Recovering global wildlife populations using ML

Alexandrina Garcia-Verdin
Geo for Environment Developer Advocate
Wildlife provides critical benefits to support nature and people. Unfortunately, wildlife is slowly but surely disappearing from our planet and we lack reliable and up-to-date information to understand and prevent this loss. By harnessing the power of technology and science, we can unite millions of photos from [motion sensored cameras] around the world and reveal how wildlife is faring, in near real-time...and make better decisions
wildlifeinsights.org/about

Case study background
Google partnered with several leading conservation organizations to build a project known as Wildlife Insights, which is a web app that enables people to upload, manage, and identify images of wildlife from camera traps. The intention is for anyone in the world who wishes to protect wildlife populations and take inventory of their health, to do so in a non-invasive way.
The tricky part, however, is reviewing each of the millions of photos and identifying every species, and so this is where Machine Learning is of great help with this big data problem. The models built by the inter-organizational collaboration, presently classifies up to 732 species and includes region-based logic such as preventing a camera trap in Asia—for example—from classifying an African elephant (using geo-fencing). These models have been in development for several years, and are continuously being evolved to serve animals all over the globe. You can learn more about it here.
This worldwide collaboration took a lot of work, but much of the basic technology used is available to you at WildlifeLifeInsights.org!
And, for those interested in wanting to learn how to build a basic image classifier inspired from this wildlife project, please continue reading. You can also go deeper by trying out our sample tutorial at the end, which contains the code we used, and lets you run it interactively in a step-by-step notebook (you can click the “play” icon at each step to run each process).
How to build an image classification model to protect wildlife
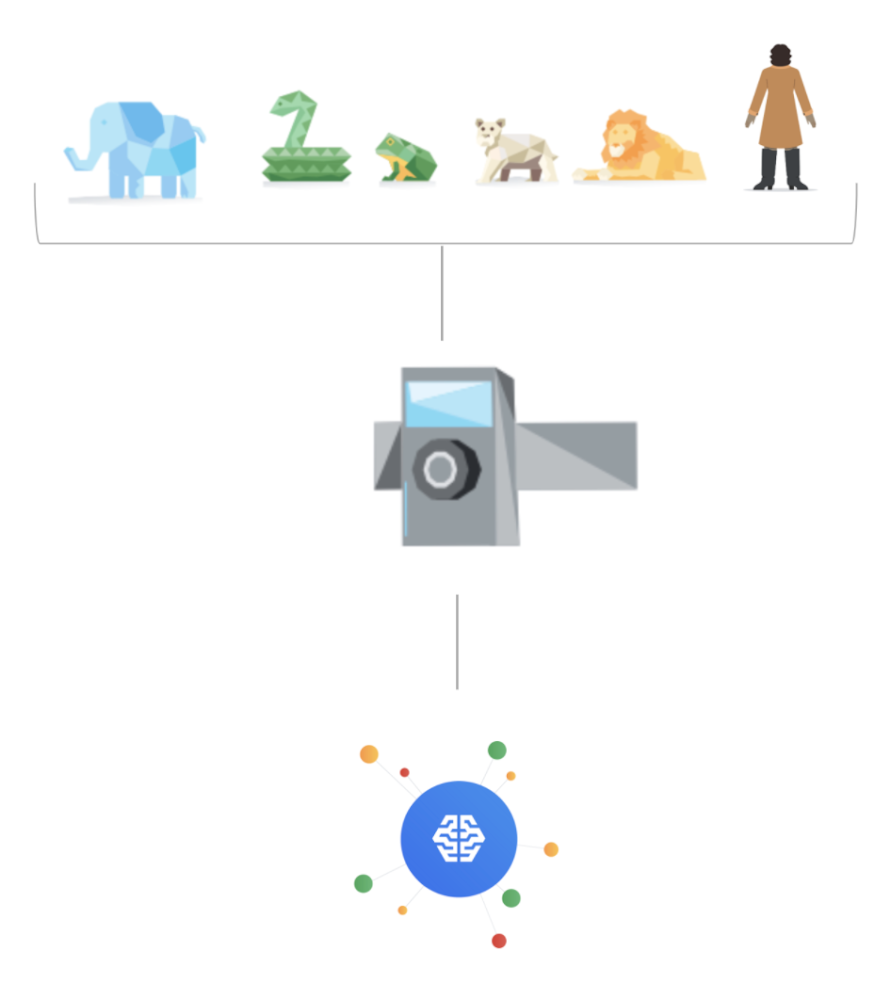
We're launching a Google Cloud series called “People and Planet AI” to empower users to build amazing apps that can help solve complex social and environmental challenges inspired from real case studies such as the project above. In this first episode, we show you how to use Google Cloud’s Big Data & ML capabilities to automatically classify images of animals from camera traps. You can check out the video here.
Requirements to get started
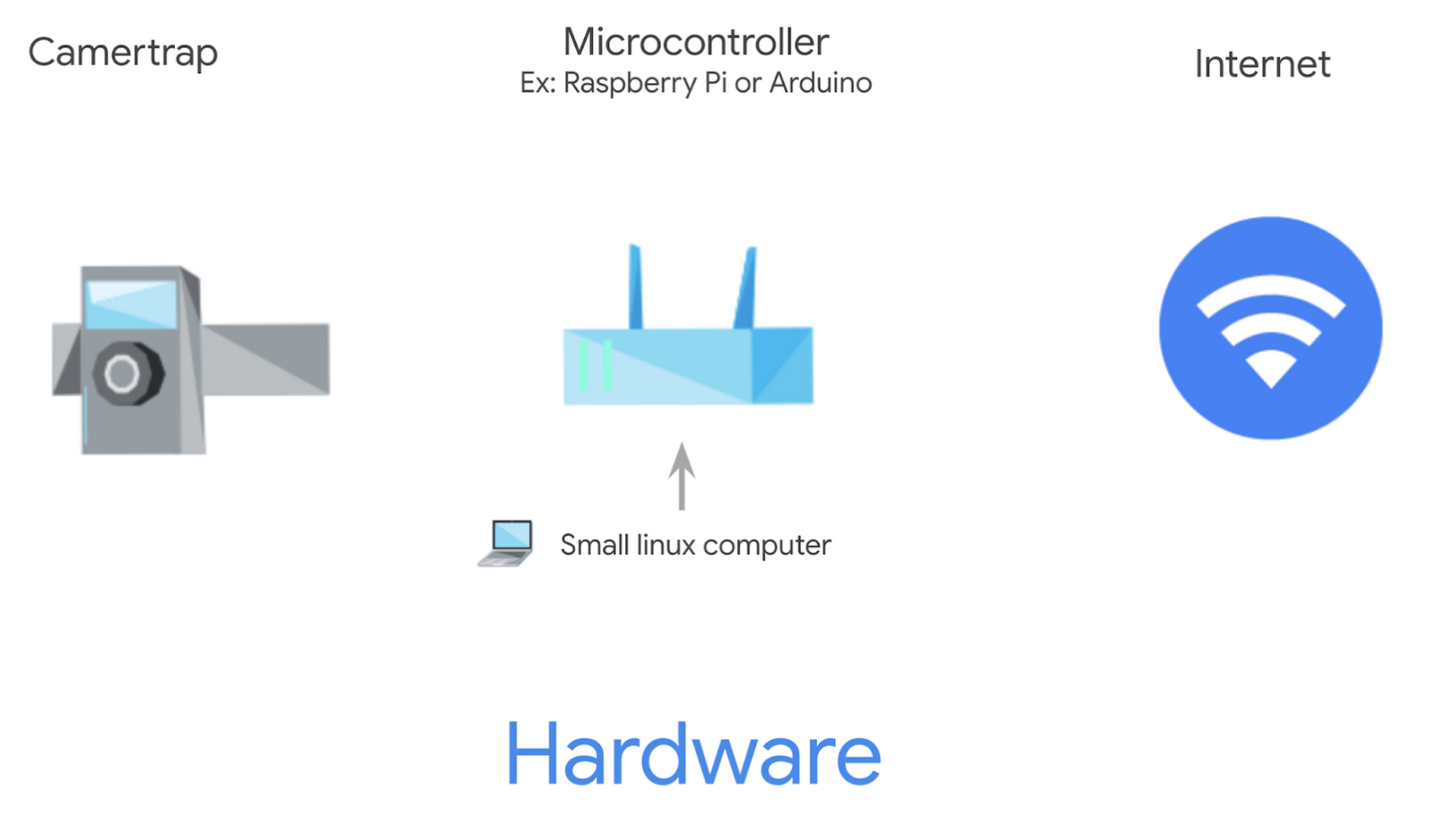
Hardware
You would require two hardware components:
Camera trap(s) → to take photos (which we also strongly recommend you share by uploading on Wildlife Insights to help build a global observation network of wildlife).
Micro controller(s) (like a Raspberry Pi or Arduino) → to serve as a small linux computer for each camera. It hosts the ML model locally and does the heavy lifting of labeling images by species as well as omitting blank images that aren’t helpful.
With these two tools, the goal is to have the labeled images then uploaded via an internet connection. This can be done over a cellular network. However, in remote areas you can carry the microcontroller to a wifi enabled area periodically to do the transfer.
? 2 Friendly tips:
? In order for the microcontroller to send the images it’s classified over the internet, we recommend using Cloud PubSub which publishes the images as messages to an endpoint in your cloud infrastructure. PubSub helps send and receive messages between independent applications over the internet.
? when managing dozens or hundreds of camera traps and their micro controllers, you can leverage Cloud IoT core to upload your ML classification model on all these devices simultaneously—especially as you update the model with new data from the field.
Software
The model is trained and output via Google Cloud using a free camera trap dataset from lila.science. It costs less than $30 each time to train the model as of the publishing of this article (the granular breakdown is listed at the bottom of this article).
? TIP: you can retrain once or twice a year, depending on how many images of new species you collect, and/or how frequently you want to upgrade the image classification model.
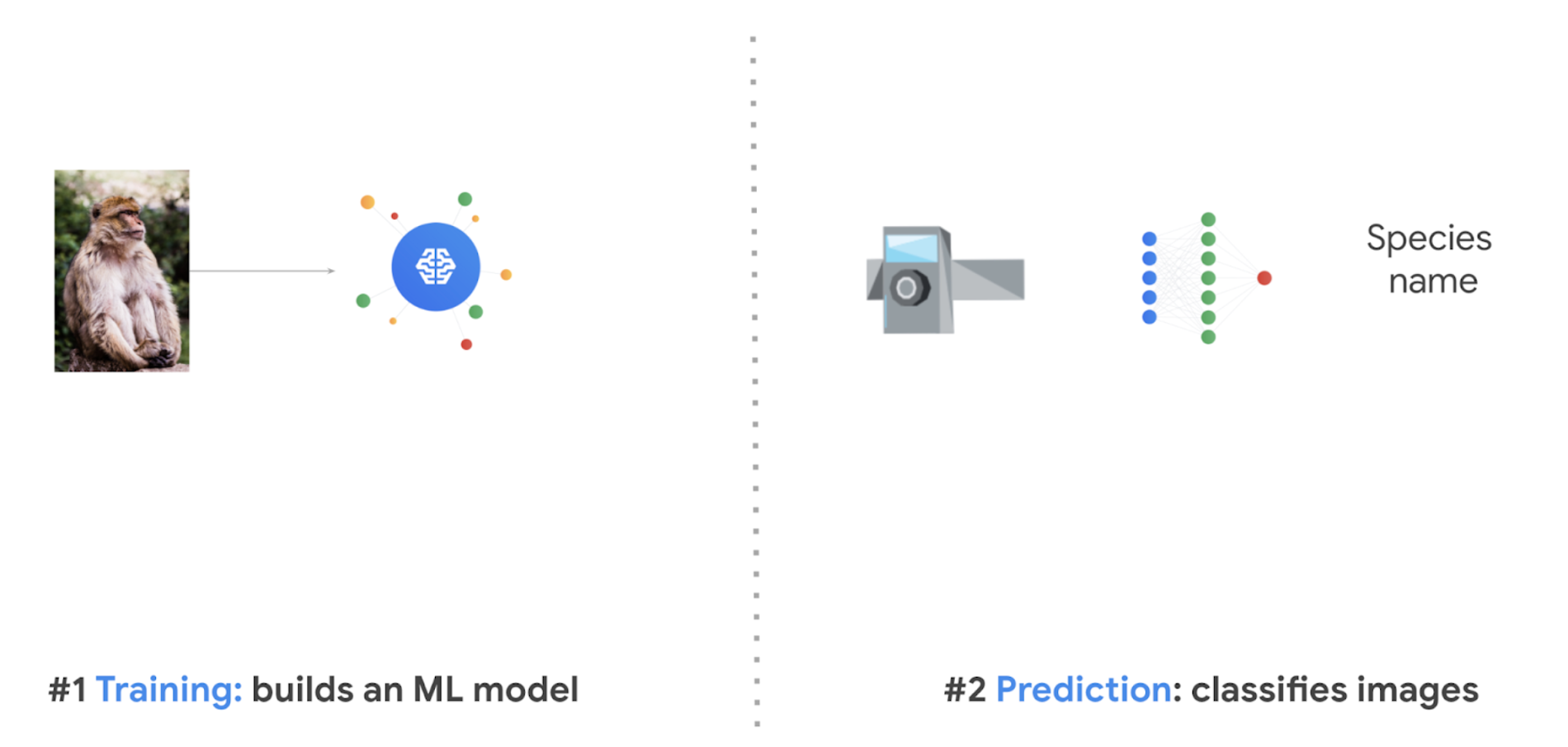
Image selection for training and validation of an ML model
The two products that perform most of the heavy lifting are Dataflow and AI Platform Unified. Dataflow, is a serverless data processing service that can process very large amounts of data needed for Machine Learning activities. In this scenario we use it to run 2 jobs:
Dataflow job 1: creates a database in BigQuery from image metadata. The 2 columns of the metadata collected are used from the Camera Traps database mentioned above. This is a one time setup:
category: The species we want to predict, this is our label.file_name: The path where the image file is located.
We will also do some very basic data cleaning like discarding rows with categories that are note useful like: #ref!, empty, unidentifiable, unidentified, unknown.
Dataflow job 2: makes a list of images that would be great for creating a balanced dataset. This is informed by our requirements for selecting images that have a minimum and maximum amount of species per category.

This is to ensure we train a bias-free model that doesn’t include a species it has too little information about, and is later unable to classify it correctly.
In emoji examples, the data looks skewed like this:
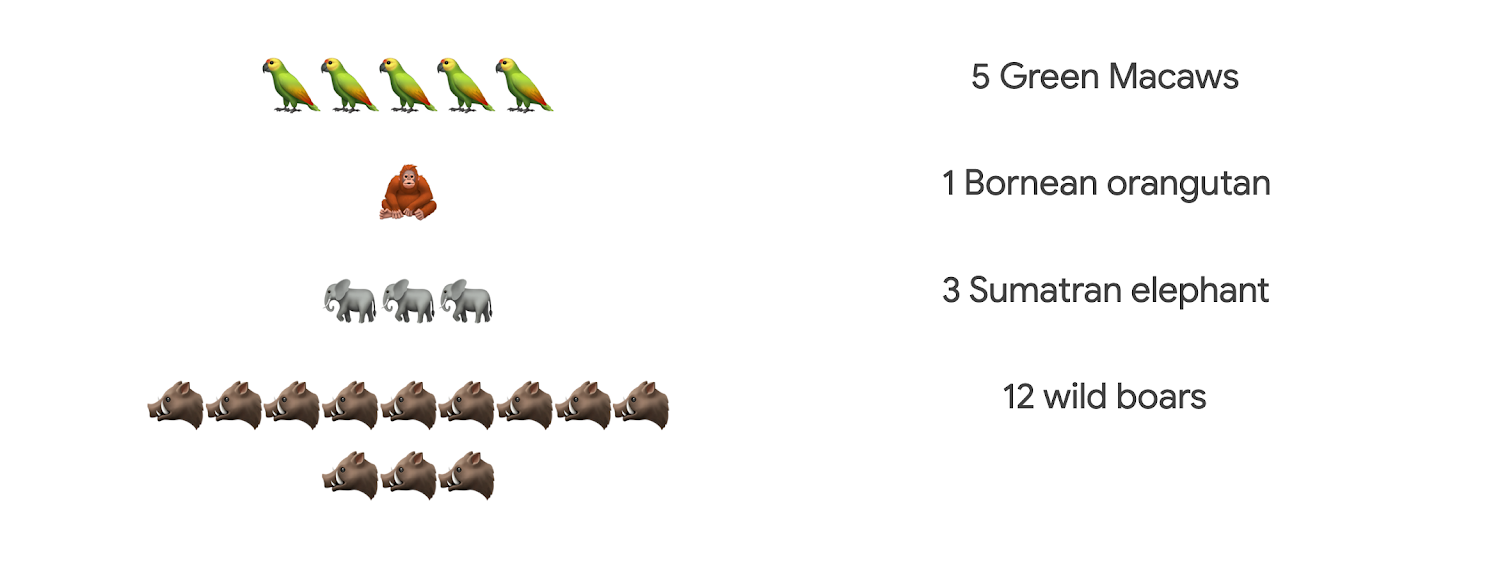
When this dataset balancing act is completed, Dataflow proceeds to download the actual images into Cloud Storage from lila.science. This enables us to only store and process the images that are relevant, and not the entire dataset, keeping computation time and costs to a minimum.
Building the ML model
We build a model with AI Platform Unified, which uses AutoML and the images we stored in Cloud Storage. This is the part where historically speaking, when training a model it could take days, now it takes 2-3 hours. Once the model is ready, you can download it and import it into each micro-controller to begin classifying the images locally. To quickly show you how this looks, we will enable the model to live in the cloud, let’s see what the model thinks about some of these images.

Export model for a microcontroller
The prior example was for exporting the model as an online endpoint, however in order to export your model and then download it into a microcontroller, here are the instructions.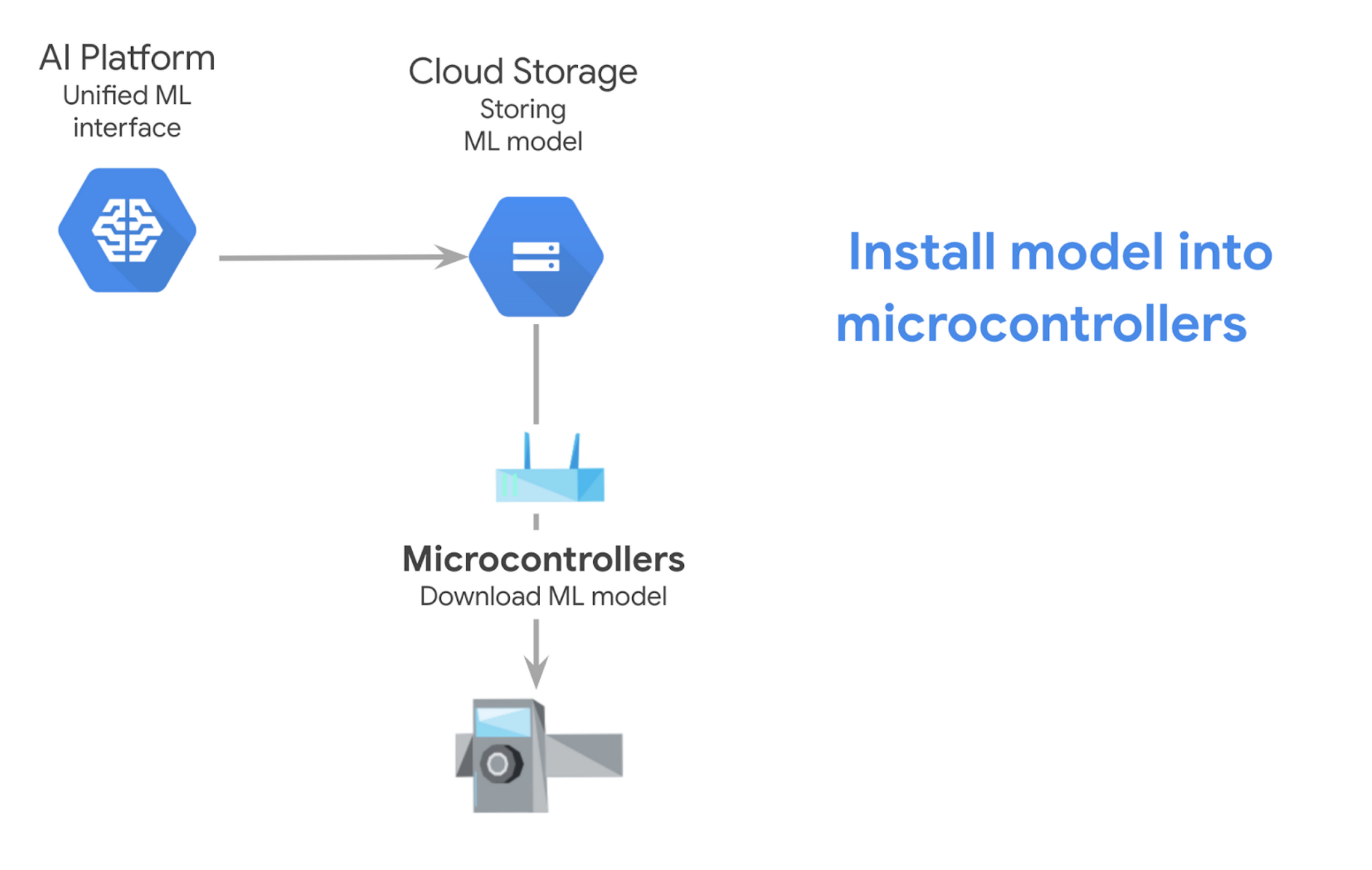
Try it out
You can use WildLifeInsights.org’s free webapp to upload and classify images today. However if you would like to build your own classification model, try out our sample or check out the code in GitHub. It requires no prior knowledge and it contains all the code you need to train an image classification model and then run several predictions in an online notebook format, simply scroll to the bottom and click “open in Colab” per this screenshot:

As mentioned earlier, what used to take days, can now compute in 2-3 hours. And so, all you will need for this project is to:
⏱️ Set aside 2 hours (you click run for each step, and the longest part just runs in the background, you simply need to check back after 2 hours to move onto the next and last step)
? Create a free Google Cloud project (you will then delete that project when you are finished to ensure you do not incur additional costs since the online model has an hourly cost).
(Optional information: *Pricing breakdown)
The total cost for running this sample in your own Cloud project < $27.61 (will vary slightly on each run. Please note rates are based from the date of the publishing of this article, and could vary).
Cloud Storage is in free tier (below 10GB). Does not include Cloud IoT Core nor if you wanted a cloud server to be an endpoint to listen to it constantly (hourly charge) to have devices speak to it online anytime. This option is when you don’t use a microcontroller). It’s a prediction web service.
Create images database (~5 minutes wall time): $0.07
Dataflow: $0.07
Total vCPU: 0.115 vCPU hr * $0.056/vCPU hr = $0.0644
Total memory: 0.431 GB hr * $0.003557/GB hr = $0.001533067
Total HDD PD: 14.376 GB hr * $0.000054/GB hr = $0.000776304
Shuffle Data Processed: unknown but probably negligible
Train AutoML model (~1 hour wall time): $26.302431355
Dataflow: $1.10
Total vCPU: 13.308 vCPU hr * $0.056/vCPU hr = $0.745248
Total memory: 49.907 GB hr * $0.003557/GB hr = $0.177519199
Total HDD PD: 3,327.114 GB hr * $0.000054/GB hr = $0.179664156
Shuffle Data Processed: unknown but probably negligible
AutoML training: $25.20
Training: 8 node hrs * $3.15/node hr = $25.20
Getting predictions (assuming 1 hr of model deployed time, must undeploy model to stop further charges): $1.25
AutoML predictions: $1.25
Deployment: $1.25/hr * 1 hr = $1.25



