BigQuery データ キャンバスについて: AI でデータを分析情報に変換する簡単な方法
Layolin Jesudhass
Global Generative AI Solutions Architect, Google
Christine De Sario
Customer Engineer - Data & Analytics, Google
※この投稿は米国時間 2024 年 7 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
Gemini in BigQuery の機能の BigQuery データ キャンバスは、データ分析の過程の全体(データの発見と準備から分析、可視化、連携まで)を BigQuery 内の 1 か所ですべて簡素化できる画期的なデータ分析ツールです。BigQuery データ キャンバスは自然言語処理を活用するため、データに関する質問を平易な英語やその他のさまざまな言語で行うことができます。この直感的なアプローチのおかげで複雑な SQL クエリを作成する必要がなくなり、技術系のユーザーも技術系以外のユーザーも、データ分析を利用できるようになります。データ キャンバスを使用すると、データが保存されている環境から離れることなく、BigQuery データの検索、変換、可視化を行うことができます。
このブログでは、BigQuery データ キャンバスの概要を説明し、公開 github_repos データセットを使用した実例を技術チュートリアルで紹介します。このデータセットには、300 万件を超えるオープンソース リポジトリのアクティビティが 3 TB 超含まれています。今回は次のような質問に答える方法を探ります。
-
1 年間に特定のリポジトリに対して何件の commit があったか
-
ある年にリポジトリを最も多く作成したのは誰か
-
一定期間に、作成者以外の commit が何件適用されたか
-
特定の時点で、特定のファイルに投稿したのはどのユーザーか
データ キャンバスを使用して、テーブルの結合、フィールドのネスト解除、タイムスタンプの変換、特定のデータ要素の抽出といった複雑な SQL タスクを、すべて自然言語プロンプトで処理する方法について説明します。また、ワンクリックで示唆に富む可視化と要約を生成する方法も実演します。
BigQuery データ キャンバスの概要
BigQuery データ キャンバスの核となる機能の領域は主に 3 つあり、データの検索、SQL の生成、分析情報の作成に使用できます。
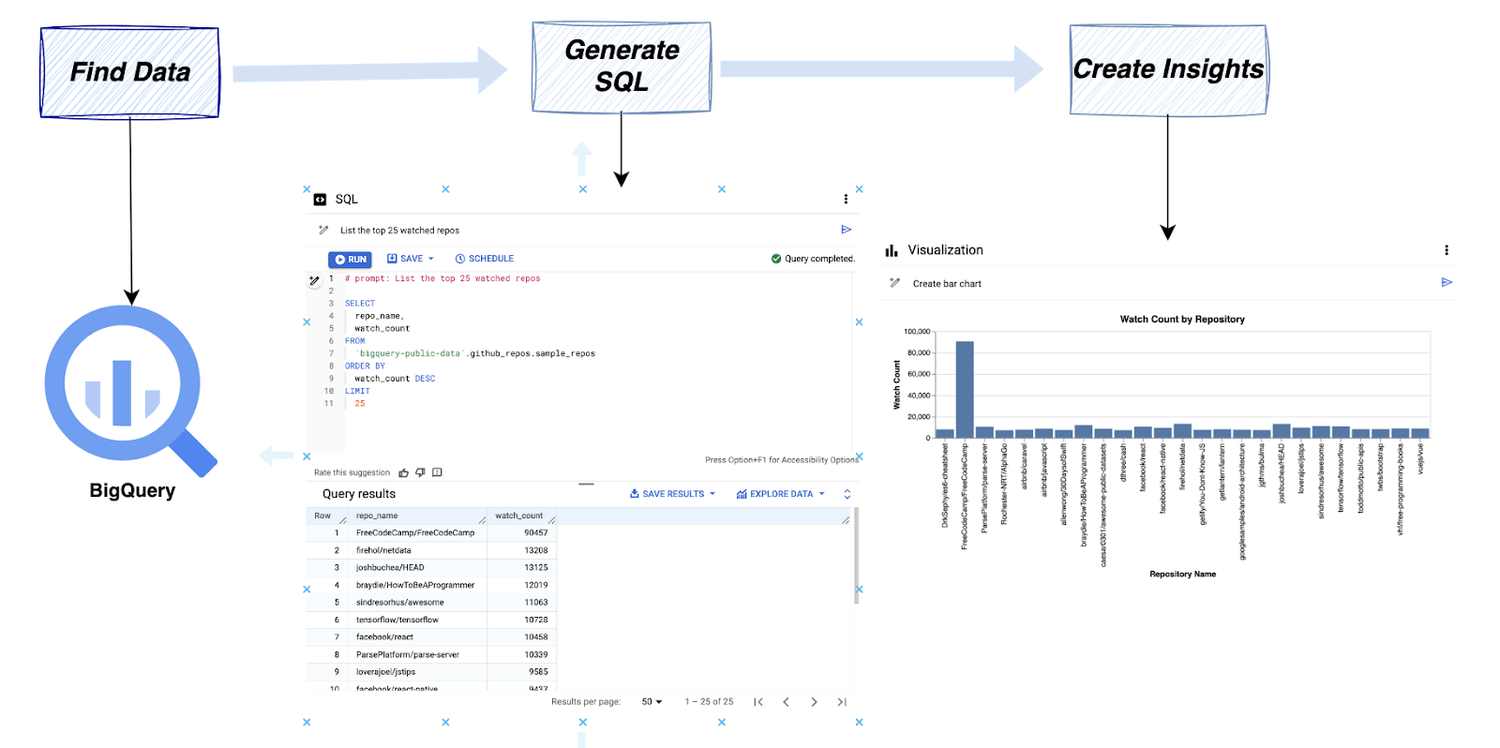
BigQuery データ キャンバスの 3 つの側面
1. データの検索
データ キャンバスを使用して、簡単なキーワード検索や自然言語のテキスト プロンプトで BigQuery 内のデータを検索します。
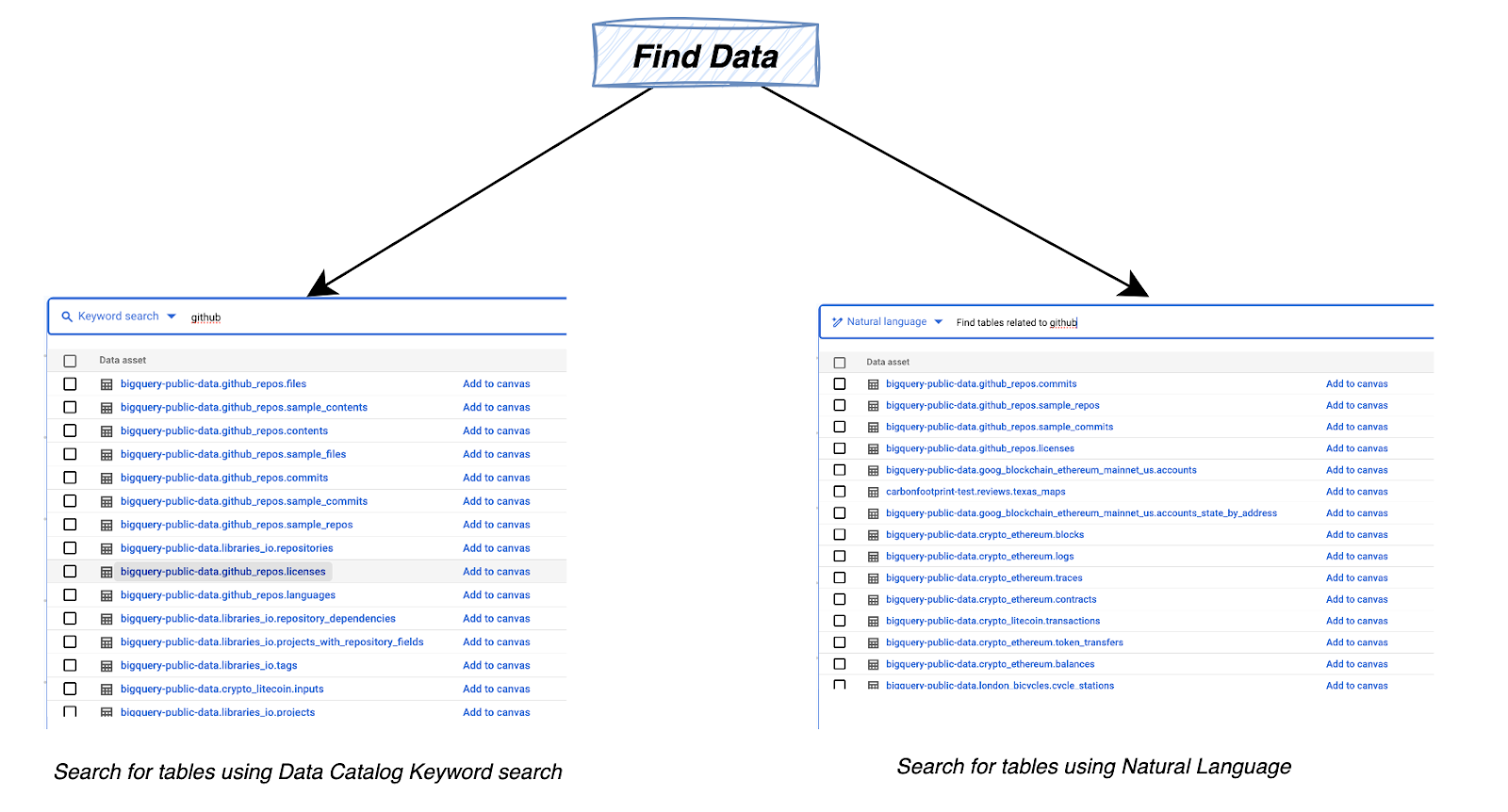
Gemini を搭載した BigQuery のデータ キャンバスで分析を開始
2. SQL の生成
BigQuery データ キャンバスを使用して、Gemini を活用した自然言語プロンプトで SQL コードを記述することもできます。

簡単な英語を使用して、選択したテーブルに対する SQL クエリを作成
3. 分析情報の作成
最後に、ワンクリックでデータから分析情報を引き出します。データの意味を理解するために役立つ可視化を Gemini が自動的に生成します。
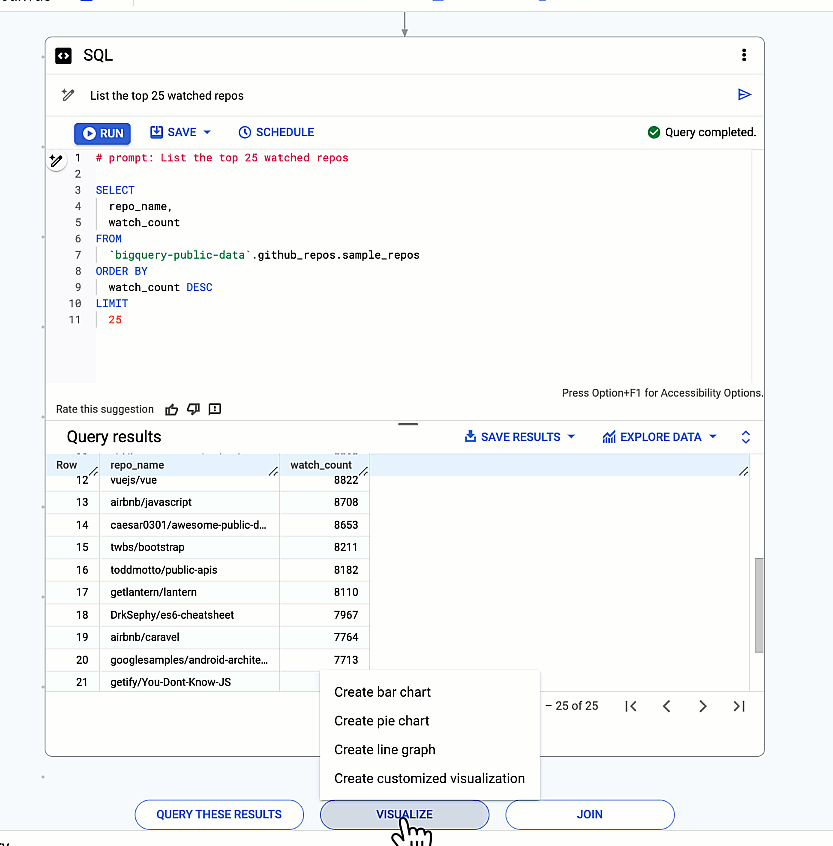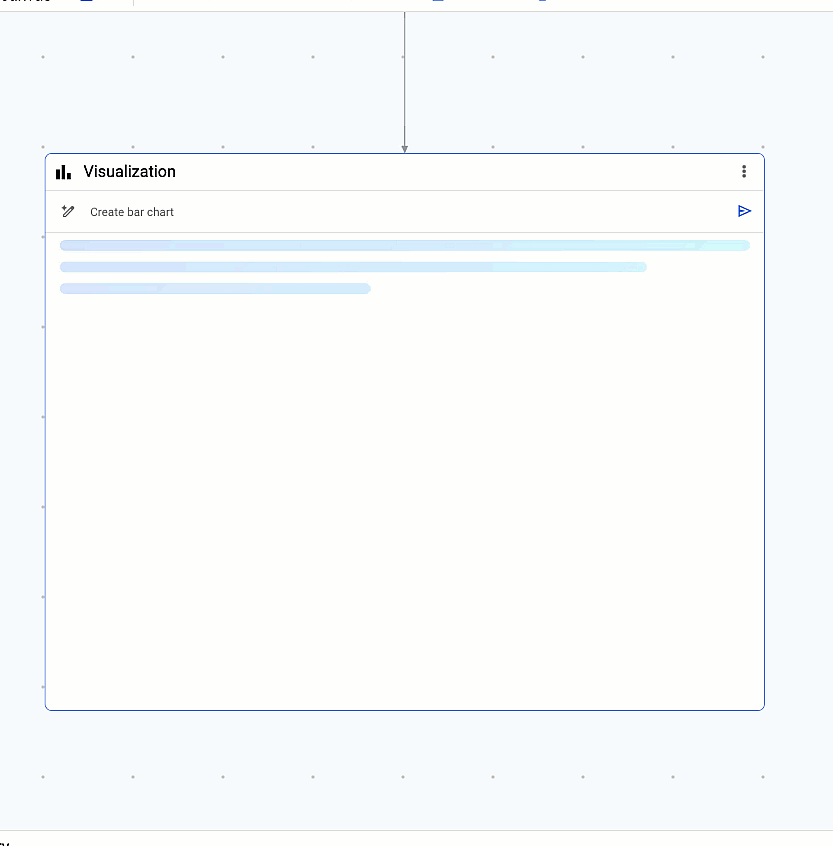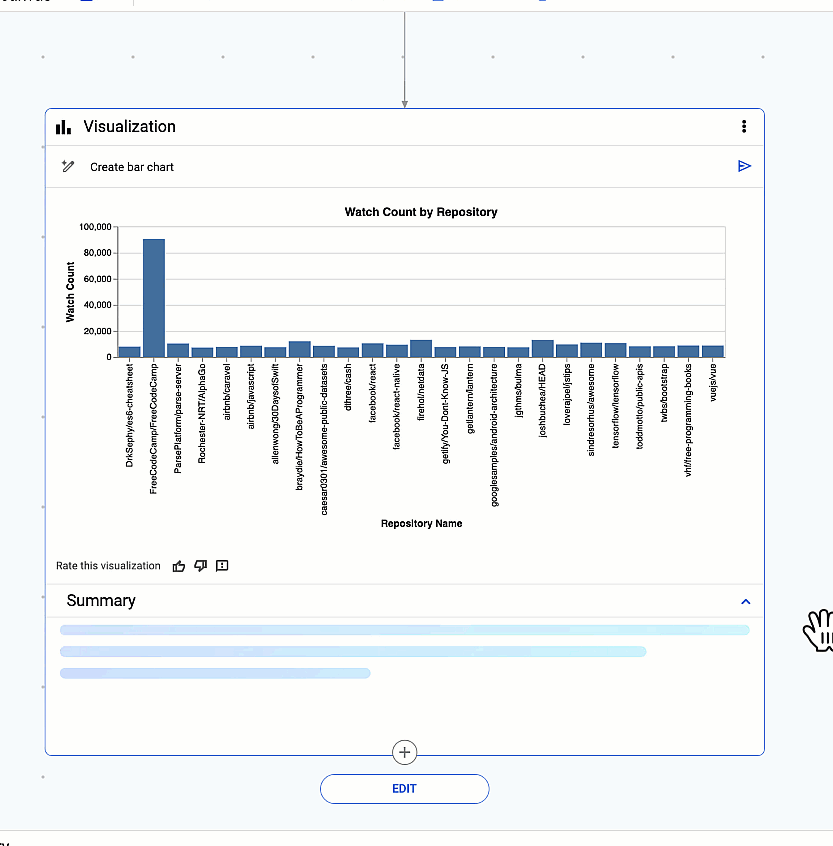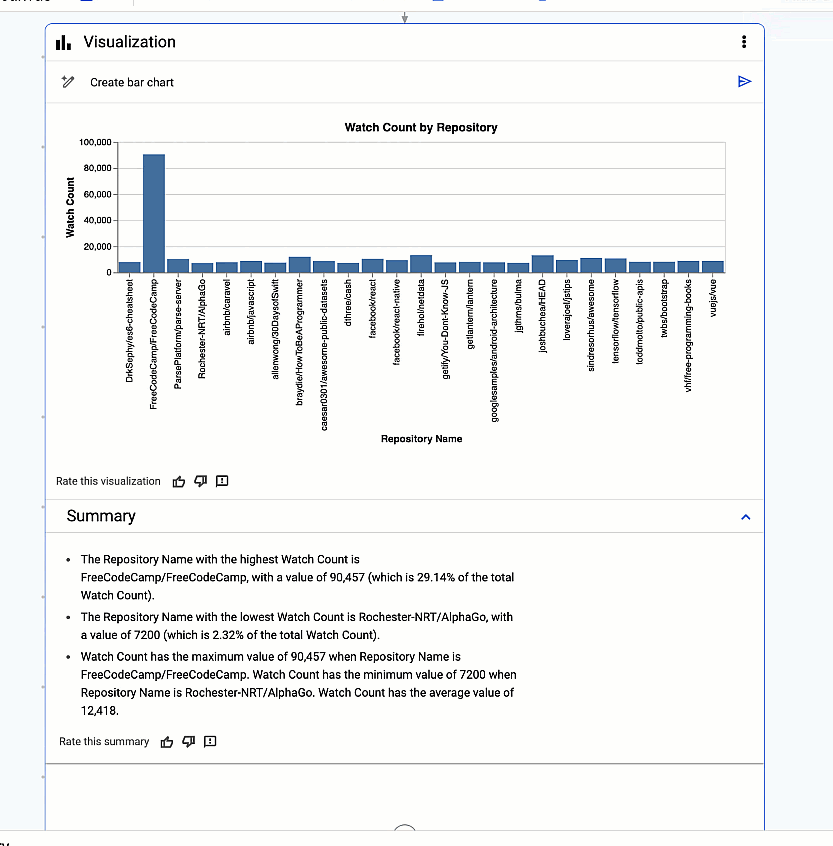
データの意味を理解するために役立つ可視化を Gemini が自動的に生成
BigQuery データ キャンバスの実例
BigQuery データ キャンバスを使用することで組織が得られる効果について、具体的な例で考えてみましょう。大企業から小規模なスタートアップまで、あらゆる規模の企業が、デベロッパー チームの生産性について理解を深めることで恩恵を受けられます。この技術解説では、github_repos 公開データセットとデータ キャンバスを使用して、共有可能なワークスペースで有益な分析情報を生成する方法を紹介します。この例から、データ キャンバスで複雑なクエリをどれほど簡単に実行できるかがわかります(ネストされたフィールドの結合やネスト解除、タイムスタンプの変換、日付フィールドからの年月の抽出などを行う SQL を作成できます)。Gemini の機能を使用すると、自然言語でこうしたクエリを簡単に生成し、示唆に富む可視化とともにデータを詳しく見ることができます。
今の多くの新しい AI プロダクトやサービスと同様に、LLM 対応アプリケーションを効果的に使用するには優れたプロンプト エンジニアリング スキルが必要です。多くの人が、既成の大規模言語モデル(LLM)は SQL の生成に適さないと捉えているかもしれません。しかしこれまでの経験上、適切なプロンプト手法を採用すれば、Gemini in BigQuery ではデータ キャンバスにより、データコーパスのコンテキストを使用して複雑な SQL クエリを生成できます。データ キャンバスは、自然言語クエリに基づいて並べ替え、グループ化、順序付け、レコード数の制限、SQL 構造を判断します。BigQuery データ キャンバスのエンジニアリング プロンプトについて詳しくは、BigQuery データ キャンバスのプロンプト記述に関するベスト プラクティスに関する別のブログ投稿をご覧ください。
BigQuery 一般公開データセットで入手できる github_repos データセットは 3 TB を超えるデータセットです。commit や視聴数などに関する 300 万件を超えるオープンソース リポジトリのアクティビティが、複数のテーブルに含まれています。この例では、Google Cloud Platform のリポジトリを見てみましょう。いつものように、始める前に適切な IAM 権限があることを確認してください。また、ノードを正常に実行するために、データ キャンバスとデータセットに対する適切な権限があることも確認してください。
データ キャンバスでは、github_repos データセット内の各テーブルを簡単に調べることができます。ここでは、すべて同じパネル内で、データセットを並べて比較し、スキーマを調べ、詳細を表示して、データをプレビューします。
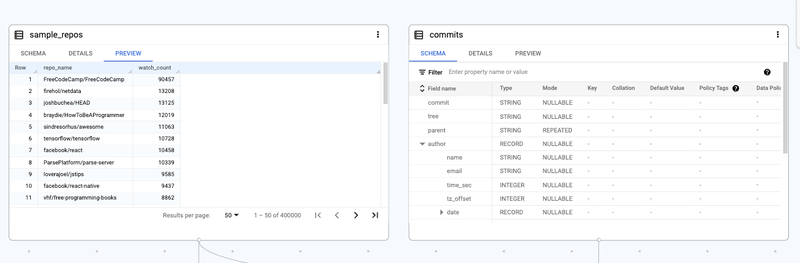
テーブルを並べて調べる - スキーマの確認、詳細の表示、データのプレビュー
データセットを選択したら、ノードの下にカーソルを合わせることで、別のノードを分岐してクエリを行ったり、別のテーブルと結合したりできます。矢印は、次の変換ノードのデータセットを示します。キャンバスを共有する場合、分かりやすくするために各ノードに名前を付けることができます。右上のオプションを使用すると、一連のすべてのノードを削除、デバッグ、複製、または実行できます。結果のダウンロードや、Google スプレッドシートまたは Looker Studio へのデータのエクスポートも可能です。また、SQL の提案の評価や以前のバージョンの復元もできるほか、ナビゲーション パネルに DAG 構造を表示することもできます。
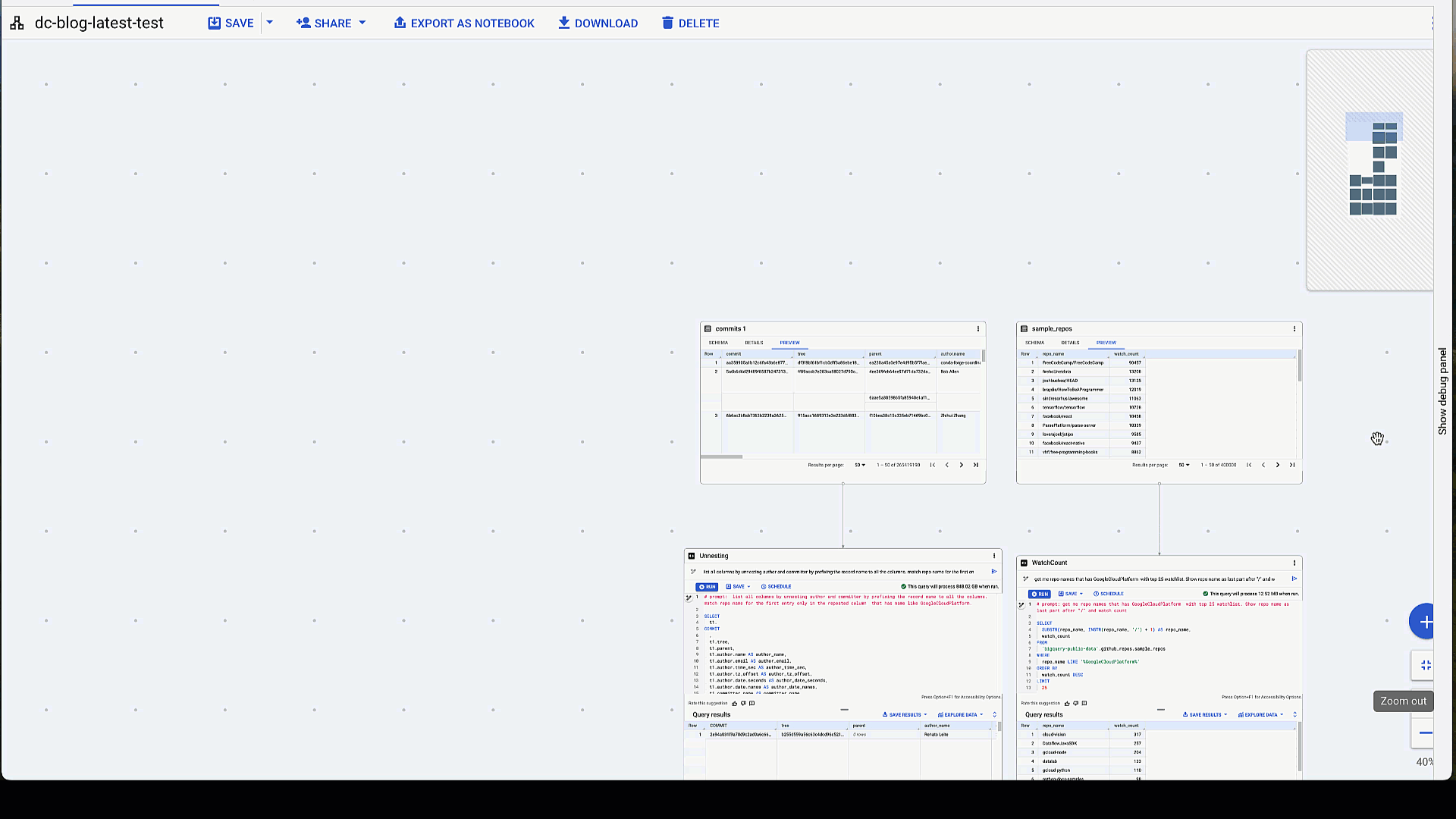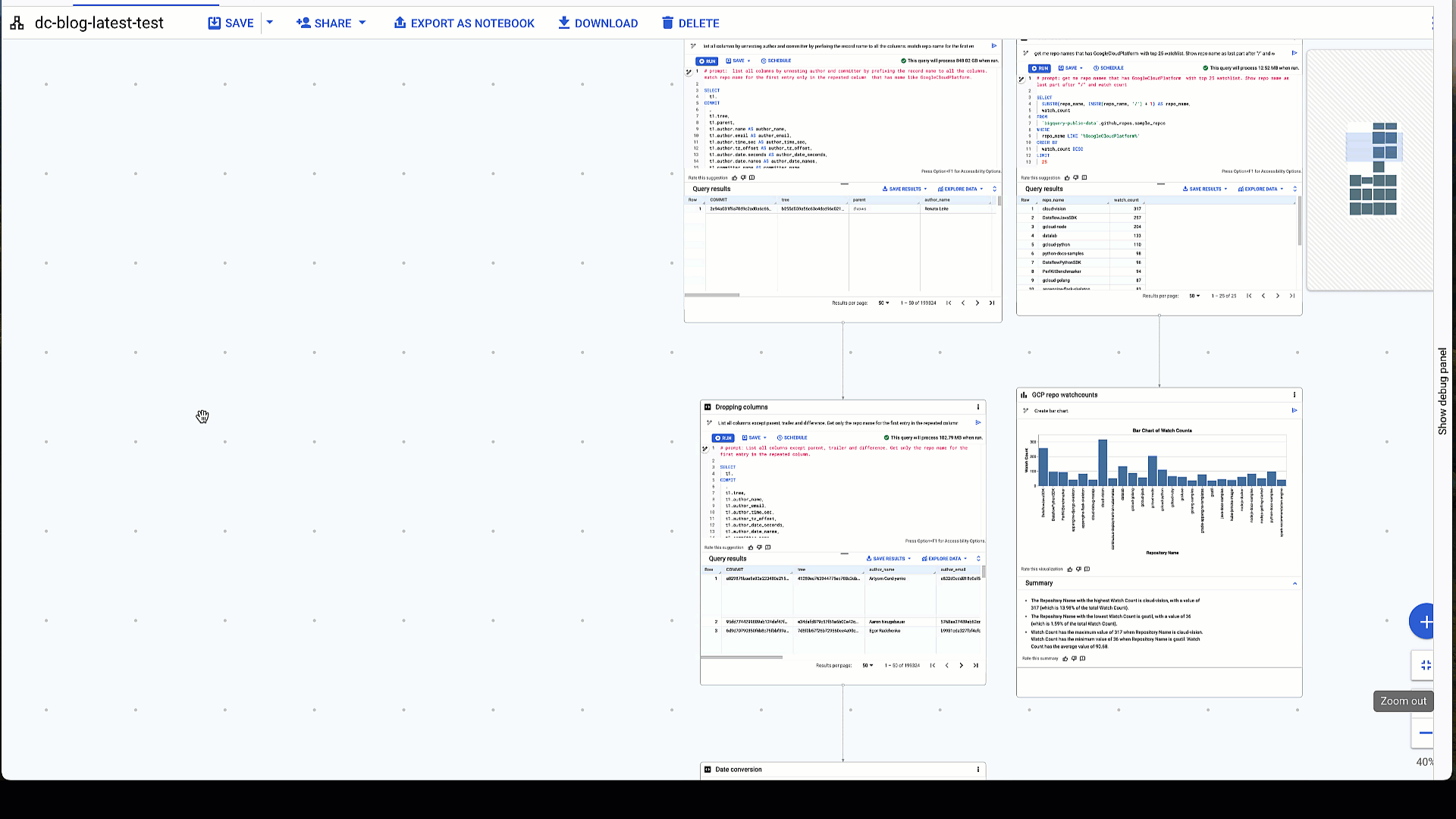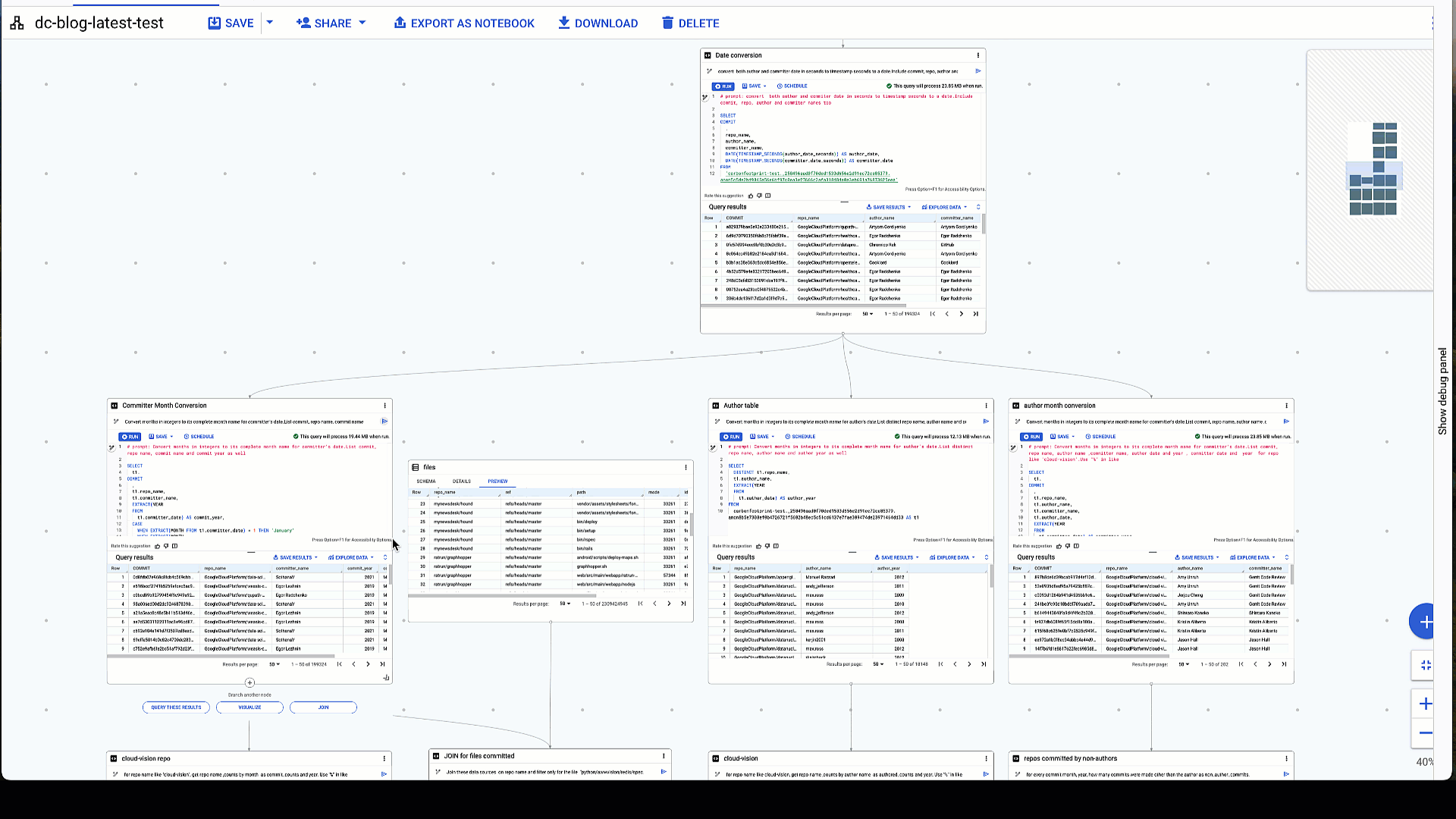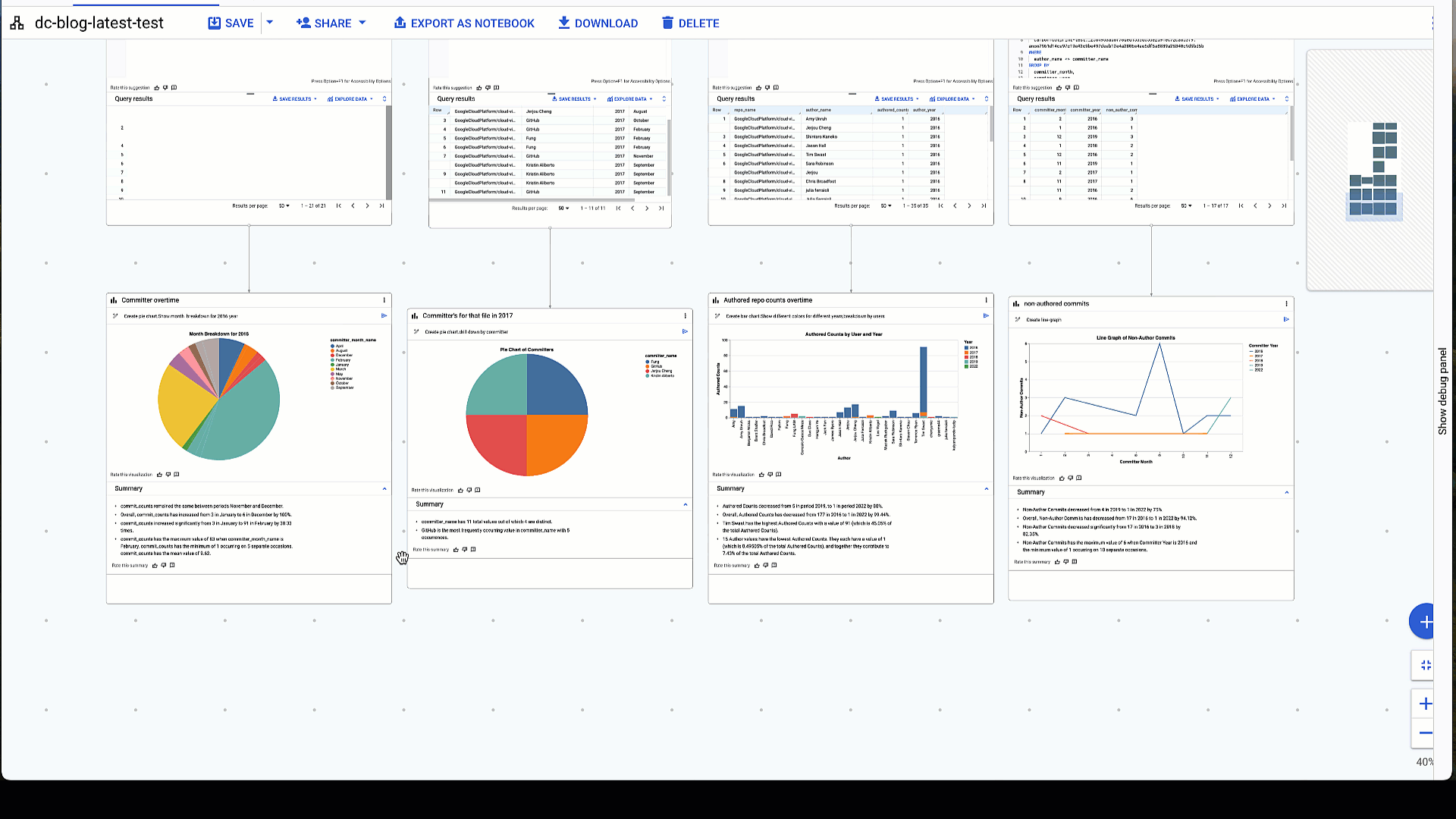
エンドツーエンドのデータ キャンバス全体の概要
github_repos データセットを調べる際、次のようにデータの 4 つの側面に着目し、その数を割り出します。
1)1 年間に行われた commit の数
2)ある年に作成されたリポジトリの数
3)その年を通して適用された、作成者以外の commit の数
4)特定の時点で特定のファイルに対してユーザーが行った commit の数
以下に、このワークフロー例の自然言語クエリ プロンプトで生成された、複雑な SQL クエリと変換の主な例を 5 つ示します。
1. 特定の列をネスト解除し、repo_name に Google Cloud Platform が含まれるすべての列を検索する
# prompt: list all columns by unnesting author and committer by prefixing the record name to all the columns. match repo name for the first entry only in the repeated column that has name like GoogleCloudPlatform. Make sure to use "%" for like
生成された SQL:
作成者とコミッターの下のフィールドを適切にネスト解除してから
GoogleCloudPlatform リポジトリに絞り込む
リポジトリ内の特定のファイルを修正したコミッターを特定する場合は、以下の例のようにテーブル結合を行うと目的の結果が得られます。各ノードの下には、既存のテーブルやクエリ結果をクエリまたは結合するオプションがあります。
2. 以前のクエリ結果と github_repos.files テーブルを repo_name で内部結合する
# prompt: Join these data sources on repo name and filter only for the file "python/awwvision/redis/spec.yaml" and year 2017
生成された SQL:
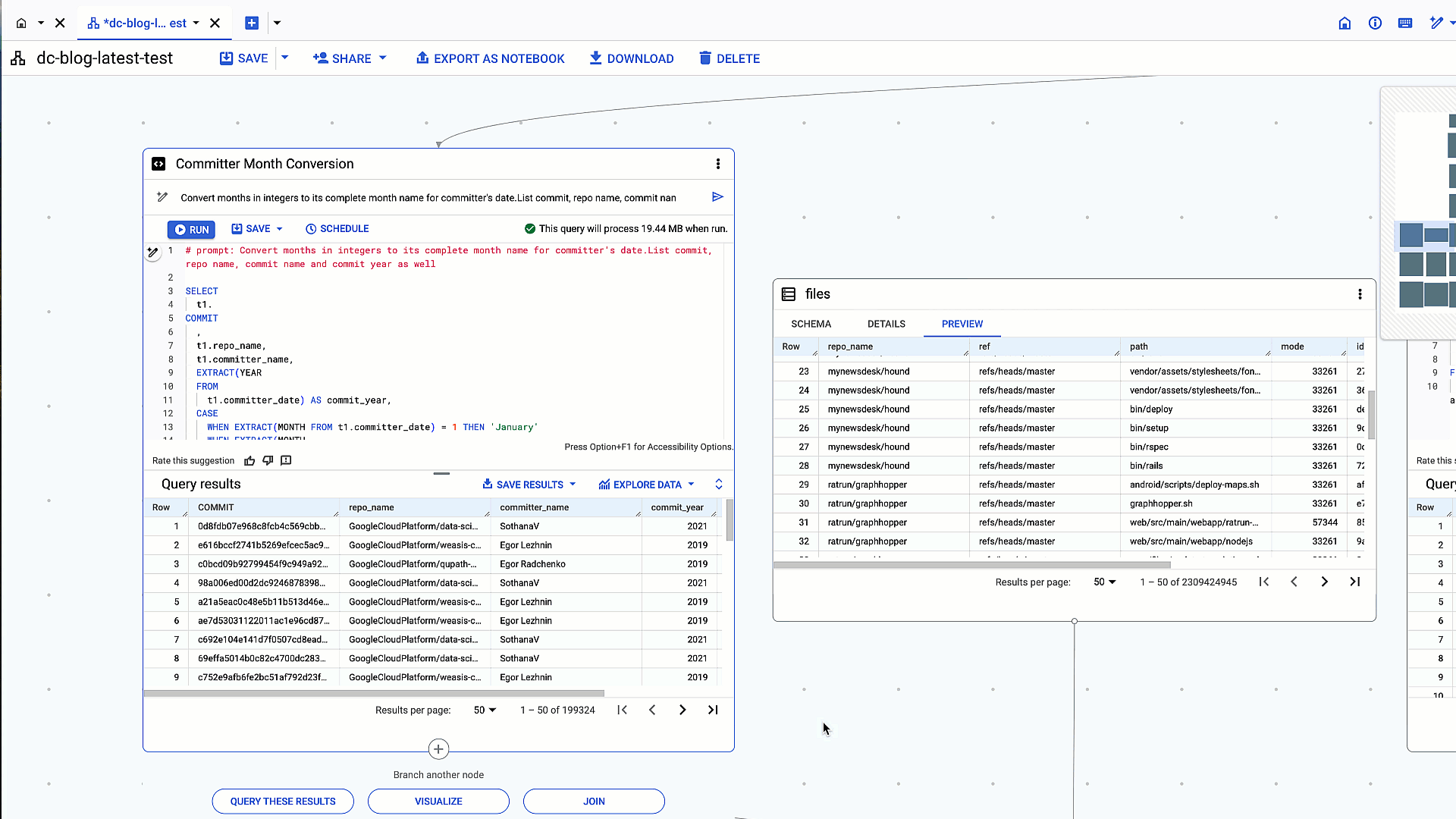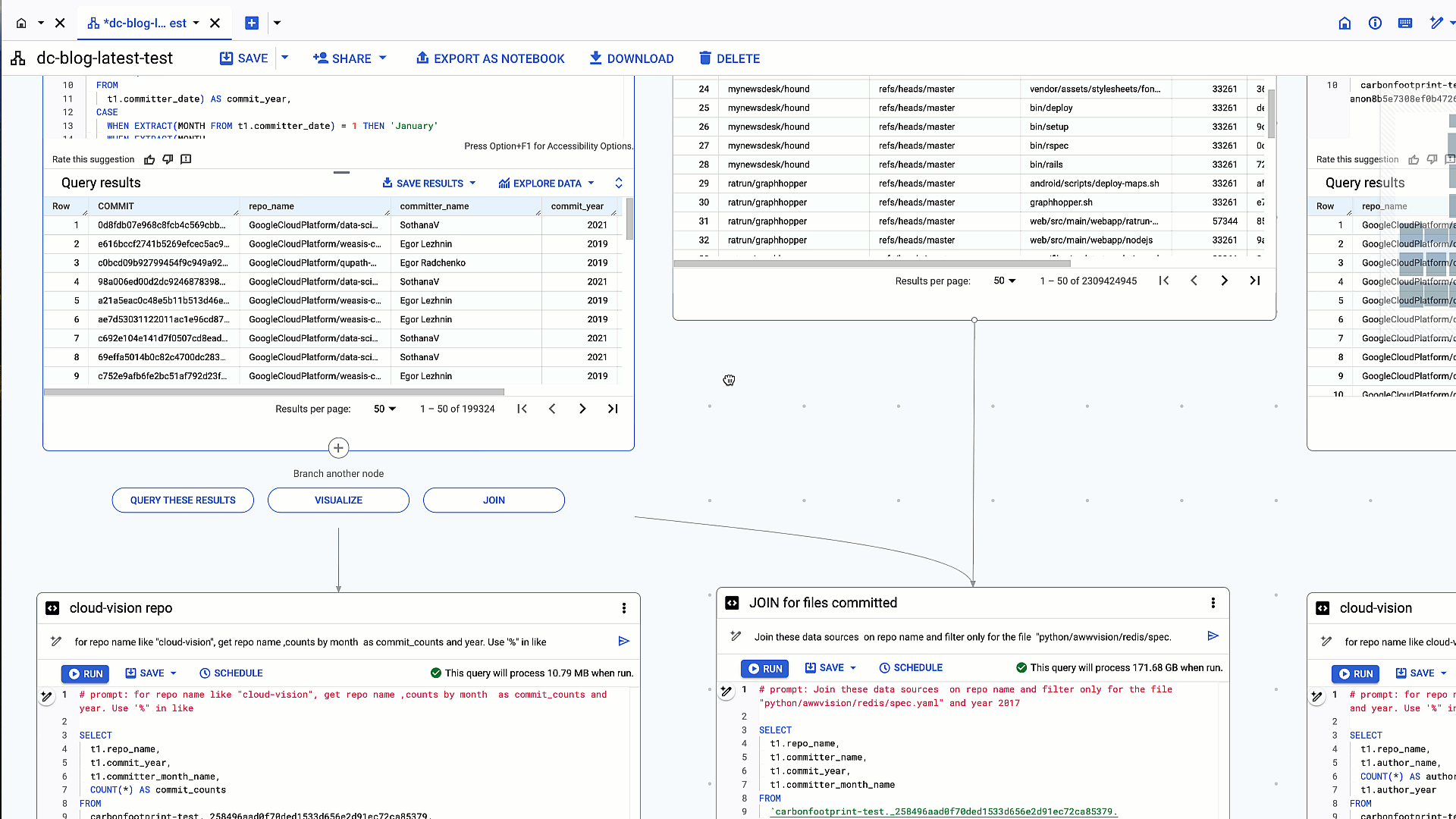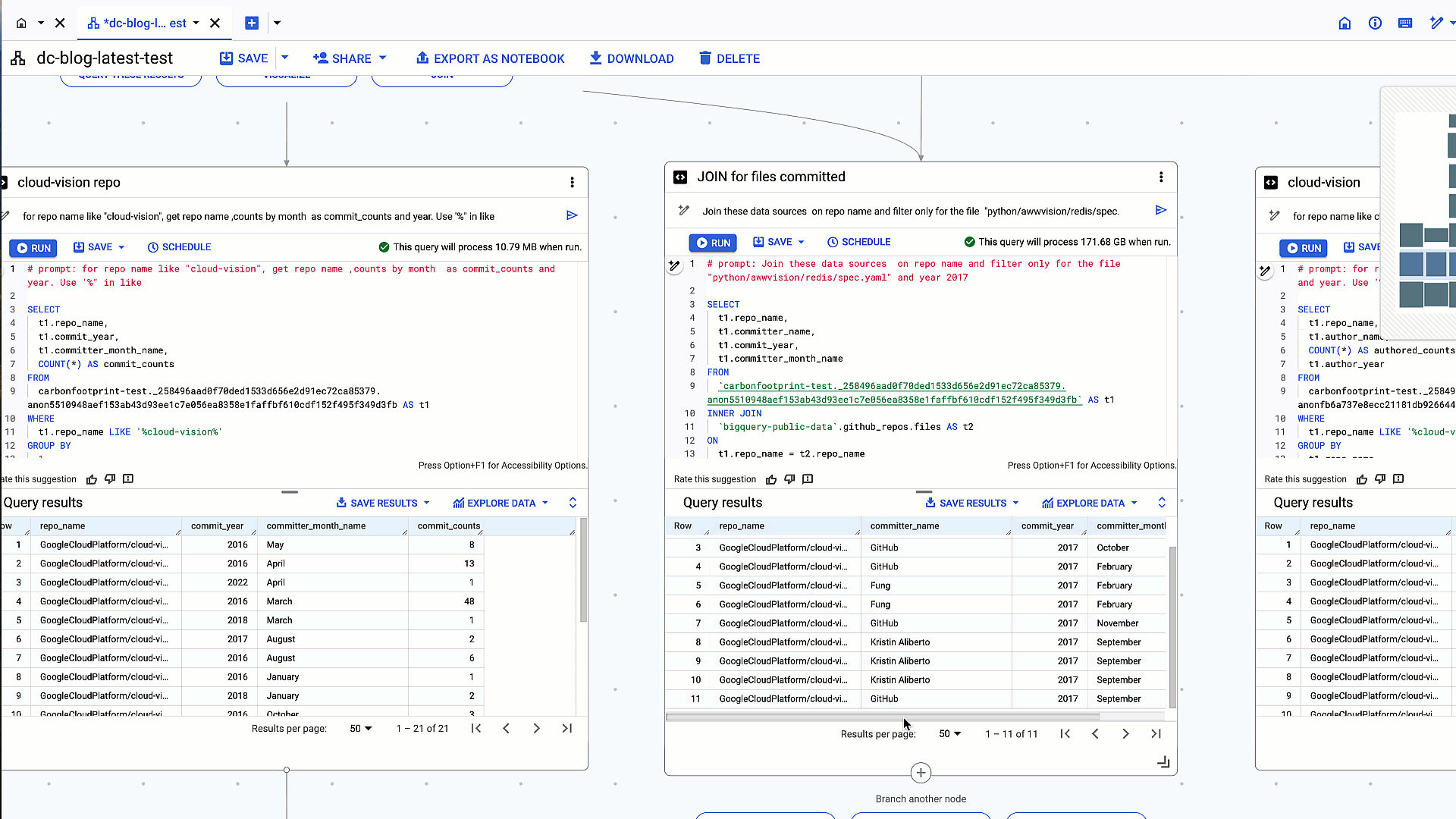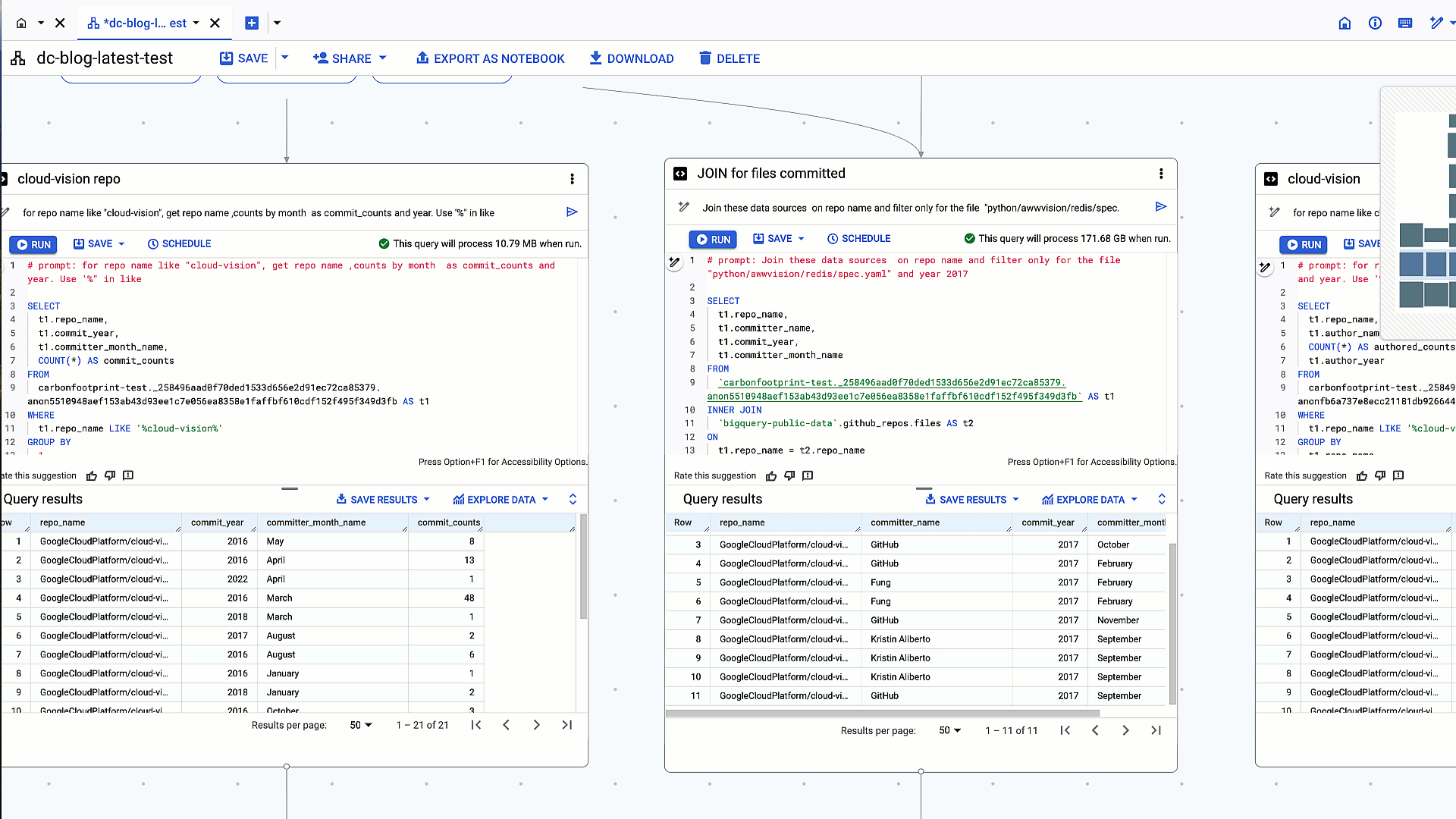
クエリ結果と github_repos.files テーブルを repo_name でテーブル結合
データ キャンバスで NL2SQL を使用するもう一つの典型例として、データ型の変換があります。ここでは作成者の日付とコミッターの日付のエポックタイムを実際の日付に変換するために、日付変換を行う必要があります。Gemini はエポックタイムを秒単位で理解し、適切なタイムスタンプ関数と日付関数を適切な順序で適用して、日付を正しく変換します。github_repos のアクティビティ データは 2016 年から 2022 年にまたがっていますが、これは予想した結果と一致しています。
3. 秒単位で表された作成者の日付とコミッターの日付の日付変換を行う
# prompt: convert both author and commiter date in seconds to timestamp seconds to a date. Include commit, repo, author and commiter names too
生成された SQL:
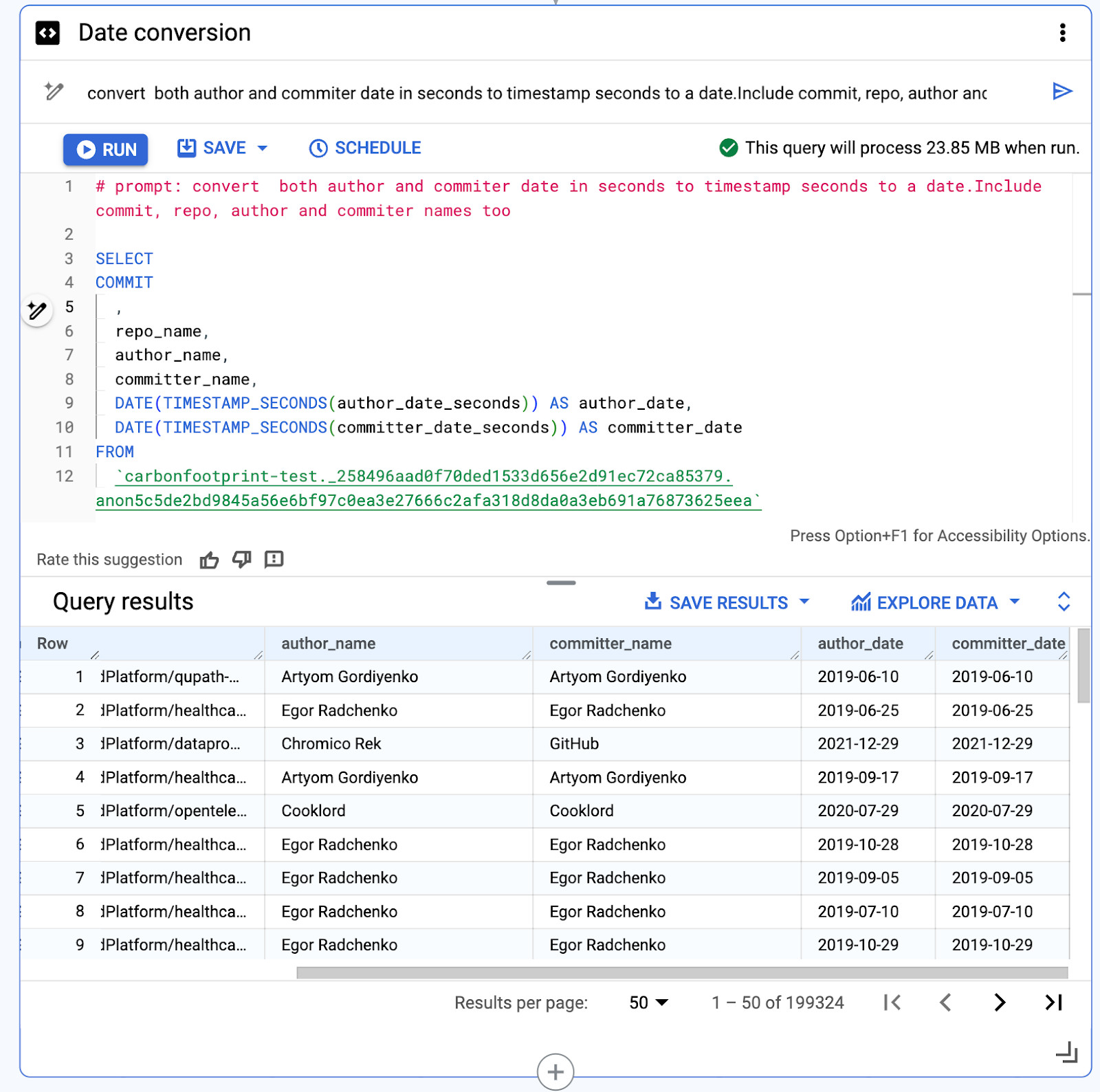
秒単位のエポックタイムから正しく変換された作成者の日付とコミッターの日付
さらに踏み込むと、Gemini がいかに複雑なクエリを生成し、質問されたことのみに基づいてロジックを見つけ出しているのかがわかります。このケースでは、日付から月と年を抽出し、整数で表された月を実際の月名に変換するように依頼しました。手作業でクエリを作成するよりかなり早く、チームの他のメンバーとも簡単に共有できます。
4. 日付型から月と年を抽出し、整数で表された月を完全な月名に変換する
# prompt: Convert months in integers to its complete month name for committer's date. List commit, repo name, author name ,committer name, author date and year , committer date and year for repo like 'cloud-vision’. Use "%" in like
生成された SQL:
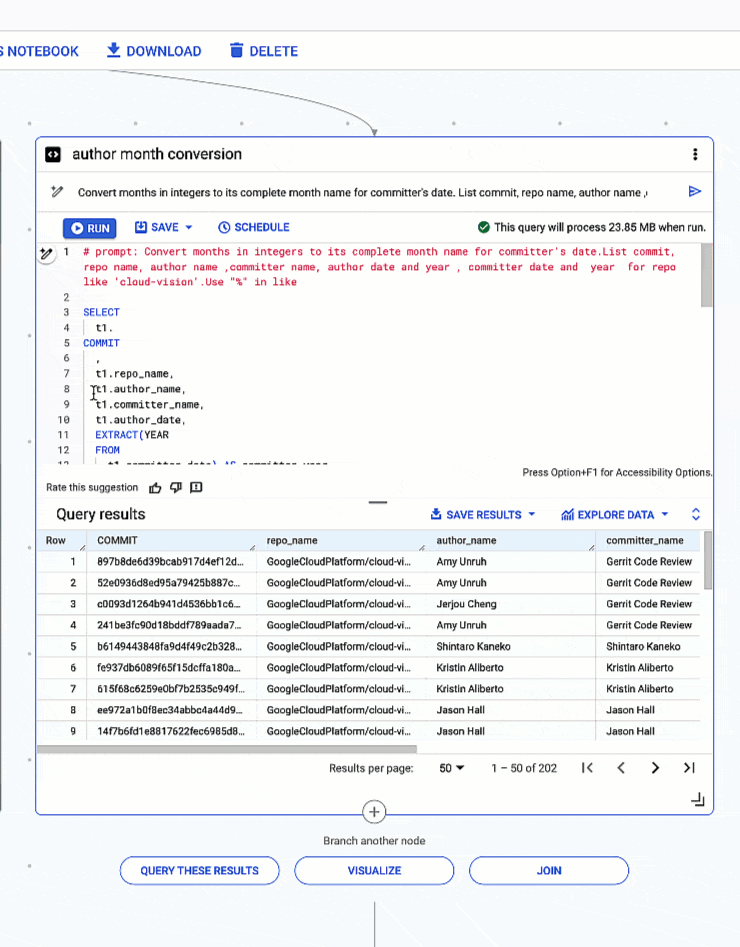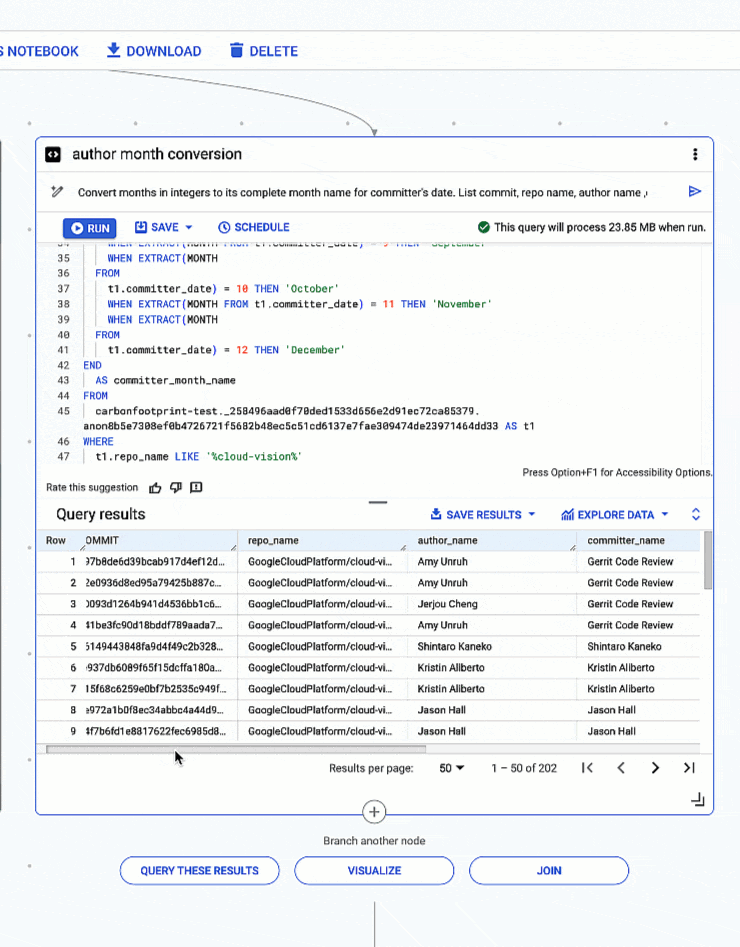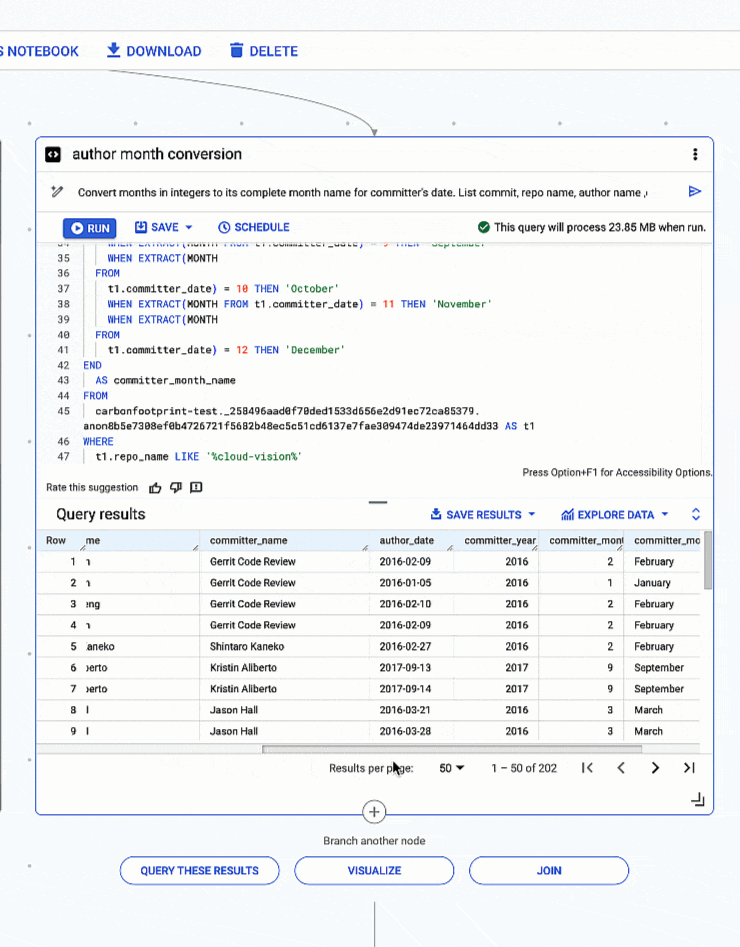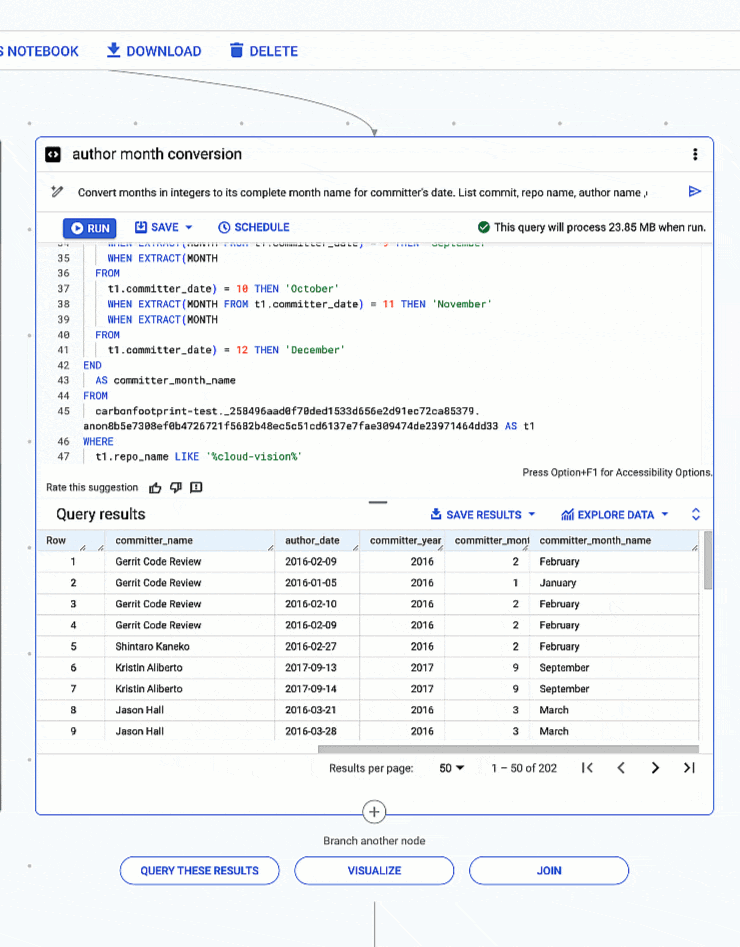
整数で表された月を完全な月名に変換
次に紹介するのは、特定の repo_name を指定してデータを絞り込み、特定の年の特定のリポジトリに対する commit_counts の数を調べる方法です。そこから、NL2Chart を使用して円グラフを生成できます。生成 AI でデータの要約を生成するという選択肢もあります。ここではさらに、一見しただけではわからないグラフの重要ポイントを明らかにします。グラフの特定の部分にカーソルを合わせると、ポインタのツールチップで説明が表示されます。この可視化は png や Looker Studio にエクスポートすることも、他の人と共有することもできます。ノードの下にある編集オプションをクリックすると、グラフのプロパティを編集したり、JSON 出力エディタにアクセスしたりできます。
5. 特定の repo_name に関する可視化と要約を生成する
# prompt: for repo name like "cloud-vision", get repo name ,counts by month as commit_counts and year. Use “%" in like
生成された SQL:
可視化結果:
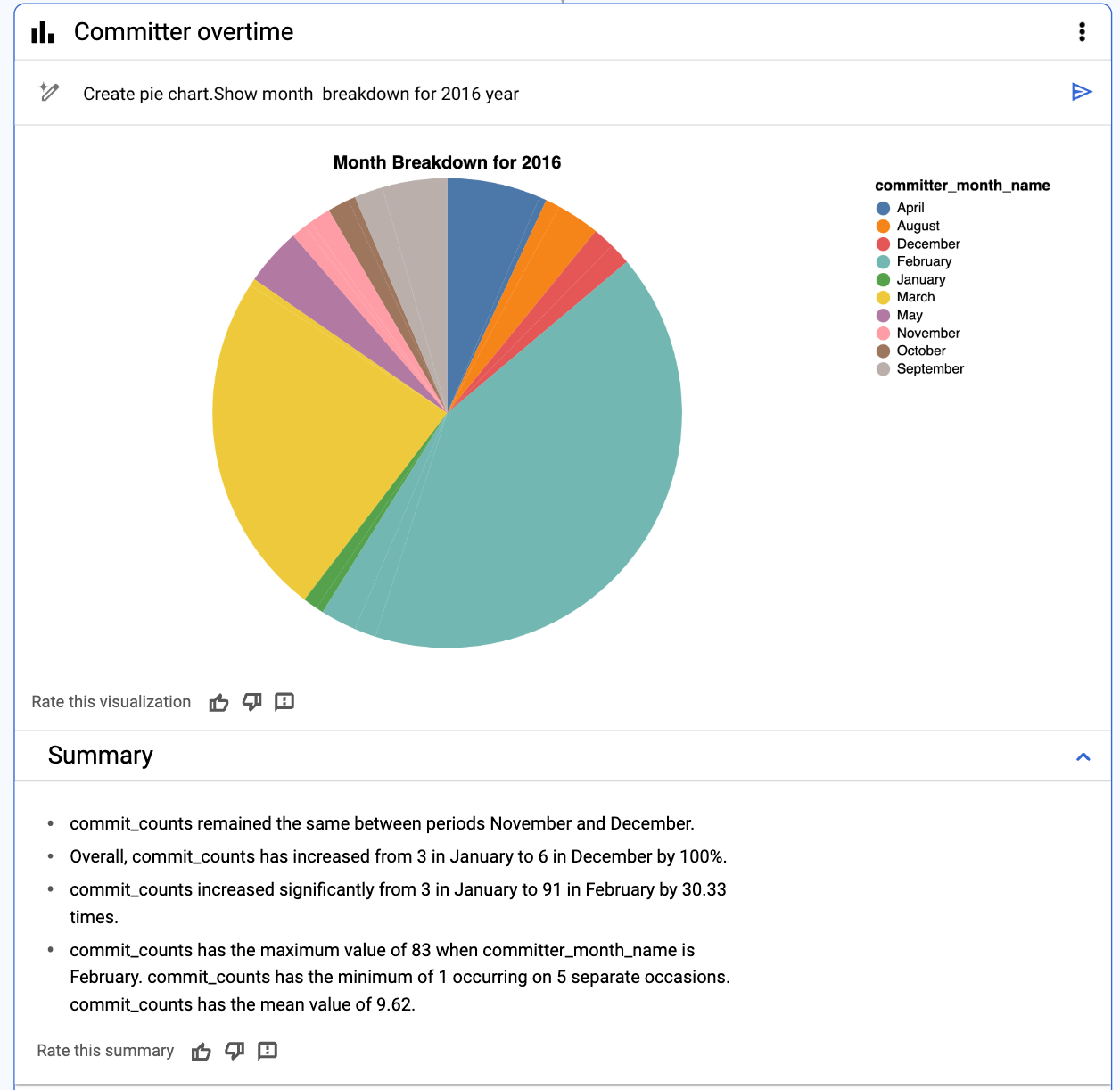
2016 年の 1 年間におけるコミッターの数を表す円グラフの出力結果
最後に、BigQuery データ キャンバスを使用して ETL(抽出、変換、読み込み)ワークフローを DAG 形式で視覚的に設計したら、それを BigQuery Colab Enterprise ノートブックにエクスポートして、視覚的な形式からコード化されたノートブック環境に移行し、さらに分析やカスタマイズを行うことができます。ランタイム環境に接続するには適切なネットワーキング パラメータを設定することが重要であるため、BigQuery Studio のノートブックに関するリファレンスを参照してください。
BigQuery データ キャンバスでデータ分析を効率化する
さまざまな分野にまたがる広範なデータセットを扱う場合、新しいプロジェクトやユースケースのデータを理解するのが難しいことがあります。データ キャンバスを使用すると、このプロセスを効率化できます。データ キャンバスは自然言語に基づく SQL の生成と可視化を通じてデータ分析を簡素化することで、作業効率を向上させ、ワークフローを迅速化します。反復的なクエリが最小限に抑えられ、データの自動更新をスケジュール設定できるようになります。BigQuery データ キャンバスは一般提供されているため、今すぐ使用を開始できます。プロンプト エンジニアリングのベスト プラクティスについては、BigQuery データ キャンバスのプロンプト記述に関するベスト プラクティスに関するブログ投稿をご覧ください。
関連情報
ー Google、生成 AI ソリューション アーキテクト、Layolin Jesudhass
ー Google、データ分析担当カスタマー エンジニア Christine De Sario



