公開論文から学ぶ Google のテクノロジー : パート 3:データベース技術編

中井 悦司
ソリューションズ・アーキテクト, Google Cloud Japan
Google Cloud のサービスは、Google が長年にわたって構築してきたグローバルネットワーク、そして、世界各地のデータセンターによって提供されています。これは、Google 検索をはじめとするさまざまな Google のサービスを支えるインフラでもあり、その上では、Google 独自の技術を活用したさまざまなミドルウェアが稼働しています。
Google のエンジニアは、自分たちが開発した技術の詳細を論文として公開しており、これまでに公開された論文は、Google の研究チーム、Google Research の Web サイトにある Publication Database で検索できます。このブログシリーズでは、次の4つの分野に分けて、Google Cloud の技術に関連の深い論文を紹介していきます。
分散処理基盤(コンテナ技術)とデータセンター
ネットワーク技術
データベース技術
機械学習 / AI
このパート 3 では、データベース技術に関連した主要な論文を紹介します。なお、それぞれの論文は、公開時点での技術情報を伝えるものですので、今現在、Google のデータセンターで使用されている技術とは異なる場合もあるので、その点は注意してください。
Google Cloud を支えるデータベース技術
Google Cloud では、利用用途に応じたさまざまなデータベースがマネージドサービスとして利用できますが、その背後では、Google のエンジニアが長年に渡って開発、そして、改善を続けてきたデータベース技術が利用されています。ここでは、Google Cloud で利用できるデータベースサービスに関連の深い論文を紹介していきます。
検索エンジンのバックエンドとして開発された Bigtable
Google の中でも特に歴史の長いデータベース技術が Bigtable です。現在は、Cloud Bigtable として、Google Cloud でも利用可能なデータベースですが、元々は、検索エンジンのバックエンドデータベースとして開発されたことが次の論文で紹介されています。
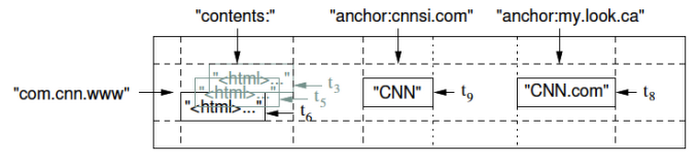
次の図は、論文からの引用で、Bigtable のデータモデル、すなわち、データを保存するテーブルの構造を説明するものですが、まさに、検索エンジンのクローラーが取得した HTML ファイルを保存する例になっています。
Bigtable は、テーブル全体を「Tablet」と呼ばれる単位に分割して、複数の Tablet サーバーが並列にアクセスすることで高いスケーラビリティを実現しています。論文の内容に基づいて、システム全体のアーキテクチャーを図示すると次のようになるでしょう。
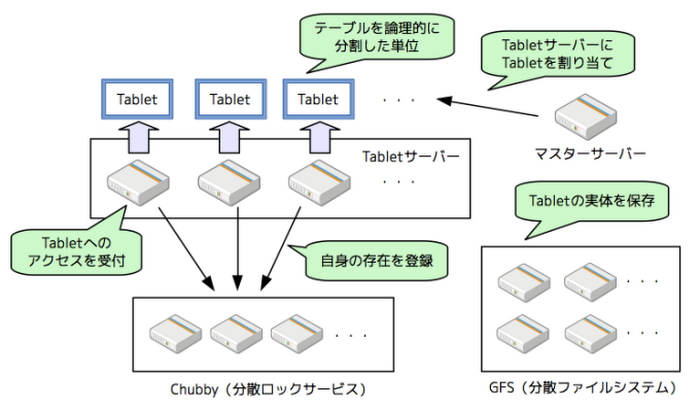
Tablet に書き込まれたデータは、Google が独自開発した分散ファイルシステム GFS に保存されているとありますが、現在、Google のデータセンターでは GFS は使用されておらず、次世代の分散ファイルシステム Colossus に移行しています。GFS から Colossus へのデータ移行は重要なプロジェクトでしたが、データを読み書きする Tablet サーバーとデータを保存する実体である GFS が分離された構造のため、Bigtable の利用者に影響を与えずに完了することができました。
テーブルを Tablet に分割して分散処理するアーキテクチャーは、この後で紹介する Spanner でも採用されており、Bigtable のアーキテクチャーは、Google の分散データベース技術の基礎になったと言えるでしょう。
データウェアハウス:BigQuery
Google Cloud で利用できるデータウェアハウスサービス Cloud BigQuery は、Google 社内では、Dremel という名前のツールとして利用されてきました。Dremel のアーキテクチャーは、2011 年の次の論文で初めて紹介されています。
Dremel が開発される以前の Google では、大量のデータを分析する際は、Bigtable をはじめとする NoSQL データベースや MapReduce によるバッチ処理を使用していましたが、データ処理システムに関する専門知識を持たない一般的なアナリストには使用が難しいという課題がありました。そこで、SQL を利用して大規模データの分析を行うツールとして、Dremel が開発されました。
計算リソースとストレージを分離して、高速なデータセンターネットワークで接続するというアーキテクチャーは、先ほどの Bigtable に類似しており、初期の Dremel は、当時の Bigtable と同様にストレージとして GFS を使用していました。その後、Dremel は、SQL によるデータ分析に特化したシステムとして、さまざまな改善やアーキテクチャーの変更が加えられてきました。2020 年までの約 10 年間に渡る Dremel の進化については、次の論文に詳しい説明があります。
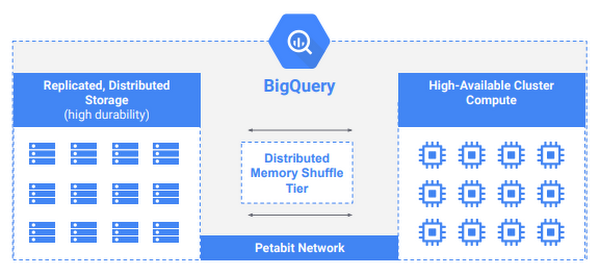
この中では、Dremel 専用のカラム型データストアの採用や、データベースの検索処理の要となる「シャッフル処理」をオンメモリーで実行する専用のシステムが導入されたことが説明されています。次の図は、現在の BigQuery のアーキテクチャーを表したものですが、計算用のサーバークラスターとデータ保存用のストレージクラスターがあり、その間には、シャッフル専用のシステムが描かれています。これら 3 つの仕組みによって、BigQuery の高い性能が実現されているのです。
分散リレーショナルデータベース:Spanner
Cloud Spanner は、Google Cloud で利用できる分散リレーショナルデータベースのサービスです。アプリケーション開発者の視点では、標準的な SQL でアクセスできて、強い整合性を持ったトランザクションをサポートする一般的なリレーショナルデータベースですが、その背後には、Bigtable と同様の分散アーキテクチャーがあり、多数のノードによる分散処理が行われます。Spanner のアーキテクチャーは、2013 年に次の論文で初めて紹介されました。
この論文では、次の図のアーキテクチャーが紹介されており、Colossus に tablet のデータが格納されるという Bigtable のアーキテクチャーが継承されていることが分かります。
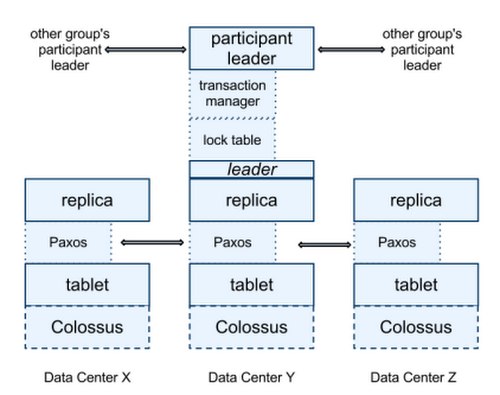
一方、Bigtable と異なる Spanner 独自の仕組みとして、複数のデータセンターにまたがったレプリケーションが行われており、トランザクション処理を実行する transaction manager が存在することなどが分かります。また、Spanner では、高精度な時刻同期システム(TrueTime)によって、分散トランザクションにおける整合性を保証していることが公式ドキュメント(Spanner: TrueTime と外部整合性)でも紹介されています。この論文では、TrueTime のシステムでは、GPS や原子時計が使用されていることにも触れられています。
先ほど説明した Dremel(BigQuery)は、SQL を用いた検索に特化したデータウェアハウスですが、Dremel の成功によって、Google 社内では、検索だけではなく、データの読み書きすべてを SQL で実行する一般的なリレーショナルデータベースの活用にも期待が高まりました。もちろん、当時から既存のリレーショナルデータベースの技術はありましたが、Google が必要とする大規模なデータ処理に対応するスケーラビリティに欠けていました。そこで、高いスケーラビリティを持った分散型のリレーショナルデータベースの実現を目指して、Spanner の開発が始まったということです。
Spanner が誕生した当初は、標準的な SQL への対応は不完全でしたが、その後の機能拡張によって、標準的な SQL に対応した、現在の Spanner へと進化していきました。SQL による検索を分散システムとして処理する仕組みについては、2017 年に公開された次の論文に詳しい解説があります。
モバイルアプリ対応のリアルタイムデータベース:Firestore
Google Cloud の特徴的なデータベースサービスに Cloud Firestore があります。モバイルアプリケーションのバックエンドとしての使用を想定したもので、リアルタイムクエリーなどのユニークな機能を提供しています。これまでに紹介したデータベース技術とは異なり、Google Cloud のサービスとして提供するために新たに開発されたデータベースです。Firestore のアーキテクチャーは、2023 年に公開された次の論文で紹介されています。
この論文では、Firestore の歴史についても触れられています。Firestore の前身となるのは、2008 年に公開された AppEngine のデータベースである Cloud Datastore です。これは、Bigtable をバックエンドのデータストアとしたシステムで、高いスケーラビリティを有するものの、強い整合性は Ancestor クエリーに限定されるなどの課題もありました。その後、2014 年に Google は、Firebase, Inc. を買収すると、当時の Firebase 社が提供していたリアルタイムデータベースを Google の独自技術で再実装することを決定しました。この際、Datastore の高いスケーラビリティに、リアルタイムデータベースの機能を統合した新しいデータベースシステムを実現することを目指して、現在の Firestore が誕生しました。
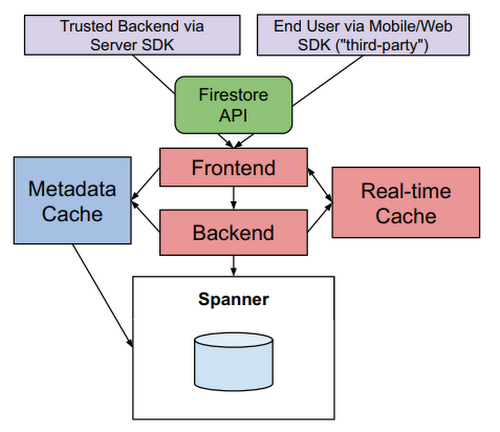
Cloud Firestore には、Datastore との違いとして、強い整合性を持ったトランザクションが常に利用できるという特徴があります。次の図にあるように、Firestore は、バックエンドのデータストアに Spanner を使用しており、Spanner のトランザクション機能を利用することで、強い整合性を持ったトランザクションを実現していることなどもこの論文で解説されています。
その他の論文
Google Cloud では、これらの他にもさまざまなデータベース技術が活用されています。たとえば、モニタリングサービスの Cloud Monitoring は、仮想マシンのリソース使用量、アプリケーションに対するアクセス数やレスポンスタイムなど、さまざまなレイヤーのモニタリングデータを収集することができますが、これらのデータは、Monarch と呼ばれる時系列データベースに保存されます。
Google 社内には、Google Cloud 用のシステムとは別に、社内利用専用の Monarch が用意されており、YouTube、Gmail、Google Maps など、Google が提供するさまざまなサービスのモニタリングデータの収集に利用されています。2020 年に公開された次の論文では、Monarch のアーキテクチャーについて、Google 社内での利用形態を前提とした解説がなされており、1 秒間にテラバイト単位のデータ保存と数百万件のデータ検索が行われているなどのデータが公開されています。
今回紹介した一連の論文を読むと、Google のさまざまなデータベース技術は、お互いに影響を与えながら共に発展してきたことが分かります。Google Cloud を通してこれらの技術に触れることで、論文に記載されたそれぞれの技術の特徴がより実感できるでしょう。Google Cloudをより深く理解して、より楽しく使いこなす、「一歩先を行くクラウドエンジニア」になるためのヒントをぜひ発見してください。





