Oracle から Cloud Spanner への移行に関するデータの検証
Google Cloud Japan Team
※この投稿は米国時間 2021 年 8 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
はじめに
Oracle データベースは、データベース業界ではよく知られている RDBMS ですが、高度にスケーラブルな環境では、マルチリージョン、無限のスケーラビリティ、最大 99.999% の可用性を備えた Cloud Spanner を活用するお客様が見受けられます。Oracle から Spanner への移行は、さまざまなアプローチによって対応できますが、移行における最も重要なステージの一つはデータの検証です。データを検証するプロセスを簡略化するためのツールの一つに、データ検証ツール(DVT)があります。
データ検証ツールは、オープンソースの Python CLI をベースとしたツールで、異種のデータソース テーブルを比較し、マルチレベルの検証機能を提供します。DVT は、さまざまな種類のソースおよびターゲット データベースに接続し、定義された基準に基づいて検証レポートを作成できます。このブログでは、データ検証ツールを設定して Oracle テーブルと Spanner テーブルの間でデータを比較し、BigQuery で検証レポートを作成する方法をご紹介します。
データ検証ツールのインストール
データ検証ツール(DVT)をインストールして実行するには、python 3.6+、pip、gcc がインストールされたマシンが必要です。DVT は、Google Cloud SDK がインストールされた BigQuery と Spanner の接続を、ネイティブにサポートしています。DVT には、データ検証の出力を BigQuery テーブルに直接書き込む機能があります(デフォルトはコンソール出力)。
この機能を使用するには、前もって BigQuery の出力テーブルを作成する必要がありますが、terraform を使えば簡単に作成できます。そのためには、お使いのマシンに Terraform CLI をインストールする必要があります。さらに、リポジトリをクローンするために、git のパッケージがインストールされていることを確認してください。
リポジトリをお使いのマシンにクローンします。
リポジトリ内で、terraform フォルダに移動します。以下の手順に沿って、データ検証レポートに必要な BigQuery テーブルを作成します。
terraform フォルダ内の testenv.tf ファイルを削除する
terraform フォルダ内の variables.tf を表示し、デフォルトの「pso-kokoro-resources」を「YOUR_PROJECT_ID」に置き換えてデフォルトとして設定する
terraform ディレクトリから次のコマンドを実行する
別の方法として、Google Cloud SDK に含まれる bq コマンドライン ツールを使ってテーブルを作成することもできます。
DVT ツールをインストールする前に、python で仮想環境を作成し、ツールのサンドボックス化を行います。
pip を使用して選択した環境に DVT ツールをインストールします。
Oracle 接続を設定するには、pip を使用して cw_Oracle パッケージをインストールします。
この場合、ローカルマシンにインストールされた Oracle インスタント クライアント ライブラリも必要になります。こちらに記載されている手順を行ってください。
接続の作成:
検証を実行する前に、Oracle システムへの接続を作成する必要があります。
コマンドを実行する前に、以下の情報を入力してください。
<oracle-host-name>Oracle ホスト名
<oracle-port-number>Oracle ポート名
<user-name>Oracle ログイン ユーザー名
<password>Oracle ログイン パスワード
<database-name>Oracle データベース名
次のステップでは、Spanner インスタンスへの接続を作成します。
コマンドを実行する前に、以下の情報を入力してください。
<gcp-project-id> | Spanner インスタンスが設置されている GCP プロジェクト ID |
<spanner-instance-id> | Spanner インスタンス ID |
<spanner-database-id> | Spanner データベース ID |
GCP サービスへの接続にデフォルト ユーザーを使用するには、「gcloud auth application-default login」を使用します。サービス アカウントを使用して接続を作成する場合は、カスタム パラメータ「google_service_account_keypath」でサービス アカウントの json キーファイルを指定できます。
検証タイプ:
DVT は以下の検証タイプをサポートしています。
テーブルレベル
テーブル行数
行数によるグループ化
列の集計 - SUM()、MIN()、MAX()、AVG()
フィルタと制限
列レベル
列全体のデータ型
シナリオに応じて、異なる検証タイプを使用できます。このチュートリアルでは、count 関数、min 関数、max 関数を使用して、各列の集約に基づく検証を行います。検証を可視化してカスタマイズするために、構成ファイルのオプションを指定し、その検証構成を yaml ファイルとして記述します。
例えば、11 列ある従業員テーブルの検証を検討しているとします。すべての列にカウントベースの集計を追加し、給与列には最小値と最大値の集計を追加します。
コマンドを実行する前に、以下の情報を入力してください。
<gcp-project-id> | Spanner インスタンスが設置されている GCP プロジェクト ID |
Config.yaml は検証基準に沿って作成されます。
検証の実行:
構成ファイルが作成されたら、confg.yaml に基づいて検証を行うことができます。
このコマンドを使用すると、検証ツールを実行し、その結果を BigQuery テーブルに保存します。
検証レポートの分析
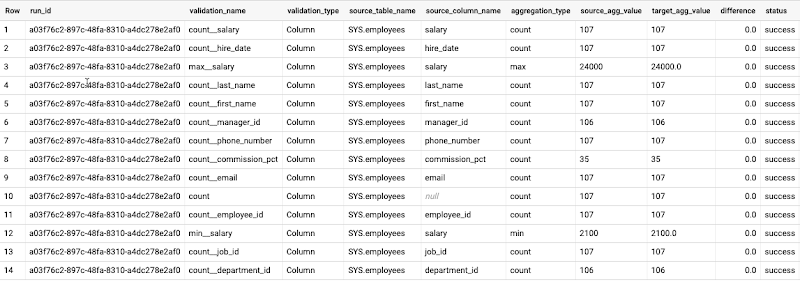
検証レポートには、構成ファイルで定義された各列の集計値と差分が表示されます。ステータス列では、指定されたしきい値に基づいて値が自動的に入力されます(デフォルトのしきい値は 0.0)。
詳細情報
データ検証ツールの積極的な開発が行われています。データ検証ツールをぜひお試しください。そしてフィードバックや問題の報告、修正や機能を強化するための PR の送付などのご協力をお願いいたします。これらのオープンソース ツールは、ユーザー コミュニティの一部であり、Google Cloud が公式にサポートするものではありません。
-Google Cloud 戦略的クラウド エンジニア Logan Ramalingam