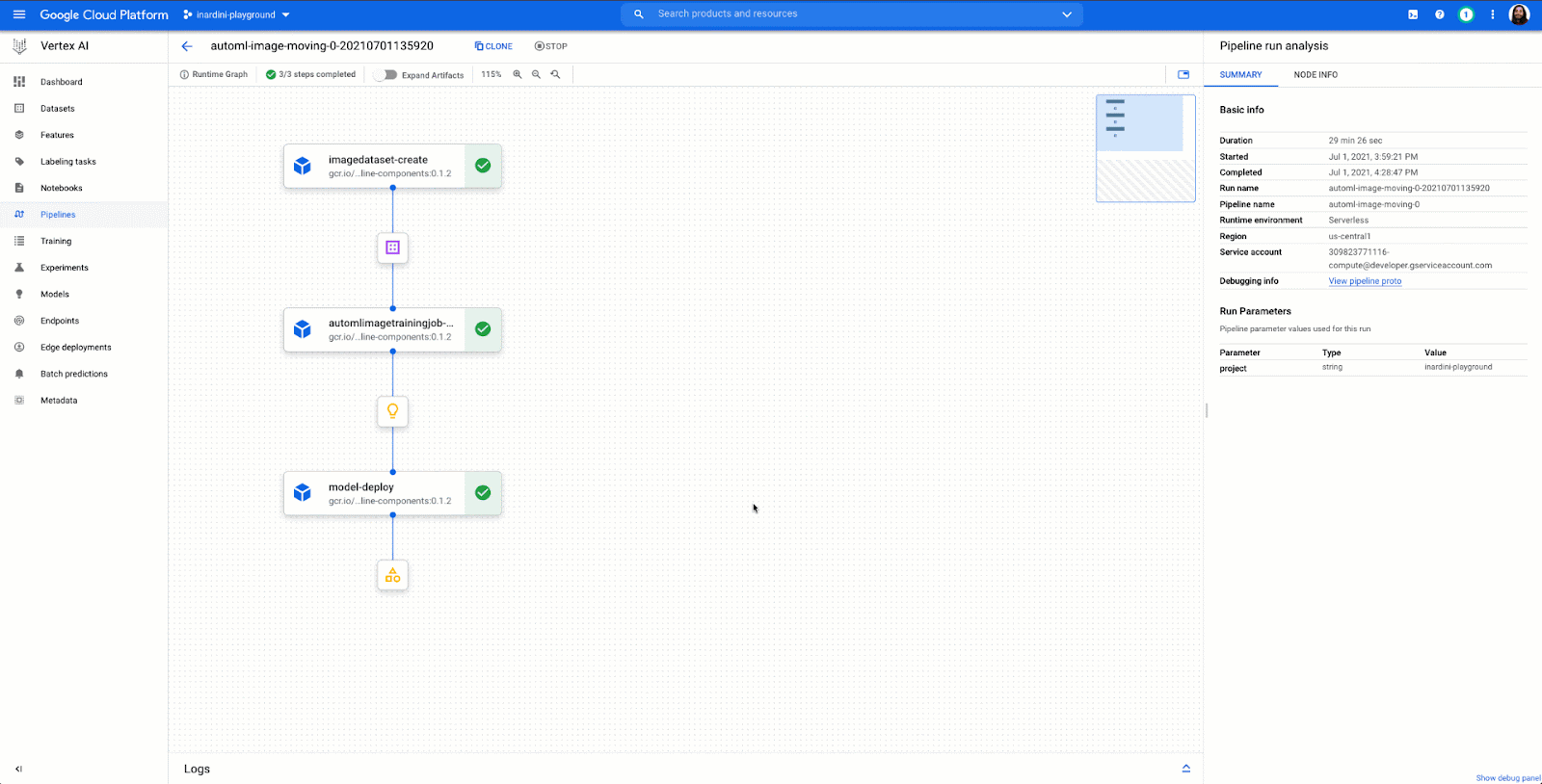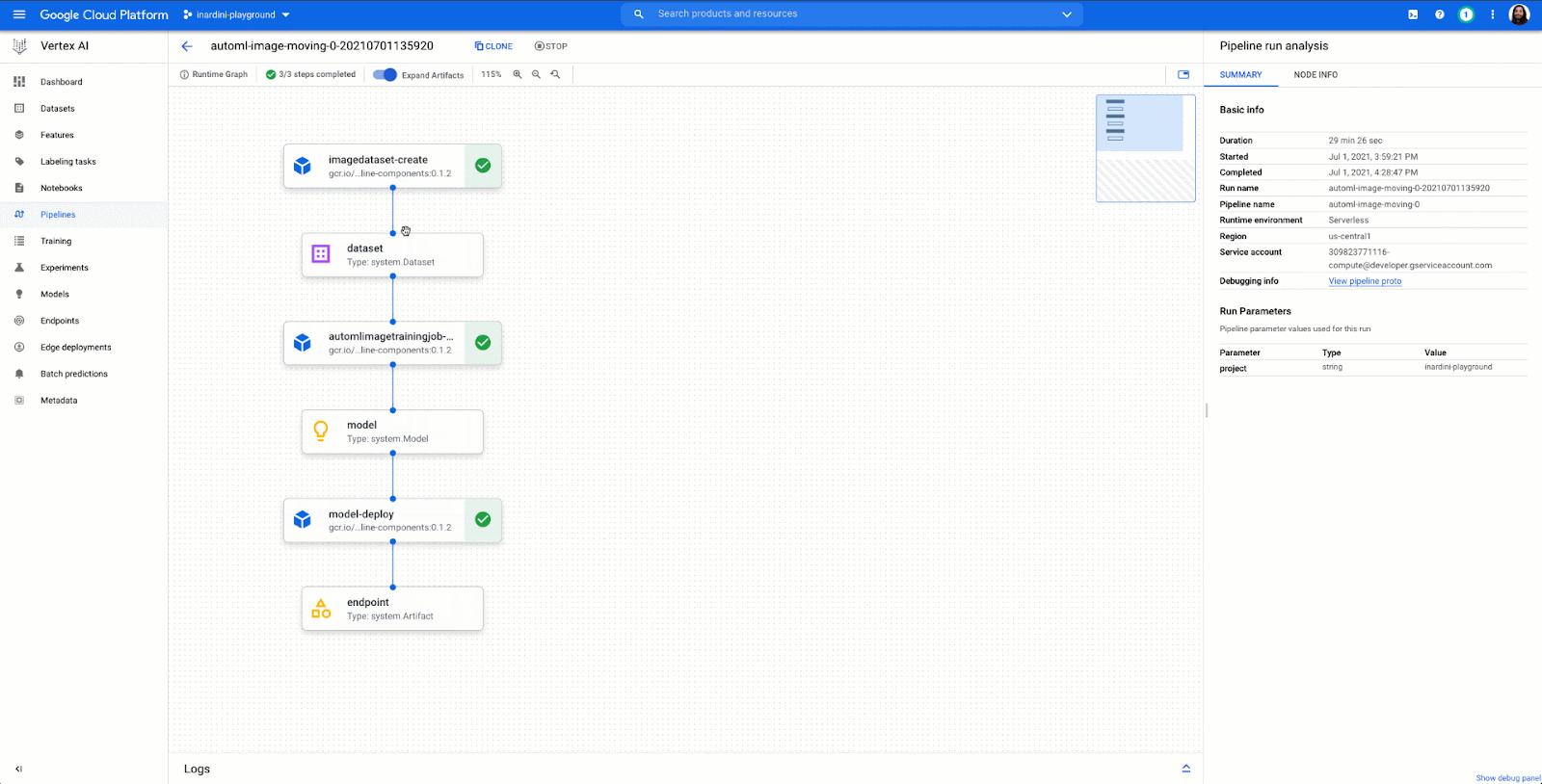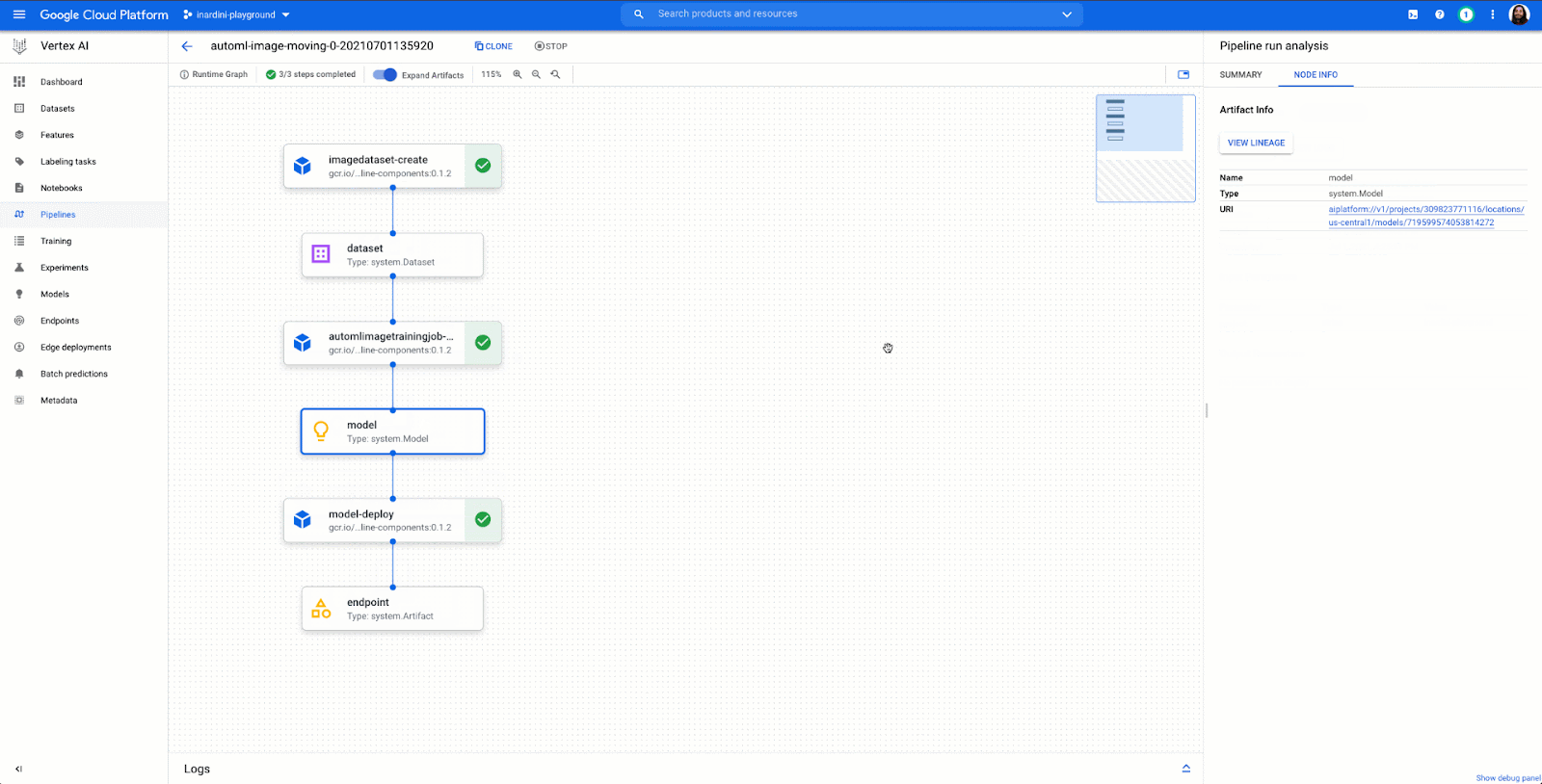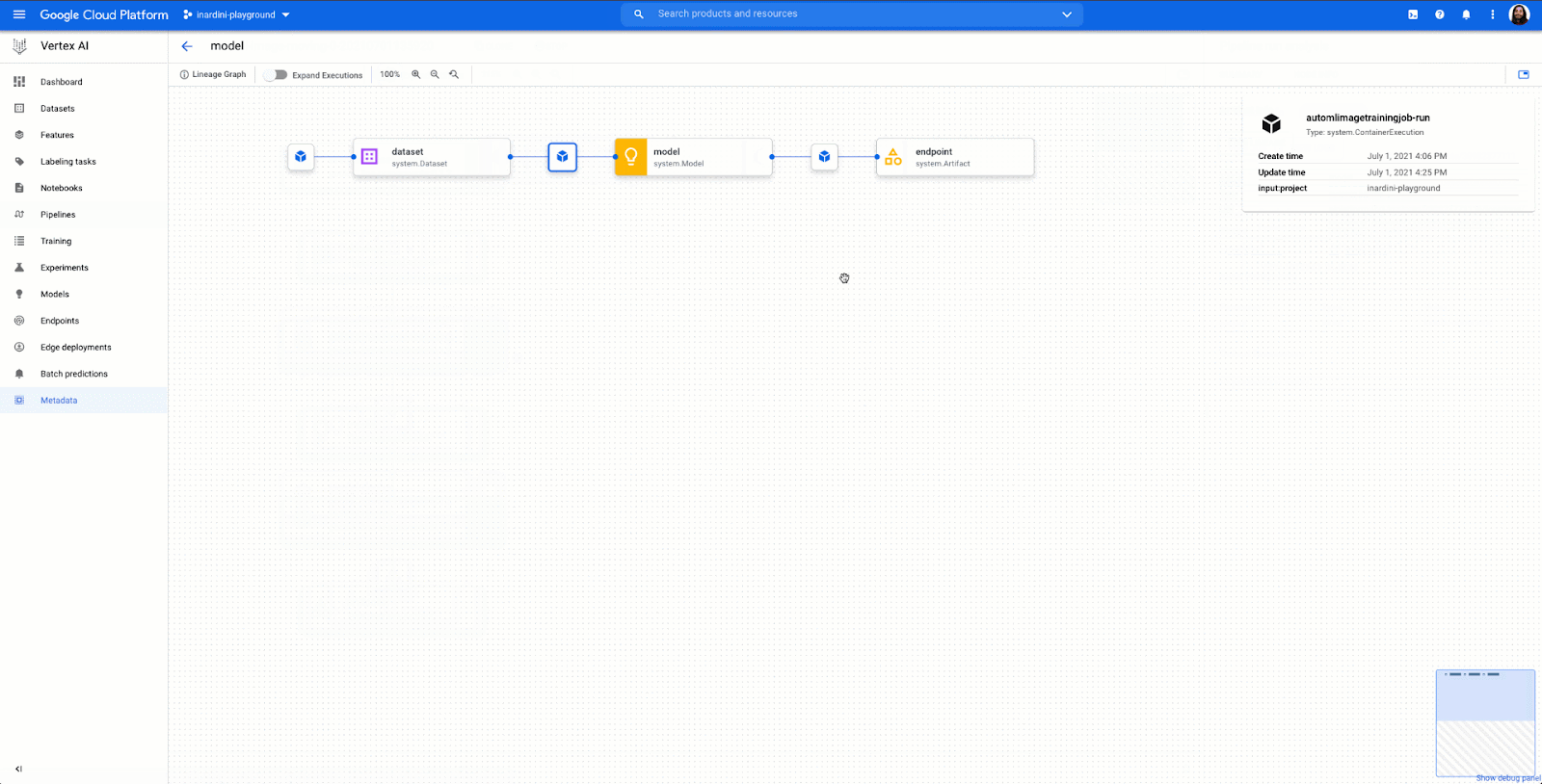
Vertex AI brings together Google Cloud ML services under one unified UI and API to simplify the process of building, training, and deploying machine learning models at scale. AutoML and AI Platform share the same underlying infrastructure, data modeling, UX, and API layers. In this single environment, you can train and compare models using AutoML or custom code, and all your models are stored in one central model repository. These models can be deployed to the same endpoints on Vertex AI.
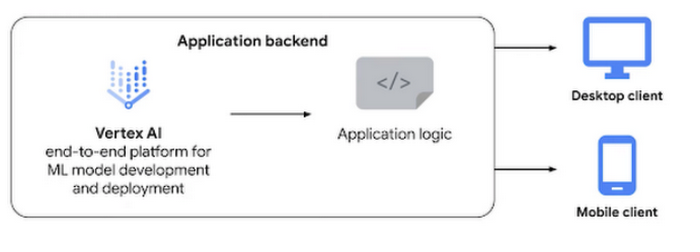
You can think of it like a choose-your-own adventure book where you can decide whether to train custom models, use AutoML, or use BigQuery ML, yet still end up with a productionized model by the last chapter. Meanwhile, your hands never leave the same bound pages of the book, so you have a sense of familiarity and control, as well as the freedom to bounce around the pages.
Some key features:
- Deep Learning VM images
- Vertex Notebooks
- Vertex Data Labeling
- Vertex Explainable AI
- Vertex Pipelines
Where does this fit into our product strategy?
We’re funneling major tools to build, deploy, and manage ML applications into one toolbox, while integrating other analytics tools like BigQuery ML. Not only are we baking our long time investments of AI into Vertex, but we’re using it as a landing spot for ways we can simplify ML for novices and experts. Meanwhile, we're continuing to build upon our industry-specific AI solutions like Contact Center AI to enhance customer service experiences, Document AI to make unstructured data available to business users, and our Healthcare API (which has prebuilt connectors to Vertex AI) to unlock ML in clinical workflows.
Where does this fit into the broader industry?
Now that we can safely say the field of ML is maturing, data science teams are looking beyond just building models to also maintaining them. Teams need to experiment with, evaluate, understand, and reproduce models. Collaboration between practitioners is a necessity, and responsible AI needs to be top of mind.
As such, DevOps practices, like CI/CD for software development, have made their way into ML. MLOps emerged to similarly codify and automate the workflow to build and manage ML models. Just as tools like GitHub, Spinnaker, and Datadog emerged, many new tools are taking the stage to help with different parts of the ML lifecycle (tracking issues, managing version history, and monitoring and alerting when something goes wrong in production).
But ML teams want a unified experience that includes pipelines, a feature store, labeling services, model stores, evaluation, and more. Vertex AI is our big attempt at giving teams just that. I see it as a way to promote the use of best practices, and help new practitioners learn. Even if you’re starting with AutoML, your projects can remain on the same infrastructure as you transition to building custom models on your own.
Where can you get started?
Start here:
- AI Simplified video series
- New to ML: Learning path on Vertex AI
- Vertex AI: How to create and manage data sets
- GCP Podcast episode
- Applied ML Summit
Get hands-on:
- Vertex AI tutorials
- Codelab: Vertex AI: Building a fraud detection model with AutoML
- Codelab: Building a financial ML model with the What-If Tool and Vertex AI
- Serve a TensorFlow Hub model in Google Cloud with Vertex AI
- Distributed training and hyperparameter tuning with TensorFlow on Vertex AI
- Monitor models for training-serving skew with Vertex AI
2. GKE Autopilot
One of our most revolutionary and exciting announcements of 2021 was GKE Autopilot, a new mode of operation for creating and managing Kubernetes clusters in Google Kubernetes Engine (GKE). In this mode, GKE configures and manages the underlying infrastructure, including nodes and node pools, enabling you to focus only on the target workloads and pay-per-pod resource requests (CPU, memory, and ephemeral storage). In addition to the GKE SLA on hosts and the control plane, Autopilot also includes an SLA on pods.
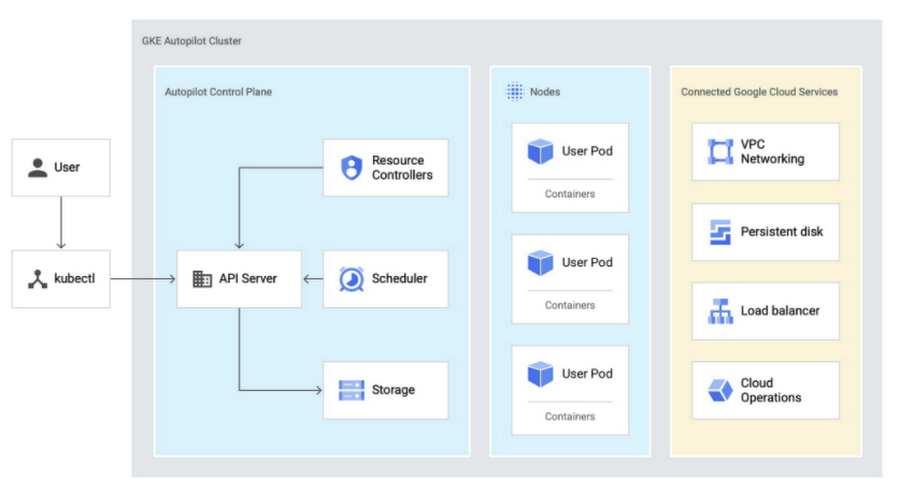
We haven’t been shy about the fact that Kubernetes can take a fair bit of manual assembly and tinkering to optimize it for your needs. GKE was launched in 2015 as a container orchestration platform. You can create or resize Docker container clusters; create container pods, replication controllers, jobs, services or load balancers; resize application controllers; update and upgrade container clusters; and debug container clusters.
But wait, you might be thinking, “Wasn’t GKE already fully managed?”
GKE was indeed already a very hands-off Kubernetes platform because it managed cluster control planes, storage, and networking, while still giving you a high level of control over most aspects of cluster configurations. This is great for companies with operator teams who want to make their own decisions on node configuration, cluster size, cluster autoscaling, and maintenance windows. But for many, especially dev-focused teams who want to onboard quickly onto GKE, that level of control and sheer number of choices can be overwhelming or simply unnecessary for their requirements.
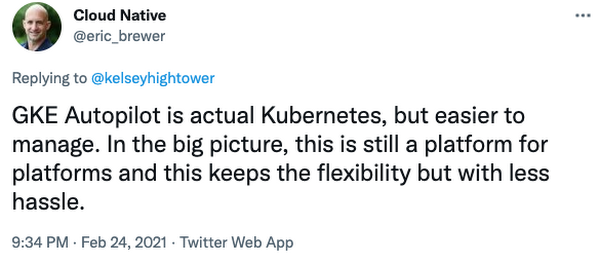
GKE Autopilot was developed to give teams a straightforward way to build a more secure and consistent development platform. You can embrace Kubernetes and simplify operations because GKE Autopilot takes care of cluster infrastructure, control planes, and nodes. I think our VP of Infrastructure, Eric Brewer, said it best:
Some key features:
- GKE Autopilot manages node and node pools.
- Autopilot clusters are preconfigured with an optimized cluster configuration.
- Autopilot comes with an SLA that covers both the control plane and your pods.
Where does it fit into our product strategy?
A question I frequently hear is, “Is this a serverless version of GKE?” A better way to think of Autopilot is that it’s “nodeless”. GKE is the industry’s first fully managed Kubernetes service that implements the full Kubernetes API. GKE Autopilot clusters offer the benefits of a serverless offering with full access to the Kubernetes API. Those who use Kubernetes are using it as a layer on top of IaaS to build their own application platforms. That doesn’t mean, however, it’s not meant for developers. On the contrary, it’s meant for developers who want an easier onboarding to Kubernetes.
Where does it fit into the broader industry?
Another question I often get is, “How does this differ from AWS Fargate?” GKE Autopilot is similar to Fargate for EKS with one major difference: Autopilot supports almost the entire Kubernetes API, including DaemonSets, jobs, CRDs, and admission controllers. One of the standout differences is that you can attach block storage to Autopilot (i.e. HDDs). Autopilot is still Kubernetes and designed that way from the ground up. Our goal from the outset was that Autopilot is GKE, and not a forked or separate product. This means that many of the improvements we make to autoscaling in GKE Autopilot will be shared back to GKE Standard and vice versa. In Autopilot, we’ve combined GKE automation and scaling and lots of great community enhancements.
For developers running on GKE, nothing really changes. For developers interested in starting on Kubernetes, I have yet to see an offering like GKE Autopilot. With Autopilot, you still get the benefits of Kubernetes, but without all of the routine management and maintenance. That’s a trend I’ve been seeing as the Kubernetes ecosystem has evolved. Few companies, after all, see the ability to effectively manage Kubernetes as their real competitive differentiator.
Where can you get started?
Start here:
- Cloud OnAir event
- GKE Standard vs Autopilot
- GCP Podcast episode
- Ahmet Alp Balkan's blog post on stress testing Autopilot
Get hands-on:
3. Tau VMs
Tau VMs were announced just this June. Tau VMs are a new Compute Engine family, optimized for cost-effective performance of scale-out workloads.
T2D, the first instance type in the Tau VM family, is based on 3rd Gen AMD EPYCTM processors and leapfrogs the available VMs for scale-out workloads from any leading public cloud provider , both in terms of performance and workload total cost of ownership.
Our Compute Engine offerings (like our general purpose, compute optimized, memory optimized, and accelerator optimized VMs) already cover a broad range of workload requirements from dev/test to enterprise apps, HPC, and large in-memory databases. There is, however, still a need for compute that supports scale-out enterprise workloads, including media transcoding, Java-based applications, containerized workloads, and web servers. Developers want focused VM features without breaking the bank or sacrificing their productivity. The purpose of our Tau VM family is to provide an intermediate path to the cloud that gives you those features.
Some key features:
- T2D VMs will come in predefined VM shapes, with up to 60 vCPUs per VM, and 4 GB of memory per vCPU, and offer up to 32 Gbps networking.
- The AMD EPYC processor-based VMs also preserve x86 compatibility.
- AMD EPYC processors are built using the Zen 3 architecture, which reduces communication penalties during scale out.
- You can add T2D nodes to your GKE clusters.
Where does it fit into our product strategy?
We launched Tau VMs to complement our general purpose VMs and provide what enterprise data centers have always aimed for: the best performance for enterprise workloads at the best price. With T2D, we saw 56% better raw performance over key competitors.
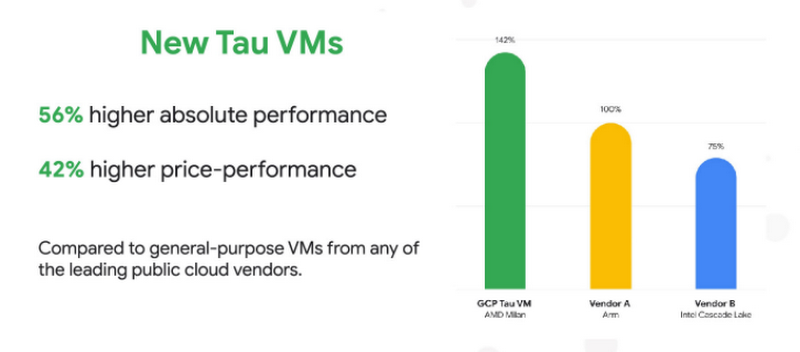
We derived findings from the SPECrate2017_int_base benchmark, which measures the integer performance of a CPU. We ran production VMs from other cloud providers and our preproduction Tau T2D instances using VMs with 32 vCPUs and 128GB RAM.
Where does it fit into the broader industry?
Looking at Tau in the bigger Google Cloud context, I think T2D delivers a VM instance type that teams want. For IT leaders, three things matter: performance, reliability, and cost. The majority of enterprise environments can live comfortably within the general purpose compute space, and don’t rise to the level of compute/memory/accelerator-optimized needs (nor their associated costs). At the same time, they want to reliably scale out nodes to support standard workloads while working within a strict budget. For those who can work with Tau predefined VM shapes, Tau VMs can step up to the plate given their competitive pricing and performance benefits; in other words, get your cake and eat it too.
Where can you get started?
4. Dataplex
Dataplex was announced in preview during our 2021 Data Cloud Summit this past May. Dataplex has been dubbed the “intelligent data fabric,” meaning you get unified data management for your data warehouses, data lakes, data marts, and databases. You can centrally manage, monitor, and govern your data across silos and make this data securely accessible to a variety of analytics and data science tools.
We’re all tired of hearing the words “data silos” when analytics comes up in a conversation. Yet, companies are still struggling to move data from various sources and extract metadata. Cleansing and preparing data is error-prone, while setting up security policies is laborious. Ensuring the interoperability of data warehouses, open source analytics engines, and SaaS platforms requires a deep understanding.
You usually have to decide between moving and duplicating data across silos or leaving your data distributed and moving slower. Dataplex was developed as one experience to curate, integrate, and analyze data without duplicating data, moving it around, or building homegrown systems.
Some key features:
- Dataplex’s interoperable storage layer enables logical constructs such as lakes, data zones, and assets.
- Dataplex uses Google AI to automatically harvest metadata for both structured and unstructured data.
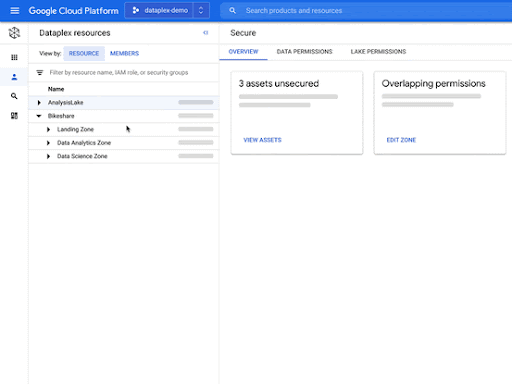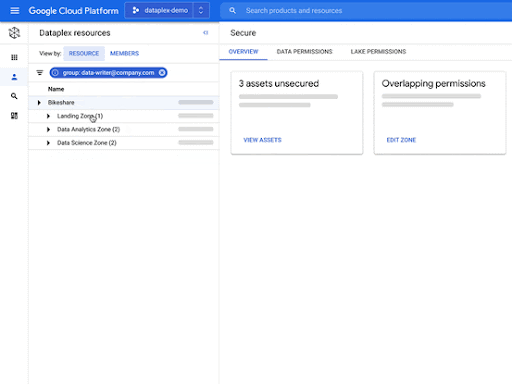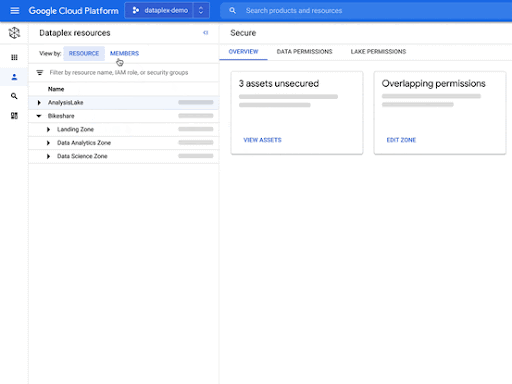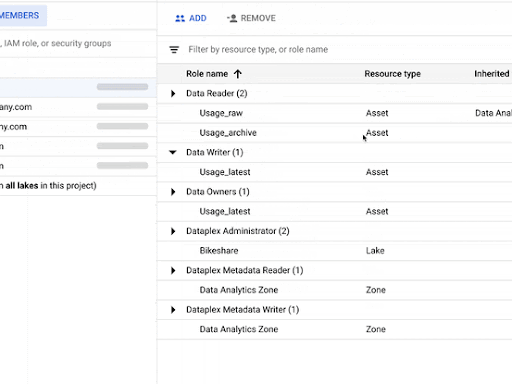
- You can define and enforce consistent policies across your data and locations.
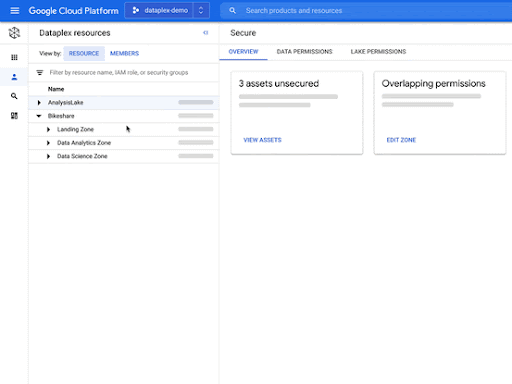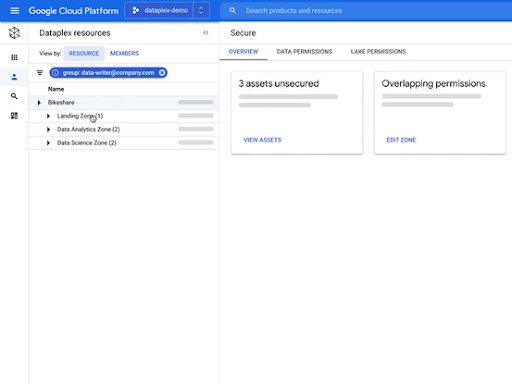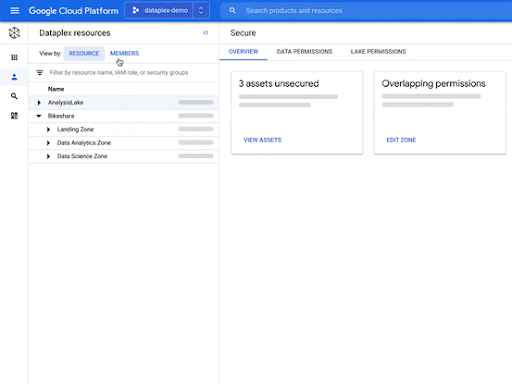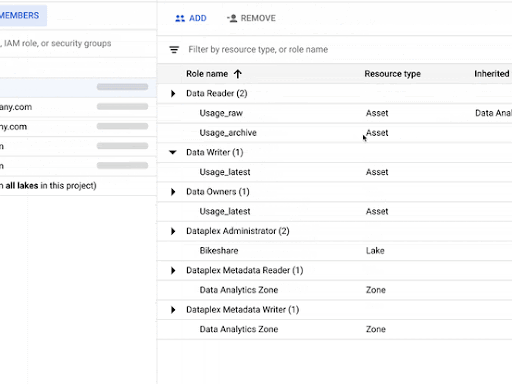
Where does it fit into our product strategy?
Dataplex is just one product alongside more than ten that were announced the same day, including Datastream, Analytics Hub, and BigQuery Omni for Azure. It’s part of a larger initiative to offer data governance across environments. Dataplex is built to integrate with Apache Kafka, Apache Spark, and Presto. We’re also partnering with Accenture, Collibra, Confluent, Informatica, HCL, Starburst, NVIDIA, Trifacta, and others.
Where does it fit into the broader industry?
With the adoption of SaaS and bespoke systems, data silos will continue to be reinvented. The industry is stepping away from closed data lake solutions and towards interoperable and open source compatible platforms. It took an interdisciplinary effort to design Dataplex’s control plane, data plane, security, metadata, catalog, integrations, and discovery enhancements. The result of that effort shows that there can be an out-of-the-box solution for teams building data lakes.
Where can you get started?
- Watch the Cloud Data Summit session on Dataplex
- Sign up for the private preview
- Quick video on our other analytics launches
5. Workflows
Workflows falls into our serverless category, and was announced in General Availability this January. Workflows lets you orchestrate and automate Google Cloud and HTTP-based API services with serverless workflows. In a nutshell, Workflows enables you to connect ‘things’ together. What kind of things? Pretty much anything that has a public API. You can connect multiple Cloud Functions together, or mix-and-match Cloud Functions with Cloud Run services, Google Cloud APIs or even external APIs.

Example of an event-driven workflow
As you grow across the cloud, you’re inevitably going to face the issue of managing and connecting more services. Between more modular architectures and containers becoming the de facto way of deploying flexible services, your solutions get more complex and harder to develop, debug, and visualize.
As API-driven architectures flourish, developers have commonly written custom services to manage integrations and host them in manually maintained virtual machines. Another option is to link them together with a carefully crafted, event-driven architecture. But observing the progress of workflow execution is nearly impossible, especially when a workflow might run for days. Implementing error handling can be difficult, and failures along a chain of events are burdensome to track down. Plus, changes to events for one workflow may break other workflows that also use those events. Without a central definition of the entire workflow, it can be difficult to see the full picture and make appropriate changes.
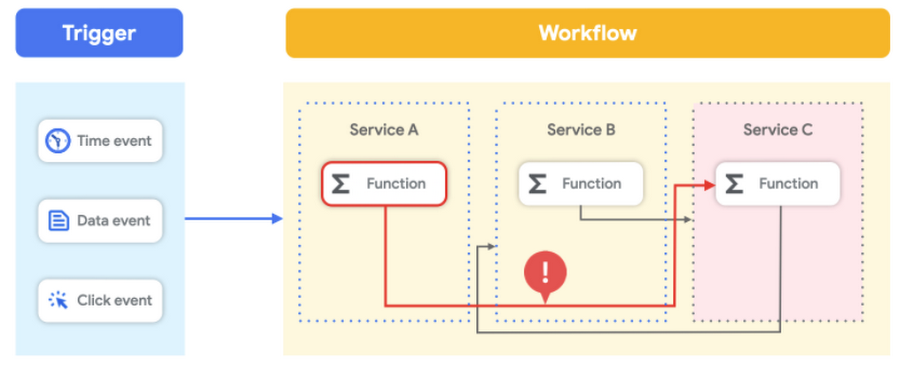
Changes to events for one workflow may break other workflows also using those events.
Workflows gives you that full picture of connected services and handles parsing and passing values among them. It has built-in error handling and retry policies. And it’s serverless, so it requires no infrastructure management and scales seamlessly with demand, including scaling down to zero. With its pay-per-use pricing model, you only pay for execution time.
Some key features:
- Built-in error handling
- Passes variable values between workflow steps
- Built-in authentication for Google Cloud products
- Low latency of execution
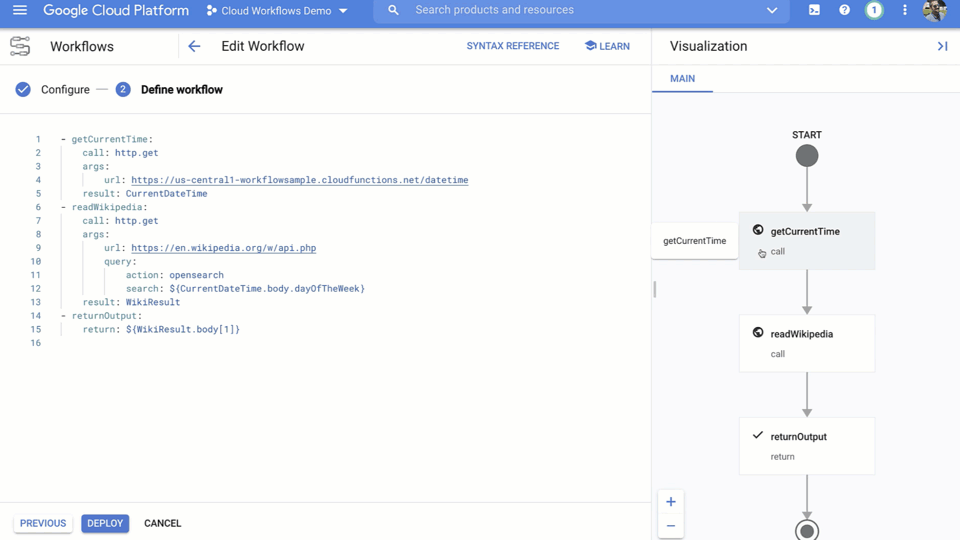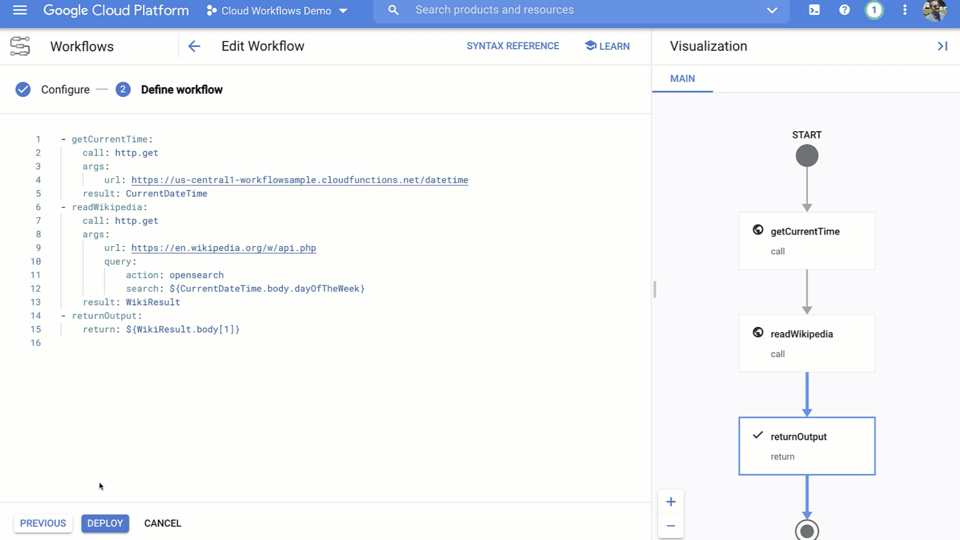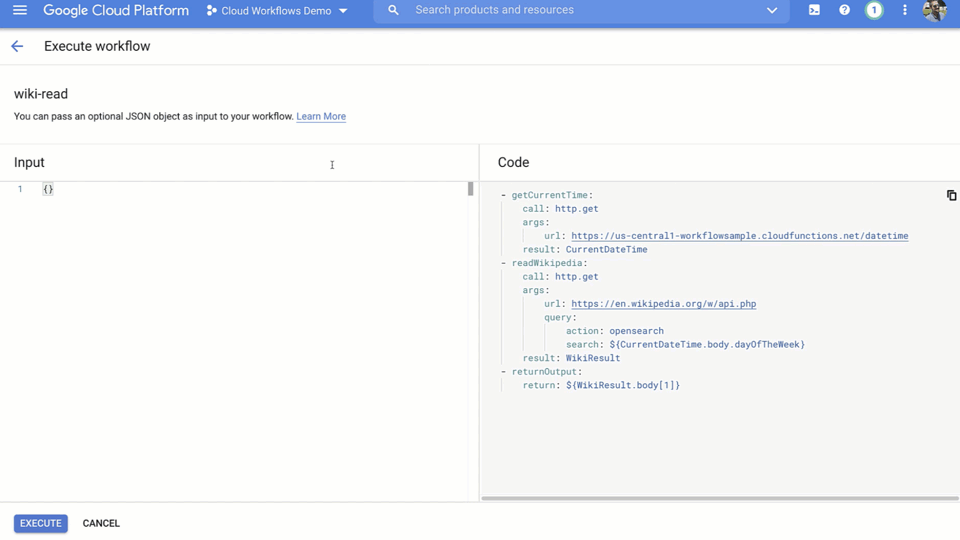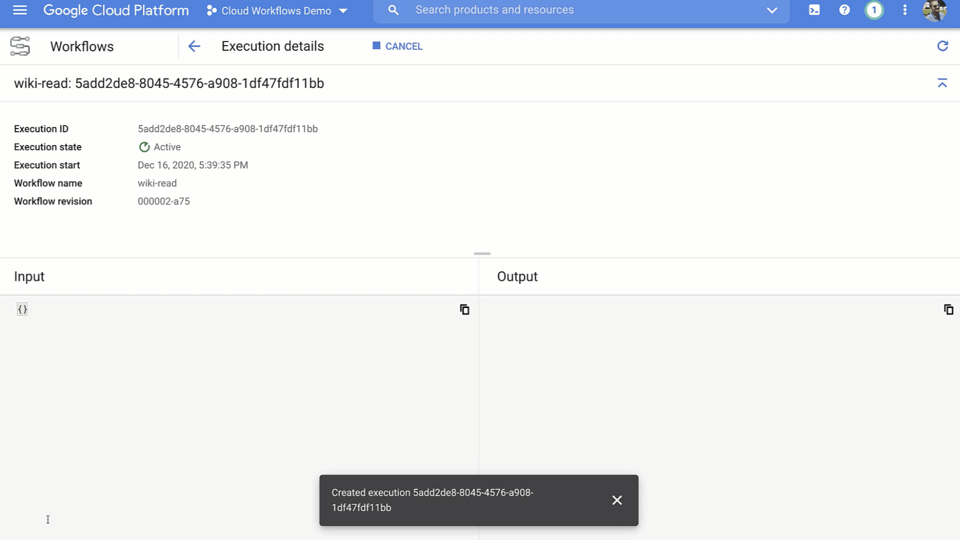
Where does it fit into our product strategy?
Some have asked me when you’d want to use Workflows over our first general purpose workflow orchestration tool, Cloud Composer. To oversimplify, if you want to manage your data processing, ETL, or machine learning pipelines and integrate with data products like BigQuery or Dataflow, then Cloud Composer is the way to go. However, if you want to process events or chain APIs in a serverless way, with bursty traffic patterns, high execution volumes, or low latency, you likely need to look at Workflows first. Workflows scales out automatically with no "cold start" effect and with a fast transition between the steps. This makes Workflows a good fit for latency-sensitive applications.
Where does it fit into the broader industry?
Creating practical workflows for customer invoice processing or batch processes like querying a database for any incomplete orders has been a need for decades. Yet, there hasn’t been a great way to create workflows without writing lots of custom logic. There are solutions popping up for low-code workflow automation to enable business users like RPA and AppSheet Automation. However, when you’re dealing with microservices, enterprise ERP systems, external APIs, and IT infrastructure automation, you need advanced features like continuous tracking of executions, error handling, data conversions, and conditional jumps. Workflows hits that spot for developer-focused serverless orchestration of any HTTP-based API services.
Where can you get started?
Start here:
Get hands-on:
- Codelab: Introduction to serverless orchestration with Workflows
- Tutorial: Loading data from Cloud Storage to BigQuery using Workflows
Phew!
You made it here. Thanks for sticking with me. I hope you found this list helpful to wrap your head around some of the big projects we’ve been working on over the past year. Though I didn’t purposely do this, I ended up with a list that crossed AI, container orchestration, compute, analytics, and serverless. And we have more in store coming up at Google Cloud Next '21. We’re planning to announce a number of new products in these categories, so register for the virtual, three-day event.

It’s clear we’re at a point where the cloud is now driving transformation more than it is driving efficiency. To me, these launches (among many more) are both efficient and transformational. Developers get the freedom to securely host apps and data where it makes the most sense, without sacrificing tooling, flexibility, or ease of use.
Got feedback or want to connect? Reach out to me @stephr_wong.




