データから利益を得る: フィンテックのシリーズ C ラウンド向けに無駄のないデータスタックを構築
Google Cloud Japan Team
※この投稿は米国時間 2024 年 3 月 6 日に、Google Cloud blog に投稿されたものの抄訳です。
「千里の道も一歩から」とは、よく言われることです。
10 年前、データ技術スタックの構築は、今よりもずっと千里を旅するような感覚でした。テクノロジー、自動化、そしてデータの価値に対する企業の理解は著しく向上しました。その代わり、昨今の問題となっているのが、最初の一歩を踏み出す方法を知ることです。

図: PrimaryBid の概要
PrimaryBid は、資金調達の際に公開会社とそのコミュニティをつなぐ、規制された資本市場のテクノロジー プラットフォームです。しかし、当社の要件には、以下のように複数のレイヤがあるため、どのデータ テクノロジーを選択するかを決めるのは困難でした。
- PrimaryBid は、個人投資家が公開株式市場や債券市場で短期資金調達案件にこれまでにない方法でアクセスできるようにするものです。そのため、当社には市場の状況に柔軟に対応できるプラットフォームが必要です。
- PrimaryBid は規制の厳しい環境で運用されているため、当社のデータスタックは、適用されるすべての要件に準拠する必要があります。
- PrimaryBid はさまざまな種類のセンシティブ データを扱うため、情報セキュリティは重要な要件です。
- PrimaryBid のデータアセットは非常に専有的です。この競争上の優位性を最大限に活用するためには、スケーラブルなコラボレーション指向の AI 環境が必要でした。
- 野心的な国際展開を目指す企業として、当社が選ぶテクノロジーは、飛躍的にスケーリングが可能で、グローバルに利用可能でなければなりません。
- そして、おそらく最大の決まり文句ですが、上記のすべてを可能な限り低コストで実現する必要がありました。
この 12 か月あまりの間に、上記の課題に沿って無駄のない、安全で低コストのソリューションを構築し、最適なベンダーと提携しました。ほんの数年前と比べ、現在、データチームが利用できるテクノロジーの質の高さに大いに感銘を受けています。当社は最終的に、エンドツーエンドのデータと AI の統合プラットフォームを構築しました。このブログ投稿では、当社の意思決定の仕組みと、選択したアーキテクチャについて説明します。
全体像
PrimaryBid の環境の全体像は、データの専門家であればそれを見て驚くことはないでしょう。私たちは各種ソースからデータを収集し、有用なものに構造化してから、さまざまな方法で表面化したのち、それらを組み合わせてモデルにします。このプロセス全体を通して、データ品質をモニタリングし、データ プライバシーを確保して、問題が発生した場合はチームにアラートを送信します。
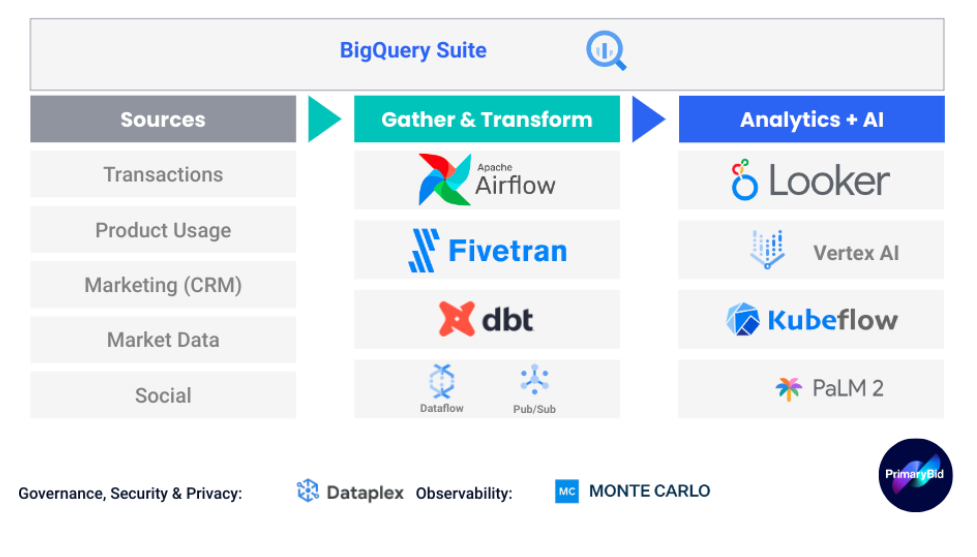
図: 当社のデータスタックの概要
データの収集と変換
元データをデータ プラットフォームに取り込むために、ローコードで高速かつスケーラブルなソリューションを提供する技術パートナーを求めていました。この目的のために、当社のニーズを満たす Fivetran と dbt を組み合わせることにしました。
Fivetran は膨大な種類の事前構築済みデータコネクタをサポートしており、データチームはわずか数分で新しいフィードを作成することができます。採用した費用モデルは、毎月の「アクティブ」な行数に基づいていて、使用した分だけの料金を支払います。
Fivetran はコネクタのメンテナンスも行ってくれます。API 統合を更新する永続的なサイクルをアウトソーシングできるので、膨大なエンジニアリング時間から解放されます。
データが抽出されると、dbt は元データを、下流のツールで使用可能な構造に変換します。このプロセスは、分析エンジニアリングと呼ばれます。dbt と Fivetran は相乗的なパートナーシップを築いており、多くの Fivetran コネクタには dbt テンプレートがあらかじめ用意されています。dbt はデータ エンジニアに絶大な人気があり、分析を確実に変換できるようにするソフトウェア開発のベスト プラクティスが数多く含まれています。
どちらのプラットフォームもパイプラインのスケジュール設定とモニタリングのための独自のオーケストレーション ツールを備えていますが、より詳細な制御のために、当社ではGoogle Cloud の Cloud Composer を介して管理する Apache Airflow 2.0 をデプロイしています。
データ ストレージ、ガバナンス、プライバシー
この時点で、Google Cloud が当社のデータスタックにおけるさまざまなニーズを解決し始めます。
まず、Google Cloud の BigQuery を導入することから始めました。BigQuery は非常にスケーラブルかつサーバーレスであり、コンピューティング費用とストレージ費用が分離されているため、必要なときに必要な分だけを支払うことができます。
しかしそれ以上に、BigQuery エコシステムの魅力は、データとモデルのプライバシー、ガバナンス、リネージすべてが統合されていることでした。Google Cloud の Dataplex を活用することで、元データ自体にセキュリティ ポリシーを 1 か所で設定することができます。データが変換され、サービス間で受け渡される際にも、同じセキュリティ ポリシーが遵守されます。
その一例が PII で、これは必要な一部の従業員以外にはロックされています。データには一度だけ「has_PII」フラグを付けます。データにアクセスするためにどのようなツールを使っていても、元データに含まれる PII へのアクセス権がなければ、それを見ることはできません。

図: Dataplex を使用した統合ガバナンス
データ分析
以下の 3 つの主な要素に基づいて、当社のセルフサービスおよびビジネス インテリジェンス(BI)プラットフォームに Looker を選びました。
- Looker は、データそのものを保存するのではなく、直接データ ウェアハウスに対して SQL クエリを記述します。正しいクエリが作成されるように、エンジニアとアナリストは「LookML」を使用して Looker の分析モデルを構築します。LookML はほとんどの場合ローコードですが、複雑な変換の場合は SQL をモデルに直接書き込むことができるので、当社のチームが SQL で培った豊富な経験を活かすことができます。この例では、データを BigQuery に保存し、Looker を通してアクセスしています。
- Looker を当社のプラットフォームに拡張できることは、重要な決定要因でした。LookML モデルがあれば、変換されたクリーンなデータを下流のどのサービスにも渡すことができます。
- 最後に、Looker と Dataplex の相互作用は特に強力です。バックグラウンドでは、Looker が BigQuery に対してクエリを記述しています。その際、データ セキュリティとプライバシーに関するルールはすべて保持されます。
Looker を使用してわかった利点については、まだまだ語りたいことがたくさんあるので、今後のブログ投稿で紹介したいと思います。
AI と ML
データ パイプラインの最後のステップは、AI / ML 環境です。ここでは、Google Cloud が提供するプロダクトをさらに活用し、モデルの開発、デプロイ、モニタリングに Vertex AI を使用することにしました。
モデル構築を可能な限り柔軟にするために、Vertex AI Pipelines 環境内でパイプライン オーケストレーション用のオープンソース Kubeflow フレームワークを使用します。このフレームワークは、モデル構築プロセスの各ステップをコンポーネントに分解します。各コンポーネントは完全に自己完結型のタスクを実行し、メタデータとモデル アーティファクトをパイプラインの次のコンポーネントに渡します。その結果、適応性が高く、可視化された ML パイプラインが実現するので、個々の要素には、他のコードベースに影響を与えることなく、独立してアップグレードやデバッグを行うことができます。
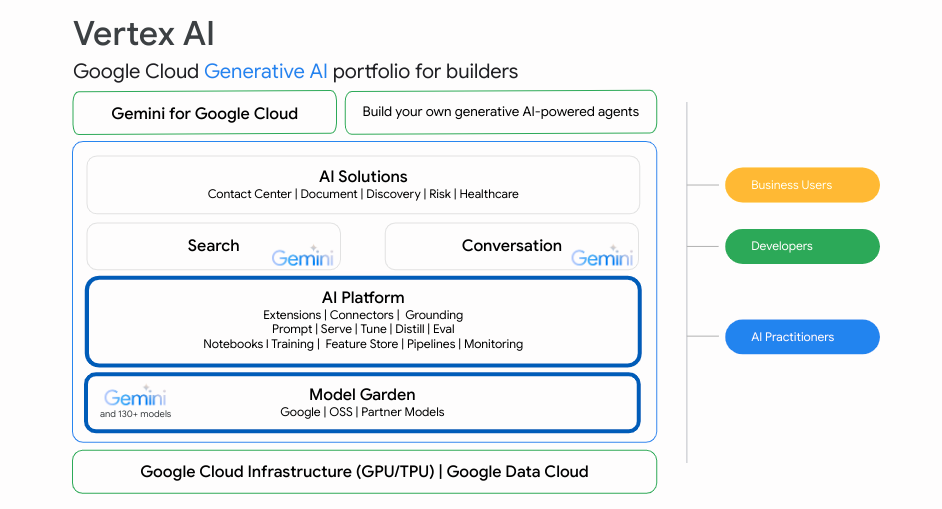
図: Vertex AI Platform
最後の仕上げ
この主要な機能をセットアップしたうえで、さらにいくつかのコンポーネントを追加し、データスタックにさらなる機能と復元力を加えました。
- リアルタイム パイプライン: Fivetran 取り込みと並行して、コア トランザクション データをリアルタイムで取り込む軽量なパイプラインを追加しました。これは、Google Cloud のマネージド サービスである Pub/Sub と Dataflow の組み合わせを活用し、最も重要なデータフィードに速度と復元力の両方を付加します。
- リバース ETL: CDP パートナーを活用して、顧客に関する分析属性を顧客管理ツールに書き戻し、マーケティングやサービスのコミュニケーションに関連するオーディエンスを構築できるようにしています。
- 生成 AI: 利用可能な生成 AI テクノロジーの大幅な増加に伴い、Google の PaLM 2 を活用した社内アプリケーションをいくつか構築しました。外部アプリケーションの構築にも取り組んでいるので、この分野にもご期待ください。
以上、当社のデータスタックについて簡単にご説明しました。私たちは、選択したデータ テクノロジーにとても満足していますし、会社からの評判も上々です。このブログ投稿がお役に立てば幸いです。また、BI 向けの Looker を当社でどのように利用しているかをご紹介するのを楽しみにしています。
この投稿の執筆に協力してくれた PrimaryBid のデータチーム、Stathis Onasoglou、Dave Elliott に心より感謝します。
-PrimaryBid、データおよび AI 担当ディレクター Andy Turner 氏
-Google Cloud カスタマー エンジニアリング(英国、アイルランド)、データおよび AI 担当プラクティス リード Bipul Kumar

