Image archive, analysis, and report generation with Google APIs
Wesley Chun
Developer Advocate
File backup isn't the most exciting topic, while analyzing images with AI/ML is more interesting—so combining them probably isn't a workflow you think about often. However, by augmenting the former with the latter, you can build a more useful solution than without. Google provides a diverse array of developer tools you can use to realize this ambition, and in fact, you can craft such a workflow with Google Cloud products alone. More compellingly, the basic principle of mixing-and-matching Google technologies can be applied to many other challenges faced by you, your organization, or your customers.
The sample app presented uses Google Drive and Sheets plus Cloud Storage and Vision to make it happen. The use-case: Google Workspace (formerly G Suite) users who work in industries like architecture or advertising, where multimedia files are constantly generated. Every client job results in yet another Drive subfolder and collection of asset files. Successive projects lead to even more files and folders which can lead to users needing to scroll longer to find what they're looking for.
How can Google Cloud help? Like Drive, Cloud Storage provides file (and generic blob) storage in the cloud. (More on the differences between Drive & Cloud Storage can be found in this video.)
Cloud Storage provides several storage classes depending on how often you expect to access your archived files. The less often files are accessed, the "colder" the storage, and the lower the cost. As users progress from one project to another, they're not as likely to need older Drive folders and those make great candidates to backup to Cloud Storage.
First challenge: determine the security model. When working with Google Cloud APIs, you generally select OAuth client IDs to access data owned by users and service accounts for data owned by applications/projects. The former is typically used with Workspace APIs while the latter is the primary way to access Google Cloud APIs. Since we're using APIs from both product groups, we need to make a decision (for now and change later if desired).
Since the goal is a simple proof-of-concept, user auth suffices. OAuth client IDs are standard for Drive & Sheets API access, and the Vision API only needs API keys so the more-secure OAuth client ID is more than enough. The only IAM permissions to acquire are for the user running the script to get write access to the destination Cloud Storage bucket. Lastly, Workspace APIs don't have their own product client libraries (yet), so the lower-level Google APIs "platform" client libraries serve as a "lowest common denominator" to access all four REST APIs. Those who have written Cloud Storage or Vision code using the Cloud client libraries will see something different.
The prototype is a command-line script. In real life, it would likely be an application in the cloud, executing as a Cloud Function or a Cloud Task running as determined by Cloud Scheduler. In that case, it would use a service account with Workspace domain-wide delegation to act on behalf of an employee to backup their files. See this page in the documentation describing when you'd use this type of delegation and when not to.
Our simple prototype targets individual image files, but you can continue to evolve it to support multiple files, movies, folders, and ZIP archives if desired. Each function calls a different API, creating a "service pipeline" with which to process the images. The first pair of functions are drive_get_file() and gcs_blob_upload(). The former queries for the image on Drive, grabs pertinent metadata (filename, ID, MIMEtype, size), downloads the binary "blob" and returns all of that to the caller. The latter uploads the binary along with relevant metadata to Cloud Storage. The script was written in Python for brevity, but the client libraries support most popular languages. Below is the aforementioned function pseudocode:
Next, vision_label_img() passes the binary to the Vision API and formats the results. Finally that information along with the file's archived Cloud Storage location are written as a single row of data in a Google Sheet via sheet_append_row().
Finally, a "main" program that drives the workflow is needed. It comes with a pair of utility functions, _k_ize() to turn file sizes into kilobytes and _linkify() to build a valid Cloud Storage hyperlink as a spreadsheet formula. These are featured here:
While this post may feature just pseudocode, a barebones working version can be accomplished with ~80 lines of actual Python. The rest of the code not shown are constants, error-handling, and other auxiliary support. The application gets kicked off with a call to main() passing in a filename, the Cloud Storage bucket to archive it to, a Drive file ID for the Sheet, and a "folder name," e.g., a directory or ZIP archive. Running it several times results in a spreadsheet that looks like this:
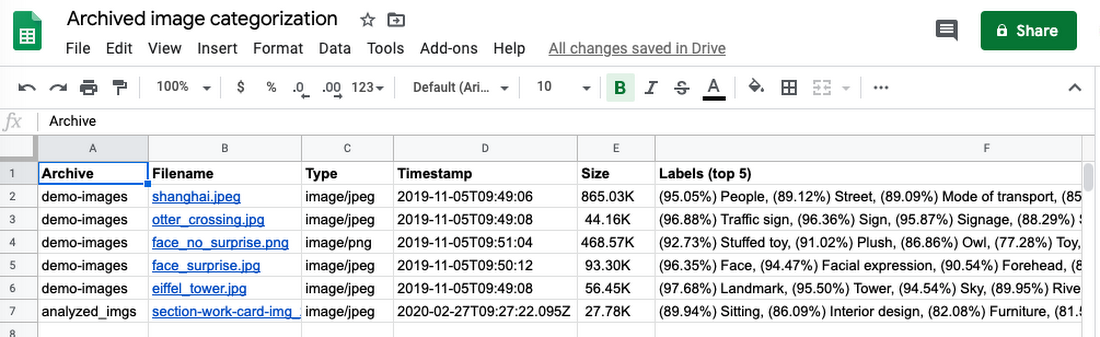
Developers can build this application step-by-step with our "codelab"—codelabs are free, online, self-paced tutorials—which can be found here. As you journey through this tutorial, its corresponding open source repo features separate folders for each step so you know what state your app should be in after every implemented function. (NOTE: Files are not deleted, so your users have to decide when to their cleanse Drive folders.) For backwards-compatibility, the script is implemented using older Python auth client libraries, but the repo has an "alt" folder featuring alternative versions of the final script that use service accounts, Google Cloud client libraries, and the newer Python auth client libraries.
Finally to save you some clicks, here are links to the API documentation pages for Google Drive, Cloud Storage, Cloud Vision, and Google Sheets. While this sample app deals with a constrained resource issue, we hope it inspires you to consider what's possible with Google developer tools so you can build your own solutions to improve users' lives every day!



