完全セルフサービスで BigQuery の本番環境のサンプルを取得
Google Cloud Japan Team
※この投稿は米国時間 2023 年 8 月 19 日に、Google Cloud blog に投稿されたものの抄訳です。
BigQuery から最新の本番環境サンプルを取得する際の問題を解決するソリューションを提案します。このソリューションは、誤ってデータが引き出されるのを防ぐ安全対策を提供します。また、セルフサービスであるため最新のサンプルを毎日取得でき、古いスキーマや最新でないサンプルを使わなくて済むようになります。
この機能に興味を持たれるのは、おそらく BigQuery を操作するデータ サイエンティストか、手動でサンプルを提供しなければならない DevOps 側にいる方々でしょう。いずれの場合も、お求めの解決方法をこのソリューションが提供するかもしれません。
このソリューションが重要である理由
データ サイエンティストが迅速に作業できるように改善することは、製品に競争力を与えるうえで非常に重要です。もし、データ サイエンティストがセルフサービスでサンプルを取得して分析情報を得られるソリューションがあれば、新たな仮説とモデルが生まれ、スムーズに本番環境に移行でき、バイアスのかかったサンプルや古いデータスキーマなどの「悪い」想定外の出来事を避けられます。
実装に使用するコード
使用するコードは Google の GitHub リポジトリでご確認いただけます。
既存のソリューションとの違い
すべての問題に対応することはお約束できないとしても、BigQuery に関わる問題を解決します。コンプライアンスが確保されたサンプリングを、セルフサービスでご利用いただけます。コンプライアンスの確保とは、サンプルのリクエストを承認するためのポリシーが存在することを意味します。
図解
図 1 はシステム コンテキストの図表で、サンプラー システムの概要を示しています。フル解像度の画像はこちらです。
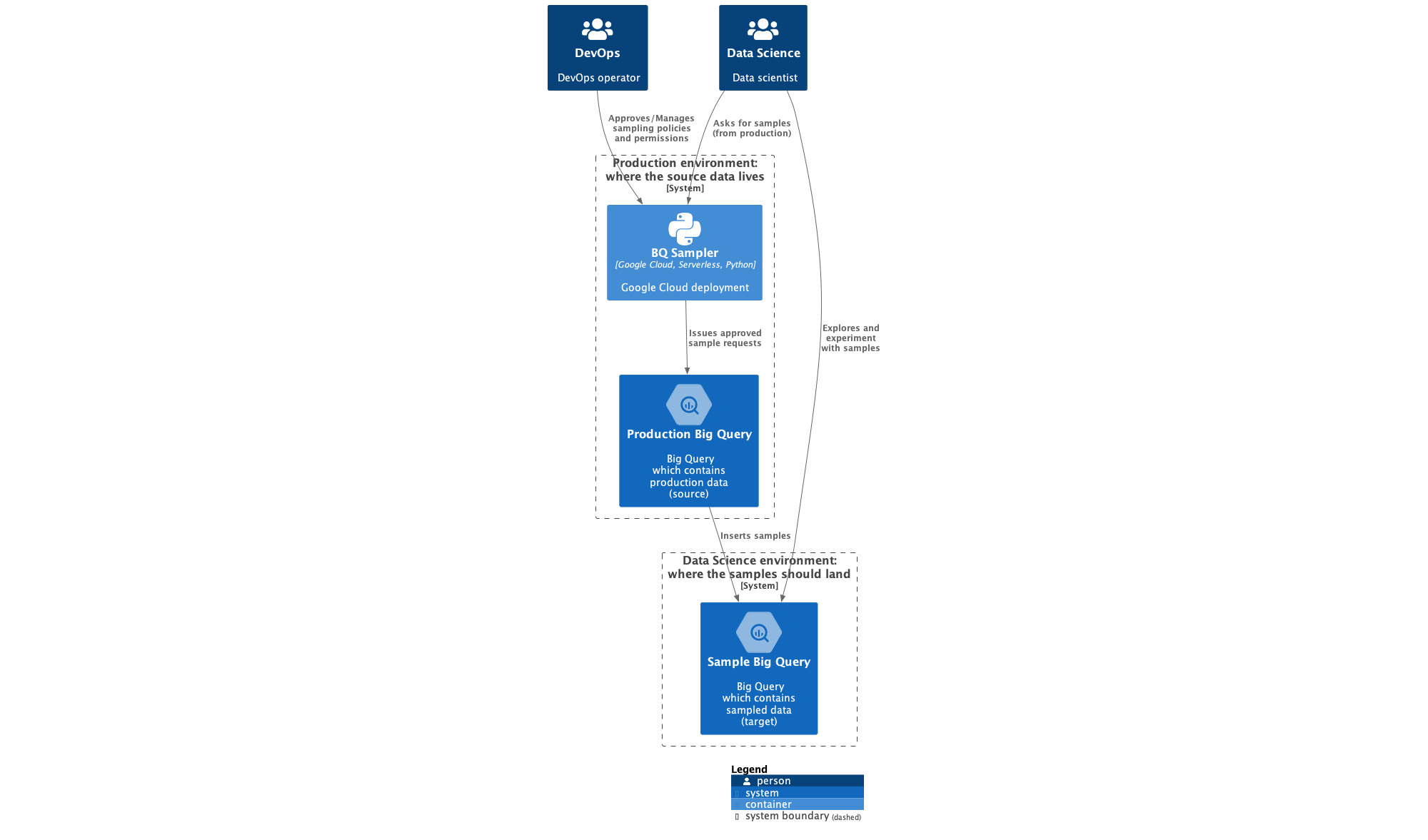
図 1 のシステム コンテキストの図表には、サンプラー(BQ Sampler)とやり取りする 2 つのロールが示されています。これら 2 つのロールは、DevOps オペレーターとデータ サイエンティストです。Devops オペレーターは DevOps チームの一員で、ここには SecOps も含まれます。DevOps は本番環境データへのアクセスを管理し、データサイエンス チームはサンプルをリクエストします。
DevOps オペレーターやデータ サイエンティストが BQ Sampler を操作すると、サンプラーが本番環境の BigQuery に承認済みのサンプラー リクエストを発行して、BigQuery はそれを受け、サンプルをデータ サイエンス環境(Sample BigQuery)に挿入します。
DevOps
DevOps(SecOps も含む)には、本番環境データがどのように処理されるかを監督する担当者が含まれます。
DevOps チームは、次のような責任を負います。
サンプル リクエストのコンプライアンスが確保されるよう、ポリシーの作成および管理を行う。ポリシーは次のような疑問に答えます。
テーブルから取得できるデータの行数または割合は?
テーブルをサンプリングできますか?
デフォルトのサンプルはどれですか?
サンプラーをデプロイしてサンプラーによる BigQuery へのアクセスを管理する。
サンプラーの障害を受信して対応を行う。
たとえば、ユーザーがサンプルに新しいテーブルを必要とする場合は、DevOps チームに連絡します。
データ サイエンス
データ サイエンティスト チームにはユーザーが含まれます。これらのユーザーは、新しい分析情報を得るためにデータのリクエストと分析を行い、データの中身を理解しています。
データ サイエンス チームは、次のような責任を負います。
DevOps が適切なポリシーを決定するのを手伝う。たとえば、あらゆる種類の航空機が含まれるテーブルは機密ではないためダンプが許可され、100% のデータがデータ サイエンス環境に転送されるべきであることを説明するなどです。
次のようなサンプル リクエストを作成する。
テーブル T の N 行または P パーセントが必要。
ランダムなサンプルが必要、またはサンプルを特定の列で並べ替えたい。
データでいろいろ試し、分析情報を得て、仮説を立ててみる。
BigQuery の費用の節約に使われなくなったリクエストを削除する。
ユーザーとは、対象ユーザーの皆様のことです。ユーザーとソリューションの接点は、DevOps によるポリシーの開発を支援し、必要とするサンプルを求めることです。
さらに詳しく
ユーザー、つまりデータ サイエンティストの観点からは、魔法のようなことは起こりません。必要とするものを要求して、権限があるものを受け取ります。
手順は次のとおりです。
サイエンティストとして必要なものを依頼する。
ポリシーを使用して、サンプラーがリクエストを承認する。
データ サイエンス環境でデータを受け取る。
これを毎日繰り返す。
上述の手順は以下のようにまとめられます。
リクエストを作成する。
次のサンプラーが実行されるのを待つ。
サンプルを取得する。
大まかなインフラストラクチャ
サンプラー内で、プロセスは次のように自動化されます。
Cloud Scheduler が毎日、サンプラーの Cloud Functions の関数をトリガーします。
Cloud Functions の関数が Cloud Storage からリクエストとポリシーを読み取ります。Cloud Functions の関数は本番環境の BigQuery サンプルを処理して、データ サイエンス環境に送信します。図 2 に示されている、ソリューションを実装する主要コンポーネントには以下が含まれます。
Cloud Scheduler: 任意のケイデンスでサンプリング サイクルをトリガーします。
Cloud Functions: サンプリングを実行するコードをホストします。
Cloud Storage: リクエストとポリシーのリポジトリです。前者はデータ サイエンス環境にあり、リクエストを本番環境に送信します。
- BigQuery: データソースを生成するエンジンで、サンプルの宛先になります。ソースは本番環境で、ターゲットはデータ サイエンス環境です。
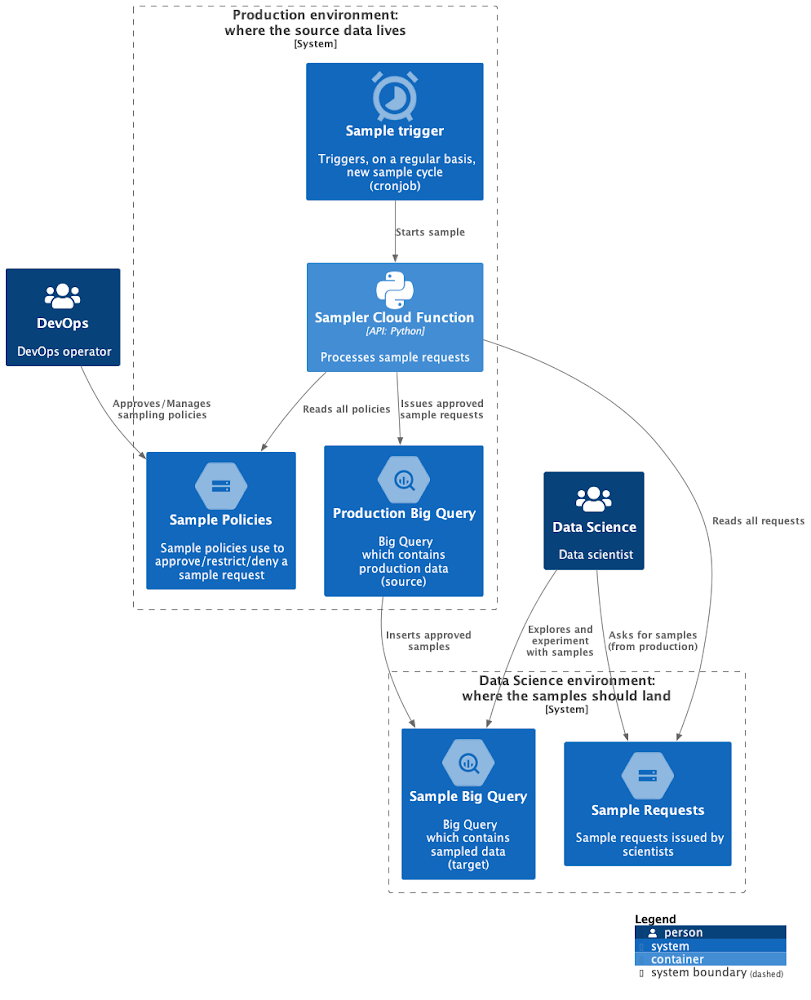
詳細なインフラストラクチャ
図 3 は、インフラストラクチャ全体を示す、コンポーネントの図表です。まず注意すべきなのは、複数の Pub/Sub トピックと Cloud Functions の関数があるにも関わらず、これらのコンポーネントは単一のトピックと関数であることです。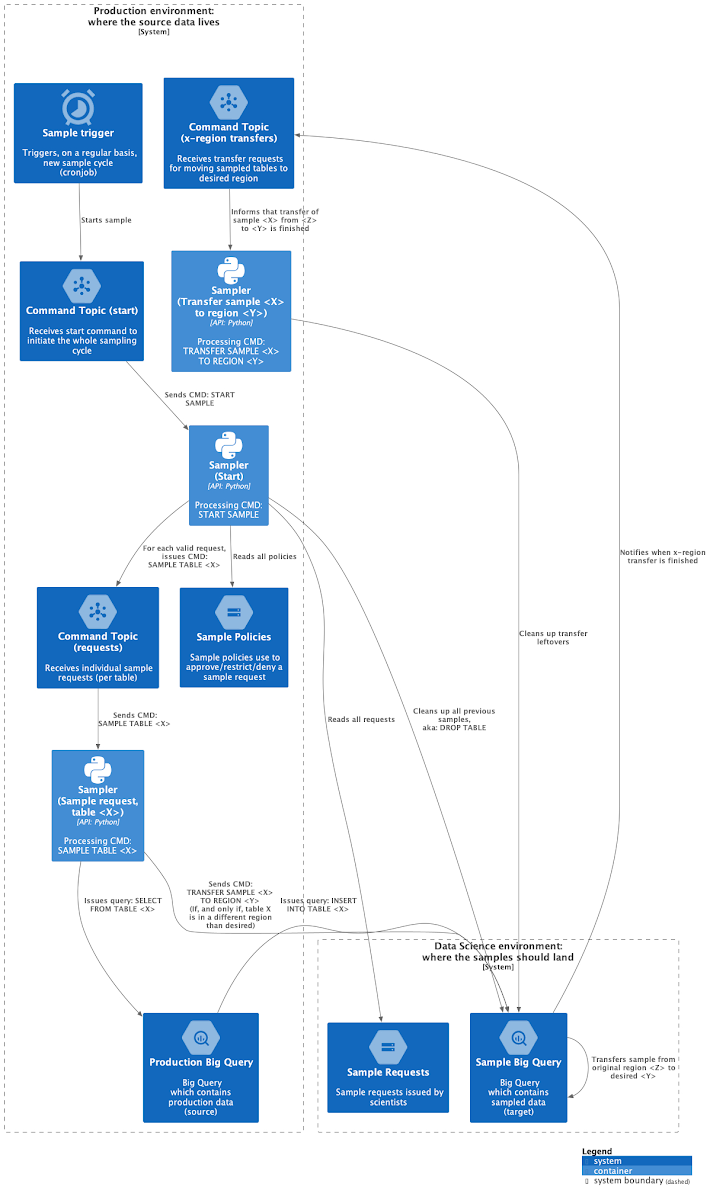
論理ステップを明確にするため、以下のようなコンポーネントを示しています。
Start sample(サンプル開始): サンプラーに完全なサンプリング サイクルを開始するよう伝えます。
Clean up(クリーンアップ): 前回のサンプルをすべて削除します。
Sample table X(サンプル テーブル X): テーブル X の承認済みサンプルを実行します。
Transfer clean up(転送のクリーンアップ): リージョン間のテーブル転送により生じたアーティファクトをクリーンアップします。
疑問に思われる点がいくつかあるかもしれません。
Pub/Sub を使う理由
Pub/Sub により、Cloud Functions の関数がステートレスかつ並列で実行されるようになります。ユーザーはそれぞれの論理ステップが Pub/Sub メッセージによりトリガーされるのと同時に、サンプリングするテーブルと同じ数だけメッセージを送信して、各テーブルのサンプリングをトリガーできます。関数がステートレスなため、並列化は簡単です。
クリーンアップする理由
クリーンアップのステップで、スキーマの変更とサンプルのインフレーションという 2 つの問題が解決されます。
スキーマの変更
シナリオ: 古いサンプルが保持され、元のテーブルには新しいスキーマがあります。
問題: スキーマから別のスキーマへのデータ移行に対処する必要があります。この作業は自動化しにくいため、ユーザーに移行の手間がかかります。最もシンプルな解決方法は、前回のサンプルとテーブルをワイプして、サンプリングのステップでテーブルを手動で作成し直すことです。
サンプルのインフレーション
各サンプルの前に、データがワイプされなかったと仮定します。その場合、サンプルのサイズがポリシーの許容範囲を超えて徐々に増加する原因となります。これは、サンプラーが前回のサンプルを認識しないためです。また、最新のサンプル取得することで、現在のデータをより正確に反映できます。たとえば、アプリでユーザーの年齢のサンプリングを行っているとします。初期の顧客ベースはアプリを試しに使ってみた若いユーザーで、アプリの人気が高まるにつれて他の年齢層もアプリを使い始めるという可能性が高いため、サンプルを更新しないと、年齢の低いユーザー層に大きく偏ってしまう可能性があります。
転送のクリーンアップ
転送とは、BigQuery Data Transfer Service を指します。BigQuery では同じリージョン内におけるプロジェクト間のテーブルクエリしか許容されないため、異なるリージョンにデータを転送できるようにする必要があります。
クエリのランディング リージョンは変更できないことに注意してください。クエリは同じリージョンに存在する必要があります。本番環境データが europe-west3 にあり、データ サイエンティストは us-east1 のみで利用可能な Vertex AI の新しい機能を試したいと考えているとします。
新しい機能と同じリージョンにサンプルを存在させるには、BigQuery Data Transfer Service を使用する必要があります。サンプルは、元データと同じリージョンでしか作成できないことに留意してください。つまり、本番環境と同じリージョンの europe-west3 でサンプリングを行うということです。次に、Data Transfer Service を使用してサンプルを europe-west3 から us-east1 にコピーします。これにより、クリーンアップする必要のあるアーティファクトが生じます。転送のクリーンアップのステップでは、この残されたアーティファクトを削除します。
次のステップ
次回のブログ投稿では、このソリューションに関する技術的な詳細を取り上げる予定ですので、どうぞお見逃しなく。それまで、GitHub リポジトリで、このソリューションをぜひ試用してみてください。フィードバックやバグの報告をお待ちしております。問題が見つかった場合は、ぜひご連絡ください。
ソリューション設計
次のようなコンポーネントを使用する、とてもシンプルなソリューションを利用しています。
BigQuery: データの移行元と移行先です。
Cloud Scheduler: 毎日または定期的にサンプリングをトリガーするために使用される Google Cloud の crontab です。
Cloud Pub/Sub: トリガー、エラー、サンプリングの各ステップを調整します。
Cloud Storage: ポリシーとリクエストを(別々の 2 つのバケットに)保管します。
Cloud Functions: ロジックの主軸です。
Secret Manager: 機密情報を保持します。
Cloud Monitoring: システムの健全性をモニタリングします。
関係者への謝辞
SWISS および Lufthansa Groupの OPSD プロジェクト チームの皆様に深く感謝申し上げます。この投稿は、このプロジェクトでの、最新の本番環境サンプルを取得し、かつ SecOps のコンプライアンスを確保するという必要性から生まれました。とりわけ、共同執筆者である Federica Lionetto 氏、セキュリティ要素の確認を担った Yaroslav Khanko 氏、terraform のコードレビュー担当 Ziemowit Kupracz 氏、CI / CD インテグレーションを担当した Regula Gantenbein 氏に感謝いたします。
- Gustavo Kuhn Andriotti


{kind=link}
{kind=link}