BigQuery における SAP データ モデリングの設計上の考慮事項

Google Cloud Japan Team
※この投稿は米国時間 2021 年 7 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
ここ数年、多くの組織が SAP ソリューションを Google Cloud へ移行し、その恩恵を受けています。しかし、この移行は IT のメンテナンス費用を削減し、データの安全性を高めるだけではありません。BigQuery では、強力なデータセットと Google の機械学習を利用して、エンタープライズ データを統合し、容易に拡張することができるため、SAP のお客様は、SAP への投資をさらに活用し、最新の分析情報を得ることができます。
BigQuery は、フルマネージドでサーバーレスの、市場をリードするクラウド データ ウェアハウスで、ペタバイト規模のクエリに超高速で対応します。SAP データと、Google アナリティクスや Salesforce などの追加のデータソースを簡単に統合できます。また、組み込みの機械学習によって、ユーザーは標準 SQL を使用した機械学習モデルを比較的低いコストで運用できます。
SAP を活用している組織が、BigQuery の強みを生かした分析を目指している場合、以下に紹介する SAP データを使用したモデリングの考慮事項と推奨事項が有用です。こうしたガイドラインは、Google のお客様における実際の導入事例に基づいて作成されたもので、お客様のビジネスが必要とする分析機能を得るためのロードマップとしてお使いいただけます。
データ レプリケーションに関する考慮事項
多くのテクノロジーに関する取り組みと同様、考慮事項の構成はビジネスの目標を立てることから始まります。お客様が意図するビジネスの価値と目標を維持することは、設計プロセスの初期段階で適切な判断を下すために非常に重要です。
SAP システムから BigQuery にデータをレプリケートする方法は複数あります。次の質問に答えて、組織にとって最適な方法を決めてください。
ビジネスにリアルタイム データが必要か。過去のデータを掘り起こして活用する必要があるか。
レプリケートされたデータと、どの外部データセットを統合する必要があるか。
ソース構造またはビジネス ロジックに変更がありそうか。SAP ソースシステムをすぐ移行する予定があるか。たとえば、SAP ECC を SAP S/4HANA に移行するなどの予定があるか。
また、レプリケーションをテーブル単位で行うか、チームが事前に構築したロジックから調達するか決める必要もあります。この決定は、ライセンスなどの他の考慮事項とともに、使用するレプリケーション ツールに影響します。
テーブル単位でのレプリケーション
テーブル、特に標準テーブルをそのままの形式でレプリケートする場合、ソースを再利用でき、ソース構造と機能出力の安定性が増します。たとえば、販売注文ヘッダー用の SAP テーブル(VBAK)は、SAP のバージョンが違っても構造が変わる可能性はとても低く、テーブルに書き込む際のロジックも、レプリケートされたテーブルに影響するような変更の可能性はほとんどありません。
他に、生のテーブルと比較したときに、BigQuery におけるソースシステムとランディング テーブルの間の調整が線形であることを考慮する必要があります。線形であるため、期末の決算など、重要なビジネス プロセスの最中に統合を行う際に問題の発生を防ぐことができます。レプリケートされたテーブルは集計されず、プロセス固有のデータ変換を条件としていないため、同様にレプリケートされた列も別の BigQuery ビューで再利用できます。たとえば、MARA テーブル(マテリアル マスター)を一度レプリケートすれば、これを必要な数のモデルで使用できます。
事前に構築されたロジックのレプリケーション
SAP エクストラクタや CDS ビューからのモデルなど、事前に構築されたモデルをレプリケートする場合、既存のロジックを使用しているので、BigQuery にロジックを構築する必要はありません。こうして抽出されたオブジェクトの一部には埋め込み型の差分処理メカニズムがあり、差分を処理できないレプリケーション ツールを補完できます。これで初期の開発時間を節約できますが、新しい列を作成する場合や、カスタマイズやアップグレードで抽出の背後にあるロジックに変更があると、問題が生じる可能性があります。
さまざまな抽出プロセスで、同じソースの列が複数回変換され読み込まれることがありますので注意してください。この場合、BigQuery に冗長性が生じ、メンテナンスのニーズが増え、費用がかさむことがあります。ただし、事前に構築されたモデルのレプリケーションは、階層のフラット化や極めて複雑なロジックなど、変更できないことの多いロジックでは有効な場合があります。
レプリケーションにどのようにアプローチするかは、お客様の長期的計画と、その他の重要な要素(デベロッパーの時間的余裕(どれほど関心を持って取り組めるか)、SQL の知識を新しいデータ ウェアハウスに適用するためにデベロッパーがどれほどの時間と労力を注げるかなど)によって異なります。
どちらのレプリケーション アプローチでも、レプリケーション プロセスを設計する場合には、BigQuery が常時追加のデータベースであることに注意してください。そのため、データの後処理と変更が、どちらの場合にも必要です。
データ変更の処理
選択したレプリケーション ツールによって、データの変更をキャプチャする方法も決まります(CDC(変更データ キャプチャ)として知られています)。レプリケーション ツール(SAP SLT など)によっては、CDC と BigQuery 関連ドキュメントで説明している同じパターンが SAP データに適用できます。
トランザクションのような一部のデータは他のデータ(マスターデータなど)に比べて静的でないことが明らかなため、リアルタイムのスキャンが必要なデータ、即時整合性が必要なデータ、コスト管理のためバッチで処理できるデータを決定する必要があります。この決定は、ビジネスのレポート作成のニーズに基づいて行われます。
ビジネス パートナー向けのサンプル マスターデータを含む、SAP テーブル BUT000 で考えてみましょう。このテーブルでは、SAP ERP システムからの変更をレプリケートしています。
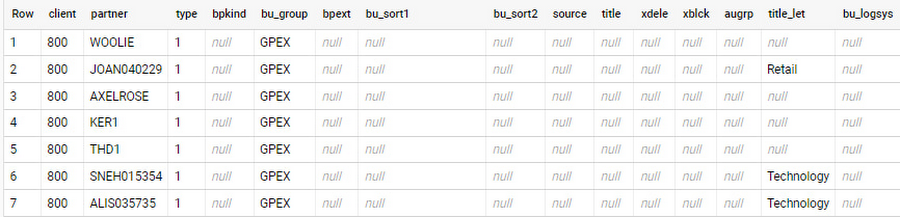
BigQuery の常時追加のレプリケーションでは、すべての更新は新しいレコードとして受信されます。たとえば、ソース内のレコードを削除すると、BigQuery では削除フラグ付きで新しいレコードとして表されます。これは、レコードの発生元が BUT000 のような生テーブルである場合にも、BW エクストラクタや CDS ビューなどの事前に集計されたデータである場合にも当てはまります。
パートナーの「LUCIA」と「RIZ」が発生元のデータを詳しく見ていきましょう。オペレーション フラグは、BigQuery の新しいレコードが挿入(I)、更新(U)、削除(D)のいずれかを示しています。タイムスタンプで、ビジネス パートナーの最新バージョンを特定できます。
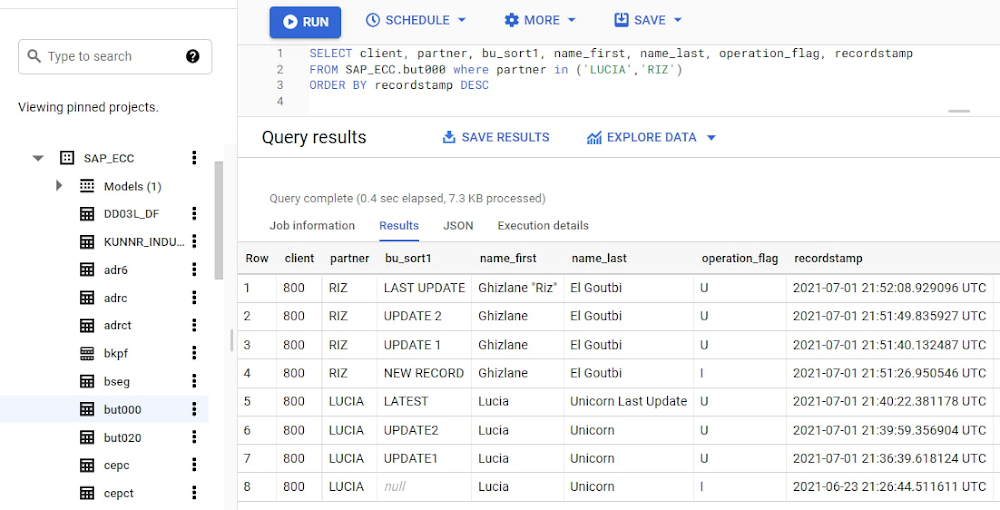
パートナーの LUCIA と RIZ で、最後に更新されたレコードを見つけたい場合のクエリは次のようになります。
結果は次のとおりです。
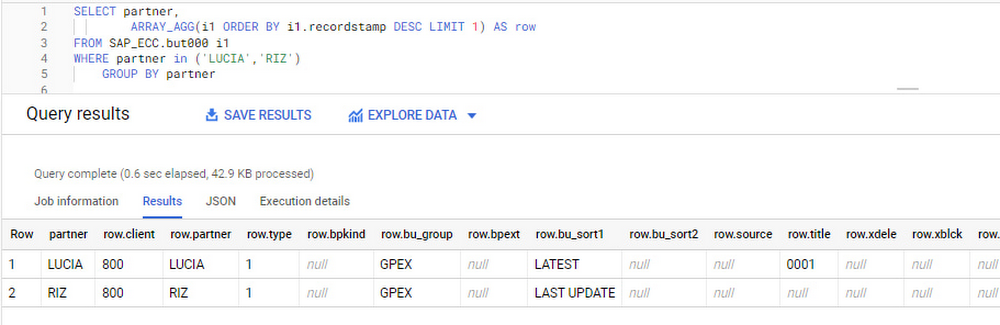
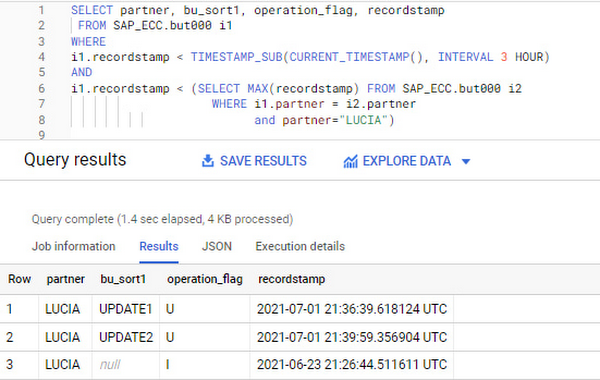
ビジネス パートナー「LUCIA」と「RIZ」の古いレコードを特定後、履歴を保存しておく必要がないのであれば、「LUCIA」の古いレコードをすべて削除するステップに進みます。この例では、結果比較のため、また、削除対象とした古いレコードすべてが削除され、最後に更新されたレコードのみ保持しているか確認するため、同じレプリケーションが実施された別のテーブルを使用しています。例:
削除を続行する前に、パートナー「LUCIA」の古いレコードを取り出すには、次のクエリも使用できます。
最後に更新されたレコード以外の、すべてのレコードが生成されます。
パーティショニングとクラスタリング
クエリでスキャンされるレコードの数を制限し、コストを抑えて最善のパフォーマンスを達成するには、パーティションを決め、クラスタを作成するという 2 つの重要なステップが必要です。
パーティショニング
パーティション分割テーブルは、パーティションと呼ばれるセグメントに分割されたテーブルです。データの管理とクエリ実行が容易になります。大規模なテーブルを小さなパーティションに分割すると、クエリごとに読み込まれるバイト数が減るため、クエリのパフォーマンスが向上し、コスト管理につながります。
BigQuery テーブルを分割する方法は次のとおりです。
時間単位列: 「timestamp」、「date」、「datetime」列に基づいてテーブルが分割されます。
取り込み時間: BigQuery がデータを取り込んだ際に記録されたタイムスタンプに基づいてテーブルが分割されます。
整数範囲: テーブルは整数列に基づいて分割されます。
以下の例のように、テーブルが作成された際にパーティションが有効になります。このクエリの左側に示すように、パーティション フィルタを組み込むことをおすすめします。
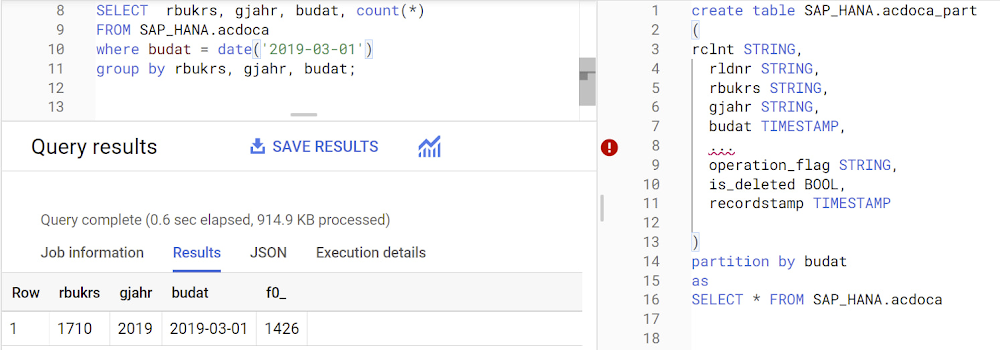
クラスタリング
クラスタリングは、フィルタリングに使用される可能性の高いフィールドを適用することで、パーティション分割テーブルと合わせて作成できます。BigQuery でクラスタ化テーブルを作成すると、テーブルのスキーマ内の 1 つ以上の列のコンテンツに基づいて、テーブルデータが自動的に分類されます。指定した列は、関連するデータを同じ場所に配置するために使用されます。
クラスタリングを行うと、フィルタ句を使用するクエリやデータを集計するクエリなど、特定のタイプのクエリのパフォーマンスを向上できます。SAP S/4HANA の会計ドキュメント用テーブルである ACDOCA などの大規模なテーブルに使用することを強くおすすめします。このケースでは、タイムスタンプがパーティショニングに使用できます。台帳、企業コード、会計年度などの一般的なフィルタリング フィールドで、クラスタを定義します。

また、BigQuery はデータの自動再クラスタ化を定期的に行うのでとても便利です。
マテリアライズド ビュー
BigQuery のマテリアライズド ビューは事前に計算されたビューで、より良いパフォーマンスと効率を得るためにクエリの結果を定期的にキャッシュに保存します。BigQuery は、事前に計算されたマテリアライズド ビューの結果を使用し、可能な場合には必ずベーステーブルからの差分のみを読み取って最新の結果を迅速に計算します。マテリアライズド ビューに直接クエリを発行できるのはもちろん、ベーステーブルに対するクエリを処理するために BigQuery オプティマイザーでマテリアライズド ビューを使用することもできます。
マテリアライズド ビューを使用したクエリは通常、同じデータをベーステーブルのみから取得するクエリよりも速く完了し、消費するリソースも少なくて済みます。ワークロードのパフォーマンスが問題の場合、マテリアライズド ビューを使用すると、よく使うクエリを何度も繰り返し使用するワークロードのパフォーマンスを大幅に向上できます。マテリアライズド ビューがサポートするのは現在のところ単一のテーブルのみですが、ストックレベルや受注フルフィルメントなどの、一般的でよく使われる集計では非常に便利な機能です。
SELECT ステートメントの作成でパフォーマンスを最適化するためのヒントについては、クエリ計算の改善のドキュメントをご覧ください。
デプロイメントのパイプラインとセキュリティ
BigQuery で実施する大半の作業では通常、2 つ以上のデリバリー パイプラインが稼働しています。1 つは BigQuery の実際のオブジェクトに対応し、もう 1 つは変更データ キャプチャ フロー内で意図したとおりにデータのステージングとデータの変換を保持して、最新の状態に保つために使用されます。継続的インテグレーション / 継続的デプロイ(CI / CD)パイプラインに、ほとんどの既存のツールを使用できます。これは BigQuery のようなオープン システムを使用するメリットの 1 つです。CI / CD パイプラインの使用が初めての組織には、段階的に経験を積める絶好の機会です。まず、データ処理ワークフロー用の CI / CD パイプラインの設定をご覧ください。
アクセスとセキュリティに関しては、大半のエンドユーザーは BigQuery ビューの最終バージョンにのみアクセスできます。SAP ソースシステムの場合のように行と列レベルのセキュリティが適用されますが、さまざまな Google Cloud プロジェクトや BigQuery データセット間でデータを分割することで、問題をさらに分離することができます。データセット間でデータと構造をレプリケートするのは簡単ですが、始めから適切にセットアップができるよう、設計プロセスの初期段階で要件と命名規則を定義することをおすすめします。
これまでよりも迅速に、多くの知見を得られる分析を始めましょう
この機会に BigQuery をぜひお試しください。SQL の知識のあるユーザーは誰でも、BigQuery の無料枠を使用して開始できます。新規のお客様には、最初の 90 日間に Google Cloud で使用できる無料クレジット $300 分を差し上げます。すべてのお客様は、10 GB のストレージと 1 か月あたり最大 1 TB のクエリを無料で利用できます。膨大な処理能力、組み込み型の機械学習、複数の統合ツール、コスト面のメリットに加え、BigQuery により分析タスクがどれほど簡単になるか、ぜひご自身でお確かめください。
さらにサポートが必要な場合は、Google Cloud プロフェッショナル サービス部門(PSO)と、カスタマー エンジニアにお問い合わせください。お客様に最も合ったサポートを提供いたします。ご不明な点は cloud.google.com/contact までお問い合わせください。

-ソリューション マネージャー Lucia Subatin
-Google Cloud スマート アナリティクス カスタマー エンジニア Ghizlane El Goutbi

