Managed Service for Prometheus を導入した Maisons du Monde の事例
Google Cloud Japan Team
※この投稿は米国時間 2022 年 5 月 17 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: 今回は、Maisons du Monde の事例を紹介します。同社は 25 年前にフランスで創立され、家具やインテリアを提供している Google Cloud ユーザーで、フランス、イタリア、スペイン、ベルギー、ルクセンブルク、ドイツ、オーストリア、スイス、オランダ、ポルトガルに 357 の店舗を構えています。この事例をまとめるにあたり、カスタマー エンジニア Adrien Aflalo 氏にご協力いただきました。
本番環境については、ログや指標などのテレメトリー データがなければ何もわかりません。Maisons du Monde のチームは、オペレーション エンジニアとサイト信頼性エンジニア(SRE)を擁し、特に指標データを活用して、Maisons du Monde ウェブサイト、API、オムニチャネル サービスを安全かつ信頼性の高い方法で運用することを目指しています。つまり、指標プラットフォームとプロバイダの選択は単なる技術面の決定ではなく、当社のビジネスにとっても重要な決定です。
Maisons du Monde は、オペレーションの多くの部分を Google Kubernetes Engine に移行していく中で新しい指標プラットフォームをいくつか評価検討し、およそ 8 か月前に Prometheus の採用を決めました。当社の環境には、Kubernetes 上に構築されてエフェメラルなコンピューティング インフラストラクチャで実行されるクラウド ネイティブ アプリケーションが含まれていますから、Prometheus がぴったりです。最初は独自の Prometheus 環境を構築して実行していましたが、Google Cloud Managed Service for Prometheus のほうが優れたソリューションであるとの結論に至りました。このソリューションには次のような特長があり、指標インフラストラクチャの管理に煩わされることなく、指標の活用に集中できます。
指標の保持期間が長い(2 年間)
Prometheus インスタンスの高可用性がシームレスにサポートされる
軽量の Kubernetes カスタム リソースを使用してルールをスクレイピングし、評価できる
グローバルなクエリビュー
すぐに使用できる、フルマネージド型の収集とクエリ
自己ホスト型 Prometheus からマネージド型 Prometheus サービスに移行した当社の経験は、自社独自の Prometheus を運用している、あるいは独自の Prometheus を運用すべきか検討している他の組織にとって参考になることと思います。
Maisons du Monde はまず、拡大していく Kubernetes 環境をサポートする目的で従来のマネージド指標サービスから Prometheus に移行しました。
その後、独自の Prometheus 環境を構築して管理していましたが、本番環境ワークロード(高可用性や短い MTTR など)とスケーリングをサポートするには追加的な機能が必要だということに気づきました。
そこで、本番環境での Prometheus の利用をサポートするソリューションを調べ、Thanos を採用しました。
それでも、これらのテクノロジーを運用してインフラストラクチャを管理するのに多大な時間と人員を投資していることがわかりました。
最終的に当社は Google Cloud Managed Service for Prometheus を採用しました。これまでのところ、当社のニーズを非常によく満たしてくれています。
小規模のデプロイメントはオープンソース Prometheus で対応可能
一般に、指標を活用しようとする組織はフルサービスのモニタリング / 指標ストレージ ツールまたはオープンソース データベースを使って指標を保存し、Grafana などの可視化ツールを使って指標を表示します。
当社では過去 5 年間、2 つのプロバイダが提供するマネージド モニタリングおよびストレージ サービスを利用しました。異なるベンダーを利用したことでオペレーション チームの業務が複雑になりました。また、信頼性確保の最終責任を負うチーム、つまりアプリケーション チームとの間で指標を共有することも困難になりました。当社は、アプリケーション チームこそが指標を所有すべきだと考えています。そうすれば、デベロッパーとプロダクトの所有者は、アラートとダッシュボードの作成に不可欠であるはずの指標を適切に維持できます。
Prometheus に移行した後、最初は何の問題もありませんでした。Prometheus の場合、Prometheus コレクタがきめ細かな指標を収集します。それがPrometheus データベースに保存され、それぞれのアプリケーションが表示できます。
ところが、本番環境アプリケーションの実行とともに増え続ける GKE クラスタに Prometheus をデプロイしたところで、制約が発生しました。たとえば、次のような制約です。
大規模な管理への対応
私たちは、リソースをデプロイして管理する「Infrastructure as Code」モデルに業務体制を移行しようとしていました。このほうが効率が良く、エラーも少なくなるからです。それには、ポリシーに従って各 Kubernetes クラスタに Prometheus をデプロイするための単純な方法が必要でした。
保持
Prometheus のデフォルトの時系列データベース保持期間は 15 日に設定されています。データベース保持期間は構成可能ですが、指標をディスクに保持しておく期間が長くなるほど、コストとリソース消費量が増大します。すべての Kubernetes クラスタとアプリケーションについて、指標の長期保持をもっと適切に管理する方法が必要です。
バックアップ / 障害復旧と復元
ビジネスの継続性は、本番環境で使用されるあらゆるサービスで考慮する必要があります。Prometheus では、ディスクの障害とバックアップが課題であることがわかりました。障害発生時のデータ損失を防ぐには、Prometheus インスタンスのデータをスケーラブルにバックアップして復元する方法が必要です。
オペレーションのスケーラビリティ
さらに、Prometheus にはネイティブのシャーディング機能がありません。これは管理やデプロイメントの観点からは長所かもしれませんが、モニタリング対象のクラスタが多数ある場合は短所となります。
更新
Prometheus では静的ファイルの中にルールが保存されます。そのため、ルールファイルの更新を適用するには Prometheus インスタンスの再起動が必要となります。
Prometheus と Thanos を使用して一部の(すべてではない)ニーズに対応
上記の問題に直面した当社は、これらの問題に対処する方法を探し、Thanos を見つけました。Thanos は、Improbable が 2018 年にリリースしたオープンソース プロジェクトです。これはマルチクラス管理とデータ ストレージに役立ちました。Prometheus の指標を Google Cloud Storage、Azure Blob Storage、アマゾン ウェブ サービス(AWS)の S3 などのオブジェクト ストレージ サービスに送信できます。
Prometheus と同様に、Thanos のアーキテクチャは拡張できるように設計されています。
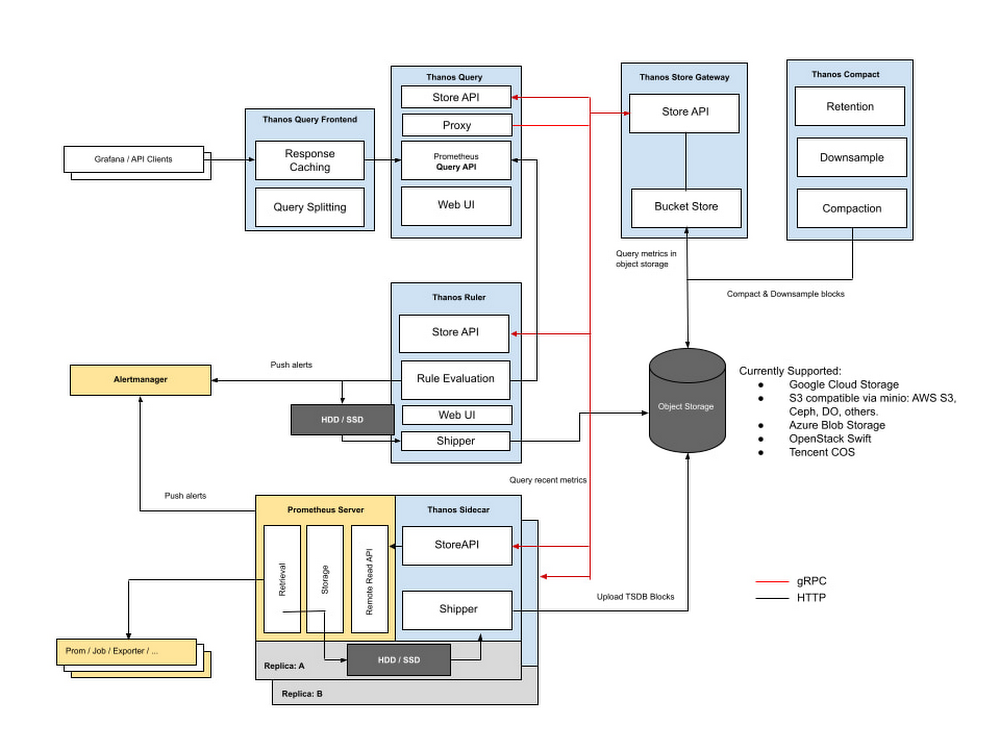
Prometheus と Thanos を併用することで、先ほど説明した以下のような問題を解決できました。
保持
Prometheus と異なり、Thanos は収集ベースではなく、クエリベースです。Prometheus インスタンスとともにデプロイされる Thanos Sidecar は、表示するよう要求された指標のみを収集します。Thanos のドキュメントでは、各ロールについて説明しています。Prometheus で保持が構成済みの場合、ローカル ディスクで指標が利用不可であれば、リモート ストレージ場所から指標を取得するように Store Gateway コンポーネントに指示が出されます。この機能により、スタンドアロン Prometheus で発生する指標の保持の問題に対処できます。さらに、Thanos は次のような他の一般的な Prometheus のニーズにも対処します。
フェデレーション
Thanos ではマルチクラスタ環境のグローバル ビューを設定できますが、Prometheus ではできません。このため、Kubernetes クラスタごとに 1 つの Querier と 1 つの Querier の「フェデレータ」を設定する必要があります(以下の図はこれを示しています)。
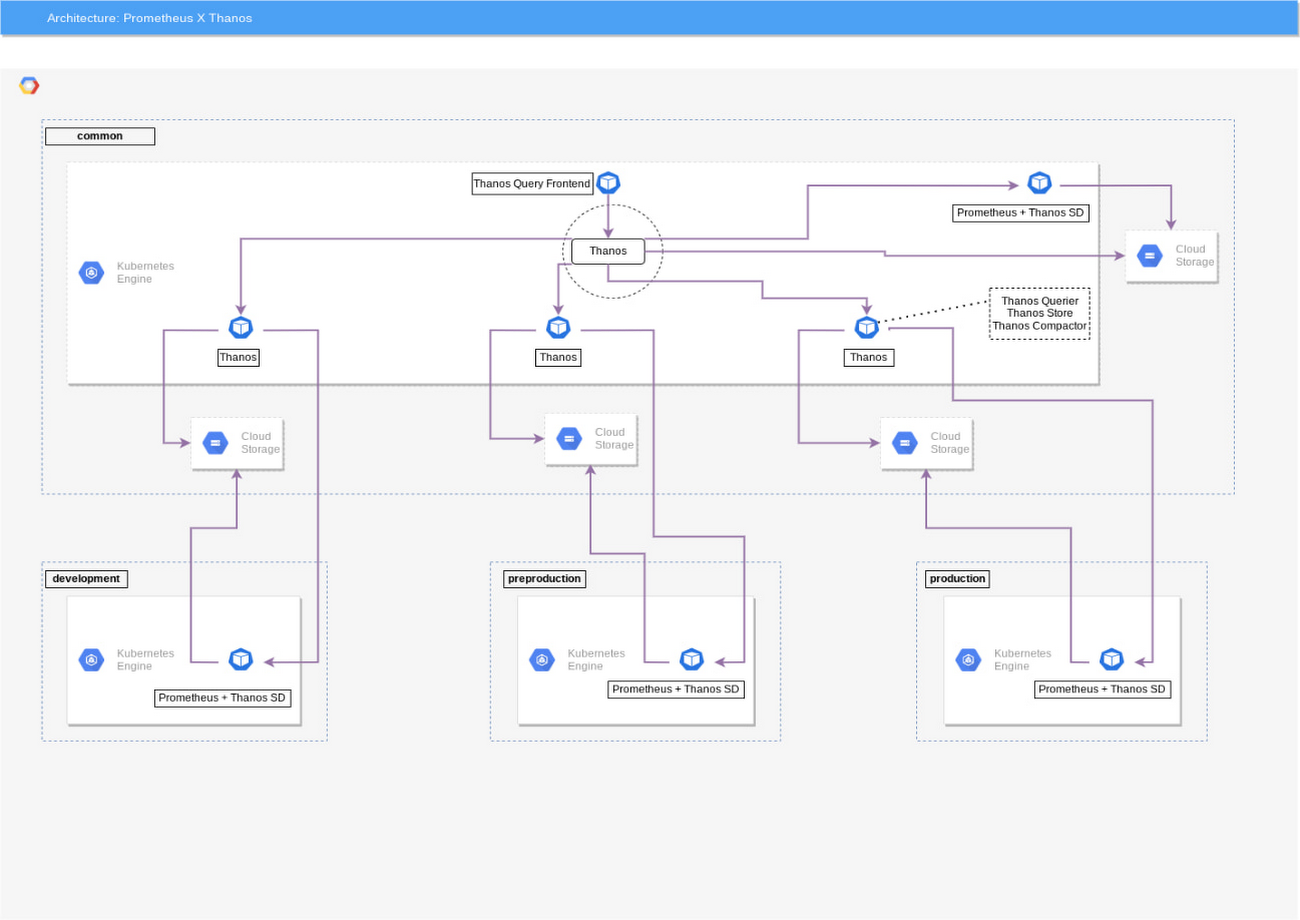
単純な構成(以下のサンプルコードを参照)を追加することで、Querier コンポーネントをマルチクラスタ環境に追加でき、指標のグローバル ビューが得られます。
Thanos Querier デプロイメント構成の例
Prometheus と Thanos は使える…しかし複雑さが増大
Thanos のおかげで、スタンドアロン Prometheus の問題に対処できました。しかし多数のコンポーネントが関与して、複雑さが増大しました。これにより、次のような問題が生じました。
開発時間
上述のようなマルチクラスタのグローバル環境を設定して管理するには、エンジニアリングのリソースと時間が必要です。エンジニアの時間は非常に貴重なので、私たちは最先端の指標システムを維持するために費やすのではなく、新機能の開発に時間をかけたいと考えました。
インフラストラクチャの負荷の増大
Kubernetes クラスタごとに Thanos Querier を構成することで、リモート ストレージにおけるネットワーク帯域幅の消費量が増大しました。さらに、多くのコンポーネントが Prometheus に追加されたので、システム消費量(CPU、RAM)も増えました。
最初に Prometheus をデプロイし、さらに別のソリューション(Thanos)を導入して自力で問題解決を試みた私たちですが、やがてマネージド サービスを検討すべき時が来たと判断しました。
マネージド サービスへの移行: Google Cloud Managed Service for Prometheus
2021 年 10 月に Google Cloud が Managed Service for Prometheus の公開プレビューを発表したのを受け、私たちは、既存の Prometheus スタックの代わりにこれが利用できるはずだと考えました。
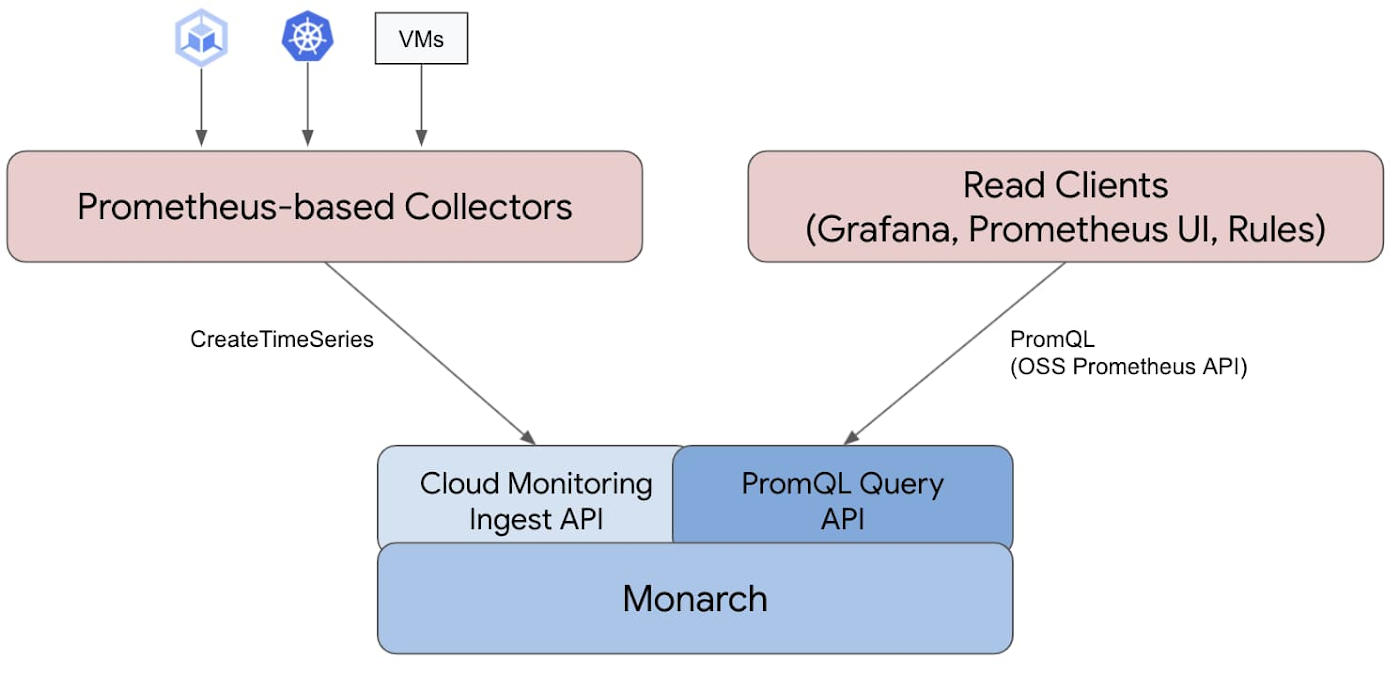
サービス用の指標を取得するコレクタは、オープンソース Prometheus テクノロジーからのフォーク(分岐)です。コレクタは指標を Monarch という名前の Google グローバル時系列データベースに送信します。これにより、Thanos が不要になりました。
Google Cloud では、Managed Service for Prometheus を使用するための 2 つのモードが提供されていますが、当社はマネージド コレクションを使用しています。これにより、Prometheus インスタンスをデプロイして管理する際の複雑さが軽減されました。Managed Service for Prometheus に備わっている 1 つのオペレーターで、指標のスクレイピングやルールの評価などを行うカスタム リソース(CR)を構成できます。すべての Prometheus オペレーションは Kubernetes オペレーターによって処理されます。
さらに、このソリューションでは最新の Prometheus ユースケース(ServiceMonitor から PodMonitoring スクレイピング構成への移行など)がサポートされます。
Maisons du Monde の成長に伴って指標データが着実に増大していくことが予想されたため、自社で大量の指標を管理しようとすると多大な負担になることは明らかでした。マネージド サービスである Google Cloud Managed Service for Prometheus のおかげで、何百台ものサーバーを投入することなく、指標インフラストラクチャを簡単にスケーリングできました。当社は、長期にわたるストレージや Prometheus インフラストラクチャの管理能力を高めるのではなく、機能的および戦略的な指標に基づいたオペレーション体制を構築することに注力したいと考えています。
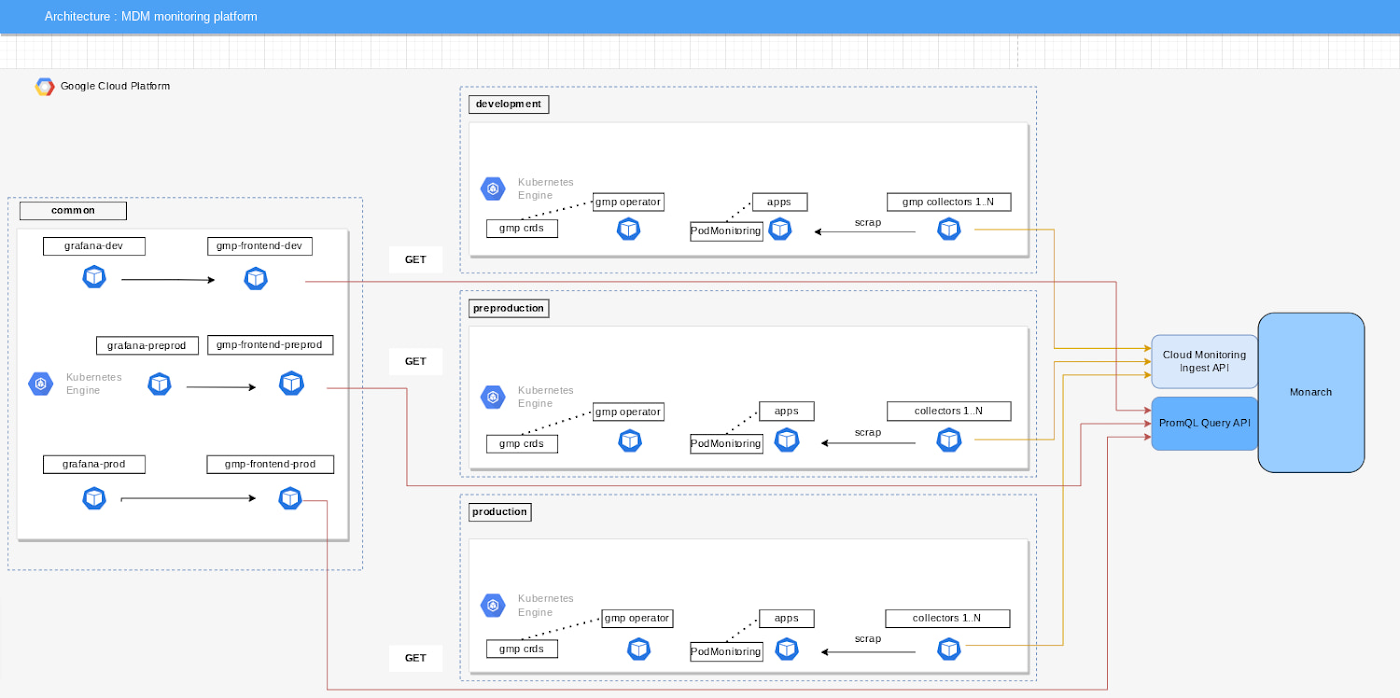
Managed Service for Prometheus のデプロイには Google Cloud コンソール、gcloud CLI、または kubectl ツールが必要なので、当社にとってまだ完璧なソリューションではありません。将来的には Terraform がサポートされるそうですが、当社では Helm チャートを使用してデプロイするためにエンジニアリング リソースを追加しなければなりませんでした。デプロイ プロセスの一部を自動化するための Helm チャートを構築しましたので、コードを公開いたします。皆様のデプロイの参考にしていただければ幸いです。このトピックに関する Medium ブログで、コード スニペットをご覧ください。
Managed Service for Prometheus を導入する
まとめると、Prometheus の構造、機能、エコシステムは当社のビジネスに適していましたが、インフラストラクチャとソフトウェアの大規模な運用には十分ではありませんでした。そこで、当社は Managed Service for Prometheus を選択しました。このサービスは、Google Cloud のフルマネージド サービスを使用して、ワークロードをモニタリングし、アラート通知を管理できます。ニーズに合わせてスケーリングでき、管理やメンテナンスは不要です。
近い将来に Managed Service for Prometheus を導入しようとお考えの場合は、最初の手順を説明したこの動画か、Managed Service for Prometheus のページで詳しく確認することをおすすめします。あるいは手っ取り早く当社のチームに加わり、一緒に働くのはどうでしょうか?Maisons du Monde のウェブサイトをご覧ください。募集中の求人が多数あります。
- Maisons du Monde、サイト信頼性担当 Victor Ladouceur


