Introducing the Data Validation Tool for EDW migrations
Neha Nene
Strategic Cloud Engineer
James Fu
Manager, Cloud Data Engineer
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialData validation is a crucial step in data warehouse, database, or data lake migration projects. It involves comparing structured or semi-structured data from the source and target tables and verifying that they match after each migration step (e.g data and schema migration, SQL script translation, ETL migration, etc.)
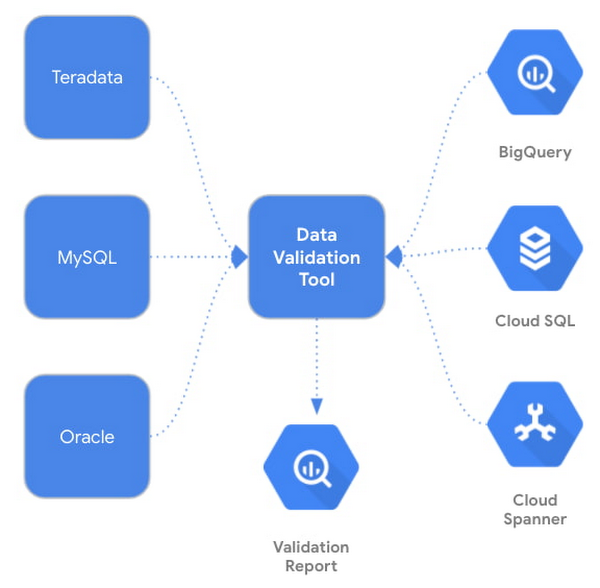
Today, we are excited to announce the Data Validation Tool (DVT), an open sourced Python CLI tool that provides an automated and repeatable solution for validation across different environments. The tool uses the Ibis framework to connect to a large number of data sources including BigQuery, Cloud Spanner, Cloud SQL, Teradata, and more.
Why DVT?
Cross platform data validation is a non-trivial and time-consuming effort, and many customers have to build and maintain a custom solution to perform such tasks. The DVT provides a standardized solution to validate customer's newly migrated data in Google Cloud against the existing data from their on-prem systems. DVT can be integrated with existing enterprise infrastructure and ETL pipelines to provide a seamless and automated validation.
Solution
The DVT provides connectivity to BigQuery, Cloud SQL, and Spanner as well as third-party database products and file systems. In addition, it can be easily integrated into other Google Cloud services such as Cloud Composer, Cloud Functions and Cloud Run. DVT supports the following connection types:
BigQuery
Cloud SQL
FileSystem (GCS, S3, or local files)
Hive
Impala
MySQL
Oracle
Postgres
Redshift
Snowflake
Spanner
SQL Server
Teradata
The DVT performs multi-leveled data validation functions, from the table level all the way to the row level. Below is a list of the validation features:
Table level
Table row count
Group by row count
Column aggregation
Filters and limits
Column level
Schema/Column data type
Row level
Hash comparison (BigQuery only)
Raw SQL exploration
Run custom queries on different data sources
How to Use the DVT
The first step to validating your data is creating a connection. You can create a connection to any of the data sources listed previously. Here’s an example of connecting to BigQuery:
Now you can run a validation. This is how a validation between a BigQuery and a MySQL table would look:
The default validation if no aggregation is provided is a COUNT *. The tool will count the number of columns in the source table and verify it matches the count on the target table.
The DVT supports a lot of customization while validating your data. For example, you can validate multiple tables, run validations on specific columns, and add labels to your validations.
You can also save your validation to a YAML configuration file. This way you can store previous validations and modify your validation configuration. By providing the `config-file` flag, you can generate the YAML file. Note that the validation will not execute when this flag is provided - only the file is created.
Here is an example of a YAML configuration file for a GroupedColumn validation:
Once you have a YAML configuration file, it is very easy to run the validation.
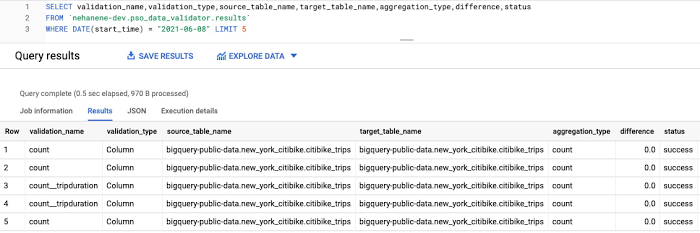
Validation reports can be output to stdout (default) or to a result handler. The tool currently supports BigQuery as the result handler.
In order to output to BigQuery, simply add the `--bq-result-handler` or `-bqrh` flag.
Below is an example of the validation results in BigQuery. View the complete schema for validation reports in BigQuery here.