Apache Iceberg BigQuery テーブル : オープン レイクハウス向けに最適化されたストレージ
Anoop Johnson
Principal Engineer
Dylan Myers
Group Product Manager
※この投稿は米国時間 2024 年 10 月 12 日に、Google Cloud blog に投稿されたものの抄訳です。
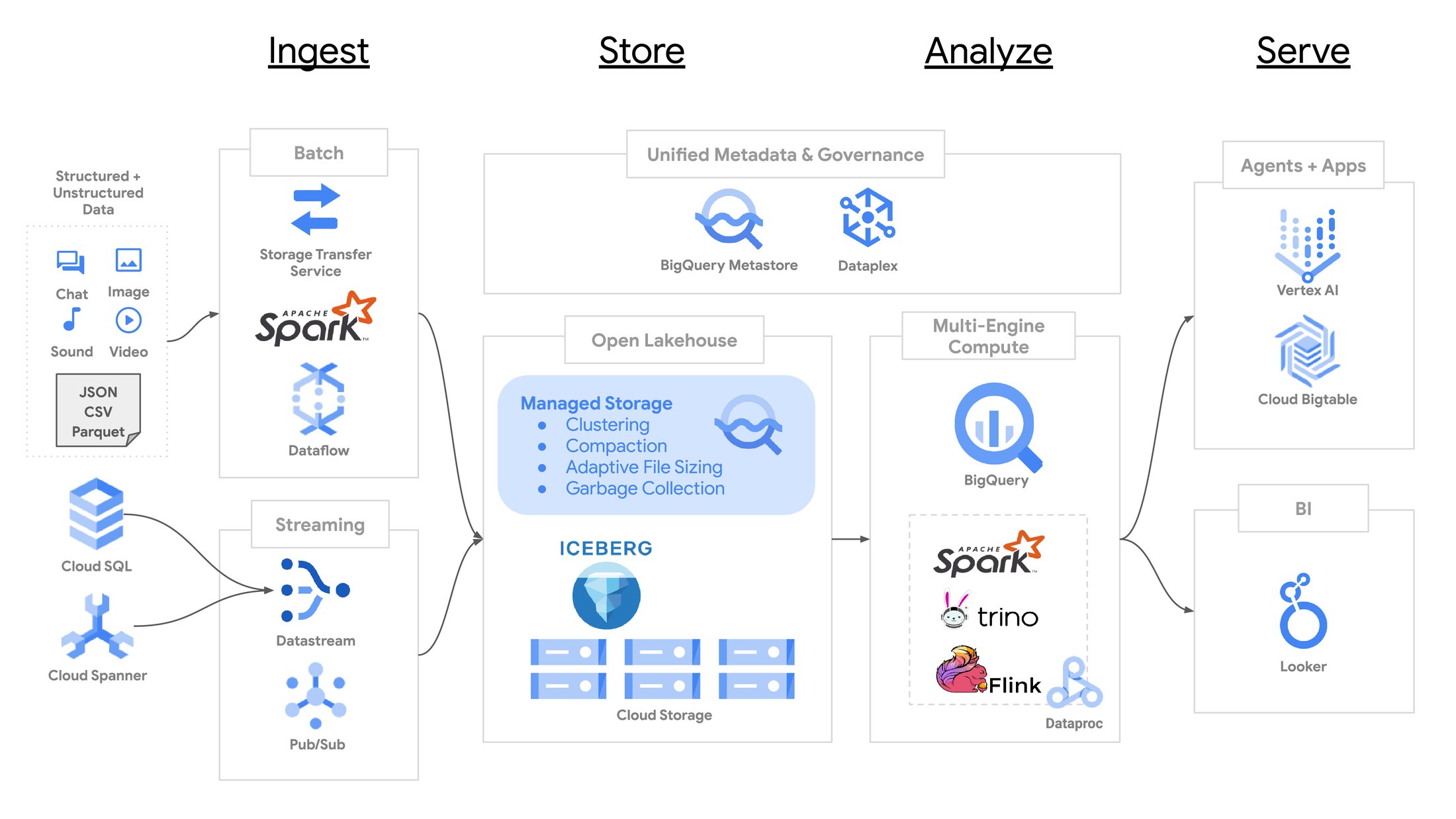
BigQuery のネイティブ テーブルは、ACID トランザクション、ストリーミング挿入、ストレージの自動最適化など、エンタープライズ レベルのデータ管理機能を長年にわたってサポートしてきました。 多くの BigQuery ユーザーは、Apache Parquet などのオープンソースのファイル形式と Apache Iceberg などのテーブル形式を使用して、データレイクにデータを保存しています。 2022 年には、お客様がデータを一元管理し、BigQuery のセキュリティとパフォーマンスのメリットを享受できるように、BigLake テーブルをリリースしました。 ただし、BigLake テーブルは現在読み取り専用です。 BigQuery ユーザーは、外部クエリエンジンを介してデータの変更を実行し、データ管理を手動で調整する必要があります。 もう 1 つの課題は、取り込み時の「スモール ファイル問題」です。 クラウドオブジェクト ストレージは追加をサポートしていないため、テーブルへの書き込みはマイクロバッチ化する必要があり、パフォーマンスとデータの整合性の間でトレードオフが必要になります。
本日、Apache Iceberg BigQuery テーブル のプレビュー版を発表できることを嬉しく思います。これは、BigQuery のフルマネージドの Apache Iceberg 互換ストレージ エンジンであり、自律的なストレージ最適化、クラスタリング、高スループットのストリーミング挿入などの機能を備えています。Apache Iceberg BigQuery テーブル は、Apache Iceberg 形式を使用して顧客所有のクラウドストレージ バケットにデータを保存しながら、BigQuery ネイティブ テーブルと同様の顧客エクスペリエンスと機能セットを提供します。 Apache Iceberg BigQuery テーブルを通じて、10 年にわたる BigQuery のイノベーションをレイクハウスにもたらします。
Apache Iceberg BigQuery テーブルは、GoogleSQL データ操作言語(DML)を介して BigQuery から書き込み可能であり、BigQuery の Storage Write API を介して Apache Spark などのオープンソース エンジンからの高スループットのストリーミング挿入をサポートしています。 クラスタリングを使用してテーブルを作成する例を次に示します。
レイクハウス向けのフルマネージド エンタープライズ ストレージ
Apache Iceberg BigQuery テーブルは、オープンソースのテーブル形式の制限に対処します。 Apache Iceberg BigQuery テーブルを使用すると、BigQuery はお客様の手間をかけずにテーブルのメンテナンス タスクを自律的に処理します。 BigQuery は、小さなファイルを最適なファイルサイズに結合し、データの自動再クラスタリングとファイルのガベージ コレクションを提供することで、テーブルを最適化された状態に保ちます。 たとえば、最適なファイルサイズは、テーブルのサイズに基づいて適応的に決定されます。 Apache Iceberg BigQuery テーブルは、BigQuery ネイティブ テーブルの自動ストレージ最適化を 10 年以上にわたって効率的かつ費用対効果の高い方法で実行してきた専門知識の恩恵を受けています。 OPTIMIZE または VACUUM を手動で実行する必要はありません。
高スループットのストリーミング挿入の場合、Apache Iceberg BigQuery テーブル は、BigQuery Storage Write API を強化するエクサバイト規模の構造化ストレージ システムである Vortex を活用します。 Apache Iceberg BigQuery テーブルは、最近取り込まれたタプルを行指向形式で永続的に保存し、定期的に Parquet に変換します。 高スループットの挿入と並列読み取りは、オープンソースの Spark および Flink BigQuery コネクタによってサポートされています。 Pub/Sub と Datastream は Apache Iceberg BigQuery テーブルにデータを取り込むことができるため、専用のインフラストラクチャを維持する必要はありません。
Apache Iceberg BigQuery テーブルは、BigQuery のスケーラブルなメタデータ管理システムにテーブル メタデータを保存します。 BigQuery はきめ細かいメタデータを保存し、分散クエリ処理とデータ管理手法を使用してメタデータを処理します。 その結果、Apache Iceberg BigQuery テーブルは、メタデータをオブジェクト ストレージにコミットする必要がなくなり、テーブル形式で可能なよりも高いレートの変更が可能になります。 ライターはトランザクション ログを直接変更できないため、テーブル メタデータは改ざん防止され、信頼性の高い監査履歴があります。
Apache Iceberg BigQuery テーブルは、Storage API によって適用されるきめ細かいセキュリティポリシーを引き続きサポートしながら、Dataplex を介したガバナンス ポリシー管理、データ品質、エンドツーエンドのリネージのサポートを拡張します。

Apache Iceberg BigQuery テーブルは、メタデータをクラウド ストレージの Iceberg スナップショットにエクスポートします。 最新のエクスポートされたメタデータへのポインタは、今年初めに発表されたサーバーレス ランタイム メタデータ サービスである BigQuery メタストアにすぐに登録されます。 Iceberg メタデータのエクスポートにより、Iceberg を理解できるエンジンであれば、Cloud Storage から直接データをクエリできます。
詳細はこちら
世界最大の医療提供者の 1 つである HCA Healthcare のようなお客様は、BigQuery の Apache Iceberg 互換ストレージ レイヤーとして Apache Iceberg BigQuery テーブルを活用することに価値を見出し、新しいレイクハウスのユースケースを可能にしています。 Apache Iceberg BigQuery テーブルのプレビュー版は、現在すべての Google Cloud リージョンで利用できます。 ドキュメントに従って、今すぐ開始できます。
-プリンシパル エンジニア Anoop Johnson
-グループ プロダクト マネージャー Dylan Myers


