プラットフォーム使用の落とし穴(パート 2): 意味のあるモニタリング指標を選択する
Darren Evans
EMEA Practice Solutions Lead, Application Platform
Alex Moss
Principal Platform Engineer, John Lewis Partnership
Try Gemini 3.1 Pro
Our most intelligent model available yet for complex tasks on Gemini Enterprise and Vertex AI
Try now※この投稿は米国時間 2026 年 2 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
この記事のパート 1 では、John Lewis Partnership の Alex Moss 氏が、同社がデベロッパー プラットフォームの価値を測定するために使用している指標について説明しました。ここでは、あらゆる測定戦略の重要な側面である、測定対象の適切な選択について説明します。膨大なデータの中に迷い込んだり、見栄えはするものの、実際にはプラットフォームの健全性やデベロッパーのエクスペリエンスを反映していない指標に注目したりしがちです。ここでは、意味のある指標を選択し、適切な会話と行動を促す方法で提示することにより、データを常に可能な限り多くのコンテキストとともに提示するという John Lewis の理念について、Alex 氏が説明します。- Darren Evans
この記事の前半で詳しく説明したソリューションは非常にうまく機能しましたが、客観的な指標のみに頼ることには、いくつかの落とし穴があります。誤解されやすいため、時間を無駄にしたり(「チームは現在別のプロダクトに取り組んでいる」)、正しい情報を伝えられなかったり(「インシデントは適切にクローズされなかった」)します。その結果、スケーリングの課題が生じます。少数のチームと話して状況を把握することはできます。しかし、プロダクトを構築しようとしているのが 1 つの小さなチームしかなく、数十のチームとやり取りする必要がある場合は、そう簡単ではありません。
エンジニアの主観的なフィードバックを収集する
当社は、主観的なフィードバックを収集する方法を必要としていました。できれば、客観的な DORA やその他のサービス指標と比較して可視化できる形式です。
この最初の試みとして、サービス運用性評価を作成しました。これは、テナントが四半期ごとに記入するアンケートです。サービス運用性評価は、チームがサービスの実行に関する優れたプラクティスに従っているかどうかを調べることを目的とした、示唆に富んだ一連の質問で構成されています。これは、さらに質問を掘り下げて、重要なフィードバックとアクションを引き出すことができる経験豊富なファシリテーター(通常はシニア プラットフォーム エンジニア)がいる場合には有効でした。しかし、ご想像のとおり、この方法ではスケーリングの課題が生じました。最終的に、このプロセスは完全にセルフサービスで処理されるようになりました。これは完璧なシステムではありません。多くのチームは、前の四半期の回答をコピー&ペーストするだけで満足しているからです。その回答が現実を反映しているかどうかはわかりません。
その後、DX プラットフォームと呼ばれるツールについて知りました。このツールは、この問題への取り組み方を大きく変え、現在ではエンジニアリング コミュニティ全体で使用されています。3 か月ごとに数分間、チームではなく個々のエンジニアにアンケートを実施します。質問は、DORA やその他の類似のフレームワークの創設者によって裏付けられた DX の調査に基づいて厳選されます。結果をさまざまな方法で分析できるのは非常に便利でした。プラットフォーム全体にわたる領域を調べることも、特定のチームを詳しく調べることもできます。後者の場合、DORA データと組み合わせれば、充実した会話が生まれます。たとえば、DX ツールでは、大きな影響を及ぼすインシデントを最近経験したチームは「本番環境のデバッグ」に関する懸念を登録した可能性がある一方、リリース頻度が大幅に低下したチームは「変更の信頼性」や「リリースの容易さ」に関する懸念を登録した可能性があります。この時点で、プラットフォーム チームは、チームが抱えている問題に対処するために、アドバイスを提供したり、新しい機能を実装したりできます。
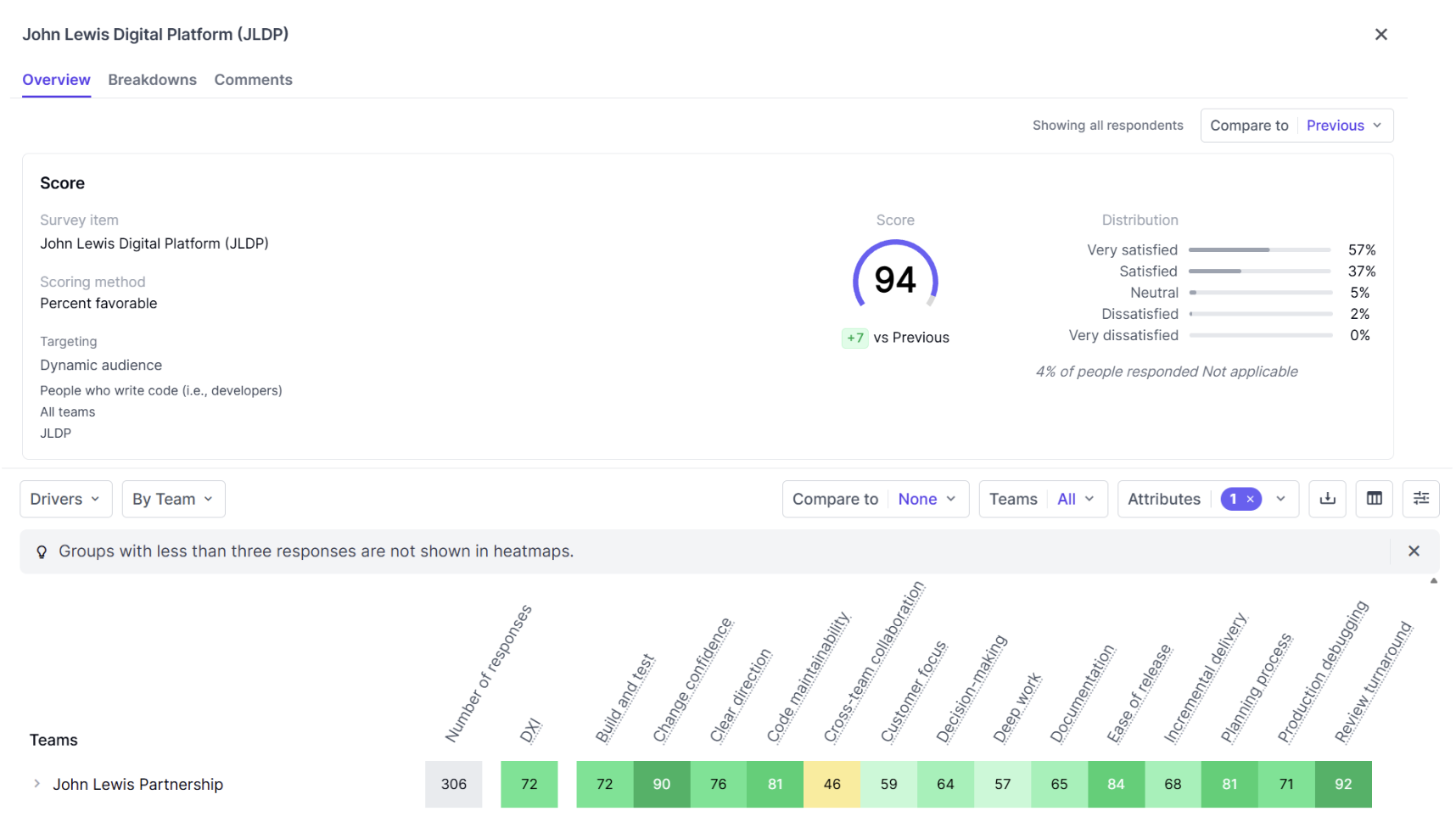
DX の事前構築されたドライバとレポートは非常に便利ですが、当社では、現在の重点分野を把握するため、独自のカスタムクエリも追加しています。たとえば、プラットフォームとそのポータル(Backstage)の顧客満足度(CSAT)を測定したり、新入社員が pull リクエストの送信を開始するまでにかかる時間をデータとして収集したり、オンボーディング プロセスについてどのように感じたかを尋ねたりしています。さらに、最近では、AI コーディング アシスタントの有効性に関するエンジニアの意見を評価し始めました。これは、市場の分析情報に頼るだけでなく、AI コーディング アシスタントへのさらなる投資を正当化するためです。
このアプローチが役立った例として、ドキュメント化があります。具体的には、Backstage デベロッパー ポータルに機能を組み込み、コンテンツを自動的に公開して見つけやすくするパイプラインを通じて、チームが互いのドキュメントを簡単に閲覧できるようにしました。
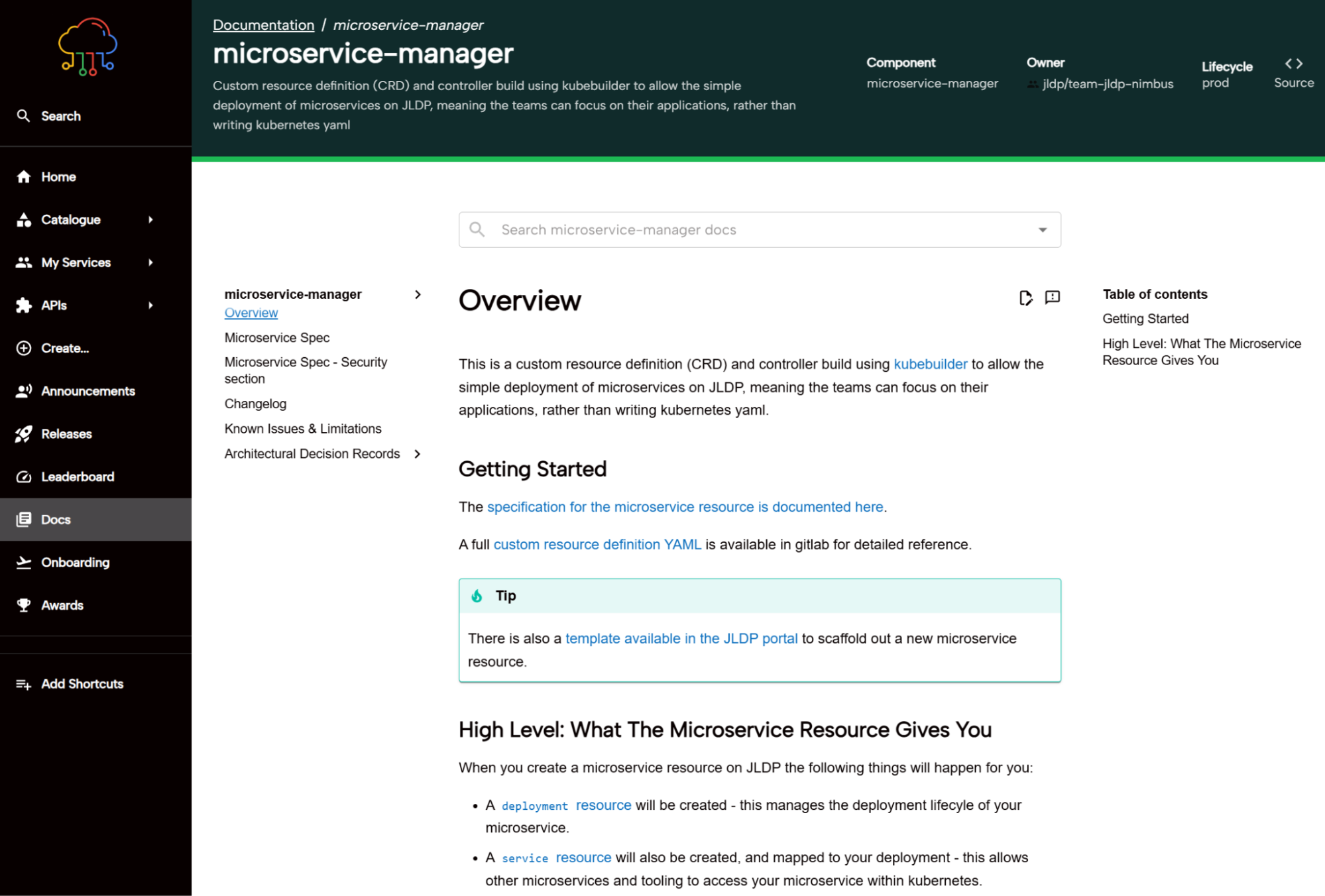
サービスの健全性 - 機能の導入とそれ以降
DORA や DX などから生成される分析情報以外にも、最近では、プラットフォーム自体に価値があるかどうかだけでなく、テナントがプラットフォームから期待される価値を得ているかどうかについても調べ始めています。つまり、プラットフォーム機能の導入結果の測定を効果的に始めたのです。
これを実現するため、社内で「技術的健全性」機能と呼んでいるものを構築しました。これは、カスタム プラグインの形で Backstage デベロッパー ポータルと統合されています。このプラグインは、測定対象に関する情報を収集する多数の小規模なジョブから得られたデータを明らかにする社内 API をクエリします。これらのジョブはそれぞれ独立してリリースできるため、比較的迅速にスケールアップできました。
現在、4 つのカテゴリの健全性指標を収集しています。
-
技術的健全性: 現在、17 の「技術的」指標があります。たとえば、各チームが独自のリソースを「Terraform 化」するのではなく、当社の「Paved Road(舗装された道路)」パイプラインとカスタム マイクロサービス CRD(以前の記事 1 と 2 を参照)を使用しているかどうか、推奨される Kubernetes プラクティス(リソースのサイズ設定、中断予算、ライフサイクル プローブなど)に従っているかどうか、ベースイメージを最新の状態に保っているかどうかを測定することなどが挙げられます。また、変更を反映するためにパイプラインを十分な頻度で実行しているか(チームでは実行していません)、運用性評価を確認しているか、Git ブランチを最新の状態に保っているかなど、「よりソフトな」技術的対策も含まれます。
-
運用準備: 次に、運用面の健全性に関する 18 の指標があります。たとえば、プリフライト構成が整っているか、ランブックが作成されているか、ドキュメントが公開されているかなどです。これは、数年前の運用準備チェックリストの進化版です(当時はデリバリー チームと運用チームが分かれていたため、このようなチェックは「引き渡し」に必須でした)。このチェックリストは、一般的なリストではなく、チームが高い運用性を実現するのに役立つプラットフォームの特定の機能に合わせて調整されています。さらに、適切なプラクティスに従っていることをサービス管理チームが確信できるようになり、手動レビューの実施時に摩擦が生じることもなくなりました。
-
移行: プラットフォーム自体に変更があった場合、テナントはその変更に対応するために随時作業を行う必要があります。この典型的な例として、チームに非推奨の Kubernetes API バージョンに対処してもらうことが挙げられます。これには、古いやり方を排除するために、より強力に推進したいさまざまな機能を導入することも含まれます(たとえば、より安全な方法を優先するなど)。プラットフォームが成長するにつれて、チームが実行する必要がある移行作業が長期間にわたって続くことがわかりました。その結果、プロダクト マネージャーとデリバリー リードがチームのワークロードに優先順位を付けやすくなりました。
-
エンジニアリング プラクティスの拡大: 最近、この機能の使用範囲を広げ、他のチーム(この場合はエンジニアリング リーダーシップ)が独自の指標を組み込めるようにしました。たとえば、チームがデザイン システムのバージョンを最新の状態に保っているかどうかや、JL デジタル プラットフォームだけでなく、より広範なエンジニアリング プラクティスに従っているかどうかなどです。
このデータは、集計ビュー(下の例を参照)や個々のタスク、より広範なリーダーボードを通じて提示されます。これらはすべて、チームの優先事項に影響力を持つ人々の目に留まるように設計されています。エンジニアが信号を青に変えたいという欲求は、ドキュメントや発表に頼るよりもはるかに効果的な、強力なモチベーターになることがわかりました。
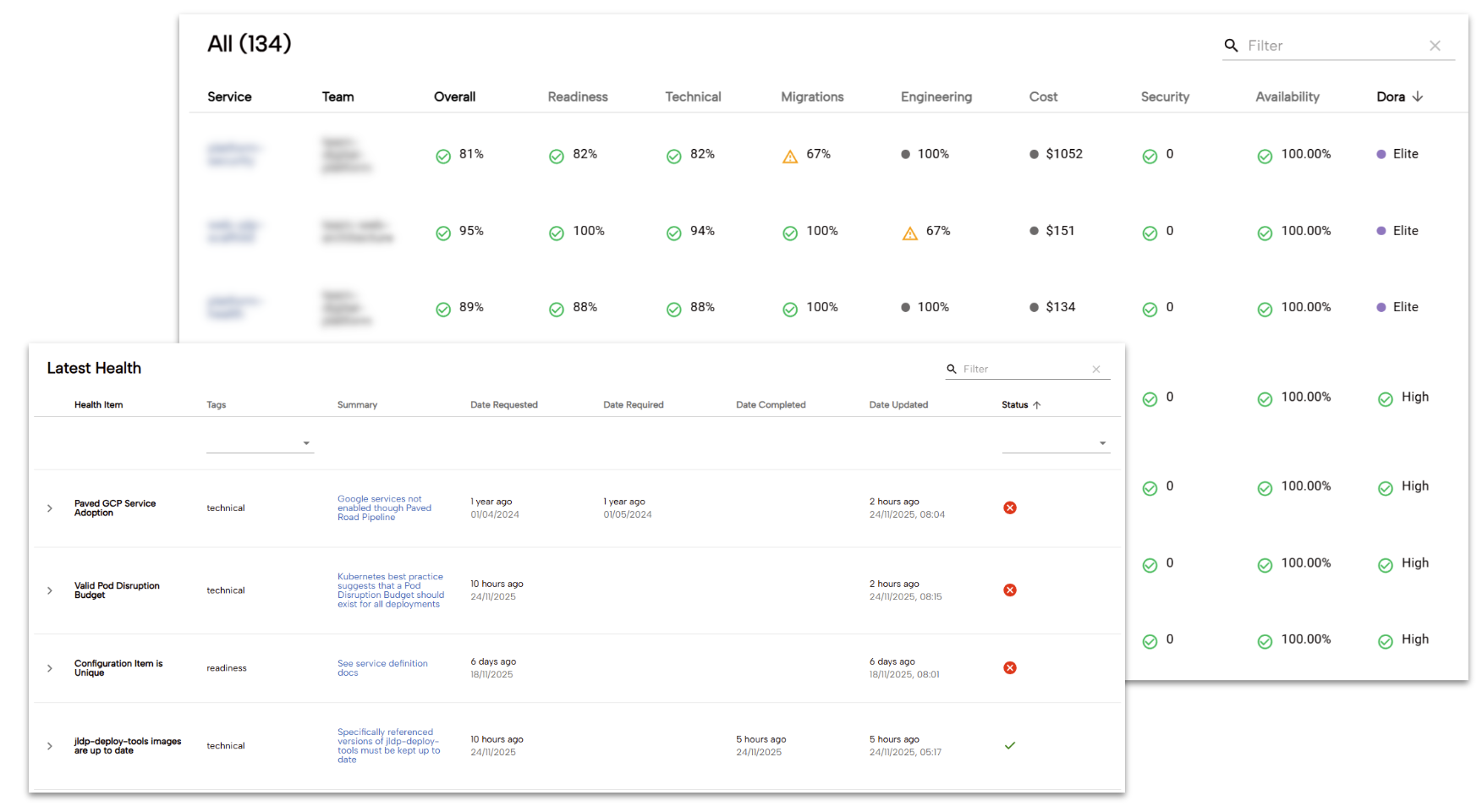
このテクノロジーは、Backstage ポータル用に構築したカスタム プラグインを通じて機能します。各「ヘルスチェック」は、それ自体が独自のマイクロサービス(多くの場合、ジョブとして実行される)であり、該当するシステムを調べて、測定基準が満たされているかどうかを判断します。たとえば、あるマイクロサービスは、Kubernetes に直接クエリを実行して PodDisruptionBudget が作成されていることを確認します。別のマイクロサービスは、コンテナ イメージのレイヤを検査して、distroless のベースイメージが使用されているかどうかを確認します。新しい指標を作成するためのテンプレートが用意されているため、エンジニアは新しい指標を簡単に作成できます。プラットフォーム チーム以外のエンジニアも同様です。結果は BigQuery に保存されます。Backstage プラグインの開発を簡素化する API も用意されています。
このような対策を導入した場合の現実として、プロダクト チームの作業量が増えることが挙げられます。そのためには、組織文化がこの変化に対応できることが重要です。プラットフォームの初期段階でこれらの対策を導入していた場合、製品の認識に影響が及んでいた可能性があります。たとえば、厳格すぎるとか、ガードレールによって変化のペースが阻害されるといった認識です。これは、全体的な導入に悪影響を及ぼす可能性があります。これらの機能を後から導入したことで、プラットフォームを非常に価値あるものとすでに認識していた多くのテナントの恩恵を受けることができました。さらに、適切な対策を選択し、一貫性のある方法で適用できるという自信も得られました。とはいえ、この取り組みを開始した後、プラットフォームの CSAT はわずかに低下しました。プロダクト チームが作業を吸収する時間を確保できるよう、各指標を導入するペースに配慮し、チームが自分たちに関係のない指標を抑制する手段を提供しています。たとえば、テナントがパフォーマンス上の理由で Pod の自動スケーリングを使用しないことを意図的に選択したり、当社のマイクロサービス CRD を使用できない機能上の理由が存在していたりする場合があります。
テナントの行動に関するこのような保証対策の導入は、プラットフォームの成熟度を反映しています。初期の頃は、高度なスキルを持つチームが、正しいことを迅速に行うことを期待していました。しかし、時間が経つにつれて、さまざまなスキルや能力、サービス所有権の移行が組み合わさったことで、適切な成果を上げるための手法を導入する必要に迫られました。これは、プラットフォーム自体が複雑になっていることも原因です。多くの新機能が追加されたため、新しいチームの認知負荷が以前よりもはるかに高くなっています。チームが「Paved Road(舗装された道路)」から外れないように、道路の端に沿ってライトを設置する必要がありました。
この進化の過程で、ビジネス自体の主な成果(つまり、当社はお客様が望むことを今も行っているか?)について報告し続けてきました。そのため、「迅速にチームを支援する」(正直なところ、これはほぼ解決済みの問題と見なされています)から「安全に実行し、技術的負債を管理する」へと自然に移行しました。
プラットフォームは期待に応えている?重要ポイント
要するに、デベロッパー プラットフォームに価値があるかどうかという問題は複雑であり、それに答える方法はさまざまです。独自のデベロッパー プラットフォームの構築と定量化に着手するにあたり、最後に留意すべき点をいくつかご紹介します。
-
測定は目的地ではなく道のりである: 関係者にとって意味のあるものを測定することから始めましょう。ただし、プラットフォームの進化に合わせて適応する準備もしておきましょう。最初は、プロダクトへのさらなる投資を優先してもかまいませんが、プラットフォームがチームにどのように役立っているかを実際に測定することをおすすめします。プラットフォームの実現可能性を最初に実証したときに重要だったことは、数年後に機能が成熟し、優先事項が変わったときには重要ではなくなっている可能性があります。
-
人間の声に耳を傾ける: プラットフォームが使用されているからといって、価値を生み出しているとは限りません。最も効果的な指標は、多くの場合、定性的なものです。エンジニアがツールを使用したいと思っていることや CSAT は重要なシグナルですが、どのように使用しているかを質問することで、どう改善できるかに関するより深い分析情報を得ることができます。測定だけでは、何が効果的で何がそうでないかを把握するのは困難です。
-
データはレポート作成だけでなく、チームの能力向上にも役立てる: グラフを経営陣に見せるだけでなく、分析情報をチームの改善に役立てましょう。さらに、行動の根拠となった具体的なデータを明確に示しましょう。たとえば、特定のチームのリリース頻度が低下していることがわかったら、それを問題として指摘するだけでなく、そのデータを使って潜在的な障害について話し合うきっかけにしましょう。そうすることで、リーダーシップとテナントの両方から信頼と好意を得て、プラットフォームを前進させ続けることができます。
John Lewis Partnership の測定戦略の進化は、説得力のあるケーススタディとして役立ちます。基本的なリードタイム追跡から、DORA の指標とデベロッパーからの定性的なフィードバックを組み合わせた包括的なモデルに移行することで、プラットフォームの真の成功は、単に導入率ではなく、プラットフォームが生み出す真の価値によって定義されることを実証しました。
Google Cloud のプラットフォーム エンジニアリングについて詳しくは、他の記事をご覧ください(プラットフォーム エンジニアリングを駆使して開発者の利便性を強化 - パート 1、パート 2、プラットフォーム エンジニアリングに関する 5 つの誤解: プラットフォーム エンジニアリングとは一体なのか、プラットフォーム エンジニアリングにまつわるさらなる 5 つの誤解)。また、App Hubについてもお読みになることをおすすめします。これは、組織全体でアプリケーション中心のガバナンスを管理するための基盤となるツールです。
- アプリケーション プラットフォーム担当 EMEA プラクティス ソリューション リード、Darren Evans
- John Lewis Partnership、プリンシパル プラットフォーム エンジニア、Alex Moss 氏



