Model Armor がプロンプト インジェクションやジェイルブレイクから AI アプリを保護する仕組み

Pallavi Vageria
Senior Strategic Cloud Engineer, Google Cloud
※この投稿は米国時間 2025 年 10 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
AI の急速な発展が続く中、IT チームは、プロンプト インジェクションとジェイルブレイクという 2 つの一般的な脅威によってもたらされるビジネスと組織のリスクに対処することが重要です。
今年初めに、Google はモデルに依存しない高度なスクリーニング ソリューションである Model Armor を導入 しました。これは、生成 AI のプロンプトやレスポンス、またエージェントのインタラクションを保護するのに役立ちます。Model Armor は、開発者向けの直接 API 統合、Apigee、Vertex AI、Agentspace、ネットワーク サービス拡張機能とのインライン統合など、包括的な統合オプション スイートを提供します。
多くの組織はすでに Apigee を API ゲートウェイとして利用しており、トラフィックとセキュリティの管理に Spike Arrest、Quota、OAuth 2.0 などの機能を使用しています。Model Armor と統合することで、Apigee は 生成 AI のインタラクションの重要なセキュリティ レイヤになります。
この強力な組み合わせにより、プロンプトやレスポンスを事前にスクリーニングできるため、AI アプリケーションが安全性・コンプライアンスを確保し、定められたガードレールの範囲内で動作するようにします。今回は、Apigee で Model Armor を使用して AI アプリを保護する方法について説明します。
AI アプリケーションの保護に Model Armor を使用する方法
Model Armor には、主に 5 つの機能があります。
-
プロンプト インジェクションとジェイルブレイクの検出: LLM が指示や安全フィルタを無視するように操作しようとする試みを特定してブロックします。
-
機密データの保護: ユーザーのプロンプトと LLM の回答の両方で、個人情報(PII)や機密データなどの機密情報を検出、分類し、漏洩を防ぐことができます。
-
悪意のある URL の検出: 入力と出力の両方で悪意のあるリンクやフィッシング リンクをスキャンし、ユーザーが有害なウェブサイトに誘導されるのを防ぎ、LLM が誤って危険なリンクを生成するのを阻止します。
-
有害コンテンツのフィルタリング: 露骨な性的描写を含むコンテンツ、危険なコンテンツ、ハラスメントやヘイトスピーチを含むコンテンツを検出するフィルタが組み込まれており、出力が責任ある AI の原則に沿ったものになるようにします。
- ドキュメントのスクリーニング: PDF や Microsoft Office ファイルなどのドキュメント内のテキストをスクリーニングして、悪意のあるコンテンツや機密性の高いコンテンツを検出することもできます。

Apigee と LLM を使用した Model Armor の統合。
Model Armor はモデル非依存かつクラウド非依存に設計されています。つまりGoogle Cloud上で動作しているか、他のクラウド プロバイダや別のプラットフォーム上で動作しているかに関わらず、REST API を通じてあらゆる生成 AI モデルを保護できるということです。これらの機能を実行するために、REST エンドポイントまたは他の Google AI サービスやネットワーキング サービスとのインライン統合を公開します。
ご利用方法
-
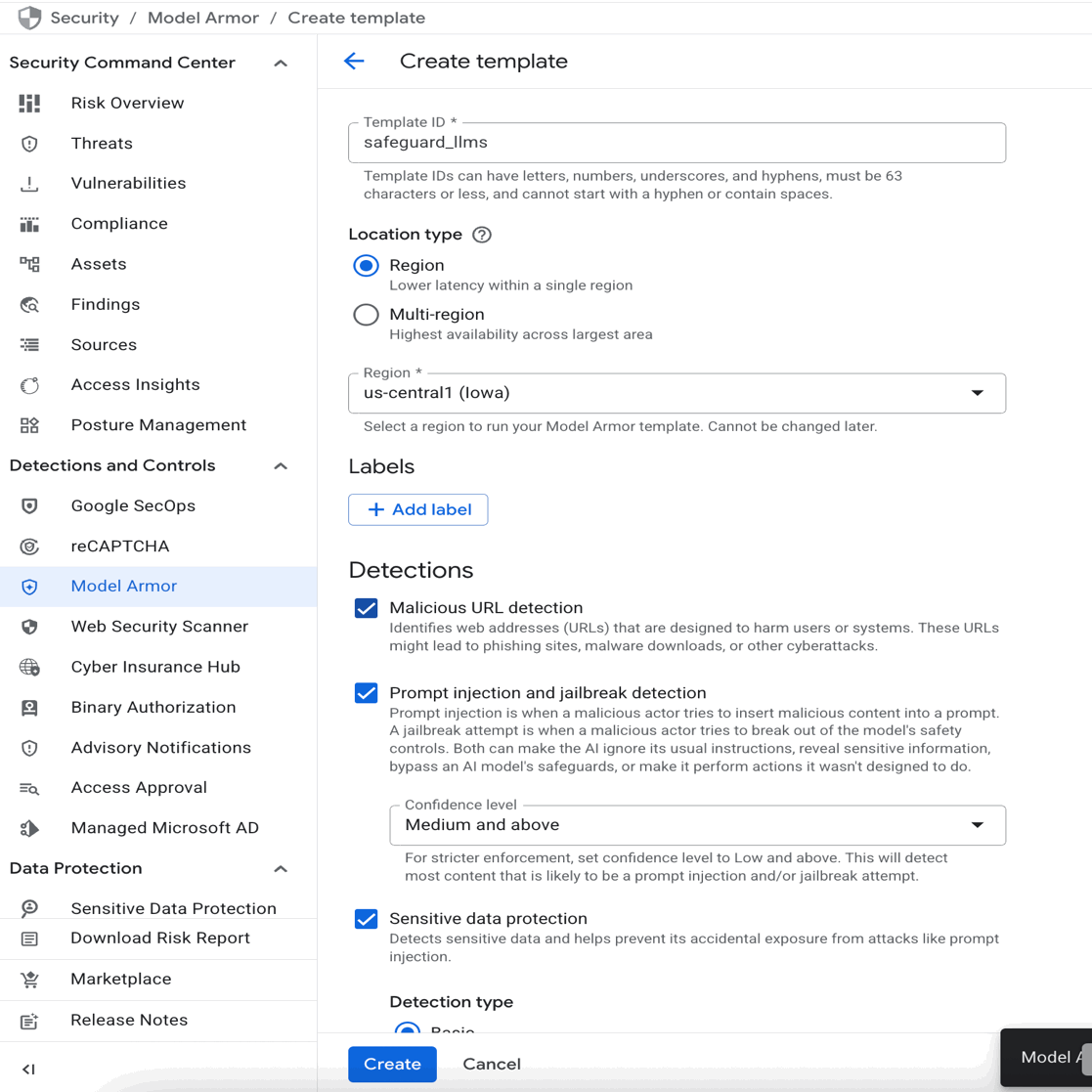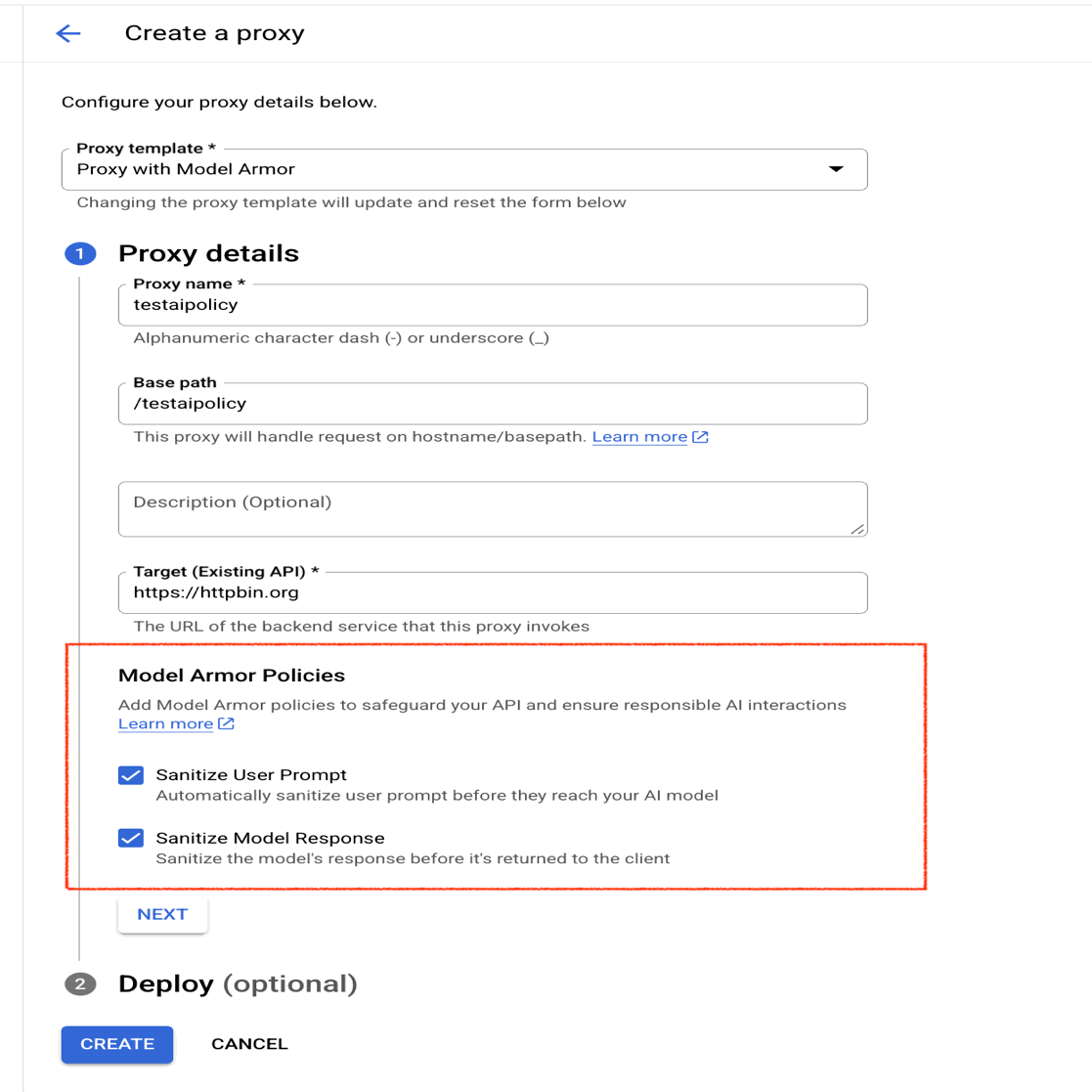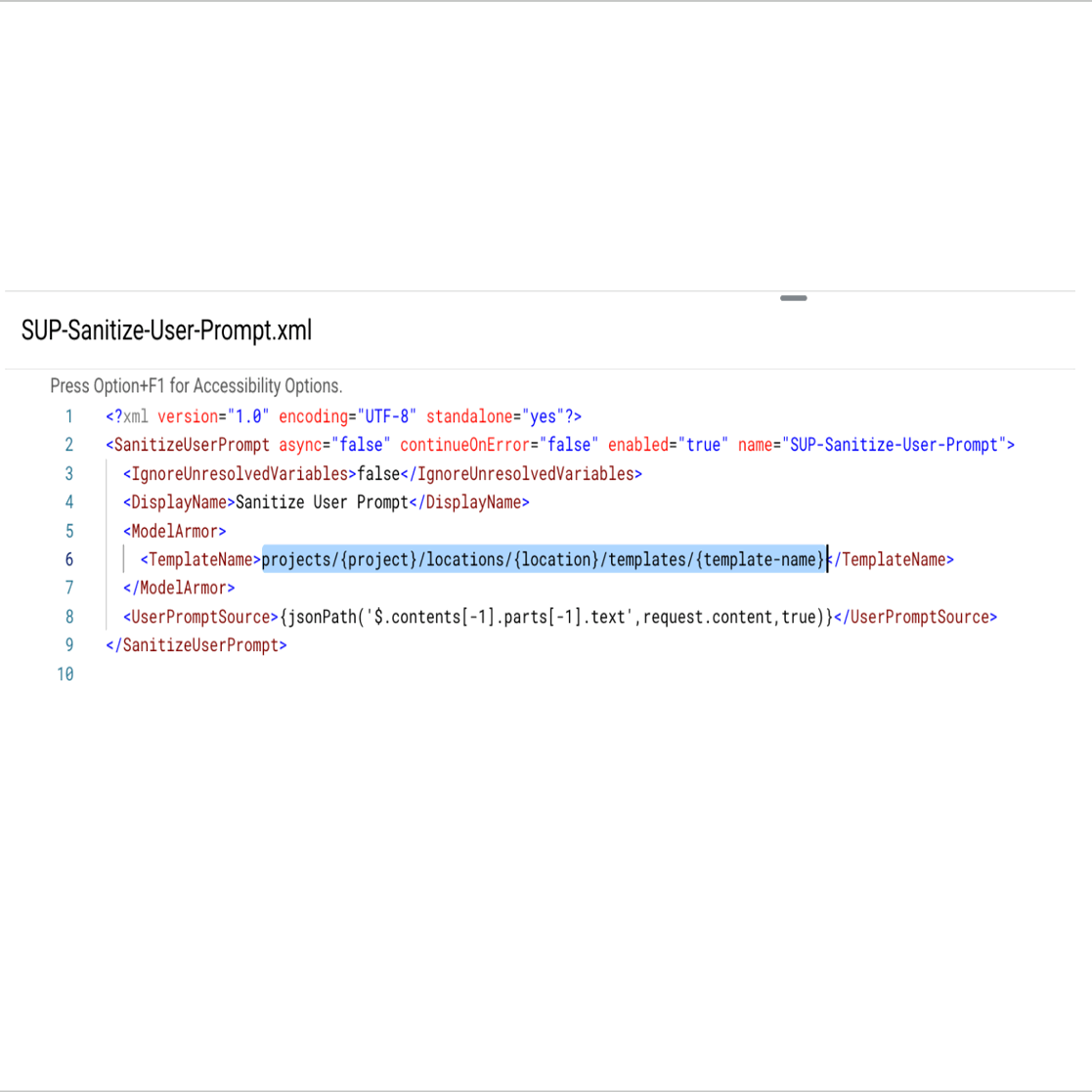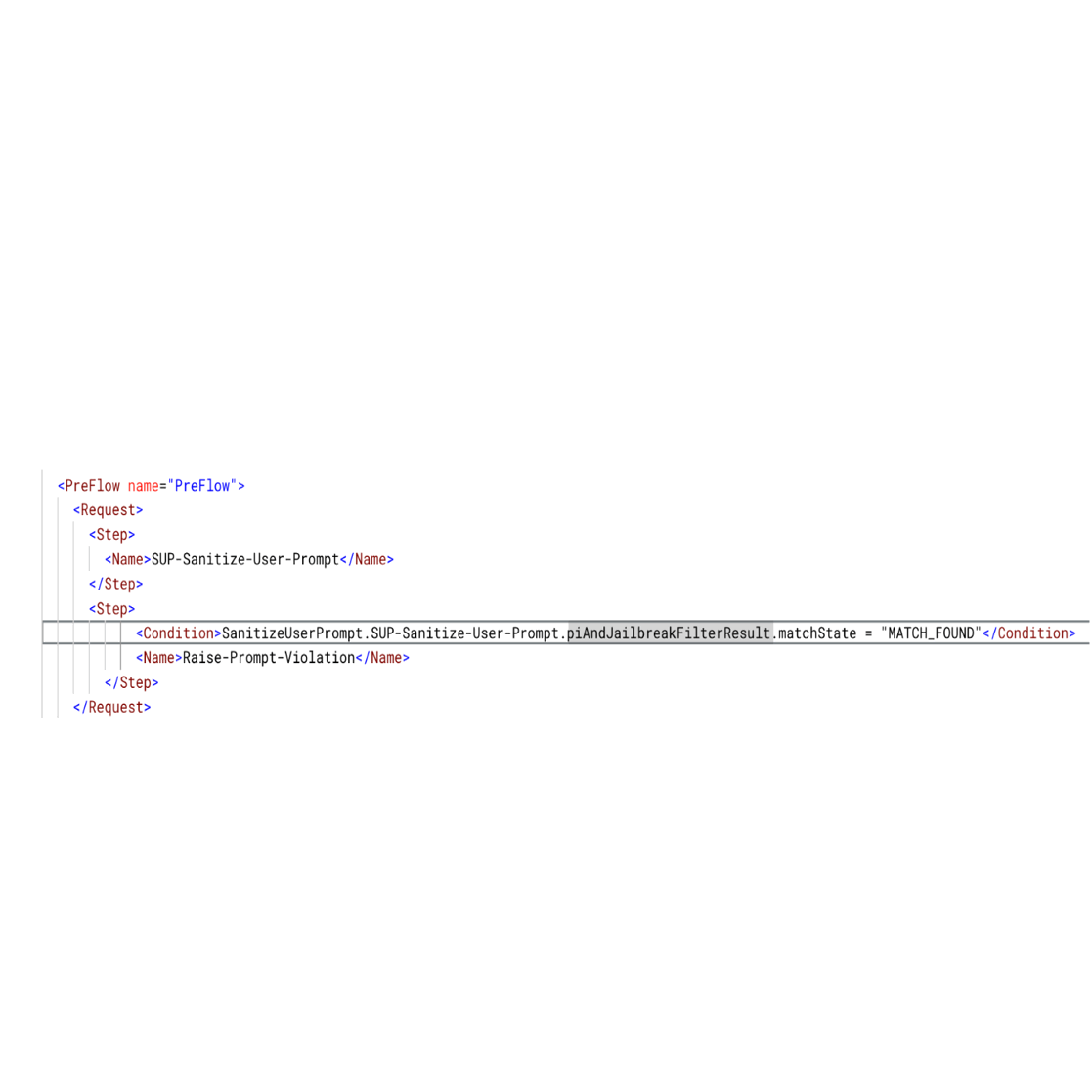
Google Cloud コンソールで Model Armor API を有効にし、[テンプレートを作成] をクリックします。
-
プロンプト インジェクションとジェイルブレイクの検出を有効にします。また、上記のように他の安全フィルタを有効にして、[作成] をクリックすることもできます。
-
サービス アカウントを作成(または Apigee プロキシのデプロイに使用された既存のサービス アカウントを更新)し、サービス アカウントで Model Armor ユーザー(roles/modelarmor.user)と Model Armor 閲覧者 (roles/modelarmor.viewer)の権限を有効にします。
-
Apigee コンソールから新しいプロキシを作成し、Model Armor ポリシーを有効にします。
-
LLM 呼び出し用のプロキシがすでに存在する場合は、フローに 2 つの Apigee ポリシー(SanitizeUserPrompt と SanitizeModelResponse)を追加します。
-
ポリシーの詳細で、先ほど作成した Model Armor テンプレートへの参照を更新します。たとえば、projects/some-test-project/locations/us-central-1/templates/safeguard_llms などです。同様に、<SanitizeModelResponse> ポリシーを構成します。
-
リクエスト ペイロードでユーザー プロンプトのソースを指定します(例: JSON パス)。
-
LLM エンドポイントを Apigee プロキシのターゲット バックエンドとして構成し、上記で構成したサービス アカウントを使用してプロキシをデプロイします。プロキシが動作し、Model Armor と LLM のエンドポイントとやり取りをしています。
-
プロキシの実行中、Apigee がモデル アーマーを呼び出すと、「フィルタ実行状態」と「一致状態」を含むレスポンスが返されます。Apigee は、SanitizeUserPrompt.POLICY_NAME.piAndJailbreakFilterResult.executionState や SanitizeUserPrompt.POLICY_NAME.piAndJailbreakFilterResult.matchState などのモデル アーマーのレスポンスからの情報で、いくつかのフロー変数を設定します。
-
<Condition> を使用して、このフロー変数が MATCH_FOUND と等しいかどうかを確認し、プロキシのフロー内で <RaiseFault> ポリシーを構成できます。
Model Armor を構成し、Apigee と統合して AI アプリケーションを保護する手順。
調査結果を確認する
Model Armor の検出結果は、Security Command Center の AI 保護ダッシュボードで確認できます。グラフには、Model Armor によって分析されたプロンプトとレスポンスの量と、特定された問題の数が表示されます。
また、プロンプト インジェクション、脱獄検知、機密データの特定など、検出されたさまざまな問題の種類を要約します。

AI 保護ダッシュボードで提供されるプロンプトとレスポンスのコンテンツ分析。

Model Armor のフロア設定では、フィルタリングの信頼度レベルを定義します。
Model Armor のロギングでは、テンプレートの作成や更新などの管理アクティビティと、プロンプトやレスポンスに対するサニタイズ オペレーションが記録され、Cloud Logging で確認できます。Model Armor テンプレート内でロギングを構成して、プロンプト、レスポンス、評価結果などの詳細を含めることができます。
実際に使って詳細を確認
Apigee と Model Armor の統合に関するチュートリアルはこちらでご覧いただけます。Model Armor の構成に関するガイド付きラボもお試しください。
ー Pallavi Vageria、Google Cloud、シニア戦略クラウド シニア エンジニア



