BigQuery 最新情報: 新しい連携クエリ、利用しやすい機械学習、詳細なメタデータ
Google Cloud Japan Team
※この投稿は米国時間 2020 年 1 月 28 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery は、Google Cloud が提供するペタバイト規模のデータ ウェアハウスです。データを素早く取り込んで分析でき、高い可用性を備えているため、新たな知見を得て傾向を把握し、予測を立てて効率的なビジネス運営に役立てることができます。BigQuery のエンジニアリング チームは、皆様にさらに便利にお使いいただけるよう機能の改善を継続的に行っています。最近追加された機能には、新たな連携データソース、BigQuery ML 変換、整数範囲パーティションなどがあります。
ここでは、これらの新機能の詳細と、機能を実際に試していただくための簡単なデモとチュートリアルへのリンクをご紹介します。
BigQuery で ORC 形式と Parquet 形式のファイルに対するクエリを直接実行
Parquet と ORC は、大規模なデータ分析でよく使われるカラム型のオープンソース形式です。データをクラウドへ移行すると、BigQuery を使用してこれらの形式で保存されたデータを分析できます。これらのファイルを Cloud Storage に保管しておくか、データを BigQuery に読み込むか、判断に迷う場合があります。
そこで、Google では BigQuery の標準 SQL インターフェースから、Cloud Storage に保管された Apache の ORC ファイルと Parquet ファイルに対して、連携クエリを実行できるようにしました。以下のデモをご覧ください。

この新機能以外にも、Cloud Bigtable、Google Sheets、Cloud SQL といったストレージ システムのほか、Cloud Storage での AVRO、CSV、JSON 形式ファイルの読み込みなど、BigQuery 内で連携クエリを実行するための機能は以前から存在します。これらはすべて、BigQuery をオープンでアクセスしやすいデータ ウェアハウスにするための取り組みの一環として開発された機能です。詳しくは、このリリースに関するブログ投稿をご覧ください。
演習: 膨大な数のおすすめを読み込んでクエリを実行する
映画がお好きな方にぴったりの、クエリ連携を試す方法をご紹介します。ここでは、2,000 万件以上の映画評価データを分析して、Cloud SQL、BigQuery の連携クエリ、BigQuery のネイティブ ストレージの分析パフォーマンスを比較します。コード ワークブックを起動して、動画の手順に沿って操作してください。Google Cloud アカウントをお持ちではない場合は、無料で登録してからお試しください。
BigQuery ML による新たなデータ変換
機械学習(ML)モデルが成功するかどうかは、トレーニングに使用するデータセットの品質に大きく左右されます。特徴量エンジニアリングの際に、トレーニング データの前処理を行うと複雑になることがあります。これは特に、予測時に本番環境データを同様に変換する必要がある場合に起こります。
Google Cloud は、単純な SQL 関数を使ってデータを前処理して変換できる、BigQuery ML の新機能を発表しました。また、BigQuery は予測時点でこうした変換を自動的に適用するので、ML モデルの本稼働を大きく簡易化できます。
ML.BUCKETIZE によるデータ値のビン化
ML モデルを構築する際、特定のディメンションに関する十分なデータがない場合、レコードを破棄するかどうかの判断を迫られることがあります。たとえば、ニューヨーク市内のタクシー運賃を評価する場合に、一度しか出現しない緯度と経度の降車地点への乗車データは破棄するか、という判断です。こうした場合によく使われるのが、緯度や経度のような連続値を個別のビンとしてバケット化する方法です。この方法なら、ロングテールに含まれる出現率の少ない降車地点も破棄することなくグループ化できます。
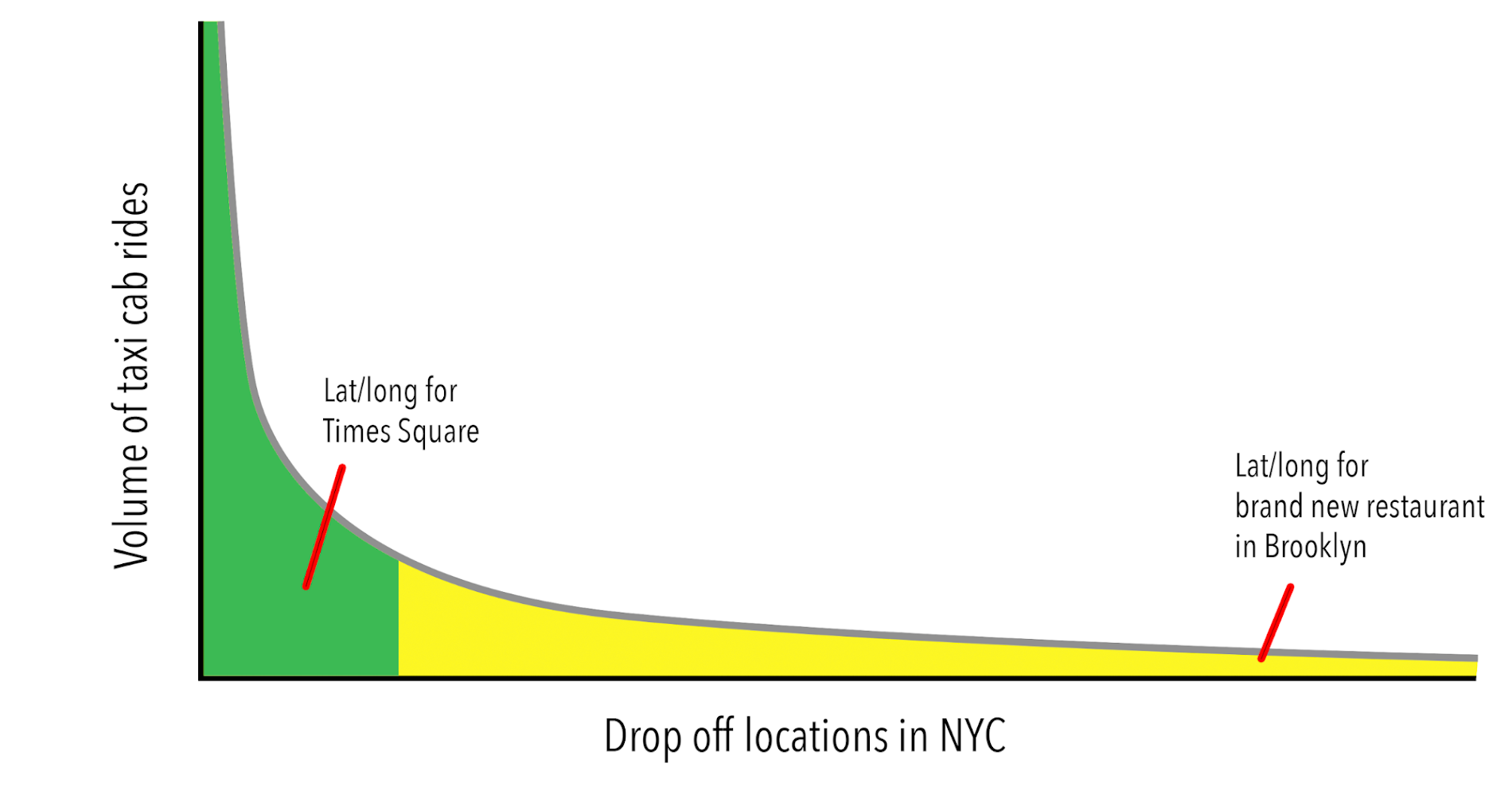
サポートを提供しています。ニューヨーク境界の緯度と経度を既知の値とした、入力のバケット化の例をみましょう。
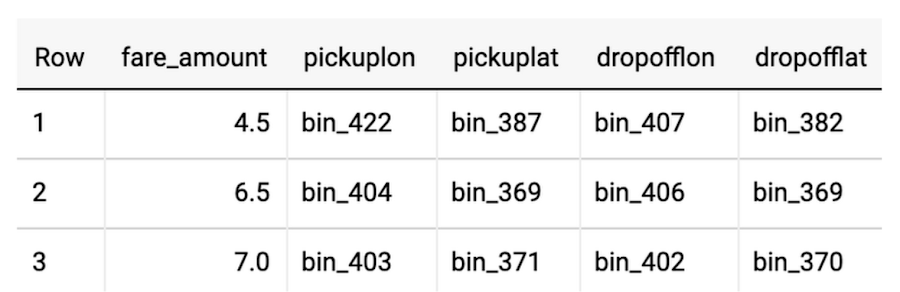
BigQuery ML では、新しい TRANSFORM 句内に必要な変換をすべてラップすることで、サービス提供時に同じ前処理のステップを実行できるようになりました。これにより、トレーニング時に元の予測データに対し行ったのと同じデータ変換を、本番環境に実装するよう覚えておく必要がなくなります。ニューヨーク市のタクシー運賃予測の詳細な例を紹介した別のブログ投稿もぜひご覧ください。また、詳細については BigQuery ML の前処理に関するドキュメントをご覧ください。
BigQuery Reservations で定額料金プランを使用
米国と欧州のリージョンで、BigQuery Reservations のベータ版をご利用いただけるようになりました。BigQuery Reservations では、BigQuery スロットをシームレスに購入して、お得な定額料金でご利用いただけます。これにより、BigQuery の費用を完全に予測して管理することが可能になります。
BigQuery Reservations では次のことができます。
コミットメントを調達することによって、専用の BigQuery スロットを簡単に購入する
コミットした BigQuery スロットをプログラムで動的に個々の予約に分散させて、ワークロードを
管理する割り当てを使用して、Google Cloud プロジェクト、フォルダ、組織全体を予約に割り当てる

INFORMATION_SCHEMA でメタデータを素早く分析
データ エンジニアやアナリストがデータセットやテーブル名を受け取る際、その内容や構成に関する情報がほとんど、あるいは一切提供されないことがよくあります。データを探索して知見を得るうえで、データセットにどのようなテーブルや列が含まれているかを把握しておくことは不可欠です。これまでも、BigQuery UI でデータのプレビューを選択するか、各テーブル名をクリックしてスキーマを調べることはできました。新たに加わった INFORMATION_SCHEMA なら、SQL を使用してこうしたタスクを大規模に実行できます。
データセットに含まれるテーブルの数を素早く把握するにはどうすればよいでしょうか。列の合計数と各列の名前、それらの列がパーティション分割されているか、クラスタ化されているかを知るにはどうすればよいでしょうか。BigQuery には、データセット、テーブル、列に関するこうしたあらゆるメタデータがクエリ可能な形式でネイティブに保存されています。INFORMATION_SCHEMA を使えば、こうしたメタデータに簡単にアクセスできます。
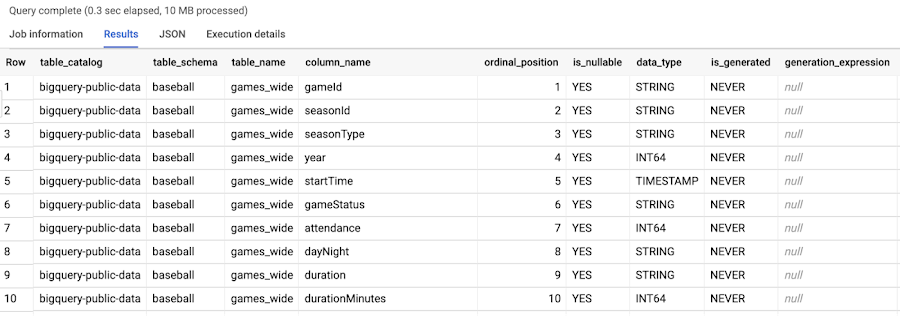
上記のように、INFORMATION_SCHEMA.COLUMNS を使用すると、すべての列の一覧と「baseball」データセットに含まれるすべてのテーブルのデータの種類を取得できます。
さらにこのクエリを拡張すると、以下のような有用な指標を集計できます。
テーブルの数
テーブルの名前
列の合計数
パーティション分割された列の数
クラスタ化された列の数

上記のクエリを、github_repos や new_york のようなさまざまな一般公開データセット、さらにご自身の Google Cloud プロジェクトとデータセットで試してみてください。
演習: INFORMATION_SCHEMA で BigQuery パブリック データセットとテーブル メタデータを素早く分析する
こちらの 10 分間のデモ動画とコード ワークブックで、データセット メタデータを分析する練習をしましょう。
また、INFORMATION_SCHEMA についてのドキュメントもご確認ください。
整数範囲によるテーブルのパーティショニング
テーブルのパーティショニングをネイティブにサポートする BigQuery では、大規模なデータセットを容易に管理して素早くクエリを実行できます。データに含まれるタイムスタンプ、日付、整数範囲のどれを使用してテーブルを分割するかを選択できます。
整数範囲パーティション分割テーブルの作成
パーティションに分割したい customer_id フィールドを含む、大規模なトランザクション データセットがあるとします。テーブルを設定すると、テーブル全体をスキャンしなくても特定の顧客でフィルタできるようになるため、高速なクエリの実行とより細やかなコスト管理が可能になります。
この例では Console UI を使用して、デフォルトのプロジェクトの mydataset 内に「mypartitionedtable」という名前の整数範囲パーティション分割テーブルを作成します。
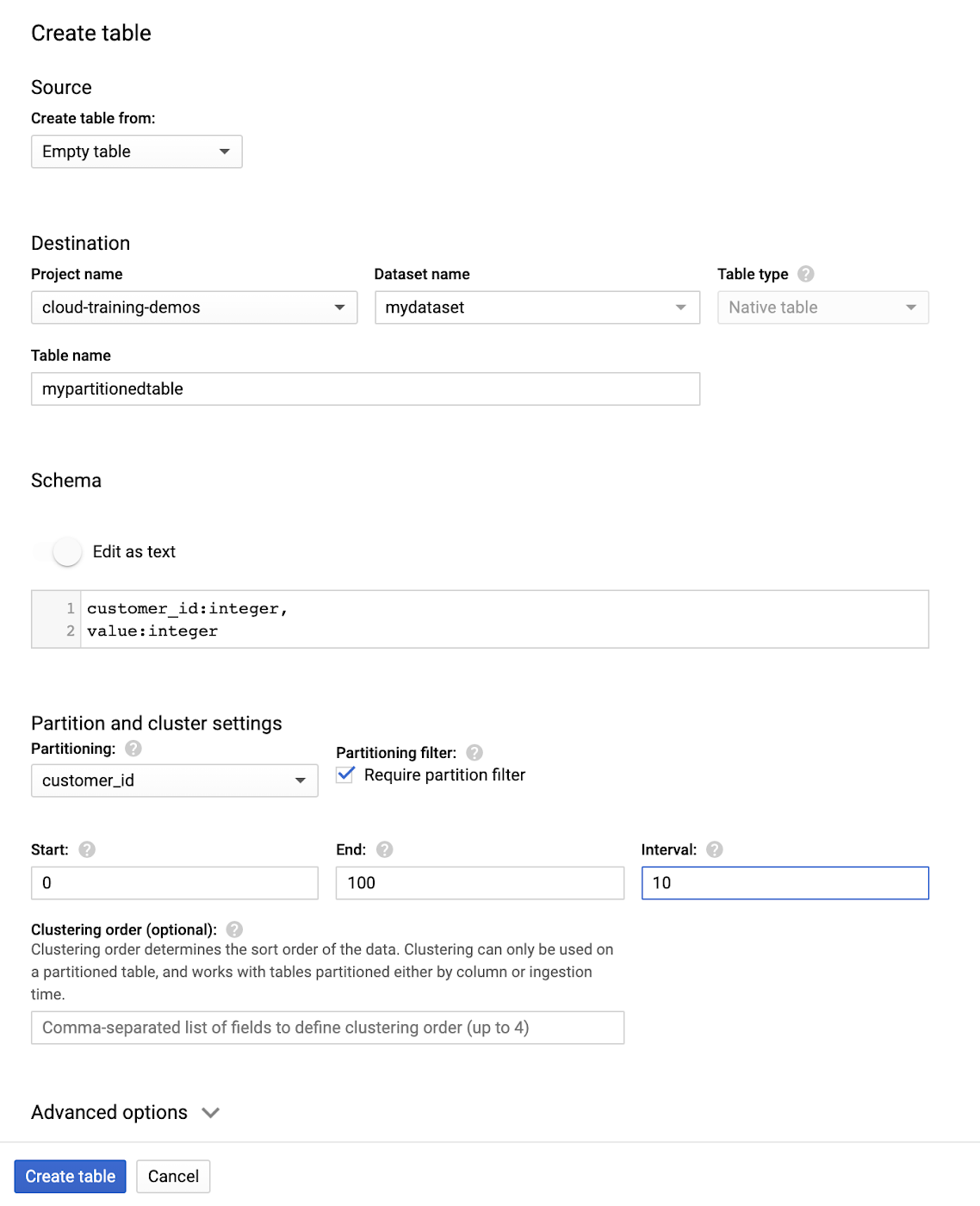
BigQuery CLIを使用した同様のコマンドは次のとおりです。
パーティショニングは開始値 0、終了値 100、間隔 10 で行われます。つまり、0 から 100 までの顧客 ID があり、それを 10 のグループで分割します(ID 0~9 が 1 つのパーティションにまとめられ、以降の ID も同様の方法でまとめられます)。なお、整数範囲パーティション分割テーブルに書き込まれる新しいデータは、自動的に分割されます。これには、読み込みジョブ、クエリ、ストリーミングによる書き込みも含まれます。時間が経過してデータセットが変化しても、BigQuery によりデータが自動的に再パーティショニングされます。
テーブル デコレータで特定のパーティションを操作
テーブル デコレータを使用すると、データの特定のセグメントに素早くアクセスできます。たとえば、最初のパーティション(0~9 の ID 範囲)内のすべての顧客にアクセスする場合は、テーブル名に「$0」という接尾辞を付けます。
この方法ならデコレータを使用してパーティションを指定するだけで済むため、追加データを読み込む必要がある場合に特に便利です。
整数範囲パーティションについて詳しくは、整数範囲パーティション分割テーブルのドキュメントをご覧ください。
その他の関連資料
BigQuery に関するあらゆる情報をご確認いただける、最近の投稿、動画、ハウツー資料を以下にご紹介します。
BigQuery 監査ログの新機能の一般提供を開始
永続的な SQL UDF の一般提供を開始
新しい書籍『BigQuery: The Definitive Guide』(Jordan Tigani、Valliappa Lakshmanan 共著)を読む
BigQuery に関する最新情報を把握したい方は、リリースノートの配信にご登録ください。無料の BigQuery サンドボックスをお試しいただけます。ご不明な点がございましたら、お気軽にお問い合わせください。
-by Evan Jones, Technical Curriculum Developer, Google Cloud
