より大きなデータセットに素早く簡単にアクセスし、Vertex AI で ML モデルのトレーニングを加速させる
Google Cloud Japan Team
※この投稿は米国時間 2022 年 8 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
Vertex AI Training はサーバーレスなアプローチで、お客様の ML モデル トレーニング エクスペリエンスを簡素化します。トレーニング データは、設計上、コンピューティング クラスタに保存されません。今までは、お客様のストレージ オプションは Cloud Storage(GCS)か BigQuery(BQ)でした。現在は、Filestore などの NFS 共有をトレーニング ジョブに使用して、ローカル ファイル システムのファイルと同じように、NFS 共有のデータにアクセスできるようになりました。
カスタム トレーニング ジョブ用のビルトイン NFS には次のようなメリットがあります。
Vertex AI Training のための大規模なデータセットを簡単に保存、アクセスする方法を提供し、トレーニング データの移動などの面倒な作業を軽減。
データ ダウンロードのステップを削減することで、トレーニング ジョブの実行を高速化。
他のストレージ ソリューションを使用する場合と比較して、より高いスループットでネットワーク経由のデータ ストリームが可能。
この記事では Filestore インスタンスの作成方法と、カスタム トレーニング コードを使用してモデルをトレーニングするのにインスタンスに保存されたデータをどのように使用するかについてご説明します。
Filestore インスタンスを作成し、データをコピーする
まず、NFS ファイル サーバーとして Filestore インスタンスを作成しましょう。
Cloud コンソールで Filestore Instances ページに移動し、[インスタンスを作成] をクリックします。

次の点に注意して、ニーズに基づいてインスタンスを設定します。
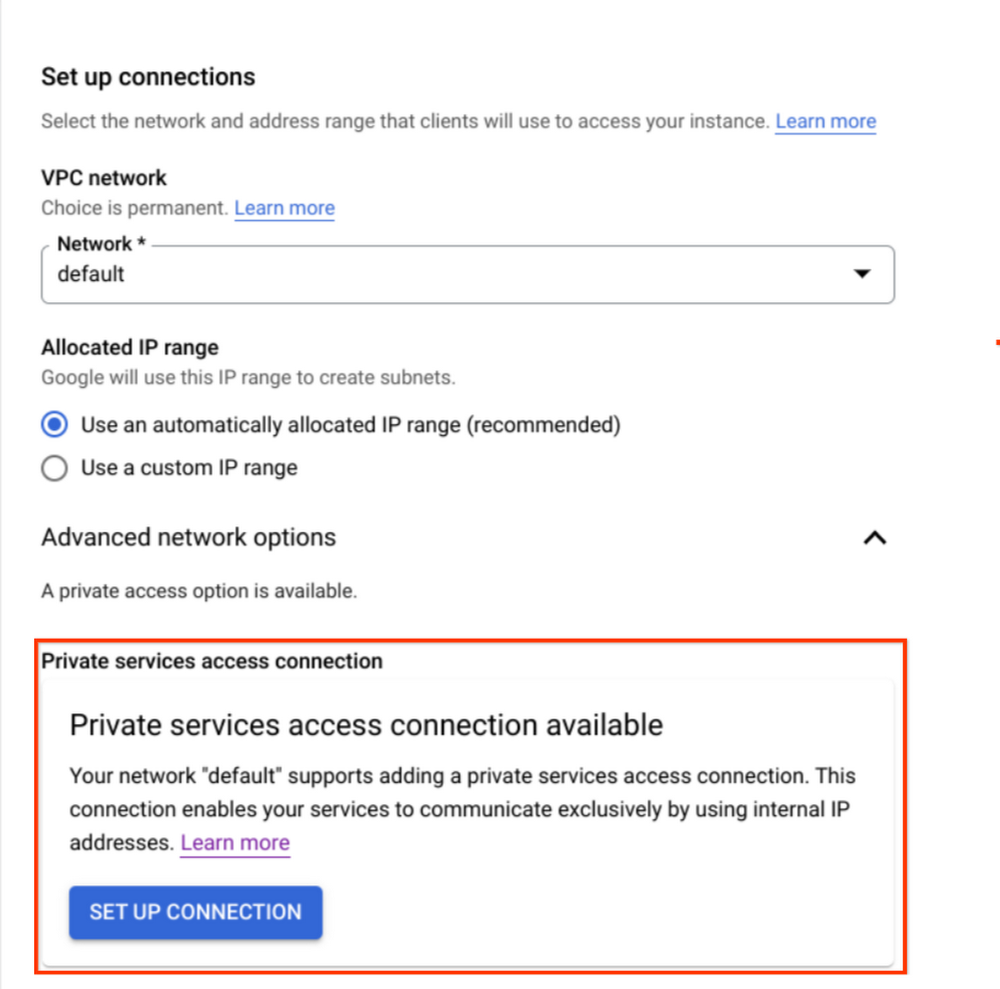
わかりやすくするため、このチュートリアルでは「デフォルト」VPC ネットワークを使用します。お好きなネットワークを選択できますが、後で必要になるのでネットワーク名を保存しておいてください。
接続モードが「非公開サービス アクセス」であることを確認してください。
詳細な手順については、インスタンスの作成をご覧ください。
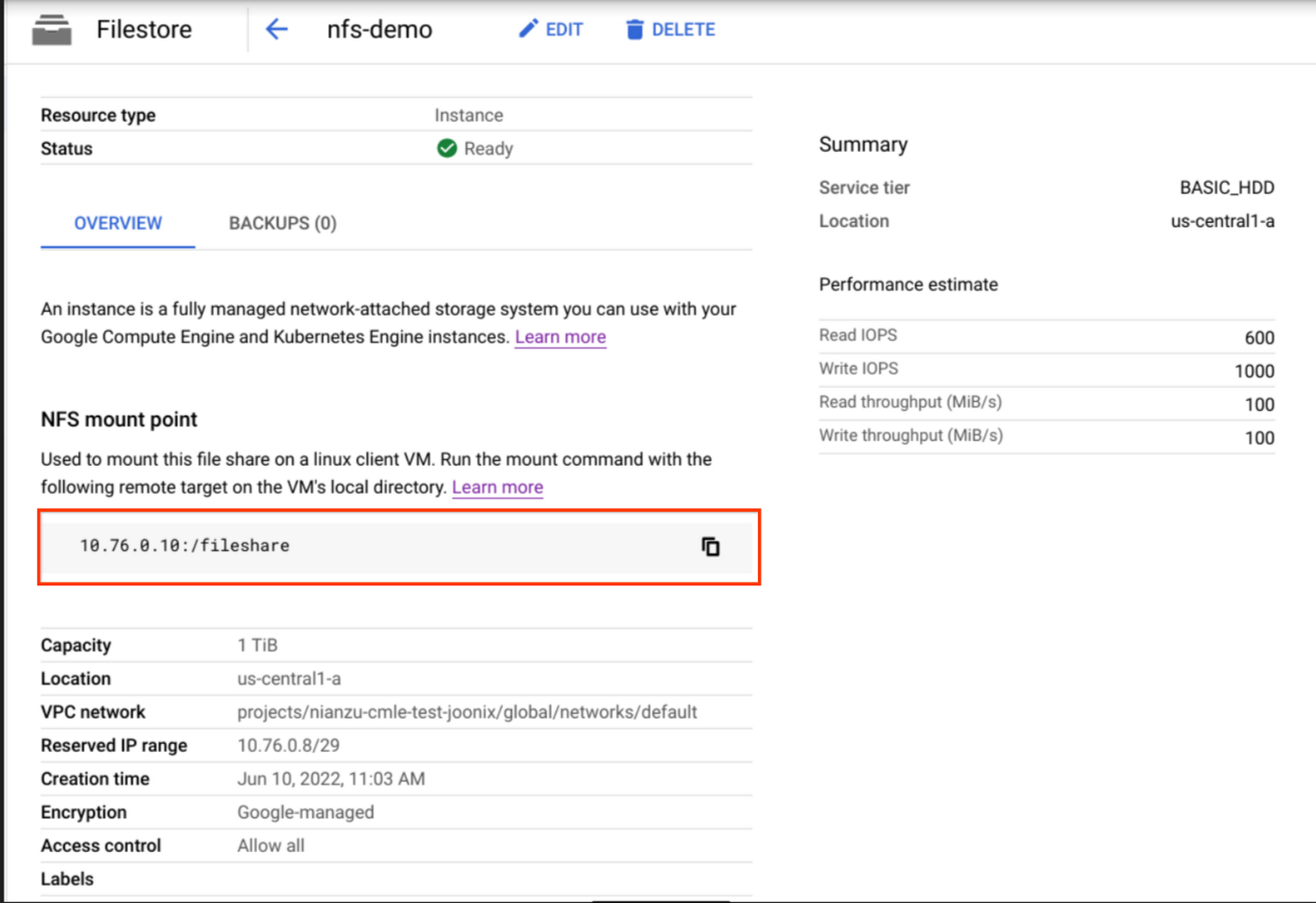
ダッシュボード ページに新しいインスタンスが表示されます。インスタンスの名前をクリックすると、詳細が表示されます。

NFS マウント ポイント情報を SERVER:PATH の形式で保存します。これは後ほど使用します。
インスタンスにデータをコピーするには、公式ガイドの手順に沿ってください。
VPC ネットワーク ピアリングを設定する
前述のとおり「非公開サービス アクセス」モードを選択して Filestore インスタンスを作成したので、ネットワークと Google サービスとの間で VPC ピアリングが構築されています。サードパーティーの NFS ソリューションを使用している場合は、VPC ネットワーク ピアリングの設定の手順に沿い、ピアリングを設定してください。
NFS にアクセスするカスタムジョブを作成する
NFS 共有と VPC ピアリングの設定ができたら、カスタム トレーニング ジョブで使用できる状態になります。このセクションでは、gcloud CLI を使用して、NFS 共有内のファイルにアクセス可能なカスタム トレーニング ジョブを作成します。
詳しくは、次のような手順で簡略化できます。
マウント ポイント ディレクトリを /mnt/nfs/ のパスに決定します。ジョブ送信時に、このディレクトリに NFS 共有がマウントされます。
カスタムコード内で、マウント ポイント ディレクトリのローカルパスを介して NFS ファイル共有にアクセスできます。
トレーニング ジョブ リクエストで「nfsMount」 フィールドと network フィールドを指定して、送信します。
例えば、my_mount を「Mount Point」フォルダにします。それから、カスタムコードで /mnt/nfs/my_mount を指定し、Filestore インスタンス内に保存されているデータを取得します。
ローカルパスを介して Filestore インスタンスに書き込むこともできます。
ここでは、トレーニング ジョブを送信するための前述のコードを含む、カスタム コンテナ イメージ gcr.io/PROJECT_ID/nfs-demo を構築するとします。次のようなコマンドを実行できます。
この config.yaml ファイルは CustomJobSpec が記述されており、次のようなネットワークと NFS マウント設定が必要です。
トレーニング ジョブのステータスを確認でき、NFS ファイル共有からのデータの読み取り / 書き込みが正常であることを確認できます。
まとめ
この記事では、Filestore を使用し、Vertex AI にマウントして NFS 共有内のファイルへアクセスする方法をご説明しました。Filestore インスタンスと VPC ピアリング接続を作成し、ローカル ディレクトリとして Filestore から直接読み込み可能なジョブを送信しました。
Filestore のような NFS 共有からデータをストリーミングすることによるパフォーマンスとスループットのメリットを利用することで、Vertex AI でトレーニング ジョブを実行するプロセスを簡素化、高速化し、ユーザーがより多くのデータでより良いモデルをトレーニングすることを可能にします。
Vertex AI での NFS ファイル システムの使用の詳細については、Vertex AI Training での NFS サポートをご覧ください。
Vertex AI については、デベロッパー アドボケイトによるブログ投稿をご覧ください。
- ソフトウェア エンジニアリング インターン Manqing Feng
- ソフトウェア エンジニア Nathan Li