完全セルフサービスで BigQuery の本番環境のサンプルを取得
Gustavo Kuhn Andriotti
Strategic Cloud Engineer, Google Cloud
※この投稿は米国時間 2024 年 7 月 9 日に、Google Cloud blog に投稿されたものの抄訳です。
パート 1 のおさらい: BigQuery から最新の本番環境サンプルを取得する際の問題を解決するソリューションを提案します。このソリューションは、誤ってデータが引き出されるのを防ぐ安全対策を提供します。また、セルフサービスであるため最新のサンプルを毎日取得でき、古いスキーマや最新でないサンプルを使わなくて済むようになります。
BigQuery の本番環境のサンプルを取得する方法、タイミング、理由については、このトピックに関する最初の投稿(コードはこちら)をご覧ください。
仕組みと詳細
この方法が実際に役に立つのか、組織のセキュリティ ポリシーに沿ったソリューションなのか疑問に思っている方のために、詳しい活用方法をご説明します。
前提条件
ここでは、DevOps 担当者がサンプルを準備することを希望しておらず、データ サイエンティストがセルフサービスでサンプルを取得できるようにするのが好ましいと仮定します。なぜなら、データを引き出す作業は DevOps の任務ではなく、データ サイエンティストが対象分野のエキスパートとして対応すべき領域だからです。
DevOps 担当者の場合
この例では、本番環境にある特定のテーブルのデータにアクセスできるかどうかを 1 回だけ評価するとします。また、各サンプル リクエストに手動で介入することは避けます。この場合、ポリシーというシンプルな JSON ファイルに評価をエンコードできます。
ポリシー
以下の JSON の例には、limit と default_sample という 2 つのセクションがあります。
-
limit: テーブルから取得できるデータの最大量を定義します。
countまたはpercentage、あるいはその両方を指定します。両方を指定した場合、percentage は count に変換され、percentage(count に変換された値)とcountのうちの最小量が使用されます。 -
default_sample: リクエストが存在しないか「不良」の場合(JSON 形式でない、空のファイルなど)に使用されます。
例:
データ サイエンティストの場合
この例では、データ サイエンティストが本番環境のデータにアクセスできるかどうかを確認しようとしています。アクセスできることを確認したら、必要に応じてさまざまなサンプルをリクエストします。翌朝起きてサンプルが準備されていたら、便利だと思いませんか?それでは、リクエストの形式を見てみましょう。
リクエスト
リクエストの構造は、ポリシーの default_sample エントリと同じです。次のようになっています。
-
size: 必要なテーブルデータの量を指定します。
countまたはpercentage、あるいはその両方を指定します。両方を指定した場合、countとpercentage(count に変換された値)のうちの最大量が実際の値として使用されます。 -
spec: 本番環境データをサンプリングする方法を指定します。以下のように指定します。
-
type:
sortedまたはrandom。 -
properties:
sortedを指定した場合、並べ替えに使用する列と並べ替えの方向を次のように指定します。 -
by: 列名。
-
direction: 並べ替えの方向(
ASCまたはDESC)。
例:
さらに詳しく説明
もう少し具体的な例を見てみましょう。limit と size がどのようなものか理解しやすくなります。この 2 つは似ているように見えますが、実際は異なります。
limit と size は異なる
limit と size には、細かいながらも重要なセマンティックの違いがあります。ポリシーで指定する limit では、count と percentage のうちの最小値が使用されます。limit は、取得するデータの量を制限するために使用します。size は、リクエストとデフォルトのサンプリングで使用します。この場合、count と percentage のうちの最大値が使用されます。limit を超える値を size に指定することはできません。
例で仕組みを確認
このシナリオのテーブルには、50,000 行があります。
次のようになります。
この場合、サンプルサイズの上限は 5,000 行(50,000 行の 10%)になります。
サンプリング サイクル
図 4 に、データ サンプリングのフローが示されています。このフローではインフラストラクチャは考慮されていません。
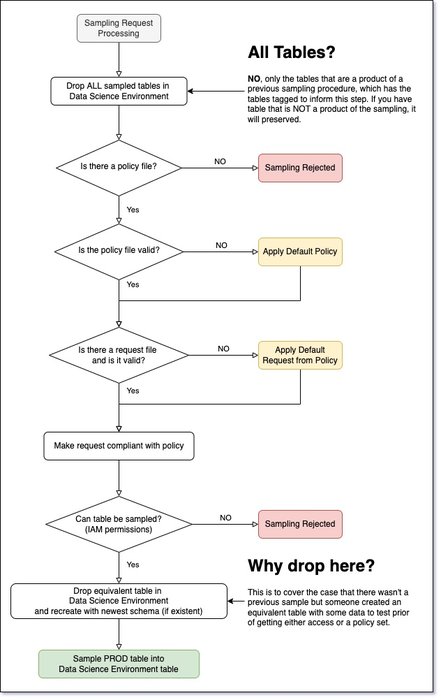
図 4. サンプリング フロー。フル解像度の画像はこちらです。
図 4 の内容は過剰に見えるかもしれませんが、そんなことはありません。次の点を確認する必要があります。
-
サンプルのインフレーションが発生しないこと。各サンプリング サイクルでサンプルが増えないようにしてください。そのためには、ポリシーを守る必要があります。
-
不良リクエストを許容すること。
-
スキーマと本番環境の同期を維持すること。
サンプラーの詳細なフローは次のとおりです。
-
Cloud Scheduler がメッセージ
STARTをCOMMANDPub/Sub トピックに配置します。これにより、サンプラー関数にサンプリングを開始するよう指示します。 -
サンプラー関数が次の処理を行います。
-
データ サイエンス環境にある以前のサンプルをすべて削除する。
-
ポリシー バケットで利用可能なすべてのポリシーを一覧表示する。
-
検出したテーブルごとに、対応するポリシーを指定して
SAMPLE_STARTコマンドを送信する。 -
SAMPLE_STARTコマンドごとに、対応するリクエスト ファイルがあるかどうかをチェックする。ファイルはリクエスト バケットにあります。 -
ポリシーに照らし合わせてリクエストがチェックされる。
-
コンプライアンスが確保されたサンプリングが BigQuery ソースに対して発行される。これはデータ サイエンス環境の対応するテーブルに挿入されます。
-
サンプラー関数が検出した各エラーのレポートが、
ERRORPub/Sub トピックに送信されます。 -
このトピックのメッセージによってエラー関数がトリガーされ、エラーの通知メールが送信されます。
-
サンプラー関数が 24 時間以内に実行されないと想定されます。そのため、アラートがトリガーされて、
ERRORPub/Sub トピックに送信されます。 -
サンプリング関数またはエラー関数に「重大な」エラーがある場合は、メール通知アラートが送信されます。
制限事項
以降のセクションでは、制限事項について詳しく説明します。サポートされていない機能を以下にまとめたので、ご覧ください。
-
あらゆる種類の
JOIN -
WHERE句 -
自動難読化(データはサンプル挿入の前に自動で匿名化されます)
-
列の除外
-
行の除外
-
正確な一様サンプリング分布
-
非一様データ サンプリング分布(ガウス、べき、パレートなど)
一部の機能は非常にシンプルに見えるが、「今後もサポートされない」のはなぜか
詳しく説明します。今後「サポートされない」理由として、次のいずれかが主に当てはまります。
-
実装が複雑で、時間がかかりすぎる。
-
ユーザーはビューを使用できる。
-
実装するとコストがかかりすぎる。
次のセクションで、それぞれの事項についてリスト形式で説明します。
JOIN と WHERE がサポートされないのは本当か
残念ながら、本当です。サンプリング ポリシーを適用するために JOIN と WHERE を実装する作業は複雑すぎるという問題があります。以下に簡単な例を示します。
-
テーブル
TYPE_OF_AIRCRAFT: これは特定の航空機のシンプルな ID を示します。たとえば、エアバス A320 neo の ID はABC123です。 -
100% のデータがサンプリングされるため、テーブルをコピーできます。
-
テーブル
FLIGHT_LEG: これは、特定の日付の 1 つのフライトを示します。たとえば、日曜日の 14:50 のロンドン ヒースロー空港発ベルリン行きのフライトなどです。 -
10% のデータがサンプリングされます。
-
テーブル
PASSENGER_FLIGHT_LEG: 特定のFLIGHT_LEGで、どの乗客がどこに座っているかを示します。 -
使用できるのは 10 行のみです。
これらのテーブルをすべて結合するクエリを作成できます。特定の日に特定の航空機のタイプに搭乗した乗客をすべて取得できます。この場合、ポリシーに従うために、以下を実行する必要があります。
-
クエリを実行する。
-
クエリによって特定の各テーブルから pull されるデータの量を確認する。
-
「許容量」に基づいて上限の設定を開始する。
このプロセスでは次の問題が発生します。
-
コストが非常に高くなる可能性がある。この場合、クエリを実行してからデータを「カット」します(クエリ全体の料金が発生します)。
-
ポリシーに違反するエッジケースが多数発生する可能性がある。
-
データの引き出しのリスクがある。
とはいえ、データを難読化する必要がある
多くの方が難読化を必要としていることは承知しています。このトピック自体は、Cloud DLP で解決できます。他にも多くの市販ソリューションが提供されているので、それらも利用できます。データの管理: Cloud DLP による機密情報の匿名化と難読化の実現のブログ投稿をご覧ください。
列と行の除外はシンプルな機能だと思うが
おっしゃるとおり、列と行の除外はシンプルな機能であり、ビューや Cloud DLP を使用するよりも簡単(かつ安全)です。これらがサポートされない理由は、すべてのユースケースに対応する一般的な仕様を作成するのが難しいからです。さらに、Cloud DLP などのはるかに優れたアプローチも存在します。最適なアプローチは、列や行を削除する理由によって異なります。
本当に一様分布はサポートされないのか
ビューを除き、TABLESAMPLE ステートメントを利用します。その理由はコストです。真にランダムなサンプルでは、ORDER BY RAND() 戦略が使用されます。これにはテーブル全体のスキャンが必要です。TABLESAMPLE ステートメントを使用すると、必要なデータ量よりもわずかに多くの料金を支払うだけで済みます。詳しく説明しましょう。
TABLESAMPLE ステートメントに関する注意点
この手法では、テーブル全体を読み取らなくてもテーブルをサンプリングできます。しかし、TABLESAMPLE を使用する際の重要な注意点があります。それは、真にランダムになることも一様になることもないということです。サンプルには、テーブル ブロックのバイアスが生じることになります。このドキュメントによると、次のような仕組みです。
次の例では、データブロックの約 20% をストレージから読み取り、それらのブロックで行の 10% をランダムに選択します。
SELECT * FROM dataset.my_table TABLESAMPLE SYSTEM (20 PERCENT)
WHERE rand() < 0.1
例を使ってわかりやすく説明しましょう。多くの偏りがある例で、TABLESAMPLE の処理を解説します。テーブルに整数列が 1 つあるとします。ブロックには次の特性があると想定してください。
この時点で、TABLESAMPLE を使用した場合にサンプルの平均値がどのようになるのか見てみます。わかりやすく説明するために、次のように想定します。
-
各ブロックには 1,000 件のレコードが含まれている。テーブル内のすべての値の実際の平均値は約 5.6 です。
-
40% のサンプルを選択した。
TABLESAMPLE によってブロックの 40% がサンプリングされるため、2 つのブロックを取得します。平均値を見てみましょう。ブロック ID が 1 と 2 のブロックを選択したとします。この場合、サンプルの平均値は 9.5 になります。ドキュメントで推奨されているダウンサンプリングを使用しても、サンプルにはバイアスが生じます。つまり、ブロックにバイアスがあれば、サンプルにもバイアスが生じるということです。
先ほど述べたように、バイアスの可能性を取り除くにはテーブル全体のスキャンが必要であり、その場合はサンプリング コストが高くなります。
他の分布が必要だが、なぜサポートされていないのか
サポートされていない理由はいくつかあります。主な理由として、他の分布は SQL エンジンのサポート対象外だからです。この問題の回避策はありません。唯一の解決策は、実装することです。実装は複雑な作業になります。注意点として、統計情報が古いとサンプルは雑になります。
以下の記述は、累積分布関数(CDF)の特殊な性質に基づいています。
特定の分布では、その CDF の分布が継続的に行われる。
これを機能させるには、次の操作を行う必要があります。
-
ターゲット列(分布のターゲットになります)のすべてのデータを取得する。
-
列の CDF を算出する。
-
CDF をランダム / 一様にサンプリングする。
-
上記を行の番号 / ID に変換する。
-
行をサンプルに追加する。
このプロセスは可能ですが、次のような影響があります。
-
テーブル全体のスキャンが必要になる。
-
すべてのデータ(数十億行)を保持するための「大規模な」インスタンスが必要となり、CDF も算出する必要がある。
この場合、次の料金が発生します。
-
高コストクエリ(テーブル全体のスキャン)。
-
高コスト インスタンスでサンプルの算出にかかる時間。
こうした作業にはコストに見合うだけの価値がないと判断しました。
ビュー: 回避策
サンプリングのビューがサポートされているため、いつでも必要な処理をビューに追加して、サンプラーにそのジョブを実行させることができます。しかし、ビューでは BigQuery の TABLESAMPLE ステートメントがサポートされていません。そのため、ランダム サンプルを取得するには、ORDER BY RAND() 戦略を使用してテーブル全体のスキャンを行う必要があります。ランダムでないサンプルの場合、テーブル全体のスキャンは行われません。
なんだかだまされたような気分
はい、そのとおりです。ビューを使用した回避策では、SecOps 担当者と DataOps 担当者がコンプライアンスが確保されたビューとサンプル ポリシーを定義しなければならず、彼らに責任を押し付けることになります。また、ビューをクエリすることは、基になるクエリを実行してサンプリングするようなものであるため、コストが高くなる可能性があります。ビューからランダム サンプルを取得する場合は、その性質上、テーブル全体のスキャンが必要になるため、特に細心の注意を払ってください。
ソリューション設計
次のようなコンポーネントを使用する、とてもシンプルなソリューションを利用しています。
-
BigQuery: データの移行元と移行先です。
-
Cloud Scheduler: 毎日または定期的にサンプリングをトリガーするために使用される Google Cloud の crontab です。
-
Cloud Pub/Sub: トリガー、エラー、サンプリングの各ステップを調整します。
-
Cloud Storage: ポリシーとリクエストを(別々の 2 つのバケットに)保管します。
-
Cloud Functions: ロジックの主軸です。
-
Secret Manager: 機密情報を保持します。
-
Cloud Monitoring: システムの健全性をモニタリングします。
仕組みを理解したので、こちらでコードを確認しましょう。皆様の仕事にぜひお役立てください。
SWISS および Lufthansa Groupの OPSD プロジェクト チームの皆様に深く感謝申し上げます。この投稿は、このプロジェクトでの、最新の本番環境サンプルを取得し、かつ SecOps のコンプライアンスを確保するという必要性から生まれました。とりわけ、共同執筆者である Federica Lionetto 氏、セキュリティ要素の確認を担った Yaroslav Khanko 氏、terraform のコードレビュー担当 Ziemowit Kupracz 氏、CI / CD インテグレーションを担当した Regula Gantenbein 氏に感謝いたします。
ー Google Cloud、戦略的クラウド エンジニア Gustavo Kuhn Andriotti

{kind=link}