Data Studio と BigQuery を使った BI ダッシュボードの作り方
Google Cloud Japan Team
このシンプルなソリューションを使えば、GCP 上に BI ダッシュボードを簡単に作れます。
ビジネス インテリジェンス(BI)が登場したときから、可視化ツールは、データからすばやく知見を獲得したいアナリストや意思決定権者のために重要な役割を果たしてきました。
ビッグデータ アナリティクスの時代になった今も、その前提は変わりません。Google Cloud Platform(GCP)は、ビッグデータの上に BI ダッシュボードを構築するための統合プラットフォームとして、ペタバイト規模のデータを高速に分析できるクラウド ネイティブなデータ ウェアハウス Google BigQuery と、美しいレポートをすばやく作れる無料の Google Data Studio を提供しています(Google のパートナー企業である Looker や Tableau、Zoomdata なども BigQuery の上で動作する有料の可視化ツールを提供していますが、それはまた別の機会に紹介します)。
この投稿では、Data Studio をフロントエンドとし、BigQuery をバックエンド エンジンとする BI ダッシュボードの作り方を説明します(処理効率を上げるために、Google App Engine の助けも少し借ります)。
なお、記事の内容を理解するには、これらの製品に関するある程度の知識が必要となります。詳細については関連ドキュメント(BigQuery の概念、Data Studio の概要、App Engine の概念)を参照してください。
ユース ケースとソリューションの概要
顧客のインタラクション データを基に重要な決定を下しているオンライン小売業の会社があると仮定しましょう。そのデータは大量(数 TB)のログという形で、BigQuery データセットの日付でパーティション分割されている usage というテーブルに格納されています。このデータからできるだけ早くビジネス バリューを引き出すため、データの傾向やパターンを可視化するアナリスト向けのダッシュボードを構築することを考えます。
幸いなことに、BigQuery に格納されたデータに Data Studio から直接クエリを送れるコネクタを利用できます。Data Studio はクエリの結果をキャッシュしますが、ダッシュボード エディタでダッシュボードをリフレッシュしたり、ユーザーがキャッシュにない結果をフィルタリングしたりすると、新たなクエリが実行されます。usage データセットには細かいログが多数格納されており、その容量は数 TB にも上るため、それに対してクエリを実行するとなると、とてもコストが高くなります。
ただし、この問題はうまく回避できます。ダッシュボードには usage からの集計が表示されますが、オーダー ID といったレベルの詳細情報まで表示する必要はありません。そこで、ここではクエリに要するコストを下げるために、まず reports という別のデータセットにログをまとめてしまいます。
そして、Data Studio ダッシュボードからは、この reports データセットにクエリを送ります。そうすれば、ダッシュボードがリフレッシュされても、クエリが処理するデータは少なくなります。しかも、過去のログはもう変更されないので、reports データセットには新しい usage データだけをリフレッシュするだけで済みます。
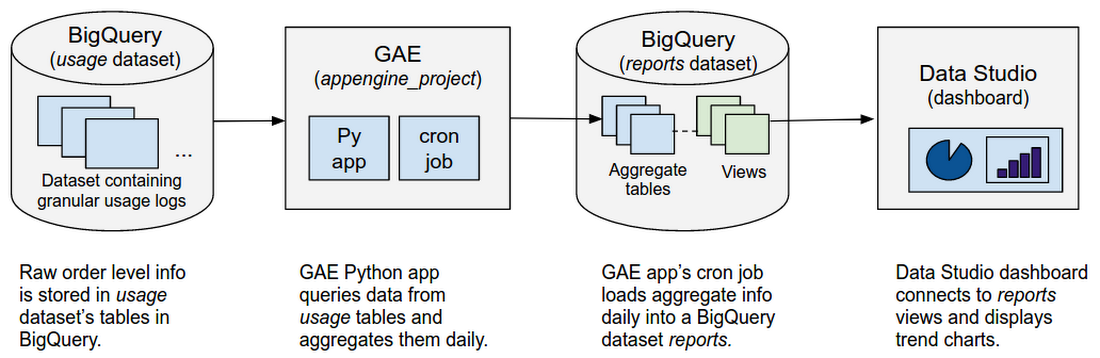
このソリューションをステップ バイ ステップで見ていきましょう。
ステップ 1 : BigQuery に集計データを格納する reports データセットを作る
BigQuery のウェブ UI を使用して、usage データセットと同じプロジェクトに reports という新しいデータセットを作ります。reports を作ることで、ダッシュボードからのクエリが相手にするデータが減り、集計データだけに関心を示すユーザーは無駄にソース データセットにアクセスしなくなります。ダッシュボードに表示する指標が決まったら、reports データセットに対応するテーブルを作ります。テーブルの作成には BigQuery のウェブ UI を使います。
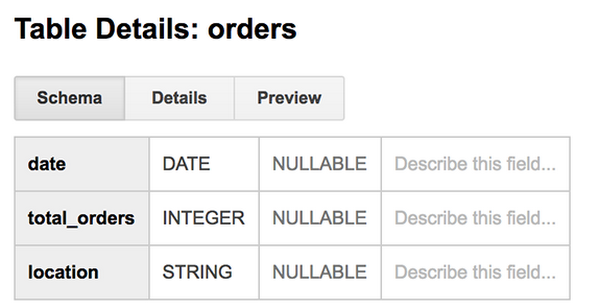
ここでは例として、日付と場所ごとに注文数を集計した reports.orders テーブルを作りました。
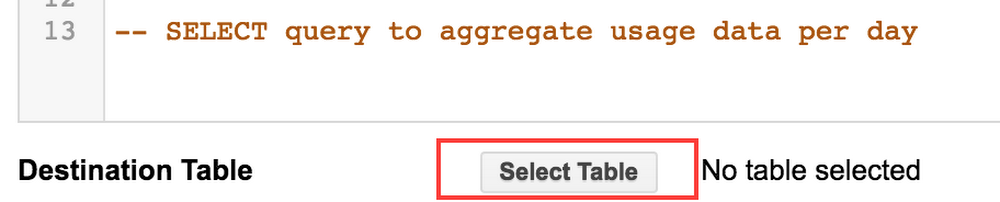
データセットとテーブルを作ったら、usage データセットから集計情報を取得して reports データセットのテーブルに書き込む 1 回限りのクエリを実行します。たとえば次のクエリは、場所別に過去 180 日間の 1 日ごとの注文数を取得します。
クエリの記述に使用する BigQuery ウェブ UI において、Destination Table として reports データセットを選択します。
利用状況の履歴データをいったん reports データセットに書き込めば、あとは最新の利用状況データで毎日更新をかけるだけです。次のステップでは、App Engine を使った更新の方法を説明します。
ステップ 2 : usage データセットにクエリを送り、結果を reports データセットにロードする App Engine アプリを作る
BigQuery にはクエリをスケジューリングする仕組みがありませんので、その代わりに、クエリを実行して結果を reports データセットにロードする App Engine アプリを作り、このアプリを cron ジョブで毎日実行します。BigQuery の Authorized Views 機能を使用すれば、必要に応じてデータセットへのアクセスを制限できます。ステップ 2a : まずは、前日の集計を usage データセットから取得するクエリの作成です。最初に、BigQuery ウェブ UI でクエリを記述し、正しく動作することを確認します。これは、指定された日に確定した注文数だけを計算する単純なクエリです。たとえば注文処理が今日であっても、確定が明日になれば、それは明日の total_orders に計上されます。
このクエリからビューを作成し、reports.daily_order_summary という名前で reports データセットに保存します。usage データセットの reports.daily_order_summary ビューには Authorized View アクセスを許可します。
ステップ 2b : 次に App Engine アプリを作成します。新たにプロジェクトを作っても、あるいは既存のプロジェクト ID を使ってもかまいません(アプリ作成の詳細は、こちらのサンプルをご覧ください)。
ステップ 2c : Cloud Console API Manager を開き、reports データセットへのクエリを実行するときに使用する App Engine のデフォルト サービス アカウントを作ります。作成したサービス アカウント名はメモしておいてください。
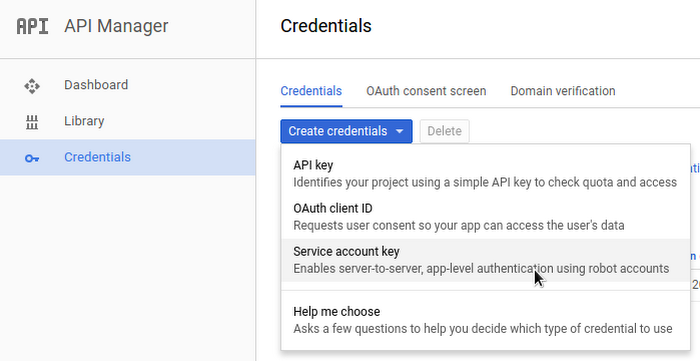
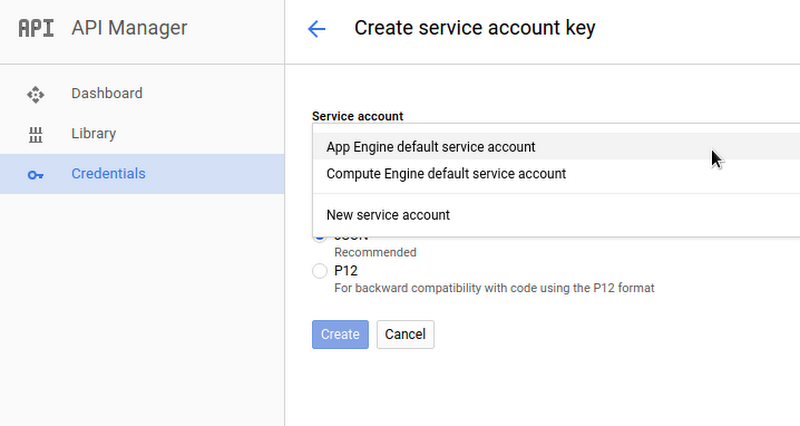
BigQuery ウェブ UI で、このサービス アカウントでの reports データセットの編集アクセスを許可します。
ステップ 2d : App Engine アプリで BigQuery API を使用し、ステップ 2a のクエリを実行します。その際の認証には Application Default Credentials を使用します。下の例では非同期クエリを使っています。クエリの出力は、writeDisposition: WRITE_APPEND によって reports テーブルに追加されます。
さらに、BigQuery DML の UPDATE を使用して reports データセットに履歴データを埋め戻したり、DELETE を使って reports データセットの履歴データを適宜削除したりすることも可能です。たとえば、過去 24 か月分のデータを reports データセットに保持したい場合は、24 か月以前のレコードを DELETE で削除できます。
ステップ 2e : アプリを毎日実行する cron ジョブを作成します。たとえば、アプリの cron.yaml に次の内容を追加します。
ステップ 3 : ダッシュボードに表示されるデータのビューを reports データセットに作る
以上で、集計データが毎日更新されて reports データセットに格納されるようになりました。次に、ダッシュボードに表示されるデータのビューを作成します。サンプルのビューには、場所ごとの注文数の月別トレンド、前月の注文数の合計、注文数が最も多かった場所をまとめた月別スコアカードが含まれています。この情報を抽出するクエリを書き、クエリからビューを作成します(たとえば、reports.monthly_order_trends と reports.monthly_scorecard)。そして、このビューに対する読み出しアクセス権限を関連ユーザーに付与します。
ステップ 4 : Data Studio で新しいデータ ソースを作る
ステップ 3 で作成した個々のビュー向けに、Data Studio で新しいデータ ソースを作ります。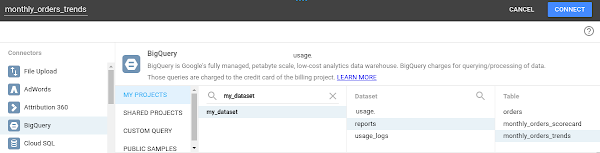
ステップ 5 : Data Studio で新しいレポートを作る
Data Studio で新しいレポートを作成し、ステップ 4 で作ったデータ ソースを追加します。月別トレンドは棒グラフを、前月の注文数、伸び率、注文数トップの場所はスコアカードを使って表示します。次に示すのは、このサンプルのために Data Studio で作成したレポートの例です。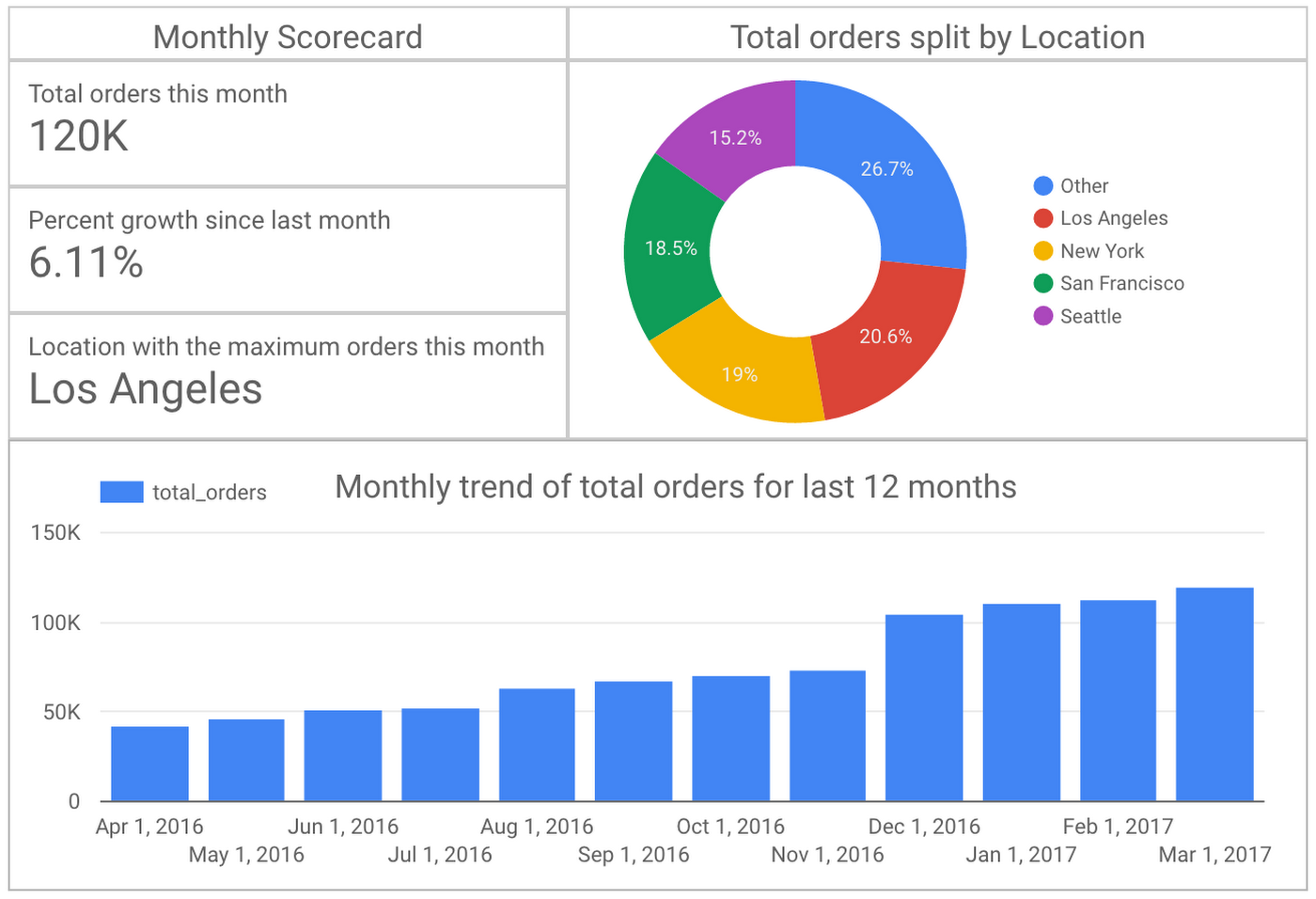
次のステップ
おめでとうございます。これで、(膨大な量のデータに対してクエリを実行するリスクを下げながら)顧客データのパターンを可視化する BI ダッシュボードの作り方がおわかりいただけたと思います。同じようなプロジェクトの詳細については次のリンクを参考にしてください。
- How to do cross-platform analytics with Google BigQuery(BigQuery を使ったクロスプラットフォーム アナリティクスの方法)
- API を使用して単純なアプリケーションを作成する
- Creating a Guestbook Application(App Engine を使ってゲストブック アプリケーションを作成する)
- Google Data Studio 360 を使用して BigQuery データを可視化する
* この投稿は米国時間 4 月 28 日、Google Cloud の Technical Program Manager である Pradnya Khadapkar によって投稿されたもの(投稿はこちら)の抄訳です。
- By Pradnya Khadapkar, Technical Program Manager, Google Cloud



