Gemini と BigQuery で始める NL2SQL(自然言語から SQL への変換NL2SQL with BigQuery and Gemini | Google Cloud Blog)
Bernard Chang
Technical Account Manager
Wei Yih Yap
Generative AI Field Solutions Architect
※この投稿は米国時間 2024 年 11 月 8 日に、Google Cloud blog に投稿されたものの抄訳です。
自然言語処理(NLP)と従来の構造化クエリ言語(SQL)を組み合わせることで、自然言語から SQL への変換(NL2SQL)として知られる魅力的で新しい技術が生まれました。これは、日常的な人間の言葉で表現された質問を構造化された SQL クエリに変換する技術です。
言うまでもなく、この技術はデータとの関わり方を変革する大きな可能性を秘めています。
NL2SQL を活用することで、ビジネス アナリストやマーケター、その他の分野のエキスパートといった非技術系のユーザーが、専門的な SQL の知識を必要とせずに自らデータベースと対話し、データを探索して洞察を得ることができます。SQL に精通している人々にとっても、NL2SQL は複雑なクエリを手作業で作成する時間を短縮し、より戦略的な分析や意思決定のための時間を確保できます。
では、これは実務でどのように活用できるのでしょうか?チャット インターフェースに話しかけて、次のような質問に対する回答がその場で得られると想像してみてください。
-
「今月これまでに販売されたユニットの合計数はいくつですか?」
-
「アジア太平洋地域の売上について、第 1 四半期と第 2 四半期を比較した場合の主な変動要因は何ですか?」
従来であれば、データベースからデータを収集し、それをビジネス インサイトに変換するには専門家が必要でした。NL2SQL を活用することで、データへのアクセス障壁を低減し、誰もが分析できる環境を実現できます。
しかしながら、NL2SQL が広く採用されるのを難しくする課題も存在します。このブログ記事では、Google Cloud 上の NL2SQL ソリューションと、その実装におけるベスト プラクティスを探ります。
現実世界での実用におけるデータの品質上の課題
まずは、NL2SQL の実装を困難にしている要因について、詳しく見ていきましょう。
NL2SQL は管理された環境や直接的な質問では優れた性能を発揮しますが、実際の本番環境のデータには以下のようなさまざまな課題があります。
データ形式のばらつき: 同じ情報が異なる形式で表現されることがあります。たとえば、性別であれば「Male」「male」「M」、金額であれば「1000」「1k」「1000.0」などの表記が考えられます。さらに、多くの組織では独自の略語を使用していますが、それらが適切に文書化されていないケースがあります。
意味の曖昧性: 大規模言語モデル(LLM)は多くの場合、特定ドメインのスキーマに関する理解が不足しており、そのためユーザーのクエリを誤って解釈してしまうことがあります。たとえば、同じ列名が異なる意味を持つ場合などです。
SQL の構文的な厳密性: 意味的に正しいクエリであっても、SQL の厳格な構文ルールに従っていない場合は失敗する可能性があります。
カスタム ビジネス指標: NL2SQL は、複雑なビジネス計算を処理し、外部キーを通じてテーブル間の関係を理解する必要があります。質問を正確に変換するには、結合およびモデリングされるテーブルについての繊細な理解が必要です。さらに、各組織には説明が主である最終的なレポートを作成するうえで測定すべき独自のビジネス指標があり、単一の一般的なアプローチは存在しません。
お客様の課題
曖昧であったり、形式が正確でなかったりするのはデータだけではありません。ユーザーの質問も、しばしば混乱を招いたり複雑であったりします。NL2SQL の実装を困難にするユーザーからの質問に関する 3 つの一般的な問題を以下に示します。
曖昧な質問: 一見単純そうに見える質問でさえ、曖昧である可能性があります。たとえば、「今月これまでに販売されたユニットの合計数」に関するクエリでは、平均合計ユニット数(average_total_unit)を使用するのか、累計ユニット数(running_total_unit)を使用するのかなどを明確にする必要があるかもしれません。また、どの日付フィールドを使用するかも明確にする必要があります。理想的な NL2SQL ソリューションは、適切な列を指定するようユーザーに事前に促し、そのユーザーによる入力を SQL クエリ生成プロセスに組み込むべきです。
詳細不足の質問: もう一つの課題は、質問の詳細が不足していることです。たとえば、ユーザーからの「第 4 四半期における私のチーム配下の全製品の返品率」のような質問では、クエリを完全に解釈するために必要な情報(「私のチーム」がどのチームを指しているのかなど)が不足しています。理想的な NL2SQL ソリューションは、元の入力に含まれる不確実性を認識し、完全なクエリ表現を得るために、明確化を目的とした追加質問を行うべきです。
複数の分析ステップが含まれる複雑な質問: 多くの質問には複数の分析ステップが含まれています。たとえば、前四半期と比較した結果としての売上変動の主な要因を特定することを考えてみてください。理想的な NL2SQL ソリューションは、分析を扱いやすい要素に分解し、中間的な要約を生成し、最終的にユーザーのクエリに対応する包括的な最終レポートを作成する機能を持つべきです。
課題への対処
これらの課題に対処するため、質問をその複雑さに基づいて分類するルーティング エージェントとして、Gemini Flash 1.5 のプロンプト エンジニアリングを実行しました。質問が分類されると、曖昧性の確認、ベクトル エンベディング、セマンティック検索、貢献度分析モデリングなどの手法を使用して、出力を改善できます。
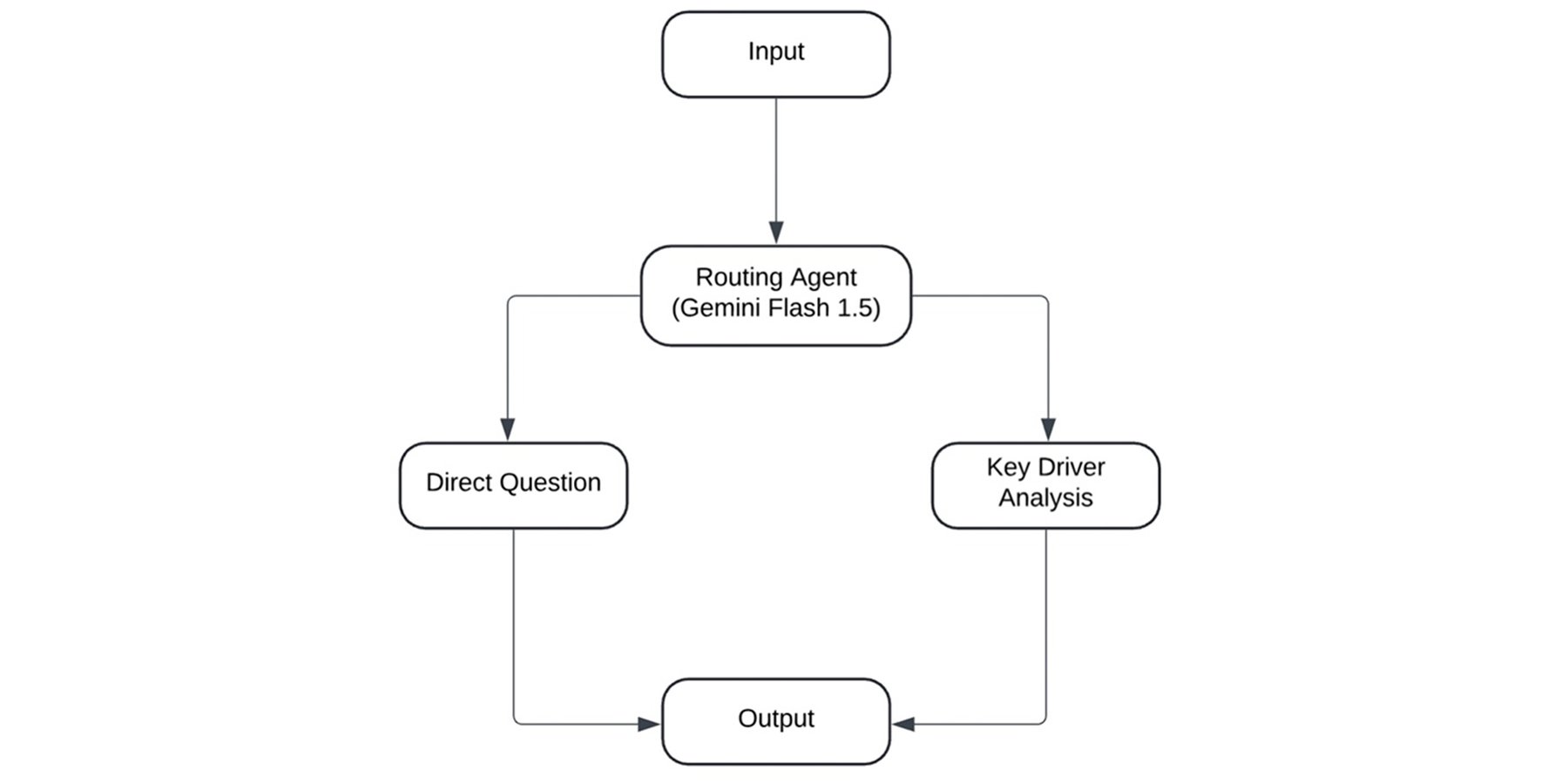
Gemini を使用して指示を受け取り、JSON 形式で応答します。たとえば、以下の少数ショット プロンプトにより、Gemini をルーティング エージェントとして機能させることができます。

直接的な質問
直接的な質問に対しては、コンテキスト内学習、ドラフト SQL の曖昧性チェック、ユーザー フィードバック ループを活用して、対象範囲内の正しい列名を明確にし、単純な質問に対する SQL の生成が曖昧にならないようにすることができます。
単純で直接的な質問に対して使用するアプローチでは、次のタスクを実行します。
-
適切な質問と SQL のペアを収集する
-
例を BigQuery の行として保存する
-
質問のベクトル エンベディングを作成する
-
ユーザーの質問に基づいて、BigQuery のベクトル検索を使用し、類似の例を抽出する
-
例、テーブル スキーマ、質問を LLM のコンテキストとして挿入する
-
ドラフト SQL を生成する
-
SQL の曖昧性チェック + ユーザー フィードバック + 改良 + 構文検証(ループ)を実施する
-
SQL を実行する
-
データを自然言語で要約する
ヒューリスティックな試験運用によると、Gemini は SQL の曖昧性をチェックするタスクで優れた性能を発揮することが示されました。まず、すべてのテーブル スキーマと質問をコンテキストとして含むドラフト SQL モデルを生成し、その後、ユーザーに対する明確化の質問を Gemini にプロンプトで求めました。
主要因分析
複数のステップで構成される推論を含むデータ分析では、アナリストが地域、製品カテゴリ、流通チャネルなど、考えられるあらゆる属性の組み合わせでデータを細分化する必要がありますが、このような分析は「主要因分析」とも呼ばれることがあります。このユースケースでは、Gemini と BigQuery の貢献度分析を組み合わせて使用することをおすすめします。
主要因分析では、直接的な質問に対して行われたステップの前に、以下の追加的ステップが組み込まれます。
主要因分析に関する質問がされた場合、ルーティング エージェントは主要因分析専用の処理にリダイレクトします。

- BigQuery ML ベクトル検索を使用して、エージェントは BigQuery のベクトル データベースに保存された正解(グラウンド トゥルース)から、類似した質問と SQL のエンベディング ペアを取得します。
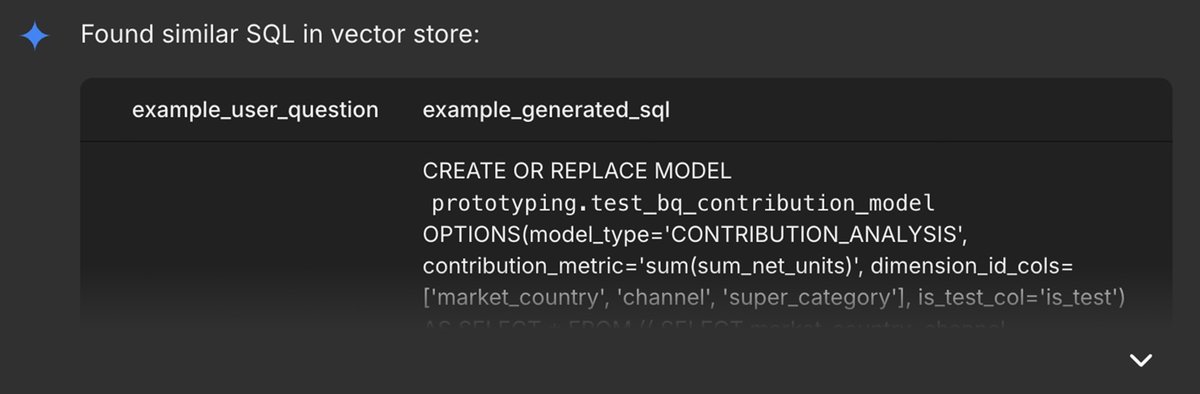
- その後、貢献度分析レポートを作成するために、CREATE MODEL ステートメントを生成し、検証します。
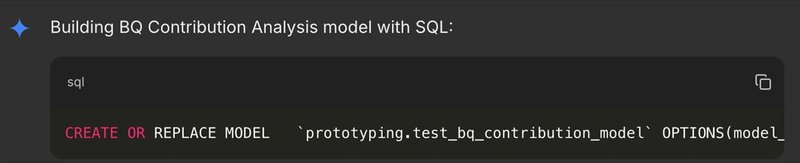
- 最終的に、以下の SQL を実行して貢献度分析レポートを取得します。

生成されたレポートは次のようになります。
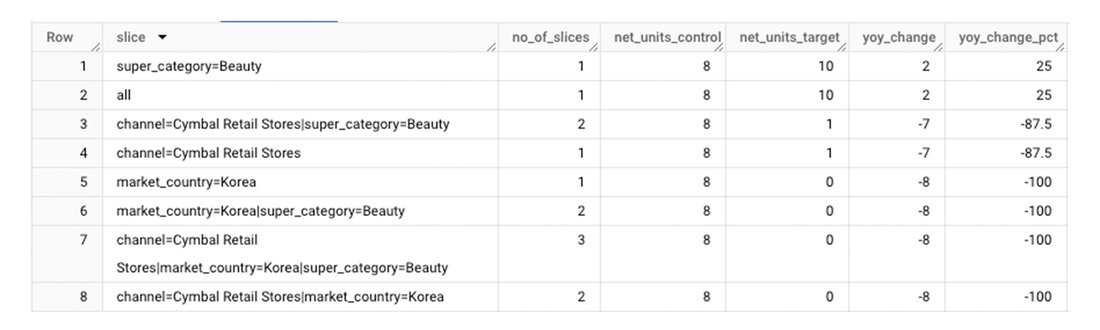
Gemini を使用してレポートをさらに自然言語で要約できます。

Google Cloud 上で NL2SQL を実装する
これは複雑に見えるかもしれませんが、Google Cloud は実用的な NL2SQL ソリューションを実装する際に役立つ完全なツールセットを提供しています。これについて詳しく見ていきましょう。
BigQuery のベクトル検索を使用したエンベディングと検索:
BigQuery はエンベディング ストレージと検索に使用され、意味的に関連する例やコンテキストの効率的な特定を可能にすることで、SQL 生成の精度を向上させます。Vertex AI のテキスト エンベディング API を使用するか、BigQuery で ML.GENERATE_EMBEDDING 関数を直接使用してエンベディングを生成できます。BigQuery をベクトル データベースとして使用し、ネイティブのベクトル検索を活用することで、ユーザーの質問と SQL のペアを簡単に照合できます。
BigQuery の貢献度分析
テストデータとコントロール データの両方を含むデータセットが与えられた場合、貢献度分析モデリングはデータセット全体で統計的有意性のある差異を特定することで、予期しない変化を引き起こしているデータのリージョンを検出できます。リージョンとは、次元値の組み合わせに基づいてデータを分割したセグメントのことです。
BigQuery ML で最近プレビュー版として発表された貢献度分析は、大規模な多次元データに対する自動インサイト生成と説明を可能にし、データに関する「なぜ?」「何が起きたのか?」「何が変化したのか?」といった質問への回答を手助けします。
簡単に言えば、BigQuery の貢献度分析モデルにより、NL2SQL を使用して複数のクエリをより簡単に生成でき、全体的な効率が向上します。
Gemini を使用した曖昧性チェック
従来、NL2SQL は自然言語クエリを構造化 SQL クエリに変換する一方向のプロセスでした。そこで、パフォーマンスを向上させるために、曖昧さを減らし、出力されるステートメントを改善するのに Gemini が役立ちます。
Gemini 1.5 Flash を使用して、質問、テーブル、列のスキーマが曖昧な場合に、明確化の質問を行い、ユーザーからのフィードバックを収集することで、生成される SQL クエリを洗練し、改善できます。また、Gemini とコンテキスト内学習を活用することで、効率的に SQL クエリを生成したり、自然言語で結果を要約したりできます。
アーキテクチャ案

NL2SQL のベスト プラクティス
この NL2SQL ソリューションの開発を通じて、多くのことを学びました。ご自身の NL2SQL プロジェクトをよりスムーズに進めるために、以下のヒントを参考にしてください。
適切な質問の特定から始める: 一見単純そうな質問であっても、望ましい答えや説明を得るには、最終的なレポートの目的に応じて、複数の推論ステップが必要になることがよくあります。試験運用を開始する前に、質問、SQL、想定される自然言語での正解(グラウンド トゥルース)を収集しておきましょう。
データの前処理が重要: LLM の使用は、データ クレンジングや前処理の代替にはなりません。ビジネス ドメイン固有の略語は意味のある説明やメタデータに置き換え、必要に応じて新しいテーブルビューを作成します。まずは単一のテーブルを使用する単純な質問から始め、その後で複雑な結合を必要とする質問に進むようにします。
ユーザー フィードバックとイテレーションによる SQL の洗練を実践する: ヒューリスティックな試験運用では、SQL の最初のドラフトを作成した後に、フィードバックを取り入れて改良する方が効果的であることが示されています。
複数ステップのクエリにはカスタムフローを使用する: BigQuery の貢献度分析モデルを使用することで、大規模な多次元データの自動インサイト生成と説明が可能になります。
次のステップ
NL2SQL、LLM、データ分析手法の組み合わせは、データを多くの人にとって、さらにアクセスしやすく、活用可能なものにするための重要な一歩を示しています。ユーザーが自然言語を使ってデータベースと対話できるようにすることで、データへのアクセスと分析を民主化し、組織内でより多くの人々が優れた意思決定を行えるようになります。
BigQuery の貢献度分析や Gemini などの新しい技術の進展により、かつてないほど簡単にデータの合理化、スケール、価値創出が可能になっています。BigQuery の貢献度分析の詳細については、こちらをご覧ください。今すぐ公開プレビュー版の利用を始めて、その可能性をご確認ください。
さらに詳しく知りたい方は、Google Cloud で BigQuery や生成 AI を活用する革新的な方法をご覧ください。
-テクニカル アカウント マネージャー Bernard Chang
-生成 AI フィールド ソリューション アーキテクト Wei Yih Yap




