ML を使用して高度にパーソナライズされた投資に関するおすすめを作成する技術的なソリューション

Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
Investment Products Recommendation Engine(IPRE)は Google Cloud を使用して SoftServe により開発されたもので、リテール バンキングのお客様の投資に関する一般的な課題に対処するために設計されたソリューションです。特に、BigQuery ML モデルの能力を利用して投資のレコメンデーションを行います。投資データを処理するため、ビッグデータのパイプラインが活用されます。Terraform を使用することで、環境設定を自動化できます。このブログ投稿では、ソリューションの技術的な実装について掘り下げて解説します。
ソリューション アーキテクチャ
ソリューションの技術的な部分について掘り下げ、ソリューションのアーキテクチャを検討してみましょう。
パターン アーキテクチャのコンポーネントは、図 1 に示すように 3 つの主な部分に分けられます。
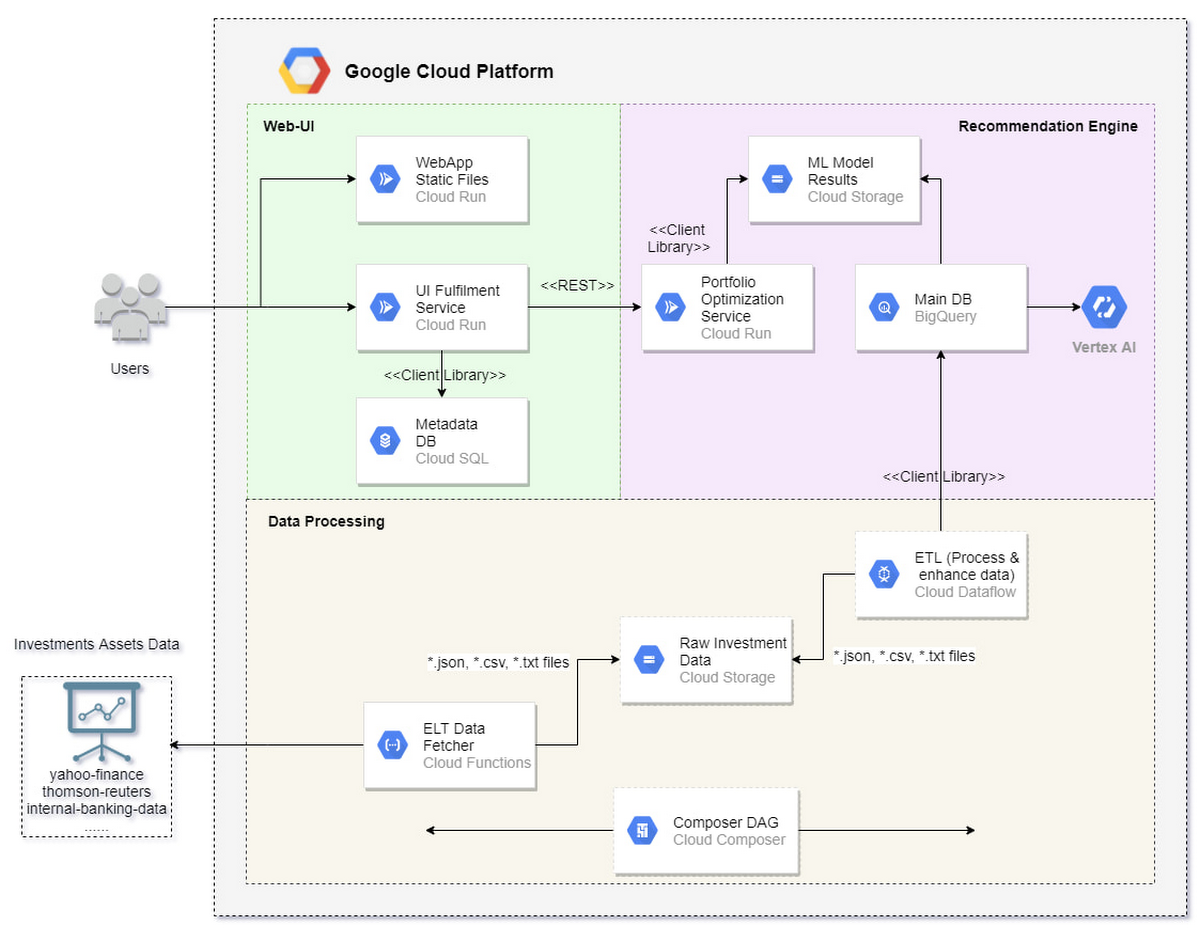
Web-UI 部分は緑色で示され、ウェブ アプリケーションに対応します(Cloud Run にデプロイされている React.js アプリケーション)。このアプリケーションは、投資のリスク選好とポートフォリオ投資のおすすめの機能を示しています。このウェブ アプリケーションには、ユーザーのリクエストに対応するためのデータベースがあります。
データ処理部分はベージュ色で示され、データ変換、集約、およびデータを BigQuery データレイクに置くデータ処理に対応します。この部分には、外部ソースからデータをフェッチする(サンプルデータとして Yahoo! ファイナンスが使用されます)、元データをクラウドデータ ストレージに保存する、Cloud Dataflow を使用してデータを変換する、データを BigQuery に置く作業が含まれます。データ パイプラインは Cloud Composer により調整されます。
レコメンデーション エンジン部分はピンク色で示され、レコメンデーション エンジン(RE)に対応します。RE は、ウェブ アプリケーションからの受信リクエスト用にポートフォリオの最適化データを提供します。AutoML Tables モデルは、2 つの異なる予測に使用されます。
投資家のリスク選好
投資のおすすめ
このソリューションは Google Cloud 上にデプロイされます。すべての必要なコンポーネントを設定し、相互に適切な通信を確立するため、Terraform が使用されます。
IPRE ワークフロー
ユーザーのリスク選好に基づいて投資のおすすめを行うため、次の手順が行われます。
Investor Risk Preference クラウド関数により、ユーザーの合成データとユーザーの選好が生成されます。
Cap Market クラウド関数により Yahoo! ファイナンスから資本市場データがフェッチされ、元データとして Cloud Storage に保存されます。
バケットで新しい元データが使用可能なとき、Cloud Composer で調整された Cloud Dataflow ジョブがトリガーされます。Dataflow が、処理済みのデータを BigQuery に保存します。
初期セットアップ後に(または毎日)、Cloud Composer により調整される BigQuery のトレーニング AutoML ジョブがトリガーされ、対応する BigQuery ML モデルを作成します。
BigQuery AutoML は、使用可能なデータに基づいて投資家の潜在的なリスク選好プロファイルと投資のおすすめを生成し、Cloud Storage に置きます。
ウェブ アプリケーションにログインしているユーザーについて、リスク選好プロファイルが決定されます。ユーザーの投資プロファイルに基づいて、おすすめが表示されます。別の UI フルフィルメント バックエンド サービスにより、おすすめされるデータがユーザーに提示されます。
新しい資本市場データが使用可能なら、毎日同じフローで投資ポートフォリオのおすすめが更新されます。
データ パイプライン
IPRE サービスは、内部と外部で複数のデータソースを使用します。このソリューションは、BigQuery、Cloud Storage、Dataflow などのテクノロジーを使用し、スケーラブルなデータ パイプラインを実装します。
すべての外部の元データ ストリームは、専用の Cloud Storage バケットに集約されます。Cloud Functions の関数により、小さな前処理スクリプトがトリガーされます。Cloud Storage バケットにオブジェクトを書き込むと、新しいデータを BigQuery に追加するための Dataflow ジョブがトリガーされます。
この種類のアーキテクチャにより、ETL パイプラインはデータ破損に対する復元性を持ち、複数のデータソースに対してスケーリング可能になります。
Cloud Functions により、膨大な量のデータセットをデータレイクから DWH に移行するための、クリーンで費用対効果の高いソリューションを実現できます。
資本市場のデータ
市場の履歴データは、おすすめサービスの重要な要素です。専用のデータ パイプライン ジョブにより、Yahoo! ファイナンスから選択された証券の相場が収集されます。すべての選択された資産は、償還やリスクが異なります。これにより、IPRE は投資家の多様な選好に応じて、広範なポートフォリオを構築できます。多少の前処理を行った後で、毎日の時価の履歴(q)が定期的な償還に変換されます。

観測値の償還が、固有のタイムスタンプ付きで Cloud Storage に書き込まれます。これにより送出が減少し、BigQuery が重複データを受信しないことが保証されます。スクリプトの最初の実行時に、2017 年からのすべての観測値が BigQuery に送られます。
以後の実行では、「未見」のデータの増分的な観測値が提供されます。ETL の最後のステージでは、処理済みのデータが BigQuery に書き込まれます。BigQuery にデータを集約することで、他のサービスは費用対効果が高い方法でデータを取得できるようになります。
投資家のリスク選好
投資家のリスク選好(IRP)は合成データセットで、既存の数千の個人投資家に関する履歴のレコードが含まれています。このデータセットは、個人の投資選好に基づいてカスタマイズされたおすすめを行うための重要なコンポーネントです。
リスク嫌悪は、関心のあるターゲット変数です。平均月収、教育、ローン、預金など、15 の独立変数が存在します。投資家の属性は、ガンマ、ギュンベル、ガウス分布、R 分散、その他各種の連続変数分散関数を使用して生成されます。スクリプトにより投資家の属性のスナップショットが毎月作成され、48,000 のデータポイントになります。
Cloud Functions の関数は、IPRE が最初に開始されたとき、データセットの生成をトリガーします。Dataflow は、生成されたデータセットを Cloud Storage から BigQuery に移行します。
機械学習の高度な分析
機械学習(ML)のワークフローは次のとおりです。
元データが前処理され、GCS にアップロードされます。Cloud Composer により Dataflow ジョブが登録されます。
処理済みのデータが、定義済みのデータスキーマとデータ形式で BigQuery にアップロードされます。
Pub/Sub トリガーにより、AutoML と ARIMA のモデルのトレーニングがトリガーされます。このトレーニングは、統合された BigQuery ML ツールを使用して行われます。
トレーニングが完了すると、システムは推論処理をトリガーします。
アップロードされた BigQuery データを入力すると、個人のリスク選好とティッカーの価格が予測されます。
予測結果は、結果をキャッシュしてデータを再利用可能にするため、Cloud Storage に保存されます。
結果は、Cloud Run 上にデプロイされているレコメンデーション エンジン経由で発行され、エンドユーザーに送信されます。
このワークフローを図 2 に示します。
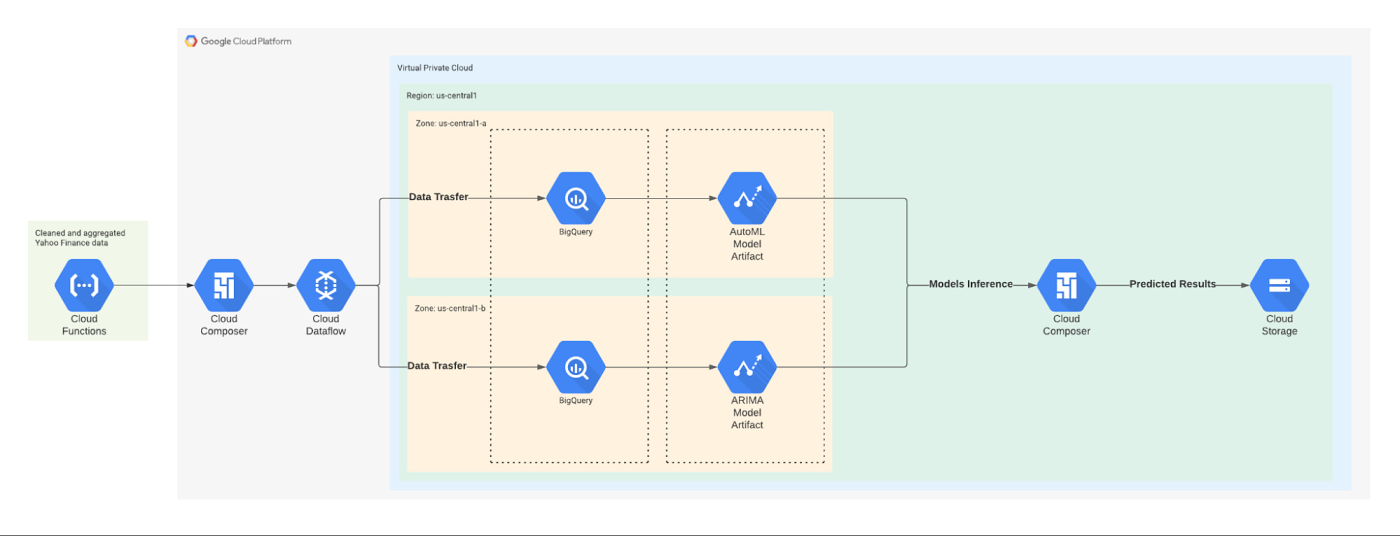
図 2:機械学習のワークフロー
IPRE 実装の特徴
このソリューションは再現性が高く、すべてのサービスをセットアップするために必要な手作業の労力が最小になるよう設計されています。
ウェブ アプリケーションのユーザーは、いくつかのウォレットを作成し、切り替えることができます。ウォレットの操作に加えて、投資のおすすめとユーザーのポートフォリオを、詳細な統計とともに参照できます。
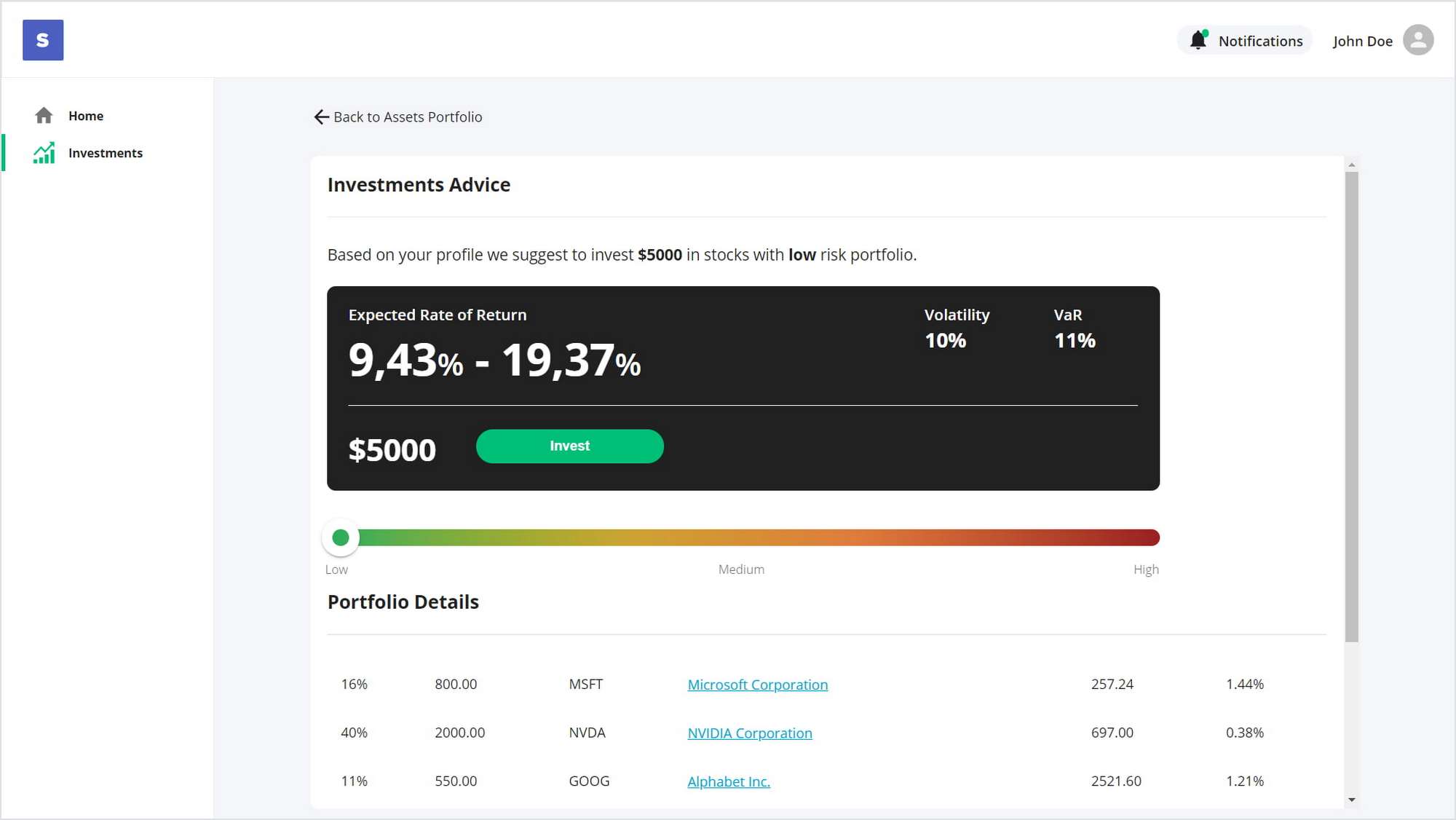
アプリケーションのバックエンドは、Django フレームワークを使用して開発されたサービスです。このサービスは IPRE とウェブ アプリケーションとの間のブリッジとして機能し、ウォレットの操作、トランザクションの管理、ユーザー ポートフォリオの表示を行います。
ML インターフェース パイプラインはデプロイが簡単になるよう考慮して設計されているため、ソリューションをクリック 1 つで Google Cloud にデプロイできます。
IPRE による的確な投資
SoftServe は Google Cloud Platform を使用して IPRE ソリューションを開発し、そのソリューション内にエンドツーエンドの自動 ML モデルを実装しました。このモデルはクリック 1 つでデプロイできます。SoftServe の Investment Products Recommendation Engine は、リテール バンキングのお客様に向けた、投資プロダクトのクロスセルの可能性を増やすうえで要となるソリューションです。これにより、金融の専門家ではない、リテール バンキングを利用する個人投資家と、今日の投資市場における投資対象の複雑性との間のギャップが埋められます。このソリューションは、ML テクノロジーを適用して、ユーザーのグループを各自のリスク選好に基づいて細かく分割し、高度にカスタマイズされた投資プロダクトの選択を各ユーザーに与えます。
IPRE は BigQuery ML モデルの能力に基づいて投資のおすすめを作成し、ビッグデータ パイプラインを使用して投資データを処理します。環境のセットアップは Terraform により自動化されます。このソリューションには、完全に自動化された ML プロセスが組み込まれています。大規模なパターン自動化により、デベロッパーは簡単に実装に切り替えて、各種の構成オプションを試すことができます。
ソリューションについてさらに深く調べる、または GCP を使用して独自の IPRE を実装するには、パターンの詳細を調べるか、詳細について Google Cloud や SoftServe チームにお問い合わせください。
-Google Cloud データ分析担当アウトバウンド プロダクト マネージャー David Sabater Dinter
- SoftServe シニア データ サイエンティスト Oleksii Lialka



{kind=link}