AI Simplified: Managing ML data sets with Vertex AI
Priyanka Vergadia
Staff Developer Advocate, Google Cloud
At Google I/O this year, we introduced Vertex AI to bring together all our ML offerings into a single environment that lets you build and manage the lifecycle of ML projects. In a previous post, we gave you an overview of Vertex AI, sharing how it supports your entire ML workflow—from data management all the way to predictions. Today, we’ll talk a little about how to manage ML datasets with Vertex AI.
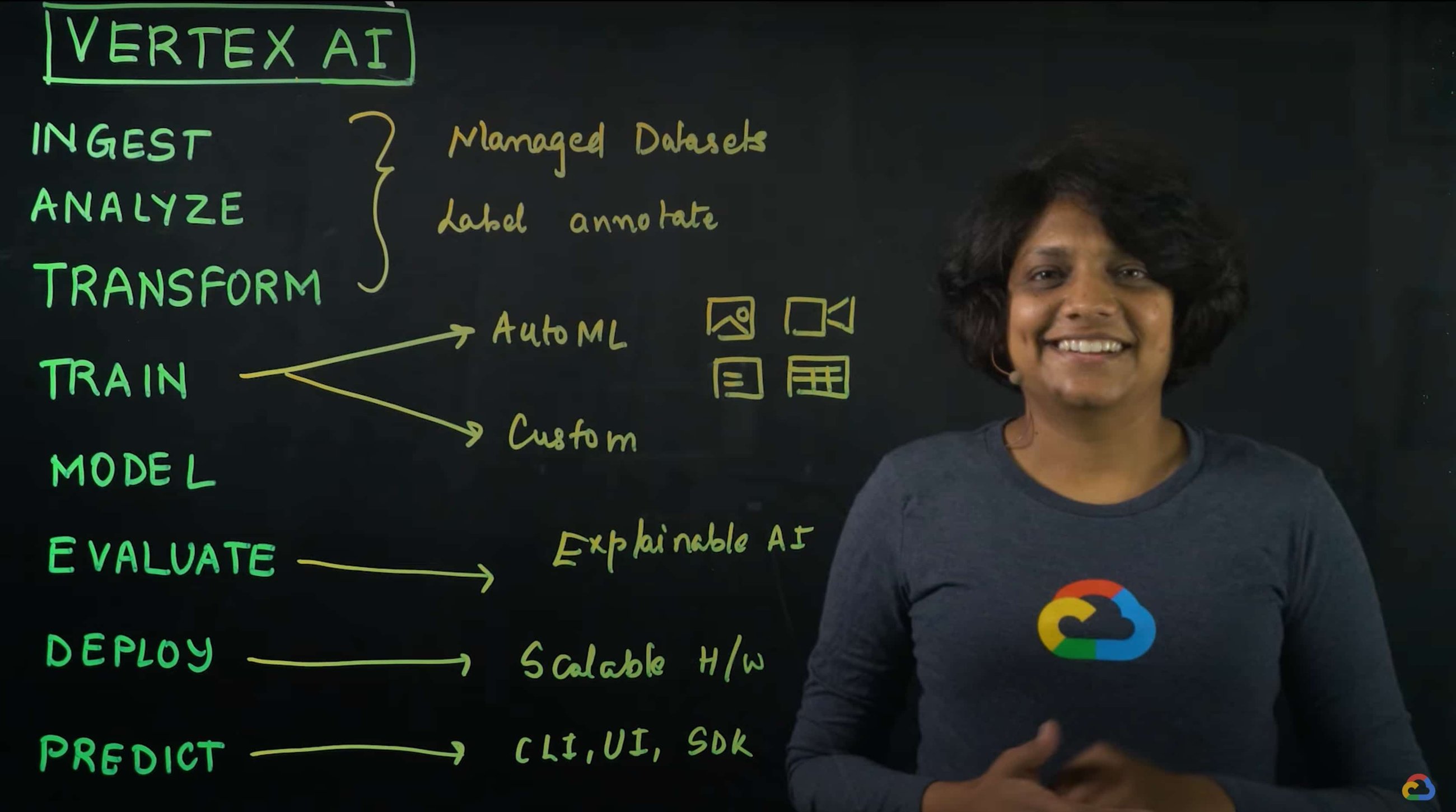
Many enterprises want to use data to make meaningful predictions that can bolster their business or help them venture into new markets. This often requires using custom machine learning models—something not every business knows how to create or use. This is where Vertex AI can help. Vertex AI provides tools for every step of the machine learning workflow—from managing data sets to different ways of training the model, evaluating, deploying, and making predictions. It also supports varying levels of ML expertise, so you don’t need to be an ML expert to use Vertex AI.

Types of data you can use in Vertex AI
Datasets are the first step of the machine learning lifecycle—to get started you need data, and lots of it. Vertex AI currently supports managed datasets for four data types—image, tabular, text, and videos.
Image
Image datasets let you do:
Image classification—Identifying items within an image.
Object detection—Identifying the location of an item in an image
Image segmentation—Assigning labels to pixel level regions in an image.
To ensure your model performs well in production, use training images similar to what your users will send. For example, if users are likely to send low quality images, be sure to have blurry and low resolution images in your data set. Don’t forget to include different angles, backgrounds, and resolutions. We recommend you include at least 1,000 images per label (item you want to identify), but you can always get started with 10 per label. The more examples you provide, the better your model will be.
Tabular
Tabular datasets enable you to do:
Regression—Predicting a numerical value.
Classification—Predicting a category associated with a particular example.
Forecasting—Predicting the likelihood of sudden events or demands.
Tabular data sets support hundreds of columns and millions of rows.
Text
With text datasets, you can do:
Classification—Assigning one or more labels to an entire document.
Entity extraction—Identifying custom text entities within a document, like “too expensive” or “great value”.
Sentiment analysis—Identifying the overall sentiment expressed in a block of text, for example, if a customer was happy or upset or frustrated.
Video
Video datasets enable:
Classification—Labeling entire videos, shots, or frames.
Action recognition—Identifying clips video clips where specific actions occur.
Object tracking—Tracking specific objects in a video.
Creating and managing datasets in Vertex AI
Now that we’ve covered the different types of data you can use, let’s shift to creating and managing those datasets. In the Cloud Console, go to Vertex AI dashboard page and click Datasets, then click Create Project.
Say you want to classify items within a set of photos. Create an image dataset and select image classification. You can import files directly from your computer, which will be stored in Cloud Storage. Then, you’ll need to add the corresponding labels (items you want to identify) for your images. If you already have labels, you can use the Import File option to import a CSV with your image URLs and their labels. If your data is not labeled and you would like human help to label it, you can use the Vertex AI data labeling service. Once the files are uploaded, you can create labels and assign them to the images. You can also analyze the images in the data set, the number of images per label, and a few other properties.
Depending on the type of data you use, your options might vary slightly. For example, if you want to use tabular data, you could upload a CSV file from your computer, use one from Cloud Storage, or select a table from BigQuery directly. Once you select the table, the data is available for analysis.
More to come
This concludes our overview of creating and managing datasets in Vertex AI. In a future installment, we’ll go over the next phase of the machine learning workflow: building and training ML models.
If you enjoyed this post, keep an eye out for more AI Simplified episodes on YouTube. In the meantime, here’s where you can learn more about Vertex AI.




