Vertex AI のカスタムモデル トレーニング用データの読み取りと格納
Google Cloud Japan Team
※この投稿は米国時間 2023 年 1 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
クラウドで ML モデルのトレーニングを行うには、まず、クラウドにデータを格納する必要があります。
しかし、Google Cloud にデータを格納する方法はいくつもあります。また、カスタムモデルの入力パイプラインにデータを読み取る方法にもさまざまな選択肢があります。Cloud Storage API を使用するか?または、トレーニング ジョブの実行場所(マシン)にデータを直接コピーするか?それとも、自分が使用している ML フレームワークのデータ I/O ライブラリを利用するか?
こうした悩みが少しでも軽くなるよう、Vertex AI のカスタム トレーニング ジョブにデータを読み取る際のおすすめの方法をご紹介します。構造化データと非構造化データの両方をカバーしていますので、Vertex AI でより効率的な入力パイプラインを構築するための参考にしてください。
非構造化データ
Cloud Storage FUSE
画像などの非構造化データの場合は、まず、Cloud Storage バケットにデータをアップロードします。それには、gsutil を使ってカスタム トレーニング ジョブの実行マシンに全データをコピーする、Cloud Storage API を直接またはクライアント ライブラリから呼び出すといった方法がありますが、もっと良い方法があります。それは、Cloud Storage FUSE を使用することです。
Cloud Storage FUSE ツールを使うと、ローカル ファイル システムのファイルにアクセスするのと同じように、Vertex AI のトレーニング ジョブから Cloud Storage のデータにアクセスできます。カスタム トレーニング ジョブを開始すると、ジョブは /gcs ディレクトリを確認します。ここにすべての Cloud Storage バケットがサブディレクトリとして含まれています。この処理は自動的に行われるため、追加の操作は不要です。
この方法は、データに簡単にアクセスできるだけでなく、大きなファイルを連続的に読み取る際のスループットが高いというメリットもあります。
たとえば、複数の JPEG ファイルを training-images という名前の Cloud Storage バケットに格納した場合は、トレーニング ジョブのコードに /gcs/training-images というパスを指定することで、このデータにアクセスできます。
TensorFlow モデルにおけるコードの例を以下に示します。
PyTorch でのコードの例を以下に示します。
NFS 共有のマウント
Cloud Storage FUSE は使いやすく、ほとんどのケースに対応できますが、高スループットを特に重視する場合は、カスタム トレーニング用にネットワーク ファイル システム(NFS)共有をマウントすることをご検討ください。これにより、ローカル ファイルと同じように、高スループットかつ低レイテンシでリモートファイルにアクセスできるようになります。
そのためには、以下の 2 つの準備作業を行います。
まず、Virtual Private Cloud(VPC)で NFS 共有を作成します。認証なしで共有できるようにする必要があります。
次に、VPC ネットワーク ピアリングの設定の手順に沿って、NFS 共有をホストする VPC と Vertex AI をピアリングします。
NFS 共有と VPC ピアリングの設定ができたら、Vertex AI のカスタム トレーニング ジョブで NFS を使用できる状態になります。
カスタム トレーニング ジョブを作成するときに、nfsMounts フィールドと network フィールドを指定する必要があります。この指定は、config.yaml ファイルで以下のように行います。
ジョブの送信時に、以下のように config で上記のファイルを指定します。
構造化データ
機械学習モデルのトレーニングに構造化データを使う場合、データを格納する方法は複数ありますが、最も一般的なのは BigQuery を使用することです。ただし、TFRecord 形式を使用する場合など、BigQuery を使えないケースもあります。この場合は、上記の非構造化データの手順に沿って操作してください。
ここからは、BigQuery からトレーニング データを読み取る際のおすすめの方法について説明します。他にも方法はありますが、手軽さの観点から、特におすすめの方法に絞って説明します。
BigQuery の構造化データ
TensorFlow と BigQuery
ここでは、データがすでに BigQuery にあるものとして説明します。TensorFlow を使用している場合は、BigQuery コネクタを使ってトレーニング データを読み取ることができます。BigQuery コネクタは、BigQuery Storage API を通じて、RPC ベースのプロトコルを使って BigQuery のマネージド ストレージに高速アクセスします。
BigQuery コネクタは主に BigQuery Storage API フローに準じますが、シリアル化されたデータ行を Tensors にデコードすることに伴う複雑な処理が背後で自動的に行われます。手順は以下のとおりです。
BigQueryClient クライアントを作成します。
BigQueryClient を使って、読み取りセッションに対応する BigQueryReadSession オブジェクトを作成します。この読み取りセッションによって、BigQuery テーブル コンテンツが 1 つまたは複数の読み取り用ストリームに分割されます。
BigQueryReadSession オブジェクトの parallel_read_rows を呼び出し、複数の BigQuery ストリームを同時に読み取ります。
TensorFlow を使用している場合のコードの例を以下に示します。
BigQuery のその他の方法
TensorFlow を使用していない場合は、別の方法を検討する必要があります。ここでは、PyTorch または XGBoost を使用しているケースについて説明します。
PyTorch と BigQuery
PyTorch を使用している場合、BigQuery からデータを読み取る方法はいくつかあります。おすすめの方法は、torchdata.datapipes.iter.IterDataPipe()class を使って、iterable-style DataPipe を作成することです。DataPipe を作成すれば、トレーニング データの読み取りに BigQuery Storage Read API を使用できます。
XGBoost と BigQuery
Vertex AI で XGBoost を使用している場合は、Dask や NVIDIA RAPIDS を使うことで、BigQuery 上でスケーラブルな Python を利用できます。Dask によって XGBoost との統合が可能になります。また、Dask を RAPIDS で拡張することも可能です。RAPIDS とは、GPU アクセラレーションによって BigQuery ストレージ上でパイプラインを直接実行できるようにする、一連のオープンソース ライブラリと API です。Dask を使用するコードの例を以下に示します。
また、BigQuery は BigQuery ML ブースト ツリー モデルをサポートしています。この方法の場合、BigQuery からデータを取り出す必要はありません。
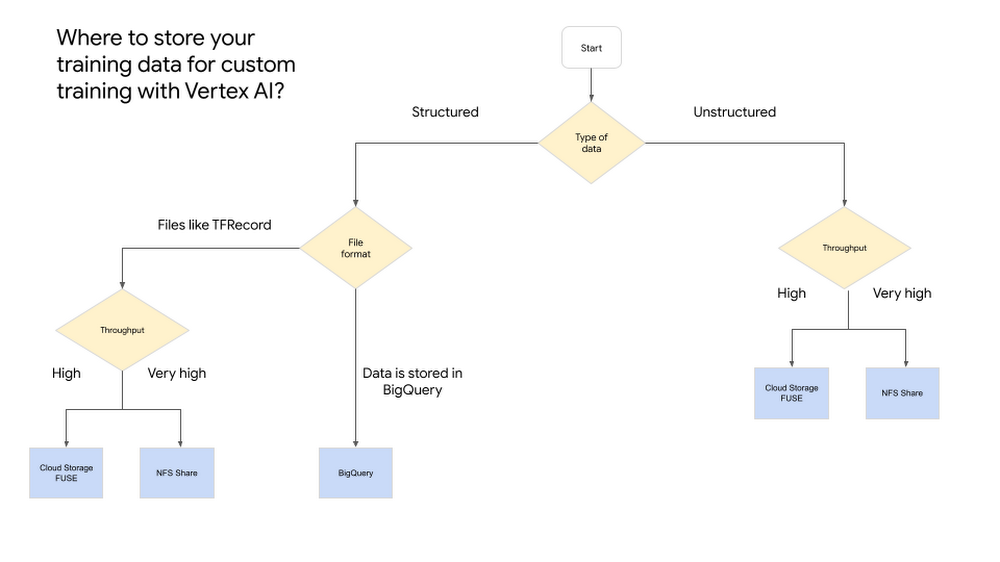
概観図
次のステップ
ML のテストと反復処理のパフォーマンスを高めるには、データ パイプラインを効率化することが重要です。この投稿では、カスタム トレーニング ジョブに構造化データまたは非構造化データを読み取る際のおすすめの方法を紹介しました。Vertex AI 上で独自の ML モデルのトレーニングに着手してみたい方は、まず入門動画シリーズをご覧になるか、こちらの Codelab に取り組んでください。それが終われば、すぐに独自の ML モデルのトレーニングを始められます。
- Google Cloud デベロッパー アドボケイト、Erwin Huizenga