公開論文から学ぶ Google のテクノロジー : パート 1:分散処理基盤(コンテナ技術)とデータセンター編

中井 悦司
ソリューションズ・アーキテクト, Google Cloud Japan
Google Cloud のサービスは、Google が長年に渡って構築してきたグローバルネットワーク、そして、世界各地のデータセンターによって提供されています。これは、Google 検索をはじめとするさまざまな Google のサービスを支えるインフラでもあり、その上では、Google 独自の技術を活用したさまざまなミドルウェアが稼働しています。
Google Cloud で提供されるマネージドサービスの多くは、これらのミドルウェアをマルチテナント化して提供しているものであり、いわば、Google Cloud を利用することで、Google 以外の企業でも「Google のサービスを支える技術」が活用できるのです。Google Cloud を活用する開発者の中には、このような Google の技術に興味を惹かれて、Google Cloud を使い始めたという方も少なくないかも知れません。
Google の技術を解説した論文
Google のエンジニアは、自分たちが開発した技術の詳細を論文として公開しており、これまでに公開された論文は、Google の研究チーム、Google Research の Web サイトにある Publication Database で検索できます。ちなみに、ここに登録されている最も古い論文は何でしょうか? ——— それは、1998 年に公開された「The Anatomy of a Large-Scale Hypertextual Web Search Engine」という論文で、Google の創業者である Sergey Brin と Larry Page が当時の検索エンジンの仕組みを解説したものになります。
この他にも、Google 検索のバックエンドデータベースとして開発された Bigtable や、分散 RDB(リレーショナルデータベース)の Spanner など、Google Cloud で利用可能なサービスに関する論文も多数公開されています。このブログシリーズでは、次の 4 つの分野に分けて、Google Cloud の技術に関連の深い論文を紹介していきます。
分散処理基盤(コンテナ技術)とデータセンター
ネットワーク技術
データベース技術
機械学習 / AI
Google Cloud で提供されるサービスの多くは、フルマネージドサービスで、Cloud Console からボタン一つでインスタンスを立ち上げて簡単に利用できます。論文レベルの深い技術を知らなくても十分に使いこなすことはできるでしょう。しかしながら、論文を通して、それぞれの技術が生み出された背景や、それを実現する際にエンジニアが重視したポイント、つまり、「何のために、何を目指して、この技術が生み出されたのか」を知ることができます。
このシリーズで紹介する論文には、Google Cloud をより深く理解して、より楽しく使いこなす、「一歩先を行くクラウドエンジニア」になるためのヒントが隠されています。いずれも英語で書かれた学術論文ですので、実際に読み通すのは少し大変かも知れませんが、仲間を募って輪読会を開くなど、それぞれの方法で楽しんでみてください。
このパート 1 では、分散処理基盤(コンテナ技術)とデータセンターに関連した主要な論文を紹介します。なお、それぞれの論文は、公開時点での技術情報を伝えるものですので、今現在、Google のデータセンターで使用されている技術とは異なる場合もあるので、その点は注意してください。
Google Cloud を支える分散処理基盤
Google の技術は、多数のコンピューティングリソースが並列にデータを処理する、分散処理技術がその基礎になっています。このような分散処理技術は、検索エンジンのアーキテクチャーから発展してきました。そして、Google の分散処理システムを支えるもう一つの要素がコンテナ管理システムです。Google では、CPU やメモリーなどのサーバーリソースを有効活用するために、コンテナ技術を用いてアプリケーションをデプロイします。この際に利用されるのが、Borg と呼ばれる独自のコンテナ管理システムです。
今回は、Google の分散処理技術の原点とも言える、検索エンジンのアーキテクチャーに関わる論文、そして、コンテナ管理システムに関する論文、さらには、データセンターの設計に関わる論文を紹介します。
Google の分散処理技術の原点:検索エンジンのアーキテクチャー
検索エンジンのアーキテクチャーを解説した最も古い論文の 1 つが、2003 年に公開された次の論文です。
これは、2003 年当時の検索エンジンのアーキテクチャーを解説したもので、サーバー専用のハードウェアの代わりに、コモディティ PC でクラスターを構築して、ソフトウェアで信頼性を確保する設計方針が説明されています。ただし、コモディティ PC と言っても、安価な PC であれば何でも構わないという意味ではありません。
次の表は、検索エンジンの中核となるインデックスサーバーについて、CPU 上でのさまざまインストラクション(CPU レベルでの処理命令)の実行状況を分析したものです。当時は、サーバーの CPU として Pentium Ⅲ、もしくは、Pentium 4 が利用可能でしたが、このデータを元に分析した所、インデックスサーバーの処理については、いずれの CPU でも実行速度は大きく変わらないとの結論が示されており、これに基づいて、より安価な Pentium Ⅲ を採用したとの記述があります。

この様に、アプリケーションの特性に応じた CPU の構造レベルでの分析が行われており、論文のタイトルにもある、「Planet」スケールのサービスを実現するための緻密な戦略が感じられます。
次の図は、この論文に記載された、システム全体の概要図です。ここでは、検索インデックス、および、検索対象のドキュメントが複数のサーバーに分散配置されています。検索処理を行うインデックスサーバーと実際のデータを保存したドキュメントサーバーを分離したアーキテクチャーは、この後のパートで紹介する分散データベースのアーキテクチャーに類似しています。
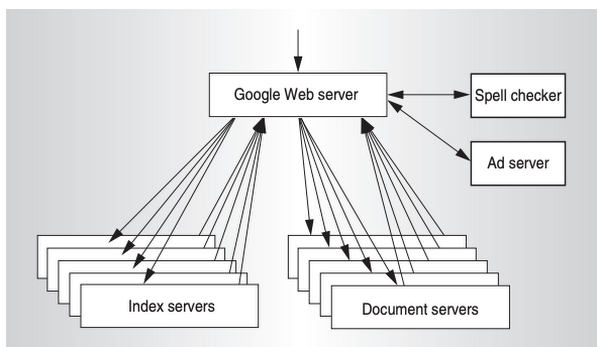
論文の中では、「検索エンジンというサービスの特性がこのような分散処理システムに適していた」と説明されていますが、ここで得られた知見が分散データベース技術をはじめとする、さまざまなシステムへと応用されたのは間違いないでしょう。
そして膨大なユーザーからの検索リクエストを受け付ける際に必要となるのが、ロードバランサーのシステムです。一般的なロードバランサーは、外部からのアクセスをデータセンター内の複数のサーバーに振り分ける処理を行いますが、検索エンジンでは、世界のさまざまな地域からのアクセスを世界各地のデータセンターに振り分ける必要があります。そのために、Google では、グローバルな負荷分散を実現する独自のグローバルロードバランサーのシステムを構築しました。その中核となるのが、Maglev と呼ばれるシステムです。2016 年に公開された次の論文で、そのアーキテクチャーが解説されています。
データセンター内の複数サーバーに負荷分散する一般的なロードバランサーは、L2 レイヤーで動作しますが、これを複数のデータセンターにまたがったグローバルなシステムにするには、どのような方法があるのでしょうか? ここでは、意外とシンプルな解決策が用いられています。この論文によると、GRE トンネルによるオーバーレイネットワークを用いて、L3 ネットワーク上で、L2 接続を実現しているということです。現在のネットワーク環境では、このようなトンネル接続は一般的になりましたが、Google が Maglev の使用を開始したのは、2008 年からということです。当時としては先進的なネットワーク技術を早くから実サービス環境で利用していたことが分かります。
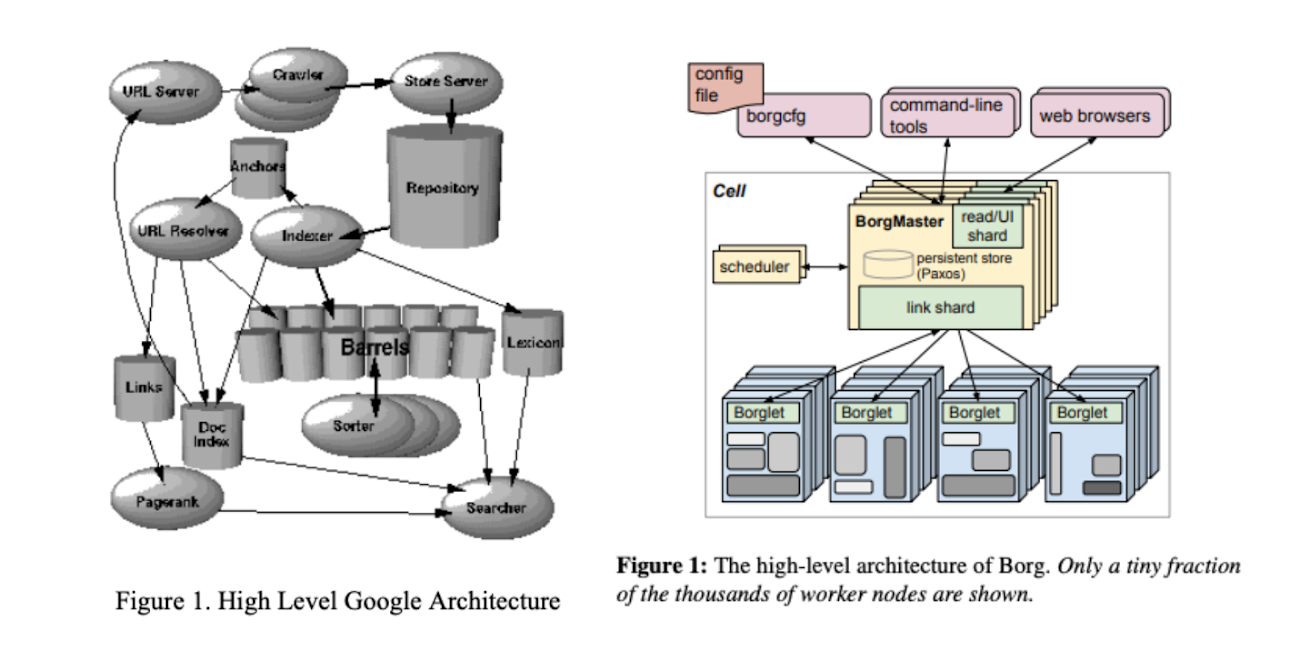
コンテナ管理システム:Borg
前述の検索エンジンのアーキテクチャーから発展した、Google の分散処理システムを支える基盤が、コンテナ管理システムです。先に紹介した論文によると、2003 年の時点で、15,000 台を超えるサーバーを使用しており、この規模のサーバー群にワークロードを配置するには、専用の管理システムが必須となります。
Google では、コンテナ技術を用いてアプリケーションをデプロイすると同時に、コンテナの配置を自動的に最適化する仕組みとして、Borg と呼ばれる独自のコンテナ管理システムを使用しています。Google 社内では、ミドルウェアを含めたあらゆるアプリケーションが、Borg を用いてデプロイされているのです。Borg のアーキテクチャーは、2015 年に次の論文で初めて公開されました。
ちなみに、現在、コンテナ管理のシステムとしては、オープンソースの Kubernetes が有名です。Kubernetes の開発プロジェクトは、Google 社内で Borg の開発に関わったエンジニアが、Borg と同じ仕組みを Google 以外の企業でも使えるようにすることを目指してスタートしたプロジェクトです。この論文内では、「セル」という用語が登場しますが、これは、Kubernetes のクラスターにあたります。
Borg のシステムで、コンテナの配置を決定するのは、タスクスケジューラの役割になります。この際、サーバーの利用効率を高めること、すなわち、より少数のサーバーでより多くのタスクを実行することが1つの目標となります。Borg の環境では、リアルタイムで応答を返す API サービスと定期実行されるバッチジョブなど、複数のサービスにまたがる様々な種類のワークロードを同一のセルに混在させることで、利用効率を上げることを目指しています。
開発環境と本番環境でサーバーを分けるというのは、一般的な考え方ですが、Google では、これらの環境もあえて同一のセルに統合しています。先ほどの論文では、環境によってセルを分けた場合のシミュレーション結果が次の図で示されています。

ここでは、実サービスを提供する優先度の高いタスクを「prod」、バッチジョブや開発中のサービスなど優先度の低いタスクを「non-prod」と表現しており、A 〜 E の 5 つのセルについて、non-prod のタスクを別のセルに分けた場合に、必要なサーバー数がどの程度増加するかをシミュレーションした結果になります。左側の baseline は、これらを混在させた実環境でのサーバー数(セル全体を 100 とした時の割合)で、右側の「prod」と「non-prod」を合わせたものがセルを分けた場合に必要なサーバー数になります。セルを分けた場合、必要なサーバー数が増加することがよく分かります。
これは、あくまでも 2015 年当時のデータになりますが、その後、2020 年に公開された次の論文では、2019 年の新しいデータが公開されています。
複数のセルに対する CPU 使用率やメモリー使用量などのリソースの使用状況が公開されており、一般的なサーバーシステムに比べて、より高いリソースの使用率が実現されていることが分かります。たとえば、次の図は、代表的な 8 個のセルに対する CPU 使用率(平均値)の時系列データになりますが、安定的に一定の使用率を保っていることなども読み取る事ができます。

データセンターの設計
その他にも、Google Cloud を支えるインフラ環境に関する興味深い論文があります。たとえば、2020 年に公開された次の論文では、Google のデータセンターにおける電源設備の設計が解説されています。
大規模なデータセンターでは、サーバーや空調設備が使用する電力コストに加えて、電力を供給するための電源設備そのものにも多大な投資が必要です。この論文では、災害などによる停電に備えるバックアップ電源を独自設計することで、電源設備の利用効率を高めていることが解説されています。
一般に、データセンターでは、外部の電力会社から供給される高電圧の電力源をサーバーに適した電圧に減圧した後、複数の「Low Voltage PDU(低電圧配電盤)」を介して、サーバーラックに電力供給します。通常は、この PDU ごとに個別のバックアップ電源を用意するのですが、Google では次の図のような仕組みを採用しています。

ここでは、小さなバックアップ電源を個別に用意するのではなく、複数の自家発電装置を束ねた「Generator Farm」を商用電力源と並列に配置しています。いわば、バックアップ電源についても、大規模なクラスターを構築することで、電源設備の使用効率を高めているのです。
データセンターの効率化に関連した論文には、次のようなものもあります。
これは、データセンターのエネルギー効率を機械学習で最適化するというもので、ニューラルネットワークを用いて、サーバーの稼働率や冷却水の温度設定によるエネルギー効率の変化を予測するモデルが解説されています。このモデルを使って、さまざまな設定をシミュレーションすることで、よりエネルギー効率の高い設定を見つけ出そうというわけです。
ちなみに、2016 年に、DeepMind がディープラーニングを用いて、Google のデータセンターのエネルギー効率を改善したというブログ記事(DeepMind AI reduces energy used for cooling Google data centers by 40%)が公開されましたが、この論文は、それ以前の 2014 年に公開されたものになります。一般に、ディープラーニングを有効活用するには、十分な量の学習データが必要になります。Google では、古くからデータセンターのエネルギー効率の改善に取り組み、さまざまなデータの収集・分析を続けており、それがディープラーニングを活用した成果につながったと言えるでしょう。
今回紹介した一連の論文から、Google では、データセンター設備から始まり、分散システムの基盤となるコンテナ管理システムなど、スケーラブルで信頼性の高いアプリケーションを実現するためのインフラを独自技術で作り上げてきたことが分かります。これからも新たな技術による進化が続いていくのは間違いありません。これらの論文から、Google Cloud のこれからの進化を想像するのも面白いかもしれません。


