Reading and storing data for custom model training on Vertex AI
Nikita Namjoshi
Developer Advocate
Erwin Huizenga
Developer Advocate Machine Learning
Before you can train ML models in the cloud, you need to get your data to the cloud.
But when it comes to storing data on Google Cloud there are a lot of different options. Not to mention the different ways you can read in data when designing input pipelines for custom models. Should you use the Cloud Storage API? Copy data directly to the machine where your training job is running? Use the data I/O library of your preferred ML framework?
To make things a little easier for you, we’ve outlined some recommendations for reading data in your custom training jobs on Vertex AI. Whether your use case requires structured or unstructured data, these tips will help you to build more efficient input pipelines with Vertex AI.
Unstructured Data
Cloud Storage FUSE
If you have unstructured data, such as images, the best place to start is by uploading your data to a Cloud Storage bucket. Instead of using gsutil to copy all of the data over to the machine where your custom training job will run, or calling the Cloud Storage APIs directly or from a client library, you can leverage Cloud Storage FUSE.
Using the Cloud Storage FUSE tool, training jobs on Vertex AI can access data on Cloud Storage as files in the local file system. When you start a custom training job, the job sees a directory /gcs, which contains all your Cloud Storage buckets as subdirectories. This happens automatically without any extra work on your part.
Not only does this make it easy to access your data, but it also provides high throughput for large file sequential reads.
For example, if your data is a collection of JPEG files in a Cloud Storage bucket called training-images you can access this data in your training code with the path /gcs/training-images.
If you were to build a TensorFlow model, your code might look something like this:
And if you’re a PyTorch user, your code might look something like this:
Mount an NFS Share
While Cloud Storage FUSE is easy to use and will work for most cases, if you need particularly high throughput you can consider mounting a Network File System (NFS) share for custom training. This allows your jobs to access remote files as if they are local with high throughput and low latency.
Before you begin, there are two steps you’ll need to take:
First, create an NFS share in a Virtual Private Cloud (VPC). Your share must be accessible without authentication.
Then, follow the instructions in Set up VPC Network Peering to peer Vertex AI with the VPC that hosts your NFS share.
Once you have the NFS share and VPC peering set up, you are ready to use NFS with your custom training jobs on Vertex AI.
When you create your custom training job, you’ll need to specify the nfsMounts field and network fields. You can do this in a config.yaml file:
And then pass in the config when submitting the job:
Structured Data
Multiple options exist when you want to train a machine learning model on structured data. Most of the time, you’ll use BigQuery for storing the training data. When you can’t use BigQuery, for example, if you want to use the TFRecord format, you can follow the instructions described in the unstructured section above.
In the second part of this blog, we’ll discuss the best options for reading training data from BigQuery. Note that there might be other options, but we’ll focus on some of the best and easiest to get started with options.
Structured data with BigQuery
TensorFlow and BigQuery
When your data sits in BigQuery then that’s a great start. If you’re a TensorFlow user, you can use the BigQuery Connector to read training data. The BigQuery connector relies on the BigQuery Storage API, which provides fast access to BigQuery’s managed storage using an rpc-based protocol.
The BigQuery connector mostly follows the BigQuery Storage API flow, but hides the complexity associated with decoding serialized data rows into Tensors. You need to follow these steps:
Create a
BigQueryClientclient.Use the
BigQueryClientto create aBigQueryReadSessionobject corresponding to a read session. A read session divides the contents of a BigQuery table into one or more streams for reading the data.Call
parallel_read_rowson theBigQueryReadSessionobject to read from multiple BigQuery streams in parallel.
If you’re using TensorFlow, your code might look something like this:
BigQuery alternatives
If you’re not using TensorFlow, then there are some alternatives you can look at. Here are two depending if you are a PyTorch or XGBoost user.
PyTorch and BigQuery
If you’re a PyTorch user, there are multiple options for reading data from BigQuery. We recommend you create an iterable-style DataPipe using the torchdata.datapipes.iter.IterDataPipe()class. When creating a DataPipe you can leverage the BigQuery Storage Read API for reading your training data.
XGBoost and BigQuery
When using XGBoost with Vertex AI, you can use scalable Python on BigQuery using Dask and NVIDIA RAPIDS. Dask offers integration with XGBoost. It’s possible to extend Dask with RAPIDS, a suite of open-source libraries and APIs to execute GPU-accelerated pipelines directly on BigQuery storage. The code for Dask would look something like this:
Alternatively, BigQuery has support for boosted tree models through BigQuery ML. This way you don’t have to take your data out of BigQuery.
All in one overview
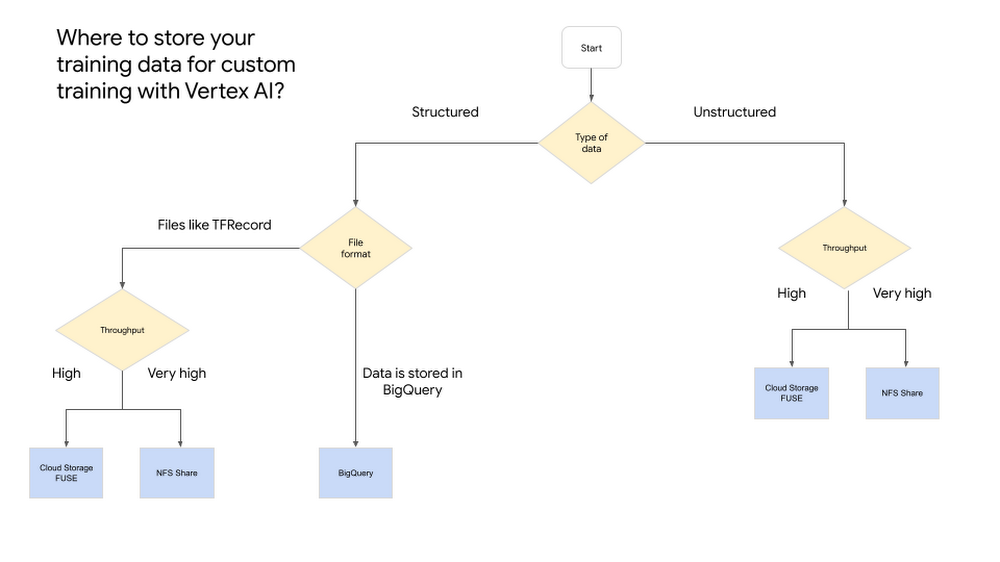
What is next
Efficient data pipelines are a key piece of effective ML experimentation and iteration. In this blog we looked at several recommendations for reading structured and unstructured data in your custom training jobs. If you’re looking to get started training some ML models of your own on Vertex AI, check out this introductory video series or run through this codelab. Now it’s time to train some ML models of your own!





