BigQuery の履歴ベースの最適化でクエリのパフォーマンスを最大 100 倍向上
Peter Freiling
Software Engineer, Google
Andrei Romanenko
Software Engineer, Google
※この投稿は米国時間 2024 年 10 月 15 日に、Google Cloud blog に投稿されたものの抄訳です。
ユーザーは、インサイトを得るために、あらゆる手段を尽くし、データ ウェアハウスにさまざまなクエリを投入して、疑問に対する答えを見つけようとします。これらのクエリの中には、大量の計算リソースを消費するものがあり、その多くは互いに非常によく似ています。。クエリの実行をさらに高速化するために、私たちは BigQuery の履歴ベースの最適化を開発しました。これは、過去に実行された類似のクエリから学習し、クエリの実行に対するさらなる改善を特定して適用する、新しいクエリの最適化手法です。これにより、クエリの実行速度が向上したり、リソースの消費量が削減されたりすることで、経過時間、スロット時間、処理済みバイト数など、さまざまなパフォーマンス指標が向上します。
履歴ベースの最適化では、過去の類似クエリの具体的な実行データを利用することで、特定のワークロードに適した、効果の高い最適化を確実に対象とすることができます。
履歴ベースの最適化のパブリック プレビューでは、お客様のワークロードのクエリのパフォーマンスが最大 100 倍向上したケースが見られました。現在、履歴ベースの最適化は一般提供されています。
このブログ投稿では、履歴ベースの最適化の基盤となるテクノロジー、その利点、およびその開始方法について詳しく説明します。
動作のしくみ
履歴ベースの最適化は、ユーザーの介入なしに改善を実現するように設計されています。インフラストラクチャは自己調整型および自己修正型であり、特別な構成や操作は必要ありません。
クエリを実行すると、BigQuery は各クエリの実行後に統計データを分析し、次回類似のクエリを実行する際に適用できるワークロード固有の最適化を特定します。これはバックグラウンドで行われ、ユーザーのワークロードに影響を与えることはありません。次回の実行で最適化が有益であることが確認されると、さらに多くの最適化を特定して適用できるようになり、クエリのパフォーマンスが反復的かつ段階的に向上します。

履歴ベースの最適化は、最適化によってクエリのパフォーマンスが大幅に向上しない(または悪化する)まれなケースにも対応し、今後そのクエリの実行でその特定の最適化を使用しないように自己修正します。ユーザーが介入する必要はありません。
クエリ マッチング
BigQuery はインテリジェントなクエリ マッチング アルゴリズムを使用して、特定された最適化を共有できるクエリの数を最大化すると同時に、大幅に異なるクエリにそれらを適用するリスクを最小限に抑えます。
コメント文字列や空白の変更など、些細なクエリの変更は、以前に特定されたすべての最適化を再利用します。このような変更は、クエリの実行に影響を与えません。
定数やクエリ パラメータの値を変更するなどの重要な変更では、BigQuery が変更されたクエリに利点をもたらすと確信しているかどうかに応じて、以前に特定された最適化の一部を再利用し、他の最適化を無視する場合があります。
異なるソース テーブルや列のクエリなど、クエリに大幅な変更があった場合、BigQuery は以前に特定されたすべての最適化を無視します。これは、最適化の特定に使用された統計データが、変更されたクエリには適用されなくなる可能性が高いためです。
履歴ベースの最適化は、現在、特定の Google Cloud プロジェクトの範囲に限定されています。
最適化の種類
現時点では、履歴ベースの最適化では、既存の最適化手法を補完する 4 種類の最適化がサポートされています。
JOIN プッシュダウン
JOIN プッシュダウンは、選択性の高い結合を最初に実行することで、処理されるデータ量を削減することを目的としています。
クエリの実行が完了すると、BigQuery は選択性の高い結合を特定する場合があります。これは、結合の出力(行数)が入力よりも大幅に少ない結合です。このような結合が、他の結合や集計など、選択性の低い他の操作の後に実行される場合、BigQuery は選択性の高い結合を先に実行することを選択する場合があります。これにより、図 1 に示すように、実行順序で選択性の高い結合が効果的に「プッシュダウン」されます。これにより、クエリの残りの部分で処理する必要のあるデータ量が削減され、消費されるリソースが削減され、クエリ実行の全体的な時間が向上します。
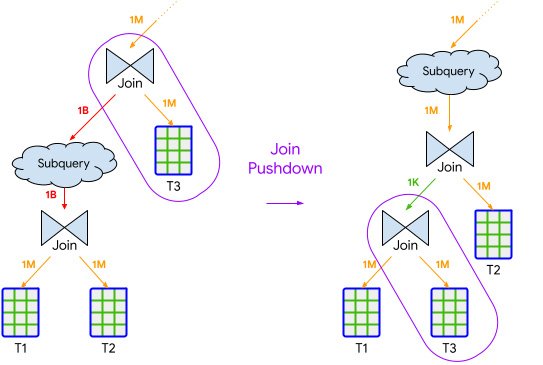
図 1. JOIN プッシュダウン履歴ベースの最適化の例。選択性の高い結合をテーブル T3 とともに実行順序で「プッシュダウン」して、中間行数を減らします。
BigQuery は、以前の実行の統計情報を利用せずに一部のクエリの最適化をすでに実行していますが、履歴ベースの JOIN プッシュダウンでは、データの分布に関する追加のインサイトを活用してパフォーマンスをさらに向上させ、より多くのクエリに適用します。
セミ結合の削減
セミ結合の削減は、クエリ全体に選択的なセミ結合操作を挿入することにより、BigQuery がスキャンするデータ量を削減することを目的としています。
BigQuery は、最終的に結合される複数のパラレル実行パスを持つクエリで、選択性の高い結合(JOIN プッシュダウンと同様)を特定する場合があります。場合によっては、BigQuery は、図 2 に示すように、選択性の高い結合に基づいて新しい「セミ結合」操作を挿入できます。これにより、これらのパラレル実行パスによってスキャンおよび処理されるデータ量を「削減」します。これは論理的にはセミ結合としてモデル化されていますが、通常はパーティションのプルーニングなどの他の内部最適化によって実行されます。
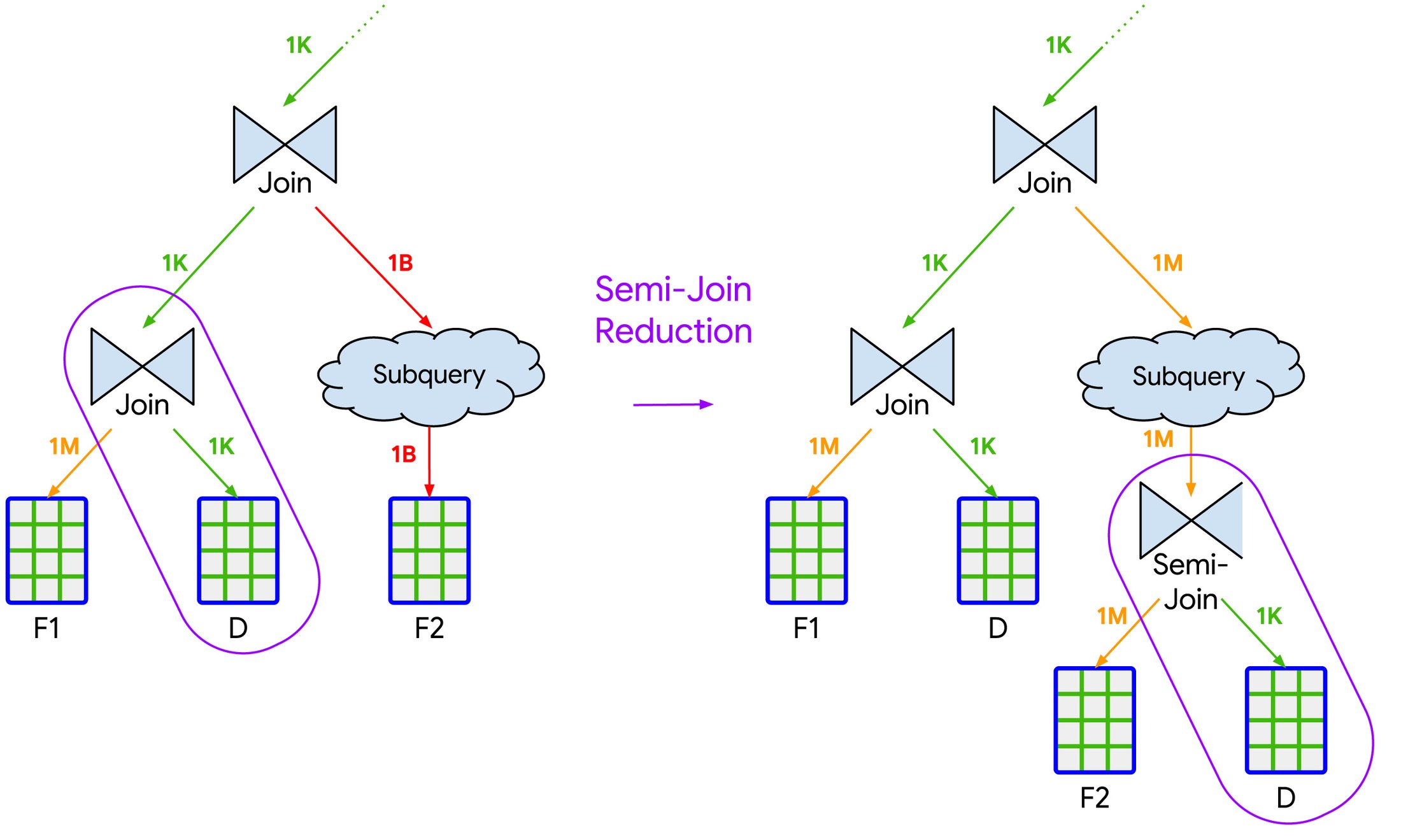
図 2. セミ結合削減履歴ベースの最適化の例。選択性の高い結合を使用して、新しいセミ結合をクエリに挿入し、2 番目のファクトテーブル F2 から処理される行数を減らします。
結合の交換
結合の交換は、結合操作の左右を入れ替えることにより、消費されるリソースを削減することを目的としています。
結合操作を実行する場合、結合の両側を異なる方法で処理できます。たとえば、BigQuery は結合の一方の側でハッシュ テーブルを作成することを選択する場合があります。これは、結合のもう一方の側をスキャンするときにプローブされます。結合の両側は「交換可能」であるため(順序によって結果が変わることはありません)、場合によっては、BigQuery はこれら 2 つの側を入れ替える方が効率的であると判断し、その結合操作の実行に消費されるリソースを削減する場合があります。
並列性の調整
並列性の調整は、作業をより効率的に並列化することにより、クエリのレイテンシを改善することを目的としています。
BigQuery は、分散並列アーキテクチャを使用して、クエリを段階的に実行します。このような各ステージについて、BigQuery は作業を実行するための初期並列度を選択します。ただし、観測されたデータパターンに応じて、実行中に並列度を動的に調整する場合があります。
履歴ベースの最適化を使用すると、BigQuery はクエリの以前の実行の既知のワークロード分布を考慮して、「並列性」の初期レベルを「調整」できるようになりました。これにより、BigQuery は作業をより効率的に並列化し、オーバーヘッドを削減し、特に計算量の多い大規模なステージを含むクエリのレイテンシを短縮できます。
試してみましょう
履歴ベースの最適化は一般提供されています。今後数か月で、すべてのお客様に対してデフォルトで有効になりますが、プロジェクトまたは組織でそれらを早期に有効にすることができます。INFORMATION_SCHEMA で、適用された履歴ベースの最適化(存在する場合)を確認したり、ジョブに対する履歴ベースの最適化の影響を理解したりできます。
次のサンプルクエリを使用して、履歴ベースの最適化を試すことができます。
-
このデモクエリをまだ実行していないプロジェクトを選択または作成します(そうしないと、すでに最適化されているクエリのみが監視される可能性があります)。
-
選択したプロジェクトの履歴ベースの最適化を有効にします。
-
キャッシュされた結果の取得を無効にします。
BigQuery 公開データセットを使用する次のサンプルクエリを実行し、経過時間を記録します。
5. 同じデモクエリを再度実行し、経過時間を最初の実行と比較します。
6. 必要に応じて、各実行のジョブ ID を使用して、こちらに記載されている手順に従って、各実行に履歴ベースの最適化が適用されたかどうかを確認できます。
今後の展望
履歴ベースの最適化は、単なる 4 つの新しい最適化の静的なセットではなく、BigQuery の最適化機能への継続的な投資の枠組みを構成しています。このテクノロジーにより、類似のクエリの以前の実行からの実際の統計データ(推定値だけでなく)がなければ実装できない、新しいクラスの最適化が可能になります。その自己学習および自己修正機能は、予期せぬ問題に対する安全メカニズムとして機能します。Google は、既存および将来の履歴ベースの最適化を継続的に拡張することで、BigQuery をよりスマートにし、変化するワークロードに自律的に適応させることを目標としています。ユーザーは何もする必要はありません。クエリはより高速かつ低コストで実行されます。上記の手順に従って今すぐお試しになり、BigQuery コンソールからご意見をお聞かせください。
-Google ソフトウェア エンジニア Peter Freiling
-Google ソフトウェア エンジニア Andrei Romanenko

