Workflows で Vertex AI の PaLM と Gemini API をオーケストレートする
Google Cloud Japan Team
※この投稿は米国時間 2024 年 2 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
最近では誰もが生成 AI に心を躍らせていますが、それは当然のことといえます。PaLM 2 や Gemini Pro でテキストを生成したり、ImageGen 2 で画像を生成したり、Codey でコードを別の言語に翻訳したり、Gemini Pro Vision で画像や動画の説明を生成したりしている方もいらっしゃることでしょう。
このように、生成 AI の使用目的はさまざまですが、ユーザーが SDK またはライブラリを使用して、あるいは REST API を介して、エンドポイントを呼び出しているという点は共通しています。Workflows は他のサービスをオーケストレートして自動化するうえで頼りになるサービスですが、その生成 AI との適合性はかつてないほど高まっています。
この投稿では、Workflows で数種類の生成 AI モデルを呼び出す方法をご紹介するとともに、生成 AI のコンテキストにおいて Workflows を活用するメリットについても説明します。
複数の国の歴史に関するテキストを生成する
まず、簡単なユースケースから始めましょう。大規模言語モデル(LLM)で複数の国の歴史に関する 1 つまたは 2 つの段落を生成し、それらを結合していくつかのテキストにするとします。
これを行うにはまず、国の詳細リストを LLM に送信し、各国の歴史を回答するよう要求する方法が考えられます。うまくいく場合もありますが、LLM の回答にはサイズ制限があるため、制限のため回答が返らない国が数多く生じる可能性があります。
もう一つのやり方として、各国の歴史を 1 つずつ生成して結果を取得し、そこから各結果を結合するように LLM に要求する方法もあります。回答のサイズ制限を回避できる可能性はありますが、LLM が各国の歴史を順番に生成するのにかなりの時間を要するという別の問題が発生します。
Workflows は、より優れた第 3 の手段を提供します。Workflows の並列ステップを使用すれば、LLM に各国の歴史を並行して生成するように要求できます。これにより、回答のサイズにまつわる問題を回避できる上、LLM に対するすべての呼び出しが並行して行われるため、順番に呼び出すことによる問題も回避できます。
Workflows で Vertex AI PaLM 2 for Text を並行して呼び出す
次に、Workflows を使用してこのユースケースを実行する方法を見てみましょう。ここでは、Vertex AI の PaLM 2 for Text(text-bison)をモデルとして使用します。
Workflows で使用する Vertex AI REST API や、PaLM 2 for Text のドキュメントのほか、text-bison モデルでテキストを生成するために使用する predict メソッドについてよく理解しておく必要があります。
時間の節約のために、詳細なワークフロー(country-histories.yaml)を以下に記載します。
引数として指定された国のリストをループで処理し、各国の text-bison モデルを使用して Vertex AI REST API を並列ステップで呼び出し、結果をマップに結合している点に注目してください。これは、LLM に対する Map-Reduce スタイルの呼び出しです。
ワークフローをデプロイします。
いくつかの国でワークフローを実行します。
LLM 呼び出しを終えるのと同時か、それに近い速さで結果を取得できます。呼び出しをそれぞれ順番に行うよりもはるかに高速です。数秒で、国とその歴史を含む出力マップが表示されます。
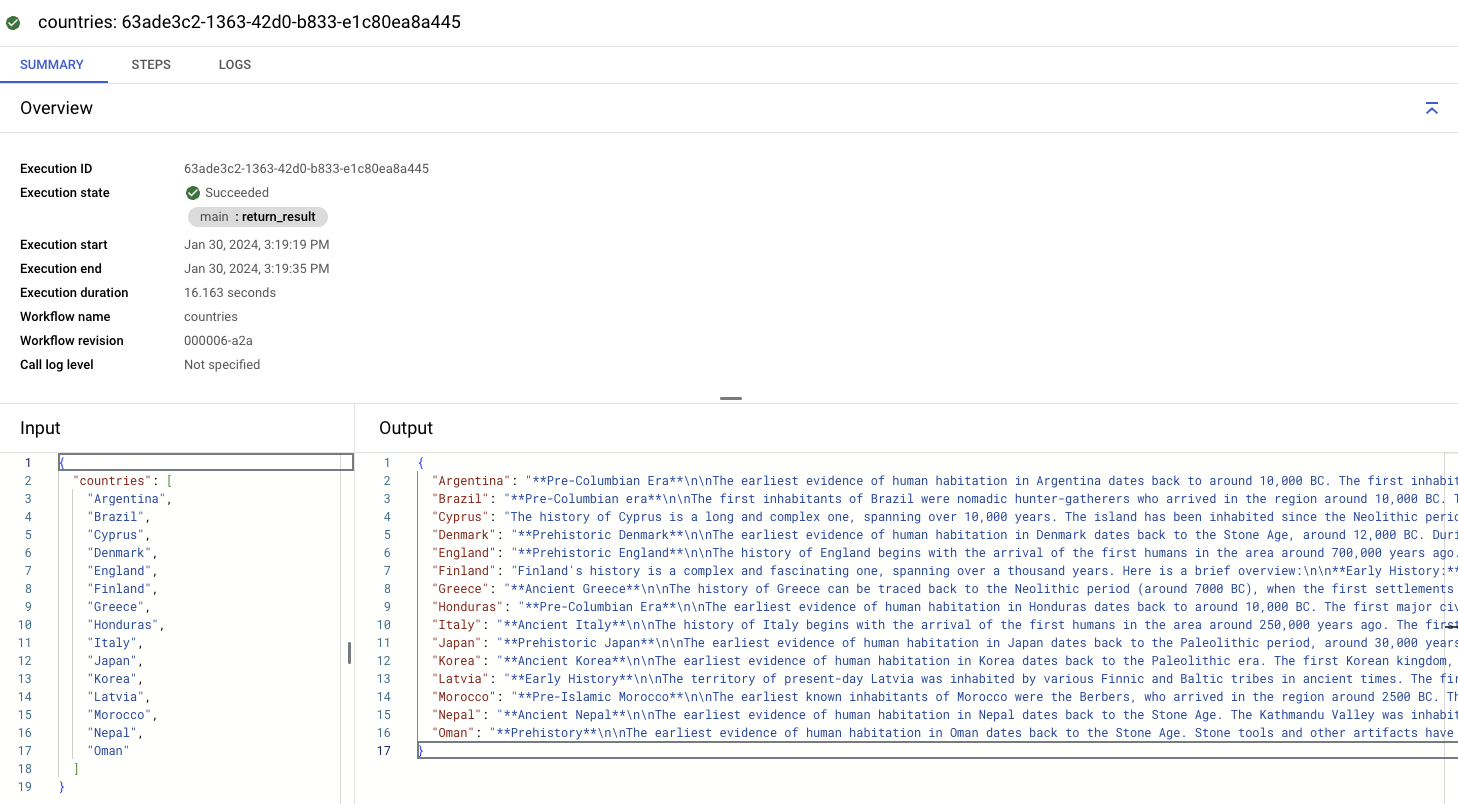
詳細なサンプルは、こちらの GitHub リポジトリにあります。
Workflows で Vertex AI Gemini Pro を並行して呼び出す
使用できる最新かつ最高のモデルは Gemini ではないかと疑問に思った方もいらっしゃるかもしれません。そのとおり、上記のサンプルに少し修正を加えれば、Workflows で Vertex AI Gemini Pro を呼び出すことももちろん可能です。
Gemini の場合は、gemini-pro モデルでテキストを生成するために使用する Gemini API と streamGenerateContent メソッドについてよく理解しておく必要があります。
ここでも時間を節約できるように、country-histories.yaml で Gemini API を使用する詳細なワークフローを記載します。上記のサンプルとの違いをいくつかご紹介しておきましょう。
まず、gemini-pro モデルと streamGenerateContent メソッドを使用します。
次に、Gemini にはストリーミング エンドポイントがあります。つまり、回答はチャンクで受信され、テキスト全文を取得するには各チャンクのテキストを結合する必要があります。次の手順で各チャンクからテキストを抽出し、結合します。
詳細なサンプルは、こちらの GitHub リポジトリにあります。
Workflows で VertexAI Gemini Pro Vision を呼び出して画像の説明を生成する
Gemini の真価は、そのマルチモーダルな性質にあります。つまり、テキスト、コード、音声、画像、動画などのさまざまな種類の情報を一般化して理解し、操作できることです。
ここまではテキストを生成してきましたが、Workflows で Gemini のマルチモーダルな性質を活用することはできるのでしょうか。もちろんできます。たとえば、Workflows を使用すれば、Gemini から以下のような画像の説明を取得できます。

以下のサンプル(describe-image.yaml)では、ワークフローが Gemini Pro Vision に対して Google Cloud Storage バケット内の画像の説明を生成するように要求しています。
ワークフローを実行します。
出力は次のようになります。
いい感じですね。詳細なサンプルは、こちらの GitHub リポジトリにあります。演習として、上記のサンプルを応用して多数の画像の説明を並行して生成し、結果を txt ファイルとして Cloud Storage バケットに保存することもできます。
まとめ
クライアント ライブラリ、生成されたライブラリ、REST API、LangChain を使用するなど、LLM を呼び出す方法は数多くあります。この投稿では、Workflows で何種類かの生成 AI モデルを呼び出す方法をご紹介しました。Workflows は並列ステップと再試行ステップを備えているため、生成 AI モデルを呼び出す堅牢な方法となります。また、Eventarc と統合することにより、イベント ドリブンな LLM アプリケーションを実現することもできます。
詳細については、ワークフローから Vertex AI モデルにアクセスする方法に関するドキュメント ページをご覧ください。ご不明な点やフィードバックがございましたら、Twitter の @meteatamel までお気軽にご連絡ください。
ー デベロッパー アドボケイト Mete Atamel


