Workflows と Gemini モデルによる長いドキュメントの要約
Google Cloud Japan Team
※この投稿は米国時間 2024 年 5 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
生成 AI は、開発者とビジネス関係者の双方にとって最重要課題です。そのため、Google Cloud のサーバーレス実行エンジンである Workflows のようなプロダクトが、大規模言語モデル(LLM)のユースケースをどのように自動化し、オーケストレートするかについて確かめるのは重要なことです。先ごろ私たちは、Workflows で Vertex AI の PaLM と Gemini API をオーケストレートする方法をご紹介しました。このブログでは、幅広く適用できる具体的なユースケースとして、Workflows で長いドキュメントの要約を実行する方法について説明します。
Python や TypeScript 開発者向けの LangChain、または Java 開発者向けの LangChain4j といったオープンソースの LLM オーケストレーション フレームワークは、LLM、ドキュメント ローダ、ベクトル データベースのようなさまざまなコンポーネントを統合して、ドキュメントの要約などの複雑なタスクを実行します。LLM オーケストレーション フレームワークに多大な時間を費やすことなく、Workflows を使用してこうしたタスクを実行することもできます。
要約の手法
短いドキュメントは、ドキュメントの内容全体をプロンプトとして LLM のコンテキスト ウィンドウに入力することで簡単に要約できます。しかし、LLM のプロンプトに入力できるトークン数には通常制限があるため、長いドキュメントには別のアプローチが必要となります。一般的なアプローチは、次の 2 つです。
-
Map / Reduce - 長いドキュメントをコンテキスト ウィンドウに収まる小さなセクションに分割します。各セクションごとに要約が作成され、最終ステップで要約をすべてまとめた要約が作成されます。
-
反復的な改良 - Map / Reduce のアプローチと同様に、ドキュメントを段階的に評価します。最初のセクションの要約が作成されると、LLM は次のセクションの詳細を使用して最初の要約を改良し、ドキュメントの最後までこれを繰り返します。
どちらの手法でも良い結果が得られます。ただし、Map / Reduce アプローチには、反復的な改良よりも有利な点が 1 つあります。反復的な改良では、ドキュメントの次のセクションは、以前に改良された要約を使用して要約されるため、逐次的なプロセスとなってしまうのです。
Map / Reduce では、下図に示すように、各セクションの要約を同時に作成し(「map」オペレーション)、最終ステップで最後の要約を行う(「reduce」オペレーション)ことができます。そのため、逐次的なアプローチよりも高速です。
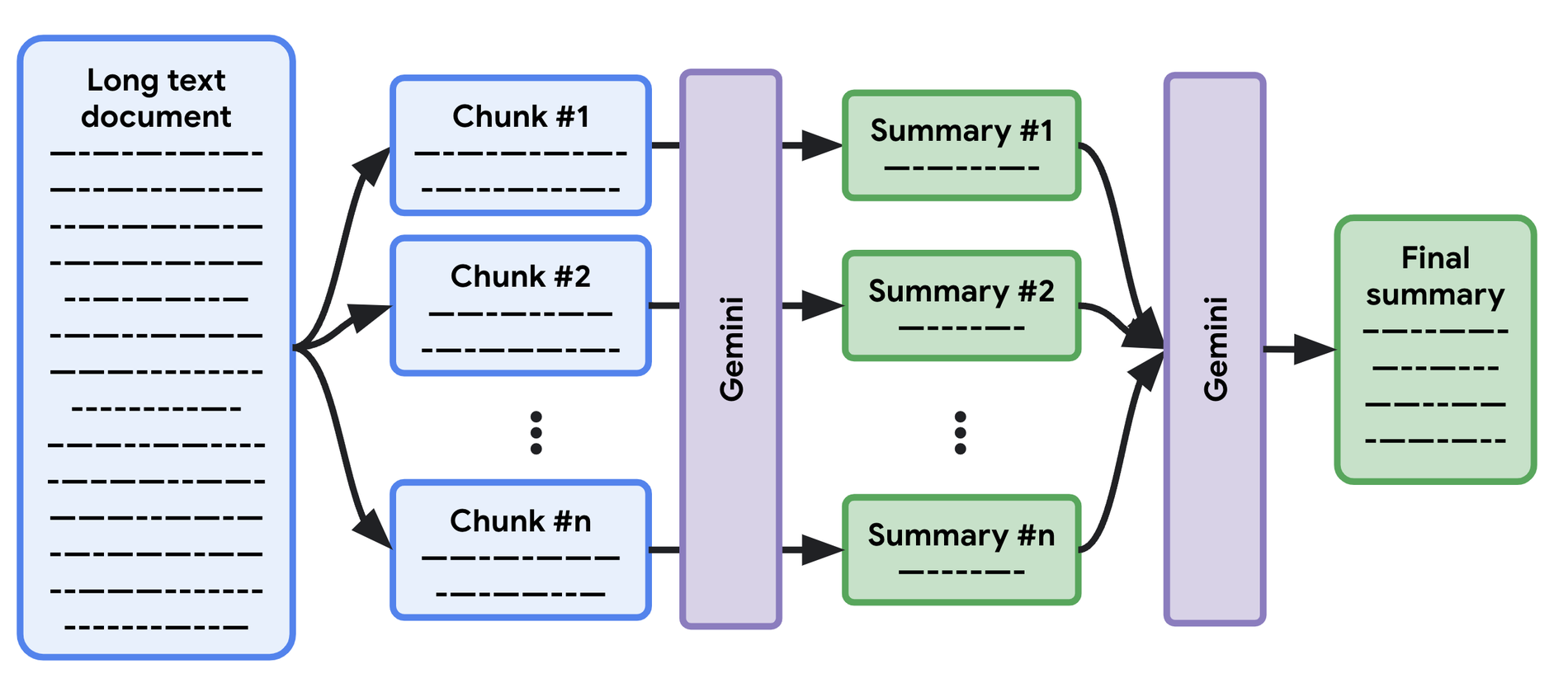
Workflows と Gemini モデルによる長いドキュメントの要約
以前のブログ記事で、Workflows 経由で PaLM と Gemini モデルを呼び出す方法をご紹介するとともに、Workflows の重要な機能である並列ステップの実行について取り上げました。この機能を使用すると、長いドキュメントのセクションの要約を同時に作成できます。
ワークフロー定義の全体像は次のとおりです。
-
新しいテキスト ドキュメントが Cloud Storage バケットに追加されると、ワークフローがトリガーされます。
-
そのテキスト ファイルは、「チャンク」に分割され、並列ステップで要約されます。
-
最後の要約ステップで、すべての小さな要約をグループ化し、それらを 1 つの要約にまとめます。
-
サブワークフローにより、Gemini 1.0 Pro モデルのすべての呼び出しが行われます。
では、実際に見てみましょう。
テキスト ファイルの取得とセクション要約の同時実行(「map」部分)
assign_file_vars ステップでは、定数とデータ構造をいくつか準備します。この例では、チャンクサイズとして 64,000 文字を選択し、LLM のコンテキスト ウィンドウに収まり、かつ Workflows のメモリ制限内にとどまるようにしています。また、要約のリストのための変数と、最終的な要約を保持するための変数もあります。
loop_over_chunks ステップでは、まず dump_file_content サブステップで Cloud Storage からドキュメントの各部分を読み込んで、テキストの各チャンクを同時に抽出します。次に、generate_chunk_summary で Gemini モデルを利用したサブワークフローを呼び出し、ドキュメントのそのセクションを要約します。最後に、現在の要約を summaries 配列に保存します。
複数の要約をまとめた要約(「reduce」部分)
すべてのチャンクの要約が揃ったので、そのすべての小さな要約を集約した要約、または要約の最終的な要約にまとめることができます。
concat_summaries では、すべてのチャンクの要約を連結します。reduce_summary ステップでは、Gemini モデルの要約サブワークフローを最後にもう一度呼び出して、最終的な要約を取得します。そして、return_result で、チャンクの要約と、最終的な要約を含む結果を返します。
Gemini モデルに要約を求める
「map」ステップと「reduce」ステップはどちらも、Gemini モデルで呼び出しをカプセル化するサブワークフローを呼び出します。ワークフローの最後の部分を詳しく見てみましょう。
init では、使用する LLM(この例では Gemini Pro)の設定のために、変数をいくつか準備します。
call_gemini ステップでは、モデルの REST API に対して HTTP POST 呼び出しを行います。OAuth2 認証スキームを指定するだけで、この API を宣言的に認証できる点に注目してください。本文では、要約を求めるプロンプトと、温度や生成される要約の最大長などのモデル パラメータをいくつか渡します。
最後に、サブワークフローの最終ステップで、呼び出したステップに要約を返します。
結果として得られた要約
Jane Austen の「Pride and Prejudice」のテキストを Cloud Storage バケットに保存すると、ワークフローがトリガーされて実行され、次のような部分的な要約と、最終的な要約が得られます。

さらに詳しく見てみましょう
このブログ記事の目的上、ワークフローはシンプルにしましたが、さまざまな方法でさらに改善することが可能です。たとえば、要約する各セクションの文字数をハードコードしましたが、これをワークフローのパラメータにすることも、モデルのコンテキスト ウィンドウの制限の長さに応じて計算することもできます。
Workflows 自体にも、メモリ内に保持する変数やデータのメモリ制限があるため、ドキュメントのセクションの要約が非常に長く、リストがメモリに収まりきれないような場合にも対応できます。そして、忘れてはならないのが Google の新しい大規模言語モデル、Gemini 1.5 です。Gemini 1.5は、最大 100 万トークンの入力が可能で、単一パスで長いドキュメントを要約できます。
もちろん、LLM オーケストレーション フレームワークを使用することもできますが、この例が示すように、Workflows 自体が有用な LLM オーケストレーションのユースケースを扱うことができます。
まとめ
このブログ記事では、Workflows を使用して LLM をオーケストレートするための新しいユースケースを探索し、専用の LLM フレームワークを使用せずに長いドキュメントの要約を実施しました。Workflows の並列ステップ機能を活用し、セクションの要約を同時に作成することで、要約全体の作成にかかるレイテンシを削減しました。
Workflows サンプル リポジトリにある、こちらのサンプルの要約ワークフローをぜひご確認ください。また、Workflows のドキュメントでは Vertex AI モデルへのアクセス方法をご覧いただけます。ご質問やフィードバックがある場合は、@glaforge までお気軽にご連絡ください。
-Cloud デベロッパー アドボケイト Guillaume Laforge
-Workflows チームリーダー Randy Spruyt



