Access larger dataset faster and easier to accelerate your ML models training in Vertex AI
Manqing Feng
Software Engineering Intern
Nathan Li
Software Engineer
Access larger dataset faster and more easier to accelerate your ML models training in Vertex AI
Vertex AI Training delivers a serverless approach to simplify the ML model training experience for customers. As such, training data does not persist on the compute clusters by design. In the past, customers had only Cloud Storage (GCS) or BigQuery (BQ) as storage options. Now, you can also use NFS shares, such as Filestore, for training jobs and access data in the NFS share as you would files in a local file system.
Built-in NFS support for custom training jobs provides the following benefits:
Delivers an easy way to store and access large datasets for Vertex AI Training with less of the cumbersome work involving moving training data around.
Training jobs execute faster by eliminating the data download steps.
Data streams over the network with higher throughput compared to using alternative storage solutions.
This article demonstrates how to create a Filestore instance and how to use the data that’s stored in the instance to train a model with your custom training code.
Create a Filestore instance and copy data
First let’s create a Filestore instance as our NFS file server.
In the Cloud Console, go to the Filestore Instances page and click Create instance.

Configure the instance based on your needs, noting the following:
For this tutorial, we used the "default" VPC network for simplicity. You may choose any network you want, but save the network name as we will need it later.
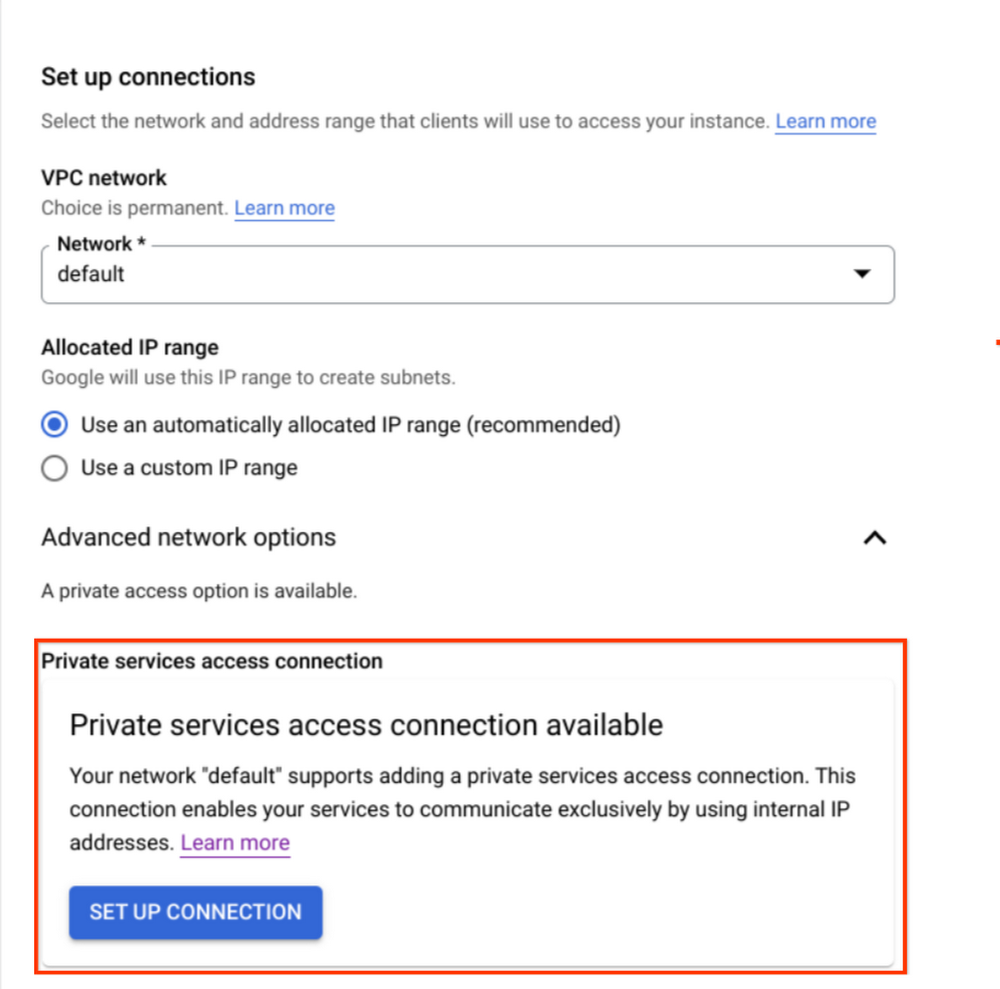
Ensure that you are using "private service access" as the connection mode.
For in depth instructions, see Creating instances.
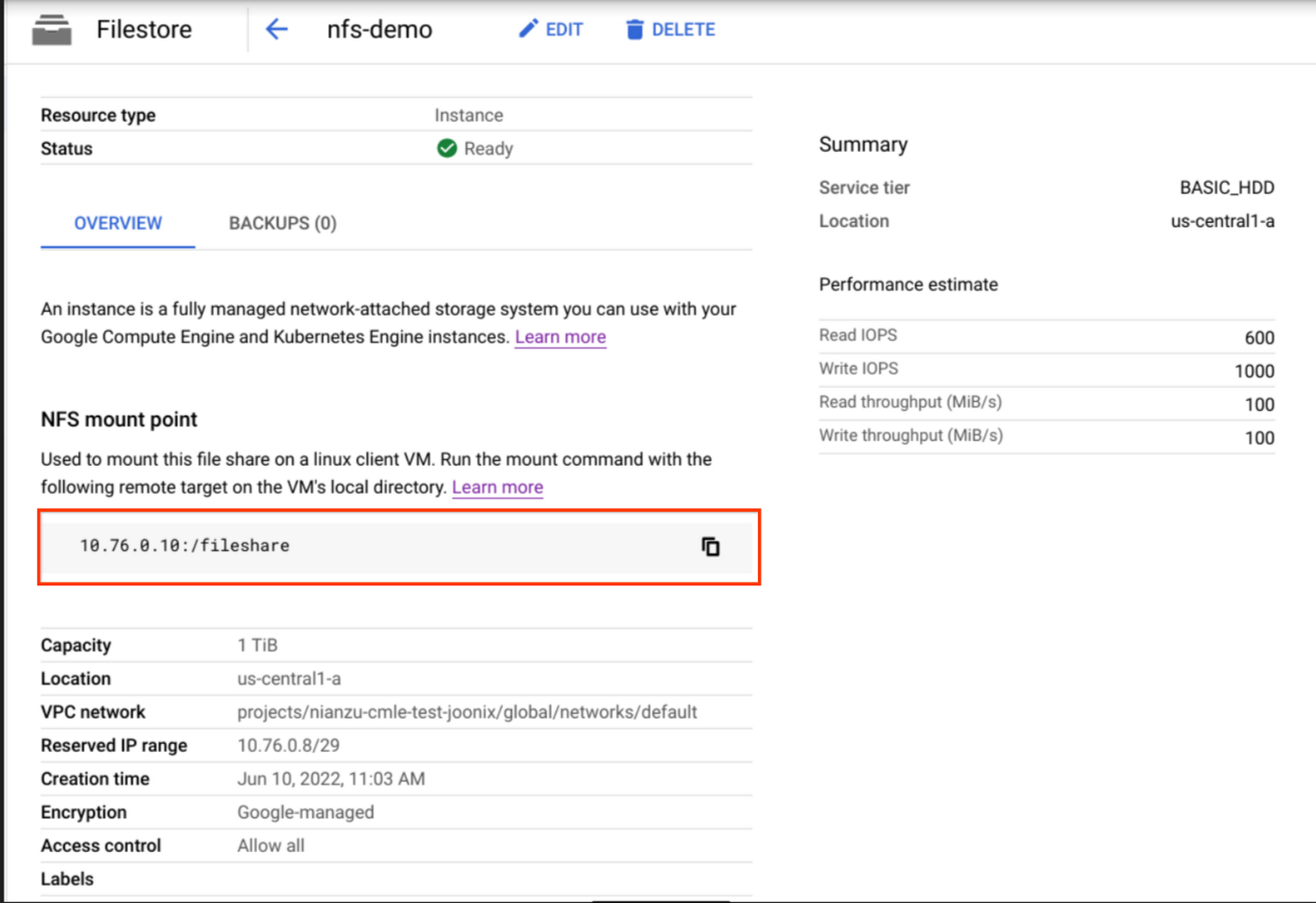
Your new instance will show on the dashboard page. Click on the name of the instance to view the details of the instance.

Save the NFS mount point information, which is in the form of SERVER:PATH. We will use it later.
Copy data to your instance by following the instructions from the official guide.
Set up VPC Network Peering
Since we chose “private service access” mode for our Filestore instance as mentioned above, we already have VPC peering established between our network and Google services. If you’re using a third party NFS solution, you may need to set up the peering yourself as instructed in Set up VPC Network Peering.
Create a Custom Job accessing NFS
Once you have the NFS share and VPC peering set up, you are ready to use it with your custom training jobs. In this section, we will use the gcloud CLI to create a custom training job that can access the files in your NFS share.
To be specific, the process can be simplified into following general steps:
Decide a mount point directory under the path
/mnt/nfs/. Your NFS share will be mounted to this directory when you submit jobs.In your custom code, you can access your NFS file share via the local path to your mount point directory.
Specify the “nfsMount” field and
networkfields in your training job request and submit it.
For example, we make my_mount the “Mount Point'' folder. Then in our custom code, we can specify /mnt/nfs/my_mount to get the data stored in our Filestore instance:
We may also write to the Filestore instance via that local path:
Here, suppose that we built a custom container image gcr.io/PROJECT_ID/nfs-demo containing the above code for submitting our training job. We can run commands like the following:
The config.yaml file describes the CustomJobSpec and it should have the network and NFS mounts settings, like the following:
Then we can check the status of your training job and see how it successfully reads/writes the data from your NFS file shares.
Summary
In this article, we used Filestore to demonstrate how to access files in an NFS share by mounting it to Vertex AI. We created a Filestore instance and VPC peering connections, and then submitted a job that can directly read from Filestore as a local directory.
By leveraging the performance and throughput benefits of streaming data from NFS shares such as Filestore, it simplifies and accelerates the process to run training jobs on Vertex AI, which empowers users to train even better models with more data.
To learn more about using NFS file systems with Vertex AI, see NFS support on Vertex AI training.
To learn more about Vertex AI, check out this blog post from our developer advocates.



