ML で世界の野生動物を絶滅から救う

Google Cloud Japan Team
※この投稿は米国時間 2021 年 4 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
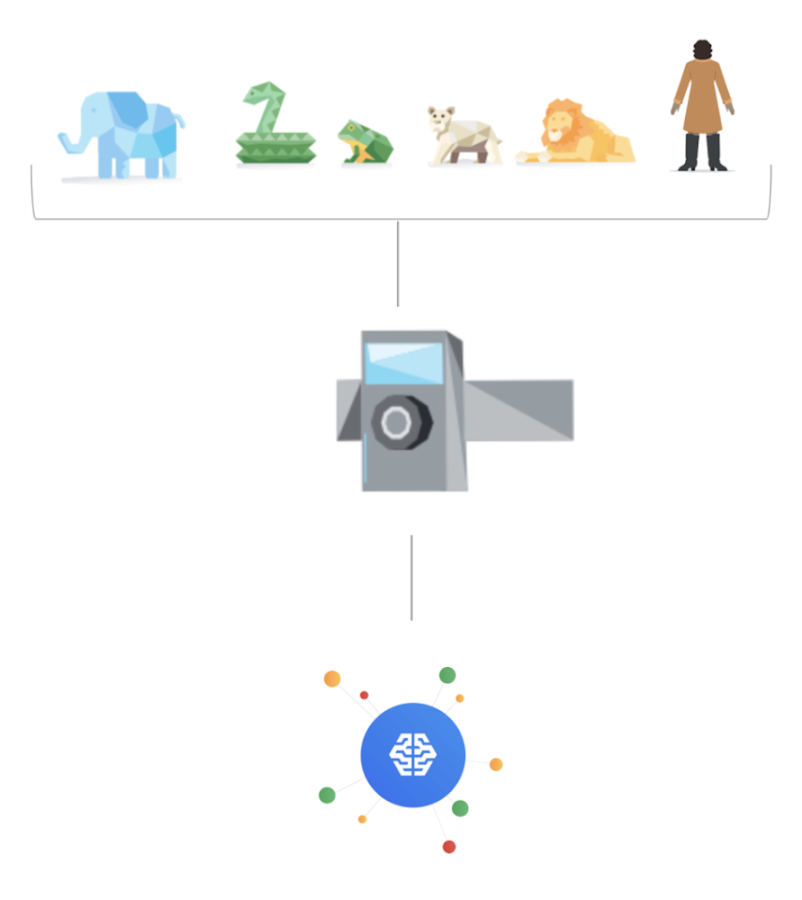
野生動物は自然や私たちに大いなる恵みを与えてくれます。残念ながら、野生動物はゆっくりと、しかし確実に地球上から姿を消しており、私たちはこの危機を理解し、食い止めるために十分な信頼できる最新の情報も持っていません。テクノロジーと科学の力を利用することで、世界中の [モーション センサー カメラ] からの何百万枚もの写真を統合し、野生動物がどのような状況にあるかをほぼリアルタイムで明らかにして、より良い判断を下すことができます。
wildlifeinsights.org/about

ケーススタディのバックグラウンド
Google はいくつかの主要な自然保護団体と提携して、Wildlife Insights というプロジェクトを構築しました。これは、カメラトラップからの野生動物の画像をアップロード、管理、識別することができるウェブアプリです。このプロジェクトには、世界中誰でも、野生動物の個体群を保護し、その健康状態を把握したいと考える人が、それを非侵襲的な方法で行えるようにという意図があります。
しかし厄介なのは、何百万枚もの写真を一枚一枚確認し、すべての種を識別することです。そこで、このビッグデータの問題に、機械学習が大いに役立ちます。組織間のコラボレーションによって構築されたモデルでは、現在、最大 732 種を分類しており、例えば、アジアのカメラトラップがアフリカゾウを分類できないようにする(ジオフェンシングを使用)など、地域に応じたロジックも含まれています。これらのモデルは数年前から開発されており、世界中の動物の調査に貢献できるよう進化し続けています。詳細については、こちらをご覧ください。
この世界規模のコラボレーションには多くの労力を要しましたが、使用された基本的な技術の多くは、WildlifeLifeInsights.org で利用可能です。
この野生動物のためのプロジェクトにインスパイアされ、基本的な画像分類器の構築方法の学習に興味を持たれた方は、ぜひ読み進めてください。また、最後にご紹介するサンプル チュートリアルでは、使用したコードが含まれており、ステップバイステップのノートブックでインタラクティブに実行することができ、より学びを深められます(各ステップで「再生」アイコンをクリックすると、各プロセスが実行されます)。
野生動物を守るための画像分類モデルの作り方
Google は、「People and Planet AI」という Google Cloud シリーズを立ち上げ、前述のプロジェクトのような実際のケーススタディからヒントを得て、ユーザーが複雑な社会的、環境的課題の解決に役立つ優れたアプリを作る支援をしています。初回となる今回は、Google Cloud のビッグデータと ML の機能を使って、カメラトラップが捉えた動物の画像を自動的に分類する方法をご紹介します。動画はこちらからご覧いただけます。
開始に必要な条件
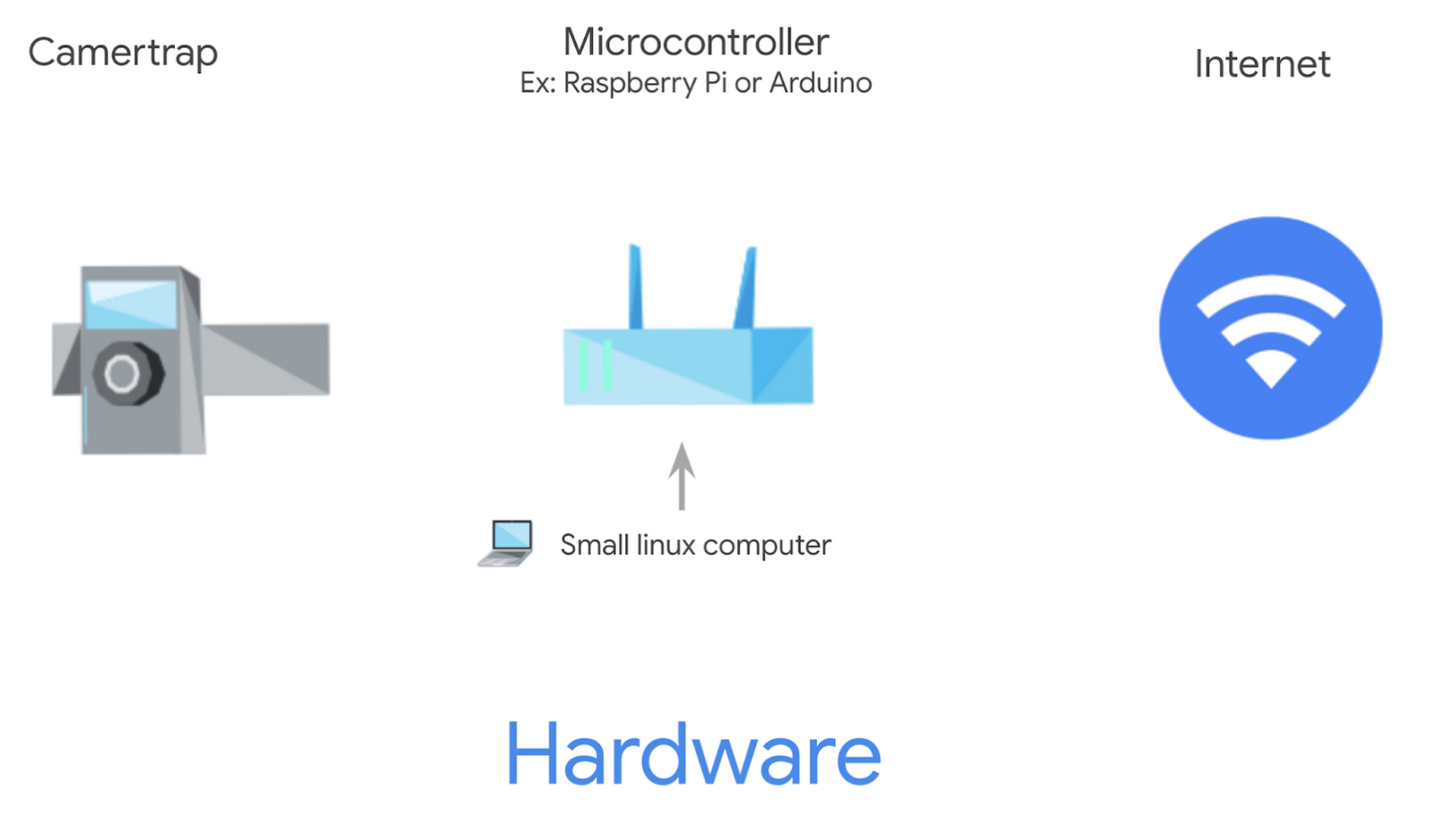
ハードウェア
2 つのハードウェア コンポーネントが必要となります。
カメラトラップ → 写真を撮るためのもの(Wildlife Insightsにアップロードして共有し、野生動物のグローバルな観察ネットワークを構築することを強く推奨します)。
マイクロ コントローラ(Raspberry Pi や Arduino など) → 各カメラの小型 Linux コンピュータとして使用します。ML モデルをローカルでホストし、画像を種ごとにラベリングしたり、使用できない空白の画像を削除したりするなどの作業を行います。
この 2 つのツールを使用して、画像をラベリングし、インターネット接続経由でアップロードすることを目的としています。これはモバイル ネットワーク上で行うことができます。しかし、遠隔地では、定期的にマイクロコントローラを Wi-Fi 対応エリアに持って行き、転送を行う必要があります。
? 2 ちょっとしたヒント:
1.? マイクロコントローラが分類した画像をインターネット経由で送信するには、Cloud Pub/Sub を使用することをおすすめします。これは、クラウド インフラストラクチャのエンドポイントにメッセージとして画像を公開します。Pub/Sub は、独立したアプリケーション間でのインターネットを介したメッセージの送受信をサポートします。
2.? 数十台または数百台のカメラトラップとそのマイクロコントローラを管理している場合、Cloud IoT core を利用することで、これらのデバイスすべてに ML 分類モデルを同時にアップロードできます(特にモデルにフィールドからの新しいデータを更新する場合)。
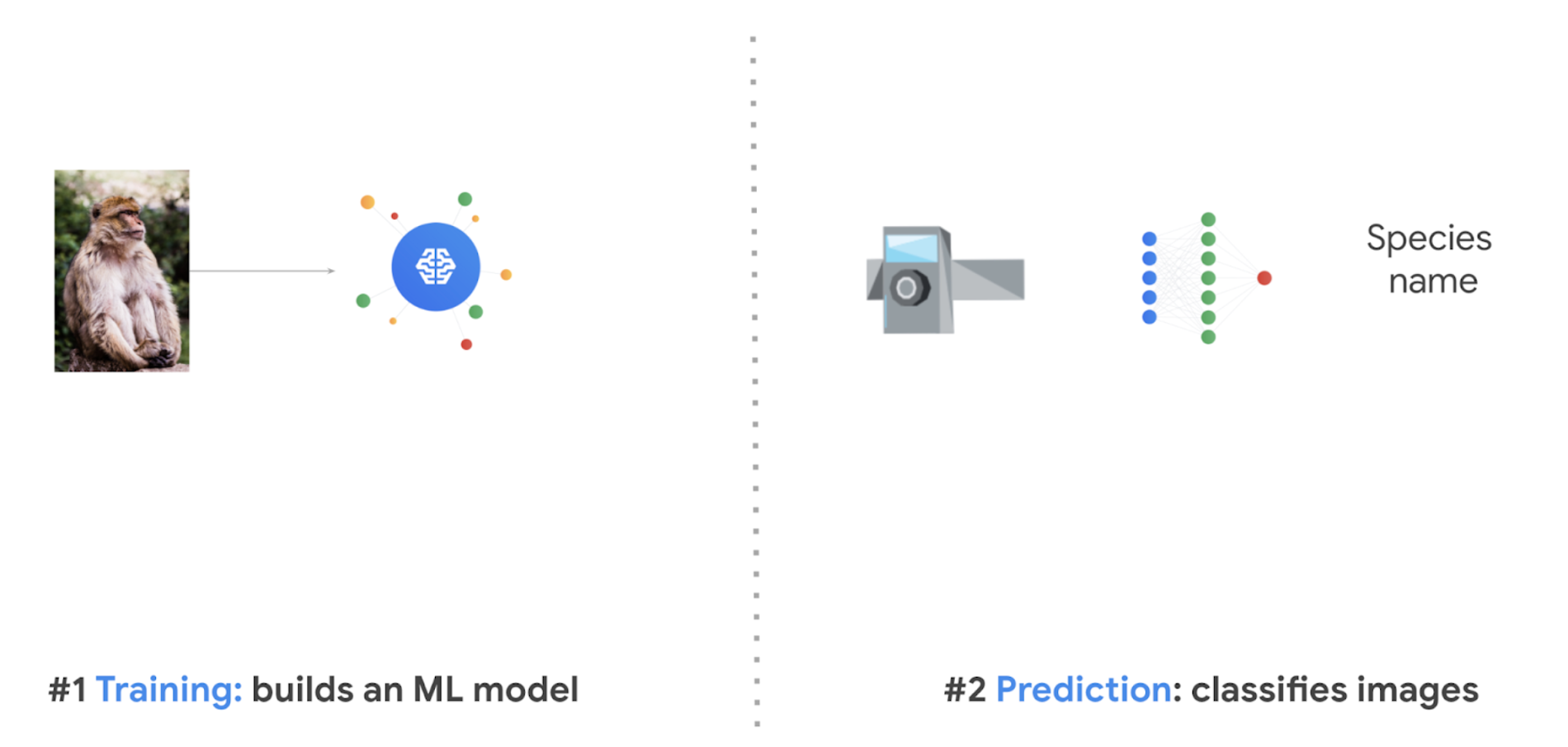
ソフトウェア
このモデルは、lila.scienceの無料のカメラトラップ データセットを使って、Google Cloud 経由でトレーニングされ、出力されます。この記事の公開時点で、モデルのトレーニングにかかる費用は 1 回あたり $30 以下です(詳細な内訳はこの記事の下部に記載しています)。
? ヒント: 新種の画像をどれだけ収集したか、あるいは画像分類モデルをどれだけ頻繁にアップグレードするかに応じて、年に 1~2 回再トレーニングを行えます。
トレーニング用画像の選択と ML モデルの検証
手間のかかる作業のほとんどを行うのは、Dataflow と AI Platform(統合型)の 2 つのプロダクトです。Dataflow は、機械学習に必要な大量のデータを処理できるサーバーレスのデータ処理サービスです。このシナリオでは、このサービスを使って次の 2 つのジョブを実行します。
Dataflow ジョブ 1: 画像のメタデータから BigQuery でデータベースを作成します。収集したメタデータの 2 カラムには、前述のカメラトラップ データベースからのデータを使用します。これは、1 回限りの設定です。
category: 予測したい種、これが私たちのラベルになります。
file_name: 画像ファイルが配置されているパス。
また、非常に基本的なデータ クリーニングも行います。例えば次のような、使用できないカテゴリを持つ行は削除します。#ref!、empty、unidentifiable、unidentified、unknown。
Dataflow ジョブ 2: バランスの取れたデータセットを作成するのに最適な画像のリストを作成します。これは、カテゴリごとに最小および最大の種数を持つ画像を選択するという私たちの要件に基づいています。

これは、情報が少なすぎる種を含んでしまい、後に正しく分類できなくなることのないよう、バイアスのないモデルをトレーニングするためです。
絵文字の例では、このようにデータが偏って見えます。
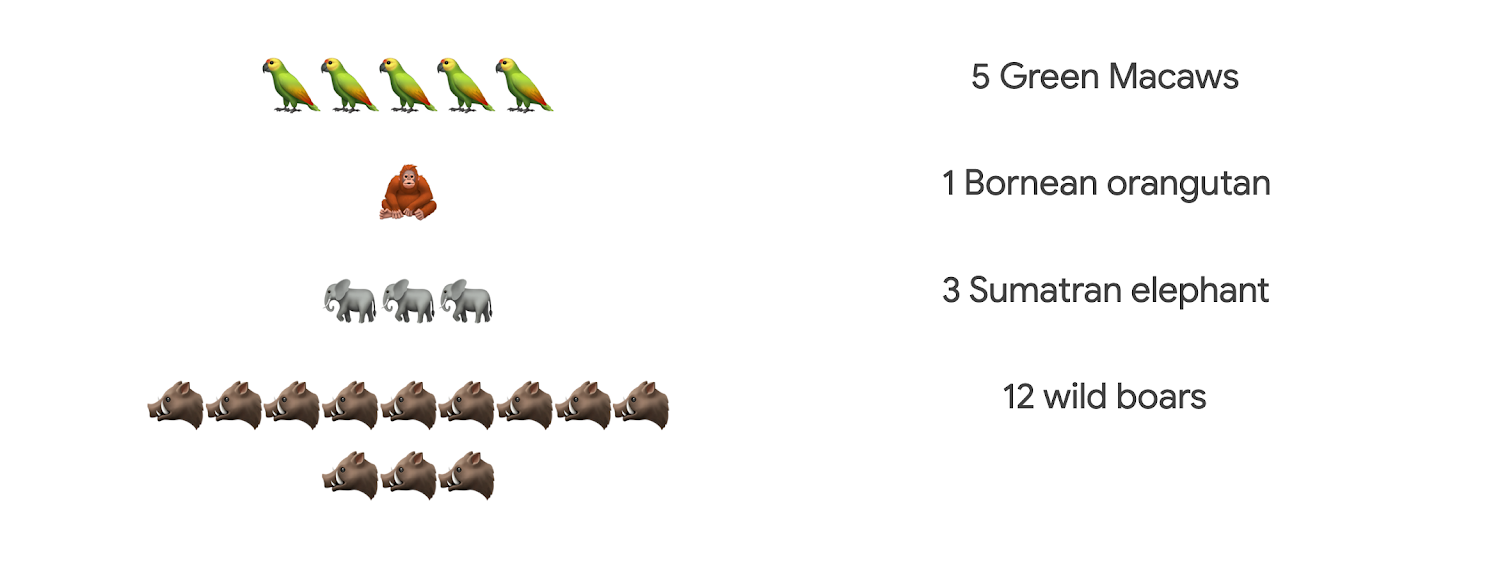
このデータセットのバランス調整が完了すると、Dataflow は lila.science から実際の画像を Cloud Storage にダウンロードする作業を行います。これにより、データセット全体ではなく、必要な画像のみを保存、処理することができ、計算時間とコストを最小限に抑えることができます。
ML モデルの構築
AI Platform Unified で AutoML と Cloud Storage に保存した画像を使ってモデルを構築します。このおかげで、今までモデルのトレーニングには何日もかかっていたのが、2~3 時間で済むようになりました。モデルの準備ができたら、それをダウンロードして各マイクロコントローラにインポートすれば、ローカルで画像の分類を始めることができます。では、モデルをクラウド上で動作させ、画像をどのように分類するかを見てみましょう。

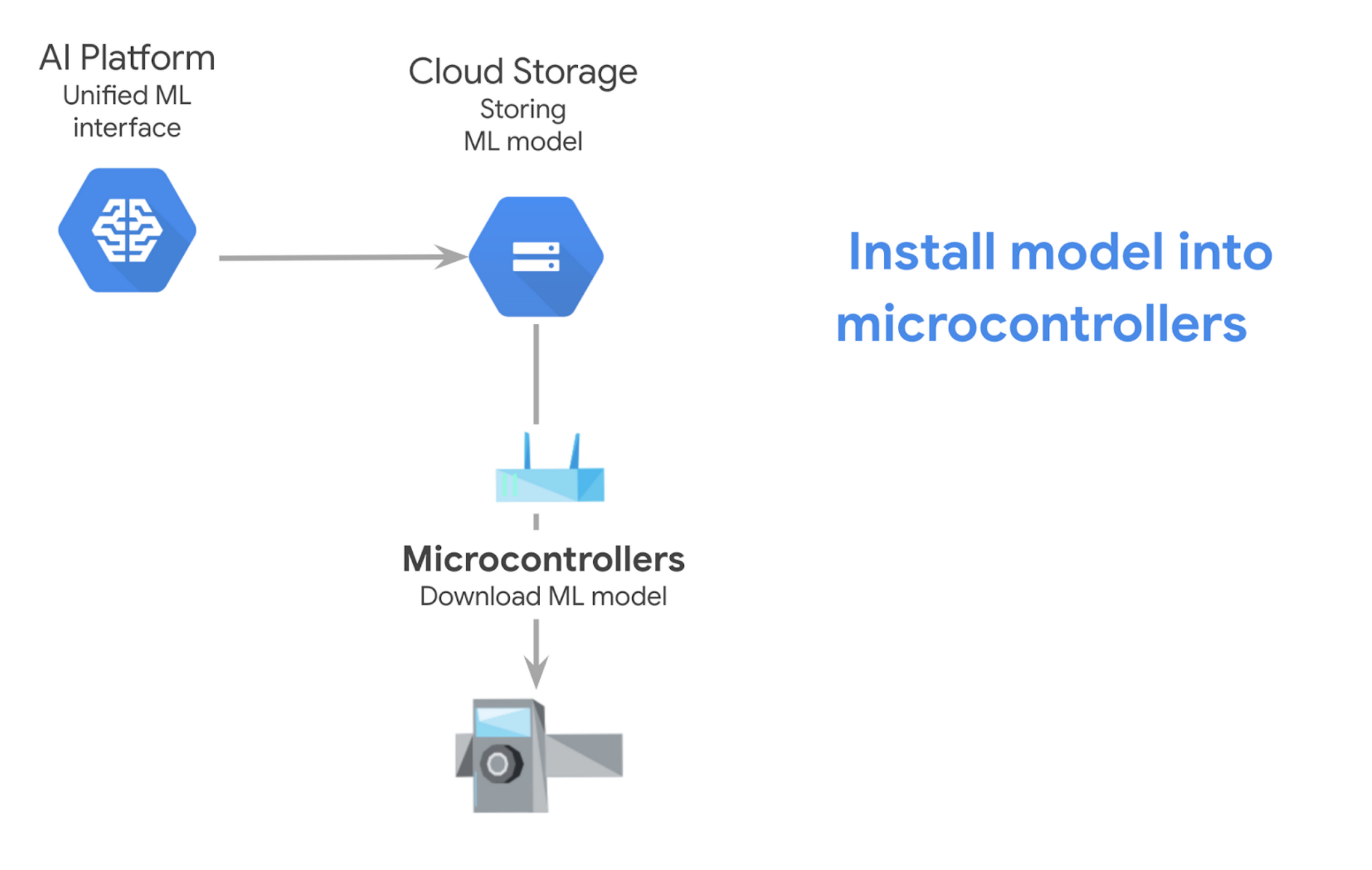
マイクロコントローラのエクスポート モデル
先ほどの例では、モデルをオンラインのエンドポイントとしてエクスポートしていましたが、モデルをエクスポートしてからマイクロコントローラにダウンロードするためには、以下の手順で行います。
お試しください
WildLifeInsights.org の無料ウェブアプリを使って、今すぐ画像をアップロードして分類できます。独自の分類モデルを構築する場合は、Google のサンプルを試すか、GitHub のコードをチェックしてみてください。事前の知識は必要ありません。画像分類モデルをトレーニングし、オンラインノートブック形式でいくつかの予測を実行するために必要なすべてのコードが含まれています。画面下部までスクロールし、このスクリーンショットの [Open in Colab] をクリックするだけです。

先に述べたように、以前は何日もかかっていたものが、今では 2~3 時間でコンピューティングできるようになりました。なので、このプロジェクトに必要なものは以下だけです。
⏱️ 2 時間確保する(各ステップの [実行] をクリックすると、最も長い部分はバックグラウンドで実行されます。あとは 2 時間後にもう一度確認して、次の最後のステップに進むだけです)
? 無料のGoogle Cloud プロジェクトを作成する(オンライン モデルでは時間単位でコストが発生するため、追加コストが発生しないように、終了後はそのプロジェクトを削除します)
(オプション情報: *料金の内訳)
このサンプルをご自身の Cloud プロジェクトで実行した場合の総コストは $27.61 未満となります(実行毎に若干異なります。料金は本記事の掲載日を基準としており、変動する可能性があります)。
Cloud Storage は無料枠(10 GB 未満)です。Cloud IoT Core は含まれていません。また、クラウド サーバーをエンドポイントにして常に(1 時間あたりの料金で)リッスンし、デバイスがいつでもオンラインで通信できるようにする必要がある場合も含まれません。このオプションは、マイクロコントローラを使用しない場合です。予測型のウェブサービスです。
画像データベースの作成(約 5 分): $0.07
AutoML モデルのトレーニング(約 1 時間): $26.302431355
Dataflow: $1.10
AutoML のトレーニング: $25.20
vCPU の合計: 13.308 vCPU 時間 × $0.056/vCPU 時間 = $0.745248
総メモリ量: 49.907 GB 時間 × $0.003557/GB 時間 = $0.177519199
HDD PD の合計: 3,327.114 GB 時間 × $0.000054/GB 時間 = $0.179664156
シャッフル データ処理: 不明だが、おそらく無視できるレベル
AutoML のトレーニング: $25.20
トレーニング: 8 ノード時間 × $3.15/ノード時間 = $25.20
予測の取得(モデルのデプロイ時間を 1 時間と想定し、それ以上の請求を停止するにはモデルのデプロイを解除する必要があります): $1.25
AutoML 予測: $1.25
デプロイ: $1.25/時間 × 1 時間 = $1.25
-Cloud デベロッパー アドボケイト Alexandrina Garcia-Verdin