Data Validation for Oracle to Cloud Spanner Migration
Logan Ramalingam
Strategic Cloud Engineer, Google Cloud
Introduction
The Oracle database is a popular RDBMS in the database industry, but for a highly scalable environments we see customers choosing to leverage Cloud Spanner with its multi-region, unlimited scalability and up to 99.999% availability. Migration of Oracle to Spanner can be addressed using many approaches but one of the most important stages of the migration is Data Validation. One tool that helps simplify the data validation process is the Data Validation Tool (DVT).
Data Validation Tool is an open sourced python CLI based tool that compares heterogeneous data source tables and provides multi-level validation functions. DVT can connect to different types of source and target databases and create validation reports based on the criteria defined. In this blog, we will see how to set up the Data Validation Tool to compare data between Oracle and Spanner tables and create validation reports in BigQuery.
Installing Data Validation Tool
To install and run a data validation tool (DVT), we need a machine with python 3.6+, pip, gcc installed. DVT natively supports BigQuery and Spanner connections with Google Cloud SDK installed. DVT has the capability to write the output of data validation into BigQuery tables directly (console output is default).
BigQuery output tables need to be created beforehand for this and we can use terraform to create them easily. This will need a terraform cli to be installed on your machine. In addition to that, make sure git packages are installed to clone the repository.
Clone the repository onto your machine.
Inside the repository, navigate to the terraform folder. Perform the below steps to create the BigQuery tables necessary for data validation reports.
Delete the testenv.tf file inside the terraform folder
View variables.tf inside the terraform folder and replace default "pso-kokoro-resources" with default = "YOUR_PROJECT_ID"
Run the following commands from terraform directory
Alternatively, we can use the bq command line tool as a part of Google Cloud SDK to create the tables.
Before installing the dvt tool, create a virtual environment in python to sandbox the tool.
Now we can install the tool in the selected environment using pip.
To configure the Oracle connection, install cw_Oracle package using pip.
This will also require an Oracle instant client library installed on the local machine. Follow the steps mentioned here.
Creating Connections:
Before running the validation, connection to the Oracle system needs to be created.
Fill in the below details before executing the command
<oracle-host-name> | Oracle hostname |
<oracle-port-number> | Oracle portname |
<user-name> | Oracle login username |
<password> | Oracle login password |
<database-name> | Oracle database name |
Next step, create a connection to the Spanner instance.
Fill in the below details before executing the command:
<gcp-project-id> | GCP Project ID where Spanner instance is located |
<spanner-instance-id> | Spanner Instance ID |
<spanner-database-id> | Spanner Database ID |
Use `gcloud auth application-default login` to use the default user to connect to GCP services. In case if you want to use a service account to create a connection, you can provide a service account json key file in the custom parameter `google_service_account_key_path`.
Validation Types:
DVT supports the following validation types:
Table level
Table row count
Group by row count
Column aggregation - SUM(), MIN(), MAX(), AVG()
Filters and limits
Column level
Full column data type
Based on the scenario, different validation types can be used. For this tutorial, we will be doing each column aggregation based validation using count, min and max functions. To visualize and customize the validation, provide the config-file option to write the validation configuration as a yaml file.
For example, we are considering validation of employee table which has 11 columns. We will be adding count based aggregation on all columns and min and max aggregation on the salary column.
Fill in the below details before executing the command
<gcp-project-id> | GCP Project ID where Spanner instance is located |
Config.yaml is created with the validation criteria.
Running Validation:
After the configuration file is created, we can run the validation based on the confg.yaml.
This command will run the validation tool and store the results in the BigQuery table.
Analyzing Validation Report
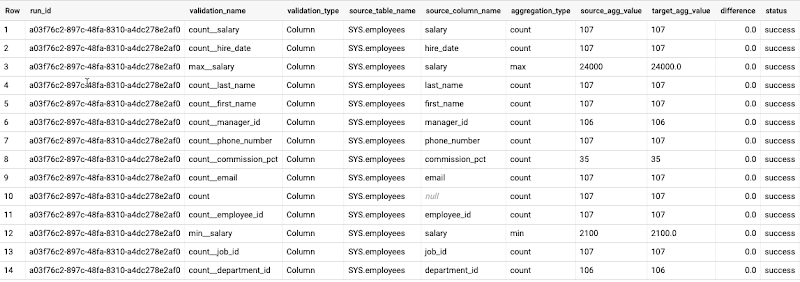
The validation report shows aggregation values and differences for each column defined in the config file. Status column automatically fills the value based on the threshold provided (default threshold is 0.0).
Further Information
Introducing the Data Validation Tool for EDW migrations
Migrating from Oracle to Cloud Spanner
Data Validation Tool is under active development. Please give them a try and help out by giving feedback, filing issues and sending PRs for fixes and enhancements. These open source tools are part of the user community and are not officially supported by Google Cloud.



