プラットフォーム使用の落とし穴(パート 1): アクティビティの多さが必ずしも価値の高さを示すとは限らない理由
Darren Evans
EMEA Practice Solutions Lead, Application Platform
Alex Moss
Principal Platform Engineer, John Lewis Partnership
※この投稿は米国時間 2026 年 2 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
社内デベロッパー プラットフォームに投資した組織では、必ず「実際に機能しているのか?」という疑問が生じます。
導入率を追跡するだけでは、プラットフォームがデベロッパーに真の価値をもたらしているかどうかはわかりません。英国の大手小売業者である John Lewis も、この課題に直面していました。これまでの記事(パート 1 と パート 2)では、John Lewis Digital Platform(JLDP)が数十のプロダクト チームによる高品質なソフトウェアの迅速な構築を可能にし、www.johnlewis.com やその他の重要なアプリケーションを強化した方法を紹介しました。しかし、このプラットフォームが実際に成功を収めたことはどのようにしてわかったのでしょうか?収益や販売などの従来のプロダクト指標をこの分野にそのまま当てはめることはできません。テナントがプラットフォームを使用しているかどうかだけを重視していると、プラットフォームがテナントに価値をもたらしているかどうかを把握できません。
この記事では、John Lewis のプラットフォーム チームの Alex Moss 氏が、単純な使用状況の指標から、プラットフォームの真の価値を測定するための洗練された多段階のアプローチを開発するまでの経緯について説明します。この取り組みは、リードタイムの指標から DORA、そして最終的には「技術的健全性」スコアへと発展しました。その過程で、JLDP の目的がどのように進化し、それとともにその価値がどのように高まってきたのかを探ります。- Darren Evans
最初の測定: プラットフォームの価値に焦点を当てる
プラットフォームの初期の頃は、その価値の把握は実際にははるかに簡単でした。これは、プラットフォームが非常に明確な目的、つまり変更の迅速化を実現するために作成されたからです。John Lewis のビジネス部門は、johnlewis.com の複数の機能を並行して開発する複数のプロダクト チームを編成し、それらの機能を顧客に迅速に提供してフィードバックを得たいと考えていました。
同社のオンライン ビジネス「John Lewis Digital」の世界で生まれたため、非常に早い段階からプロダクトとして扱われ、その分野のレポート メカニズムとも統合されました。そのため、プラットフォームの目標をオンライン ビジネスのより広範な目標に四半期ごとにリンクさせ、測定可能かつ主要な成果を報告することが標準になりました。これにより、このプラットフォームが重要とみなす理由に焦点を当てることができました。プラットフォームの改善は、別のプラットフォームを探すのではなく、そのプラットフォームを使用し続けることを正当化するものでしょうか?現状に満足してはなりません。

6 つの年間指標が四半期ごとに報告されています。具体的な対策は年々変化しました。
これに加えて、プラットフォームの最初の数年間は、プラットフォーム作成の根拠を最もよく示す 3 つのシンプルな指標がありました。
-
サービス作成のリードタイム: テナント(プロダクト チームがソフトウェアを作成するスペース)の作成にかかった時間
-
オンボーディングのリードタイム: プロダクト チームが本番環境にデプロイするのにかかった時間
-
最初の顧客までのリードタイム: プロダクト チームがサービスを「顧客向けに本稼働開始」するまでに要した時間
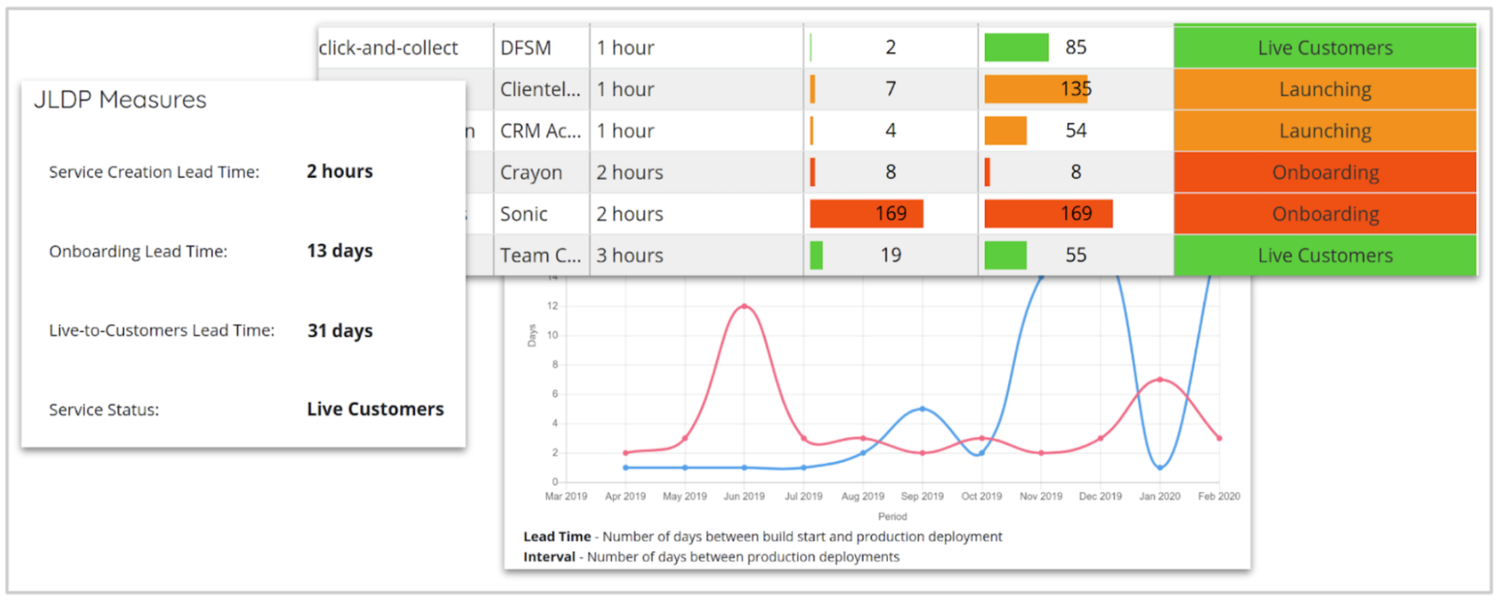
プラットフォームの自社作成サービス カタログの初期バージョンのスクリーンショット。前述の 3 つの指標を追跡
これをプラットフォームに存在するテナントの数と組み合わせてレポートを作成し、上記の初期の自社製サービス カタログの一部として表示しました(その後、Backstage に置き換えられました)。このレポートには 2 つの目的がありました。
-
プラットフォームの導入状況と、稼働開始までの時間(特に「サービス作成」は、従来チームが数週間待つ必要があったのに対し、1 桁の時間で測定)を、関係者向けに非常にわかりやすく可視化する。これは、プロダクトの初期段階では、継続的な成長を実証して投資を正当化する必要があるため重要です。
-
どのチームが本番環境への移行に時間をかけているかを、プラットフォーム チーム自身(および関係者)が確認できるようにする。プロダクトは実際に役に立っているか?そうでない場合、他に何ができるか?
これをテナントとの会話のきっかけとして利用することで、プラットフォームの機能にいかせる豊富なフィードバックを得ることができました。テナントに「本稼働開始を妨げているものは何ですか?」と尋ねたところ、多くの場合、構築しているプロダクトが複雑すぎるという回答が返ってきました。しかし、独自のプロセスが妨げになっていることもよくありました。これは重要なことでした。これにより対策を講じることができたからです。
これらの障壁のうち、当社が最も簡単に克服できたのは、通常、技術関連のものでした。これまでの記事では、「チームが PubSub をプロビジョニングするために Terraform の記述に多くの時間を費やしている」と「Kubernetes の使用方法を学ぶのに苦労している」という 2 つの例を取り上げました。これに対処するため、プラットフォーム チームは「Paved Road(舗装された道)」を作り、セルフサービス プロビジョニングや Kubernetes の簡素化を実現して、チームの負担を大幅に軽減しました。
新しいサービスを本番環境に移行する手順を合理化するためのより大きな機会は、当社のプロセス(セキュリティ承認など)に存在していました。プラットフォームがこのような組織機能を簡素化できるように強化されていれば、得られるメリットは非常に大きくなります。その一例が、情報セキュリティ リスク保証プロセスです。必要なセキュリティ承認を得て、必要なドキュメントを作成する作業が必要でしたが、時間がかかりました。また、ビジネスの変化の速さから、多くのチームが並行してこの作業を行っていました。プラットフォーム チームは、テナント向けの簡素化されたプロセスを交渉で獲得しました。これは、プラットフォームに常駐することで、セキュリティ管理が実施され、ポリシーが遵守されていることを保証できたからです。これは、このニーズを満たす機能をプラットフォームが構築し、それらの機能が使用されているという証拠を提示できたことから直接もたらされた結果です。これにより、テナントチームがこれをドキュメント化したり、独自に考案したりする必要がなくなりました。このソリューションは技術的な要素が少ないものですが、プラットフォーム エンジニアリングを通じてデベロッパーのエクスペリエンスを簡素化しています。
会話の結果、プラットフォームの形をなさないフィードバックが得られることもありました。たとえば、機能フラグやダークローンチなどのコンセプト、あるいはレガシー システムとの依存関係を解消するのに役立つソフトウェア設計オプションをチームが理解できるよう支援することなどです。John Lewis のプラットフォーム チームには、経験豊富なエンジニアが配置されています。このようなやり取りに大いに貢献できる、ソフトウェア開発の経験があるエンジニアが理想的です。
ここで重要なのは、チームがどれだけ効果的に本番環境に移行できたかを測定することで、誰に話を聞くべきかを特定し、対処すべき問題について必要なフィードバックを明らかにできることです。テナントが全体像を把握していない(または他の優先事項がある)場合にテナントが自らこれを考えることを期待するだけでは、効果はほとんどありません。
その後、アンケートの実施やネット プロモーター スコアの利用など、より従来的なアプローチと組み合わせることで、プロダクトの人気を高めることができました。その結果はたいてい非常にポジティブなものであり、マインドシェアの獲得に利用できました。特に、プロダクト チームが社内の技術会議などでポジティブな経験について話すことに抵抗がない場合は、その効果が大きくなります。
チームのパフォーマンスを把握できるようにする
プラットフォームを運用してから数年経つと、重視する点が変わり始めました。プラットフォームの価値を証明する必要性は低くなり、ビジネス部門とエンジニアは満足していました。そのため、「いかに早く本番環境に移行できるか」から「いかにして日常業務で迅速さを維持しつつ、摩擦を減らすことができるか」へと焦点を移しました。これが DORA 指標につながりました。
DORA の最初の実装では、変更とインシデントに関する記録システムから情報をマイニングし、すでに成熟していた可用性データ用のオブザーバビリティ スタックで補完しました。また、クラウド監査ログなどのイベントも取得しました。このためのソフトウェアを構築して BigQuery に保存し、自社開発のサービス カタログツールでデータを可視化できるようにしました。その後、これを Grafana ダッシュボードに移行し、現在も使用しています。
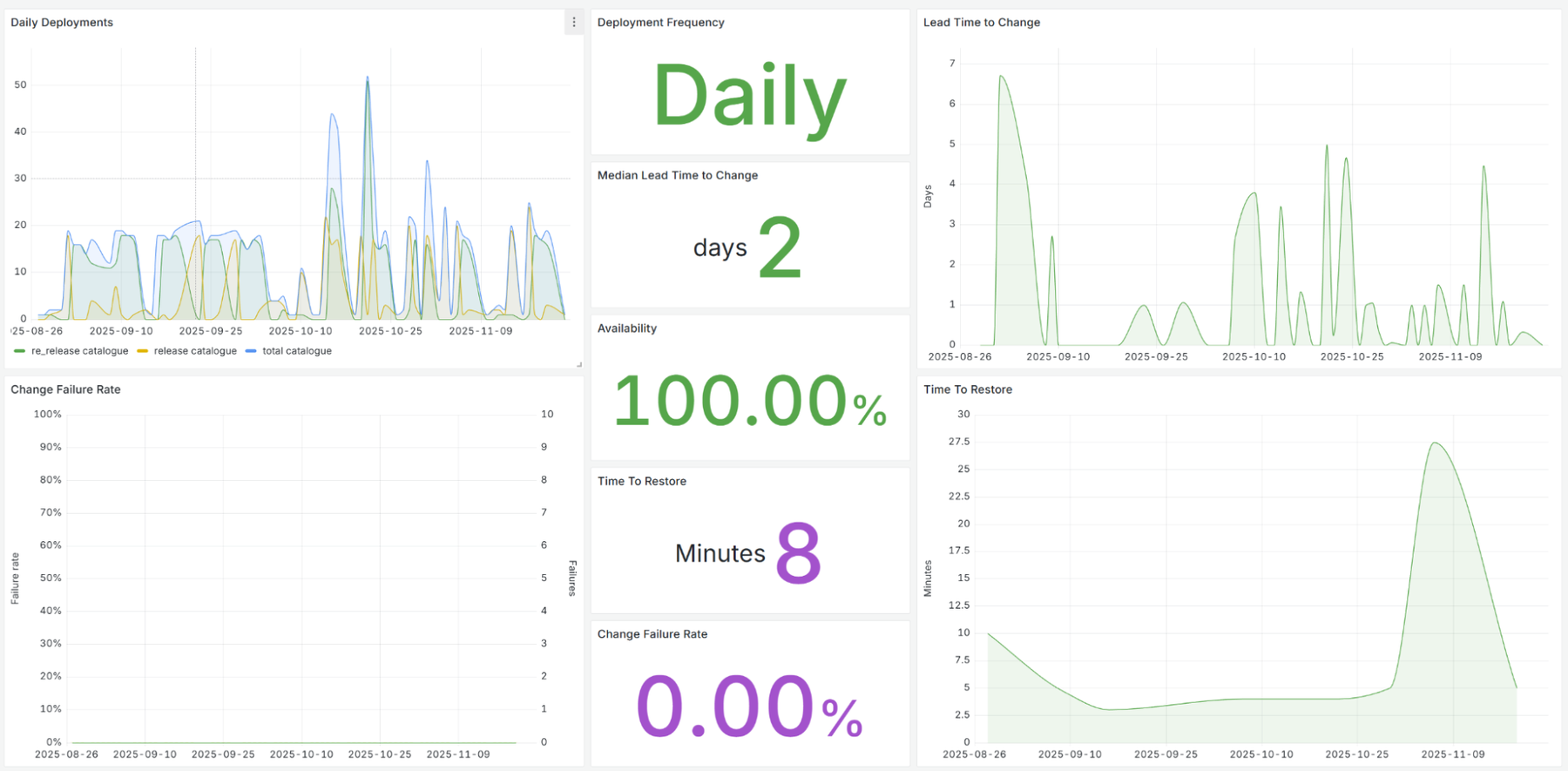
このデータからパターンを探した結果、構築に役立つ他の機能を発見できました。この 2 つの大きな例は、変更への対応と運用準備です。
JLP のサービス管理プロセスは、複数の大規模なシステムやチームにわたる複雑なリリース プロセスを処理することを目的としていましたが、マイクロサービスを採用することでアーキテクチャを根本的に変更しました。これにより、チームは必要に応じて独立してリリースできるようになり、変更の失敗による影響を自分たちで管理できるようになりました。変更時の障害率と小規模なリリースの頻度について収集したデータを使用して、別のアプローチを正当化しました。テナントが CI / CD パイプラインの一部として変更を自動的に発生させて終了できるようにするアプローチです。サービス管理チームにこのアプローチを承認してもらった後、チームがパイプライン内で使用できる CLI ツールを開発しました。これには、より扱いにくいデータソースをスクレイピングするのではなく、リリース時に有用なデータを取得できるというメリットもありました。自動変更の「アメ」は非常に人気があり、広く採用されました。これにより、承認ポイントはリリース プロセスの後半ではなく、pull リクエストの段階に移行しました。この結果、時間の無駄、変更セットのサイズ、衝突のリスクが軽減されました。
同じような事例として、独自のサービスを運用するチームが増えたことで、サイト全体の運用チームを中央に置く必要性が低下しました。指標から、「You Build It, You Run It(自ら開発し、自ら運用する)」を実践しているチームはインシデントが少なく、インシデントの解決もはるかに迅速であることがわかりました。これを根拠として、インシデントへの迅速な対応に役立つツールを導入し、集中型の運用チームをこれらのプロセスから切り離しました。これにより、レガシー システムに集中できるようになったチームもあれば、サービス自体が不要になったチームもあります(後者の場合、個々のプロダクト チームのオンコールが増えたにもかかわらず、大幅な費用削減につながりました)。これに加えて、オブザーバビリティ / アラートツールをサポートするものはすべて、前回の記事で説明したプラットフォームの「Paved Road」パイプラインを通じて構成されました。
DORA の指標は、アーキテクチャの面でも役立ちました。運用データから、サードパーティ サービスと従来のサービスの脆弱性が明らかになり、その結果、レジリエンス エンジニアリングや代替ソリューションへの投資が拡大しました。構築と購入の意思決定を再評価することになったケースもありました。
測定対象を選択する
何を測定するかを賢く選択することは非常に重要です。この分野の専門家(Laura Tacho 氏など)から、見栄えのよい指標は避け、収集した指標の解釈には慎重になるようアドバイスを受けました。さらに、指標がターゲット オーディエンスにとって意味のあるものであり、それに応じて提示されることも重要です。
たとえば、費用や脆弱性についてチームとコミュニケーションをとりますが、その形式はターゲット オーディエンスの役割によって異なります。たとえば、新しい脆弱性や費用の急増は、プロダクト チームのコラボレーション チャネルに直接送信します。これは、エンジニアがこれらの脆弱性を確認することで、より迅速な対応が可能になることが経験からわかっているためです。一方、コンプライアンス レポートやチームリーダーによるレビューでは、対応が必要な領域を要約するためにはレポートの方が効果的です。「ポリシー外の脆弱性」ダッシュボードのリーダーになりたい人はいないことは、よく知っています。
それまで、インシデントの数や頻度などの指標を調べることは珍しくありませんでした。しかし、高度に自動化された対応システムの世界では、アラートは簡単に複製できるため、これは落とし穴となります。数値を重視しすぎると、間違った行動につながる可能性があります。最悪の場合、インシデントの登録を意図的に避けることさえあります。代わりに、親インシデントの影響と復旧にかかった時間に焦点を当てる方がはるかに良いでしょう。もう一つの例は、脆弱性の数の報告です。分散システム内の多くのコンポーネントで広く使用されているパッケージがあるとします。パッケージに脆弱性があることを開示すると、ベースイメージにパッチを適用すればすぐに問題に対処できる場合でも、影響の範囲が実際より大きく誤認される可能性があります。代わりに、重大度に基づく事前合意済みのポリシーよりも、対応のスピードを重視することをおすすめします。これは、チームが行動を起こすうえでより効果的かつ合理的な指標であるため、エンゲージメントが向上します。
データを示す際には、できるだけ多くのコンテキストを伝えることが非常に重要です。そうすることで、正しい結論を導き出すことができます。特に、意思決定者がレポートを見る場合はなおさらです。それを踏まえて、可視化できる未加工の指標と、それに関するユーザーの意見を組み合わせました。これにより、欠けていたコンテキストが明らかになりました。変更時の障害率が高いチームは、リリース プロセスやバッチサイズにも苦労しているのでしょうか?脆弱性に迅速に対処していないチームは、機能の開発に時間をかけすぎて、運用上の問題にも十分な時間をかけられていないと報告していますか?そこで、このような情報を活用するために、別のツールである DX を使用することにしました。続編の記事では、これをどのように行ったかと、その結果テナントに関する収集データの拡大がどのように促されたかについて詳しく説明します。今後の情報にご注目ください。
Google Cloud でのプラットフォーム エンジニアリングを活用したシフトダウンについて、詳しくはこちらをご覧ください。
- アプリケーション プラットフォーム担当 EMEA プラクティス ソリューション リード、Darren Evans
- John Lewis Partnership、プリンシパル プラットフォーム エンジニア、Alex Moss 氏



