Google Cloud での Dataproc Metastore のデプロイ パターン
Rajashekar Pantangi
Big Data & Analytics Cloud Consultant
Vince Gonzalez
Data & Analytics Engineering Manager
※この投稿は米国時間 2024 年 7 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
ビッグデータを扱う方であれば、Apache Hive や、ビッグデータ エコシステムでのメタデータ管理におけるデファクト スタンダードとなっている Hive Metastore についてよくご存じかと思います。Dataproc Metastore は、Google Cloud 上で実行されるフルマネージド Apache Hive メタストア(HMS)です。Dataproc Metastore は、高可用性、自動修復型、自動スケーリング、サーバーレスです。これらすべての機能を活用してデータレイクとメタデータを管理し、使用しているさまざまなデータ処理エンジンとツール間の相互運用性を実現します。
複数の Hive メタストアを備えたオンプレミスの Hadoop 環境から Google Cloud 上の Dataproc Metastore への移行を進めている場合、Dataproc Metastore(DPMS)を効果的に整理する方法を必要としているのではないでしょうか。DPMS アーキテクチャを設計する際には、集中化と分散化、シングル リージョンとマルチリージョン、永続性と連携など、考慮すべき重要な要素があります。これらのアーキテクチャに関する決定事項は、メタデータのスケーラビリティ、レジリエンス、管理性に大きな影響を与える可能性があります。
今回のブログ投稿では、4 つの DPMS デプロイ パターンについて説明します。
-
集中型マルチリージョン DPMS
-
ドメインごとの DPMS による集中型メタデータ連携
-
ドメインごとの DPMS による分散型メタデータ連携
-
エフェメラル メタデータ連携
これらの各パターンにはそれぞれの長所があり、組織のニーズに最適なものを判断するヒントになります。設計は複雑さと成熟度による昇順で示されているため、組織の特定の DPMS 要件と使用状況に基づく最適なパターンを選択できます。
注: このブログ投稿の文脈では、ドメインとは、組織内の事業単位、部門、または機能領域を指します。各ドメインには、固有の要件、データ処理のニーズ、メタデータ管理手法がある場合があります。
それぞれのパターンを詳しく見ていきましょう。
1. 集中型マルチリージョン Dataproc Metastore
この設計は、ドメイン数が限られていて、すべてのメタストアを単一のマルチリージョン(MR)Dataproc Metastore に統合できる、比較的シンプルなユースケースに適しています。
この設計では、ドメイン全体のすべてのメタストアを中央の共有プロジェクト内に統合することで、単一のマルチリージョン DPMS がデプロイされます。この設定により、組織内のすべてのドメイン プロジェクトがこの集中型 DPMS からメタデータにアクセスできるようになります。この設計の主な目標は、ドメイン数が限られていてユースケースが比較的単純な組織に、わかりやすく管理しやすいソリューションを提供することです。
Dataproc Metastore サービスを作成する際は、サービスが配置される地理的位置(リージョン)を永続的に設定します。シングル リージョンかマルチリージョンを選択できます。マルチリージョンとは、2 つ以上の地理的場所を含む大きな地理的領域であり、より高い可用性が得られます。マルチリージョンの Dataproc Metastore サービスは、データを 2 つの異なるリージョンに保存し、これらの 2 つのリージョンを使用してワークロードを実行します。たとえば、マルチリージョン nam7 には、us-central1 リージョンと us-east4 リージョンが含まれます。
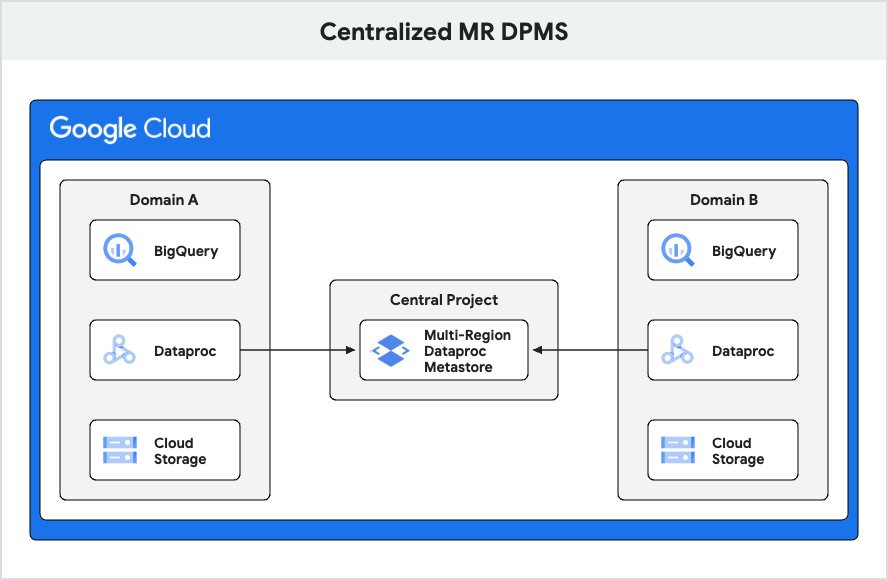
この設計の長所:
-
複数のメタストアを単一の DPMS に統合することで、メタデータ管理を簡素化し、データ環境の複雑さを軽減できます。
-
権限 / アクセス権の管理がより簡単になります。
2. ドメインごとの DPMS による集中型メタデータ連携
この設計は少し高度で、それぞれ独自の DPMS を持つ複数のドメインがあり、それらを単一のメタストアに統合できない場合に使用します。このような場合でも、ドメイン間でのコラボレーションやメタデータの共有を可能にしたい場合は、メタデータ連携と呼ばれる基本ブロックを活用することで実現できます。
メタデータ連携は、1 つのエンドポイントから複数のメタデータ ソースにアクセスできるようにするサービスです。このブログの執筆時点では、これらのソースには Dataproc Metastore、BigQuery データセット、Dataplex レイクが含まれます。連携サービスは、gRPC(Google リモート プロシージャ コール)プロトコルを使用してこのエンドポイントを公開します。このプロトコルは、メタストア間のソース順序をチェックして必要なメタデータを取得することにより、リクエスト処理を容易にします。gRPC は高いパフォーマンスで知られており、分散システムの構築に広く使用されています。
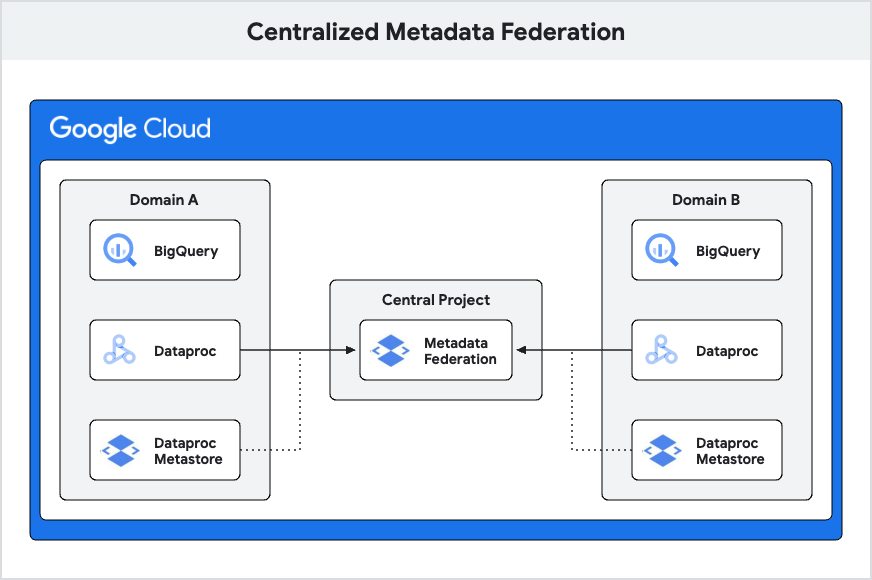
連携を設定するには、連携サービスを作成し、メタデータ ソースを構成します。その後、サービスはすべてのメタデータにアクセスするために使用する 1 つの gRPC エンドポイントを公開します。この設計では、各ドメインが独自の Dataproc Metastore を所有して管理する責任を負います。中央プロジェクトは、各ドメインの DPMS と BigQuery リソースを統合する Metastore Federation をホストします。この設定により、チームが自律的に活動してデータ パイプラインを開発し、メタデータにアクセスできるようになります。必要に応じて、チームは連携サービスを利用して他のドメインのデータやメタデータにアクセスすることが可能です。
この設計の長所は次のとおりです。
-
ドメインごとの DPMS: 各ドメインが独自の Dataproc Metastore を持つことで、メタデータとデータアクセスの境界が明確になり、管理とアクセス制御が簡素化されます。
-
集中型 Metastore Federation: 集中型の連携により、すべてのドメインにわたるメタデータの統合ビューが提供され、エコシステム全体の包括的な概要に容易にアクセスできるようになります。
3. ドメインごとの DPMS による分散型メタデータ連携
この設計はさらに少し高度で、各ドメイン内に複数の DPMS インスタンス(シングル リージョンとマルチリージョン)がある場合に使用します。ドメイン内の各チームで独自の DPMS を所有・管理してもらいたい一方で、単一ドメイン内のすべての DPMS インスタンスを結びつけ、ドメインのメタストア全体でのコラボレーションを可能にするメタデータ連携も必要としているような場合です。
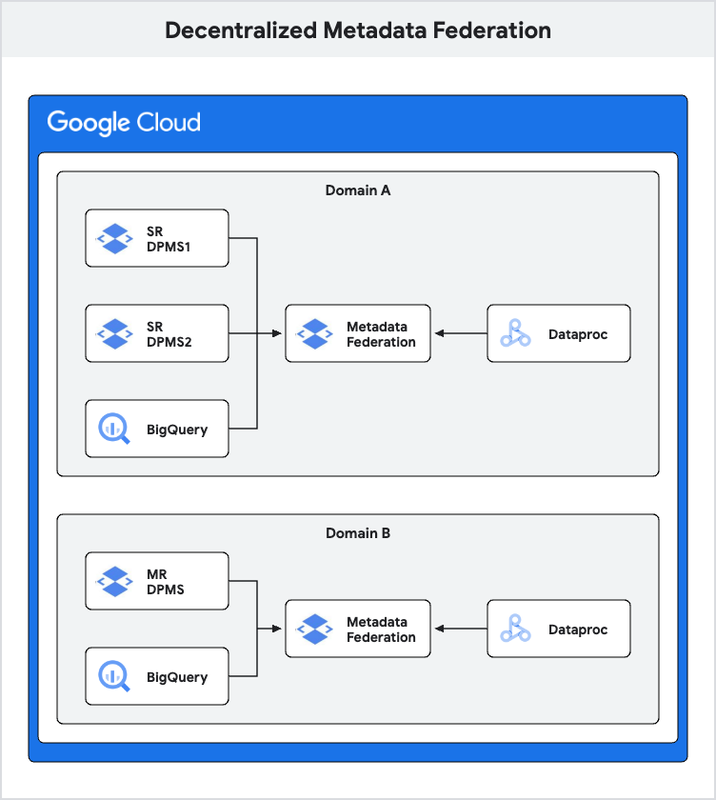
このアーキテクチャでは、各ドメインが独自の Dataproc Metastore(複数の DPMS インスタンスまたは 1 つの統合 MR DPMS で構成)を管理します。Metastore Federation はドメインごとに確立され、ドメイン内の DPMS インスタンス(1 つ以上)、BigQuery、Dataplex レイクを接続します。この連携サービスは、上述の集中型メタデータ連携セクションで説明されているメタデータ連携のコンセプトに基づいて、必要に応じて他のドメインのメタデータ(DPMS、BigQuery、レイク)を統合することもできます。
この設計の長所は次のとおりです。
-
DPMS に計画外の障害が発生した場合の影響は、単一の MR DPMS シナリオ(設計 1)と比較して大幅に軽減されます。
-
必要な DPMS インスタンスのみが連携に含まれ、DPMS インスタンスをつなぎ合わせる順序によってメタデータ検索の順序と競合時の優先順位が決まるため、連携を通じて複数の DPMS を検索する際のレイテンシが最小限に抑えられます。
-
ローカル メタストアと ETL に必要なものだけが連携に含まれるため、名前空間の問題が軽減されます。
4. エフェメラル メタデータ連携
ドメイン内でのメタデータ連携について説明した先述の設計を基に、このコンセプトをさらに拡張して、ドメイン間でのエフェメラル連携を有効にできます。この設計は、異なるプロジェクトやドメインにまたがる複数の DPMS インスタンスのメタデータに一時的にアクセスする必要がある ETL ジョブに対して特に有効です。
この設計では、エフェメラル連携を活用して ETL の目的に応じてメタストアを動的につなぎ合わせます。ETL ジョブでドメインの DPMS や BigQuery で利用可能なメタデータ以外の追加のメタデータにアクセスする必要がある場合は、プロジェクト間で他の DPMS インスタンスを含むエフェメラル連携を作成するオプションがあります。このようなエフェメラル連携により、ETL ジョブは追加の DPMS から必要なメタデータにアクセスできるようになります。この設計でも、Metastore Federation をビルディング ブロックとして活用します。
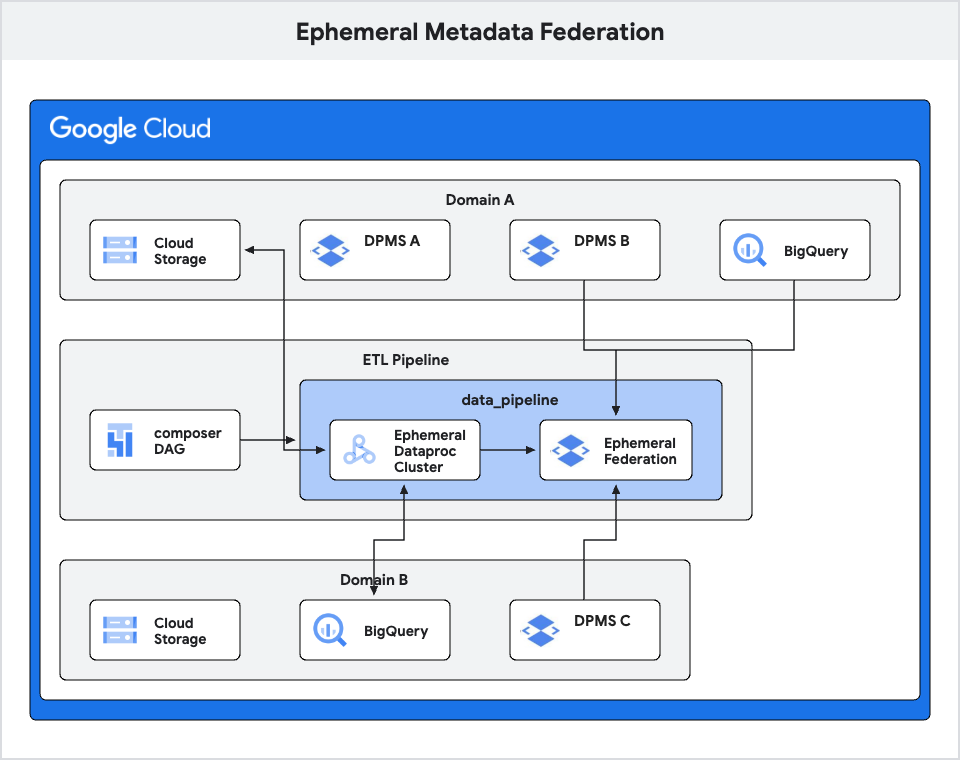
エフェメラル連携アプローチの主な長所は、必要に応じて ETL ジョブやワークフローごとに異なる DPMS インスタンスを動的に指定して結合できる柔軟性です。これにより、静的で広範な連携構成ではなく、必要なメタストアのみに連携を限定できます。エフェメラル連携設定は、Dataproc クラスタを作成するときにオーケストレーションし、Airflow DAG に統合できます。つまり、エフェメラル連携のプロビジョニングと破棄は完全に自動化され、ETL ジョブの実行中に並行して実行されます。
まとめ
組織の目標とインフラストラクチャの機能に合致させるため、DPMS の各デプロイパターンの長所と短所を理解することは極めて重要です。最適な設計パターンを選択する際には、以下のポイントを考慮してください。
-
ドメイン数、チーム数、データ処理要件など、データ環境の複雑さを評価する。
-
組織におけるドメイン間のコラボレーションとメタデータ共有に対するニーズを評価する。
-
データの自律性の重要性と、各ドメインがメタデータに対して必要とする管理レベルを考慮する。
-
メタデータ管理アーキテクチャにおいて、シンプルさと柔軟性のベストなバランスを決定する。
これらの要素を慎重に評価し、さまざまな設計パターン間の長所と短所を理解することで、シンプルさ、スケーラビリティ、コラボレーション、レジリエンスの適切なバランスを保ちながら、大規模なメタデータ管理を確実に成功させる情報に基づいた意思決定を実現できます。Dataproc Metastore を作成するには、こちらをクリックしてください。
ー ビッグデータおよび分析担当クラウド コンサルタント、Rajashekar Pantangi
ー データ分析エンジニアリング マネージャー、Vince Gonzalez

