BigQuery での機械学習用にデータ変換を簡素化
Google Cloud Japan Team
※この投稿は米国時間 2019 年 12 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
構造化データ上で機械学習モデルを構築するには、通常、大量のデータを変換する必要があります。さらに、こうした変換は予測時に適用する必要もあるため、モデルのトレーニングを担当したデータ サイエンス チームではなく、データ エンジニアリング チームが担当する場合が少なくありません。この 2 つのチームで使用するツールセットが異なると、トレーニングと推論で一貫した変換を維持することは極めて難しくなります。そこで、単純な SQL 関数を使ってデータを前処理して変換できる、BigQuery ML の新機能をご紹介します。また、BigQuery は予測時点でこうした変換を自動的に適用するので、ML モデルの本稼働を大きく簡易化できます。
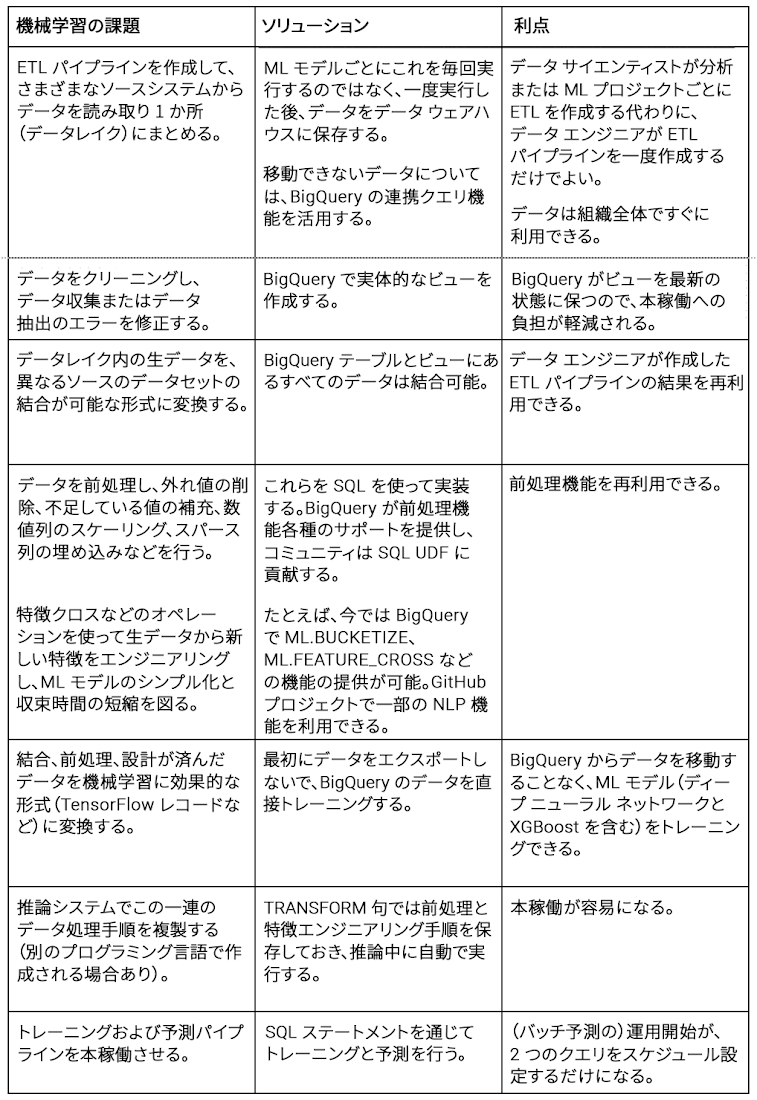
調査的なデータ マイニングに関する 2003 年発行の書籍の中で、著者の Dasu 氏と Johnson 氏はデータ分析の 80% がデータのクリーニングに費やされているとしています。機械学習にも同じことが言えます。Google Cloud でも、機械学習プロジェクトでは機械学習用のデータの準備に時間のほとんどを費やしていることがわかっています。データの準備には次のようなタスクが含まれます。
ETL パイプラインを作成して、さまざまなソースシステムからデータを読み取り 1 か所(データレイク)にまとめる
データをクリーニングし、データ収集またはデータ抽出のエラーを修正する
データレイク内の生データを、異なるソースのデータセットの結合が可能な形式に変換
するデータを前処理し、外れ値の削除、不足している値の補充、数値列のスケーリング、
スパース列の埋め込みなどを行う特徴クロスなどのオペレーションを使って生データから新しい特徴をエンジニアリングし、ML モデルのシンプル化と収束時間の短縮を図る
結合、前処理、設計が済んだデータを機械学習に効果的な形式(TensorFlow レコードなど)に変換する
推論システムでこの一連のデータ処理手順を複製する(別のプログラミング言語で作成される場合あり)
トレーニングおよび予測パイプラインを本稼働させる
組み込みの機械学習でデータ ウェアハウスを活用
機械学習プロジェクトはデータのラングリングとデータの移動がほとんどです。プロジェクトごとにカスタム ETL パイプラインを作成してデータをデータレイクに移動し、データを把握し結合可能な形式に変換するタスクをすべての ML プロジェクトに課す代わりに、組織のエンタープライズ データ ウェアハウス(EDW)を構築することをおすすめします。EDW がクラウドベースかつ(BigQuery のように)コンピューティングとストレージが分離していれば、事業部門に関係なく、あるいは外部のパートナーであっても、データを移動することなくデータにアクセスできます。この場合、データへのアクセスに必要になるのは、適切な Identity and Access Management(IAM)の役割だけです。
このタイプの EDW の場合、データ エンジニアリング チームが ETL パイプラインを一度作成すると、ソースシステムの変更をキャプチャしてデータ ウェアハウスにフラッシュできるので、機械学習チームはそれらを 1 つずつコーディングする必要がなくなります。データ サイエンティストはデータ形式の変換をする必要がなくなり、データから分析情報を取得することに集中できます。また、EDW に機械学習機能が備わっていて、AI Platform などの強力な機械学習インフラストラクチャとの統合が可能な場合、データの移動はまったく必要ありません。Google Cloud 上の BigQuery ML でディープ ニューラル ネットワーク モデルをトレーニングすると、実際のトレーニングはシームレスに結合された AI Platform で実行されます。
たとえば、ニューヨークのタクシーのデータセットを使って乗車運賃を予測する機械学習モデルをトレーニングするには、SQL クエリがあれば十分です(詳細は以前のブログ記事をご覧ください)。
スケジュール設定されたクエリで本稼働
モデルのトレーニングが終了したら、乗車地点と降車地点を入力してその区間の乗車運賃を決定できます。
次のように返されます。

機械学習機能を備えた BigQuery のようなクラウドベースの最新 EDW を使用すると、データの移動に関連する問題のほとんどが解消されます。ご覧のとおり上記のクエリでは SELECT ステートメントだけで ML モデルをトレーニングできています。これで本記事の冒頭で指摘した最初の 3 つの問題点が解決したことになります。ML モデルのトレーニングを本稼働に移してバッチ予測を実行する作業は、上記の 2 つの SQL クエリをスケジュール設定するだけとなり、本稼働関連の問題点が大幅に軽減されます。
今回ご紹介する BigQuery ML の前処理および変換機能は、残りの問題点に対処するための機能です。これにより、データを効率よく改変し、モデルをすばやく学習して、トレーニングと結果のズレに臆することなく予測を実行できます。
BigQuery ML で前処理を行う
データ ウェアハウスは幅広いデータ分析タスクに適応可能な方法で生データを保存します。たとえば、ダッシュボードがデータ ウェアハウス内のデータを表示し、データ アナリストがアドホック
クエリを実行するというのが一般的ですが、機械学習モデルをトレーニングする場合に通常必要になるのは、生データでトレーニングすることではなく、外れ値を除外し、バケット化やスケーリングなどのオペレーションを行ってトレーニング精度や収束精度を向上させることです。
SQL でフィルタリングを行うには、次のように WHERE 句を使います。
データのクリーニングと修正に必要となるオペレーションを決定したら、実体的なビューを作成できます。
BigQuery の実体的なビューは現在アルファ版です。代わりに論理ビューを使用するか、データを新規テーブルにエクスポートするかを選択できます。ML コンテキストで実体的なビューを使用する利点は、BigQuery のデータを常に最新の状態に保つための負担を減らせる点です。元のテーブルに新しい行が追加されると、クリーンアップされた行が実体的なビューに表示されます。
スケーリングも同様に、SQL に実装できます。たとえば、次のコードは 4 つの入力フィールドをゼロノルムにします。
これらのスケーリングされたデータを実体的なビューに保存することもできますが、平均値と分散値は時間とともに変化するため、これを行うことはおすすめしません。このスケーリング オペレーションは(ここでは平均値と分散値を計算するのに)分析パスを必要とする ML の前処理の一例です。分析パスの結果は新しいデータが追加されると変わるので、ML トレーニング クエリの一部に分析パスが必要な前処理オペレーションを行うことをおすすめします。また Google Cloud ではコミュニティ GitHub リポジトリで定義された利便性の高い UDF を利用しています。
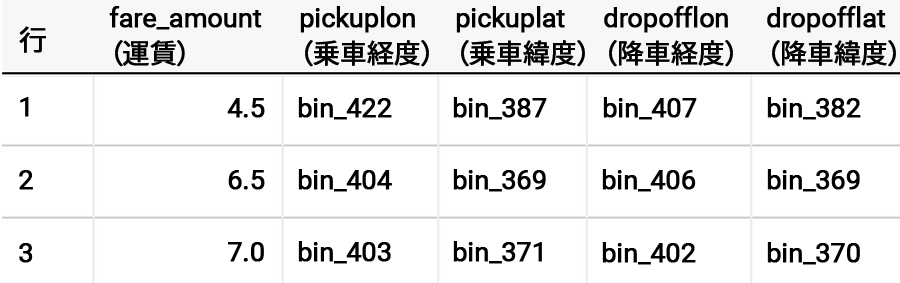
BigQuery では、データを個別に分析する必要のない、一般的な各種機械学習オペレーションをすぐに使えるようサポートを提供しています。入力のバケット化を例に取り、ニューヨークの緯度と経度の境界を割り出してみましょう。
フィールドはカテゴリ化されて、乗車地点と降車地点がビンに対応していることがわかります。
TRANSFORM を使用してトレーニングと結果のズレを低減
上記のようにモデルをトレーニングする場合の問題は、本稼働がかなり難しくなるという点です。
モデルに緯度と経度を送信するだけという単純なものではありません。それどころか、予測パイプラインで前処理手順を覚え、複製もしなくてはいけません。
TRANSFORM キーワードのサポートをご紹介する理由がここにあります。すべての前処理オペレーションを特別な TRANSFORM 句に挿入すると、予測中に BigQuery ML が同じ前処理オペレーションを自動的に実行します。これにより、トレーニングと結果のズレを低減できます。
例として、GIS 数量の計算、タイムスタンプからの特徴抽出の実行、特徴クロスの作成、さまざまな乗車ビンと降車ビンの連結(極めて複雑な前処理)を下に示します。
予測コードは非常に単純でシンプルなままなので、前処理手順を複製する必要はありません。
これらの新機能をどうぞご利用ください。
スタートガイド:
ドキュメントにある前処理用機能リストをご確認ください。
この記事に引用したクエリについては、こちらの 2 つの GitHub ノートブックをご覧くだ
さい。AI Platform ノートブックまたは Colab でお試しください。BigQuery ML について詳しくは、こちらの Qwiklabs のクエストをご覧ください。
BigQuery での機械学習に関する詳しい解説は、『BigQuery: The Definitive Guide』の第 9 章をご覧ください。



