Google API を使用した画像のアーカイブ、分析、レポート生成
Google Cloud Japan Team
※この投稿は米国時間 2020 年 12 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
ファイルのバックアップはそれほど関心度の高いトピックではありませんが、AI / ML を使用した画像分析は注目を集めています。これらを組み合わせたワークフローを考え付く人は少ないかもしれません。ファイルのバックアップを画像分析で補強することで、より利便性の高いソリューションを構築することができます。Google はこの目的を実現するために使用できる多様なデベロッパー ツールを提供していて、実際にこうしたワークフローを Google Cloud のツールだけで構築できます。さらに、Google のテクノロジーを組み合わせる際の基本原則は、開発者、企業、顧客が直面する他の多くの課題にも応用できるため、非常に有益です。
提示されているサンプルアプリには、Google ドライブ、スプレッドシート、Cloud Storage、Vision が使用されています。ユースケース: マルチメディア ファイルが絶えず生成される建築や広告などの産業に従事する Google Workspace(旧 G Suite)のユーザー。すべてのクライアント ジョブによってドライブの別のサブフォルダが作られ、アセット ファイルのコレクションが生成されます。連続するプロジェクトでは、さらに多くのファイルとフォルダが生成されます。ある時点でドライブは混乱状態になり、効率性が低下し、必要なファイルを探すのにいつまでもスクロールしなければならなくなります。
これには Google Cloud をどのように活用できるでしょうか。Google ドライブのように、Cloud Storage はクラウドにファイル(および汎用 blob)ストレージを提供します(Google ドライブと Cloud Storage の違いに関する詳細は、こちらの動画でご確認ください)。
Cloud Storage はアーカイブ ファイルにアクセスする頻度に応じて複数のストレージ クラスを提供します。ファイルへのアクセス頻度が少ないほど、ストレージは「よりコールド」になり、コストも低くなります。1 つのプロジェクトから別のプロジェクトへ進むと、以前のドライブ フォルダはそれほど必要ではなくなるため、これらは Cloud Storage へのバックアップの候補として適しています。
最初の課題: セキュリティ モデルを決定する。Google Cloud API を使用する際は通常、ユーザーが所有するデータへのアクセスには OAuth クライアント ID を選択し、アプリケーションやプロジェクトが所有するデータへのアクセスにはサービス アカウントを選択します。前者は一般に Workspace API とともに使用します。後者は Google Cloud API にアクセスするための主要な方法です。ここでは両方のプロダクト グループの API を使用しているため、決定を行う必要があります(今どちらかを選択し、後で必要に応じて変更)。
目標はシンプルな概念実証であるため、ユーザー認証で十分です。OAuth クライアント ID は Drive API と Sheets API へのアクセスの標準で、Vision API は API キーのみを必要とするため、より安全な OAuth クライアント ID があれば十分条件を満たします。スクリプトを実行しているユーザーが獲得できる IAM 権限は、目的の Cloud Storage バケットへの書き込みアクセス権を取得することだけです。最後に、Workspace API には自身のプロダクト クライアント ライブラリが(まだ)ないため、より低いレベルの Google API「プラットフォーム」クライアント ライブラリが 4 つの REST API のすべてにアクセスするための「最小の共通分母」の役割を担います。Cloud クライアント ライブラリを使用して Cloud Storage コードまたは Vision コードを書き込んだ場合は、少々異なります。
プロトタイプはコマンドライン スクリプトです。実際には、クラウド内のアプリケーションである可能性が高く、Cloud Scheduler で指定されたとおりに実行する Cloud Functions の関数または Cloud Task として実行されます。その場合、ワークスペース ドメイン全体の委任でサービス アカウントが使用され、従業員の代理として機能し、ファイルをバックアップします。こちらのページで、このタイプの委任をどのような場合に使用するか(あるいは使用しないか)について説明したドキュメントをご確認ください。
この例ではシンプルなプロトタイプが個別の画像ファイルを対象にしていますが、必要に応じてさらに進化させ、複数のファイル、ムービー、フォルダ、ZIP アーカイブをサポートさせることが可能です。各関数は異なる API を呼び出し、画像を処理する「サービス パイプライン」を作成します。関数の最初のペアは drive_get_file() と gcs_blob_upload() です。前者はドライブ上の画像に対してクエリを実行し、関連するメタデータ(ファイル名、ID、MIMEtype、サイズ)の取得と、バイナリ「blob」のダウンロードを行い、それらすべてを呼び出し元に返します。後者は関連するメタデータと一緒にバイナリを Cloud Storage にアップロードします。簡潔にするためにスクリプトは Python で書かれていますが、クライアント ライブラリは一般的な言語のほとんどをサポートしています。以下は前述の関数の擬似コードです。
次に、vision_label_img() が Vision API にバイナリを渡し、結果をフォーマットします。最終的にその情報が、ファイルのアーカイブされた Cloud Storage の場所と一緒に、sheet_append_row() によって Google スプレッドシートに 1 行のデータとして書き込まれます。
最後に、ワークフローを実行する「メイン」のプログラムが必要です。これにはファイルサイズをキロバイトに変換する _k_ize() と、有効な Cloud Storage ハイパーリンクをスプレッドシートの数式として構築する _linkify() という 2 つのユーティリティ関数が備わっています。これらを以下に示します。
この投稿では擬似コードのみを示していますが、基本的な作業バージョンは実際の Python のコード 80 行以内で完了します。コードのうち表示されていない部分は定数、エラー処理、その他の補助サポートです。このアプリケーションは main() への呼び出しで起動し、ファイル名、アーカイブする Cloud Storage バケット、スプレッドシート用のドライブ ファイル ID、ディレクトリまたは ZIP アーカイブなどの「フォルダ名」を渡します。数回実行すると、スプレッドシートは以下のようになります。
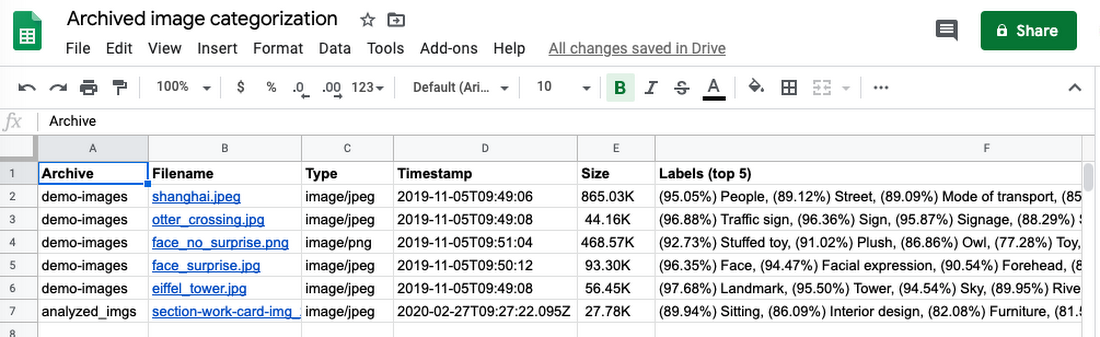
Google の「Codelab」を使用すると、順を追ってこのアプリケーションを作成できます。Codelab は自分のペースに合わせて学べる無料のオンライン チュートリアルで、こちらからアクセスできます。このチュートリアルを進めると、対応するオープンソース リポジトリ機能がそれぞれのステップにフォルダを分けるため、各関数の実装後にアプリがどのような状態になるかを理解できます(注: ファイルは削除されないため、ユーザーはドライブ フォルダをいつクレンジングするか指定する必要があります)。下位互換性のために、スクリプトは旧バージョンの Python Auth クライアント ライブラリを使用して実装されています。ただし、リポジトリには「alt」フォルダがあり、これにはサービス アカウント、Google Cloud クライアント ライブラリ、より新しいバージョンの Python Auth クライアント ライブラリを使用した、別バージョンの最終スクリプトが使用されています。
最後に、便利なリンクを紹介します。Google ドライブ、Cloud Storage、Cloud Vision、Google スプレッドシートの API ドキュメントのページをご確認ください。このサンプルアプリはリソースの制約の問題に対処していますが、Google デベロッパー ツールを使用して何を行えるかを考えるうえでのヒントになります。ユーザーの利便性を高める独自のソリューション構築にお役立てください。
-デベロッパー アドボケイト Wesley Chun



