Vertex AI Workbench Notebooks で Cloud Storage をファイル システムとして利用
Google Cloud Japan Team
※この投稿は米国時間 2022 年 6 月 1 日に、Google Cloud blog に投稿されたものの抄訳です。
Vertex AI Workbench User Managed Notebooks で Cloud Storage をファイル システムとして利用
「gsutil cp -r 」が不要ということになったら、どう感じられるでしょうか?
機械学習モデルを開発されたことがある方なら、データ品質とガバナンスの課題を経験されていることでしょう。モデル開発の際には、Vertex AI Workbench の Jupyter Notebook を立ち上げ、Cloud Storage からデータをコピーします。データセットが大きい場合は、すべてのデータがノートブックにコピーされるまで、しばらく待つことになります。これで、データのコピーが 2 つになります。この数 x 組織内のデータ サイエンティスト数を考えてみると、どうやってそれだけのデータを調整するのかという問題が発生します。
Cloud Storage FUSE により、Vertex AI Workbench Notebooks や Vertex AI トレーニング ジョブに Cloud Storage バケットをファイル システムとしてマウントできるようになりました。こうすることで、すべてのデータを単一のリポジトリ(Cloud Storage)に保管し、信頼できる唯一の情報源として複数のチーム間で利用できるようになります。
Cloud Storage FUSE
Cloud Storage FUSE は Vertex AI システムにマウントされる File System in User Space(FUSE) です。これは従来の Cloud Storage へのアクセス方法に比べ、3 つのメリットを提供します。
データをダウンロードすることなく、ジョブをすばやく開始することが可能。
Cloud Storage API の呼び出し、レスポンスの処理、クライアントサイド ライブラリとの統合などの操作を行わなくても、ジョブで大規模かつ簡単に I/O を実行可能。
ジョブは、Cloud Storage FUSE の最適化されたパフォーマンスを活用可能。
Cloud Storage FUSE の詳細とベスト プラクティスについては、こちらをご覧ください。
すべてのカスタム トレーニング ジョブで、Vertex AI はアクセス可能な Cloud Storage バケットを各トレーニング ノードのファイル システムの /gcs/ ディレクトリにマウントします。ローカル ファイル システムに直接読み書きを行い、Cloud Storage のデータを読み書きできます。
Vertex AI Workbench Notebooks の場合、数ステップで Cloud Storage FUSE に対応します。次にその方法を説明します。では、さっそく始めましょう。
Vertex AI Workbench Notebooks を開始する
Vertex AI Workbench は、Jupyter Notebooks を実行するためのフルマネージド、スケーラブル、エンタープライズ対応のコンピューティング インフラストラクチャです。Workbench Notebooks にはディープ ラーニング パッケージ スイートがプリインストールされています。また、TensorFlow、PyTorch、scikit-learn など複数のフレームワークをサポートしています。さらにカスタマイズが必要な場合も、問題ありません。お気に入りのフレームワークと依存関係を持つカスタム コンテナも構築できます。
Cloud Storage のバケットをマウントする
まず、Vertex AI Workbench Notebook を作成する必要があります。この例では、ユーザー管理のノートブックを作成します。作成はシンプルです。
Vertex AI コンソールの「ワークベンチ」セクションで、[ユーザー管理のノートブック] タブを選択し、「新しいノートブック」を選択して、ノートブックを作成します。
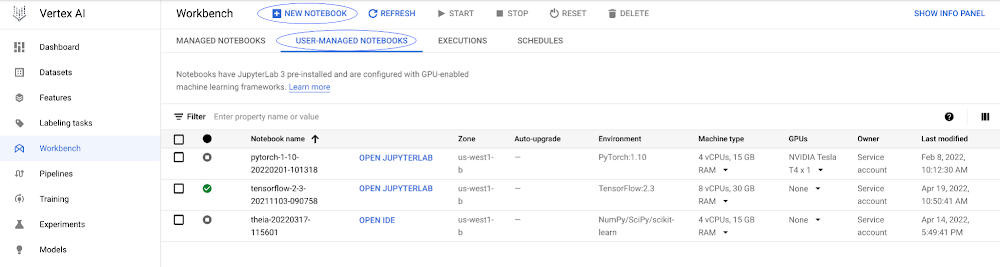
プリインストールされているディープ ラーニング パッケージ スイートの多くを選択することも、カスタム コンテナを選択することも可能です。この例では、GPU なしの TensorFlow Enterprise 2.7 イメージを選択し、[作成] を選択します。
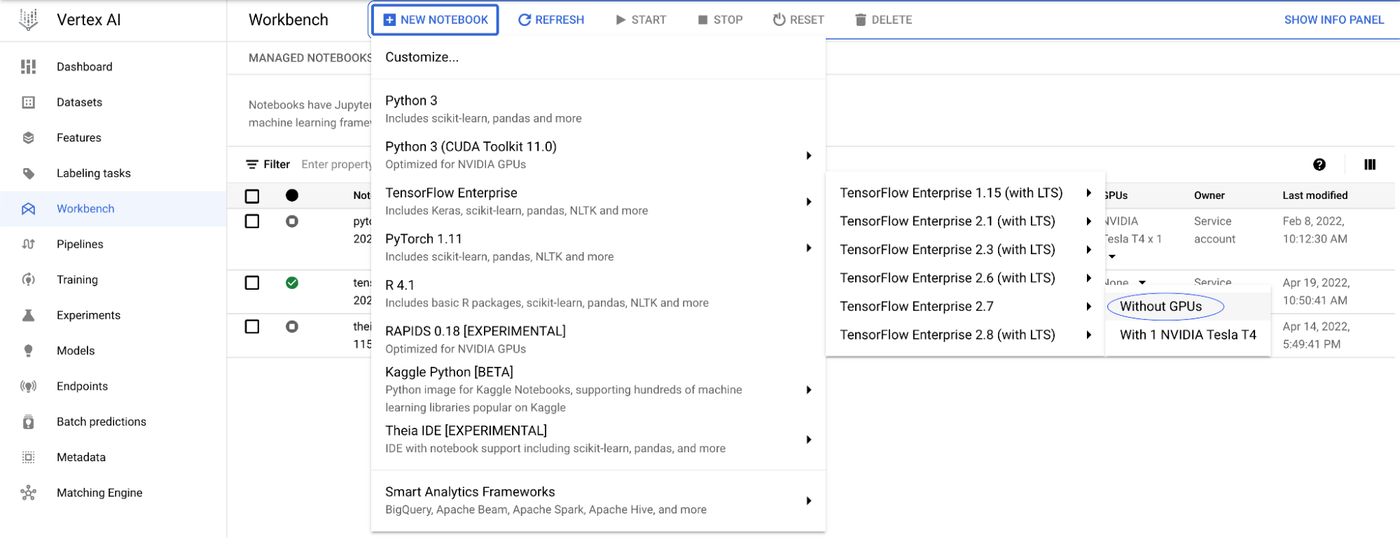
ノートブックの準備ができたら、[Jupyterlab を開く] という青いボタンが表示されます。これをクリックすると、新しいブラウザ ウィンドウで Jupyter Notebook の環境が開きます。
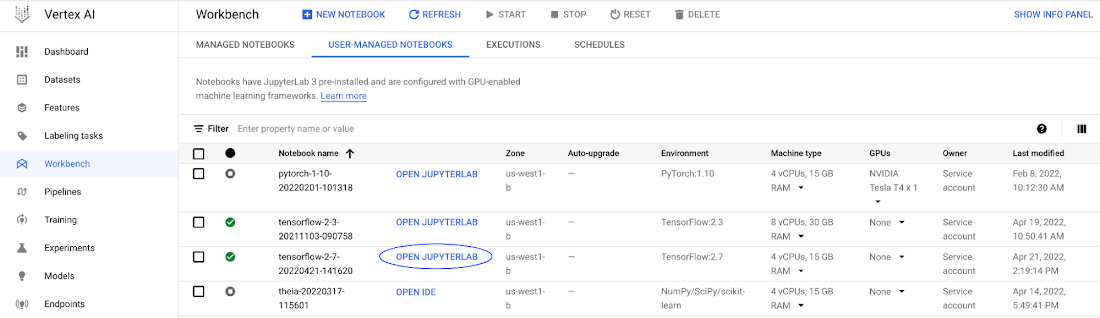
Launcher から新しいターミナル セッションを開きます。今回は Cloud Storage バケットをファイル システムとして Notebook にマウントするためのコマンドをいくつか実行します。

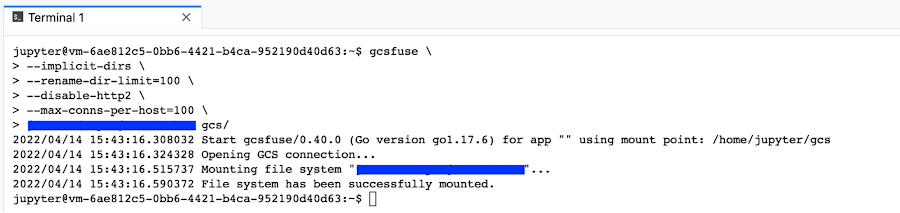
ターミナル ウィンドウで、gcsfuse というコマンドを実行して、gcsfuse がインストールされていることを確認します

マウントしたいバケット名を、プロトコル識別子(ここでは gs://)を省略してコピーします。例えば、バケットが gs://my-cloud-bucket であれば、my-cloud-bucket をコピーします。
バケット名をコピーしたら、ターミナル ウィンドウで以下のコマンドを実行します。この例では、コピーしたバケット名「my-cloud-bucket」を、gcsfuse コマンドのパラメータとして貼り付け、最終行の gcs ディレクトリに変数を使ってマッピングしています。
MY_BUCKET=my-cloud-bucket
cd ~/ # /home/jupyter/ に移動する
mkdir -p gcs # マウント ポイントとして使用するフォルダを作成する
gcsfuse --implicit-dirs \
--rename-dir-limit=100 \
--disable-http2 \
--max-conns-per-host=100 \
$MY_BUCKET "/home/jupyter/gcs"
Workbench Notebook インスタンスから、Cloud Storage バケット ファイルに、まるでローカルにあるかのようにアクセスできるようになりました。Jupyter Notebooks を Cloud Storage のバケットから作成し、実行することも可能です。
Cloud Storage プロジェクト内のすべてのバケットをマウントしたい場合は、gcsfuse を使用する際にバケット名を省略できます。
cd ~/ # /home/jupyter/ に移動する
mkdir -p gcs # マウント ポイントとして使用するフォルダを作成する
gcsfuse --implicit-dirs \
--rename-dir-limit=100 \
--disable-http2 \
--max-conns-per-host=100 \
"/home/jupyter/gcs/"
この場合、バケットにはフルパスでアクセスする必要があります。例えば、次のようになります。
with open("gcs/my-cloud-bucket/area_cover_dataset.csv",'r') as f:
print(f.read())
起動スクリプトを使用する場合は、以下の投稿にサンプルがあります。
Cloud Storage バケットをマウントしたことで、コピーの作成や、データの整合性を気にすることなく、直接データを読み込むことができるようになりました。
- エンタープライズ AI ML カスタマー エンジニア、 Juan Acevedo




