サーバー不要のビッグデータ用オープンソース ソフトウェアの準備
Google Cloud Japan Team
※この投稿は米国時間 2020 年 10 月 23 日に、Google Cloud blog に投稿されたものの抄訳です。
Apache Hadoop、Apache Spark、Presto などのビッグデータ用オープンソース ソフトウェア(OSS)は、引き続きエンタープライズ データレイクやビッグデータ アーキテクチャの業界標準となっています。ベンダー ロックインを回避し、コストを削減して、コミュニティのイノベーション能力を活用するために企業がオンプレミス型 OSS デプロイメントを採用する中で、各企業とも、企業としての要件(セキュリティ、SLA など)とビジネス上のニーズの折り合いをつけるのに苦労しています。この業界で変化のときを迎えている Google が提供している Dataproc プラットフォームでは、お客様のデータとお客様がすでに使用している OSS システムを管理、分析し、最大限に活用できます。
Dataproc のルーツは 2010 年の Apache Hadoop のオンプレミス デプロイメントにありますが、この時点では改善点が多く、ビッグデータ アーキテクトが個別にスケールできない、柔軟性に欠けるマシンで作業する必要があり、チューニングとテストに手間がかかりました。ビッグデータ アーキテクトには、将来のデータ量の急増または次の OSS のリリースによってパイプラインまたはクエリが使用できなくなるのかどうか判断がつきませんでした。その後クラウドが登場し、こういった問題の多くが解決されました。2015 年に Google Cloud の Dataproc が発表されたことで、企業がコンピューティングをストレージから切り離し、カスタムマシンを使用してカスタム OSS クラスタを構築できるようになりました。クラスタの構築とスケーリングを自動化することで、オンプレミスで発生する一般的な問題を回避し、OSS における次の大転換、すなわちサーバーレスに向けてお客様の準備を整えることができました。
サーバーレスの未来を予測する前に、まずはこの業界がどういう形で誕生したか、現在はどうなっているのかを考察してみましょう。
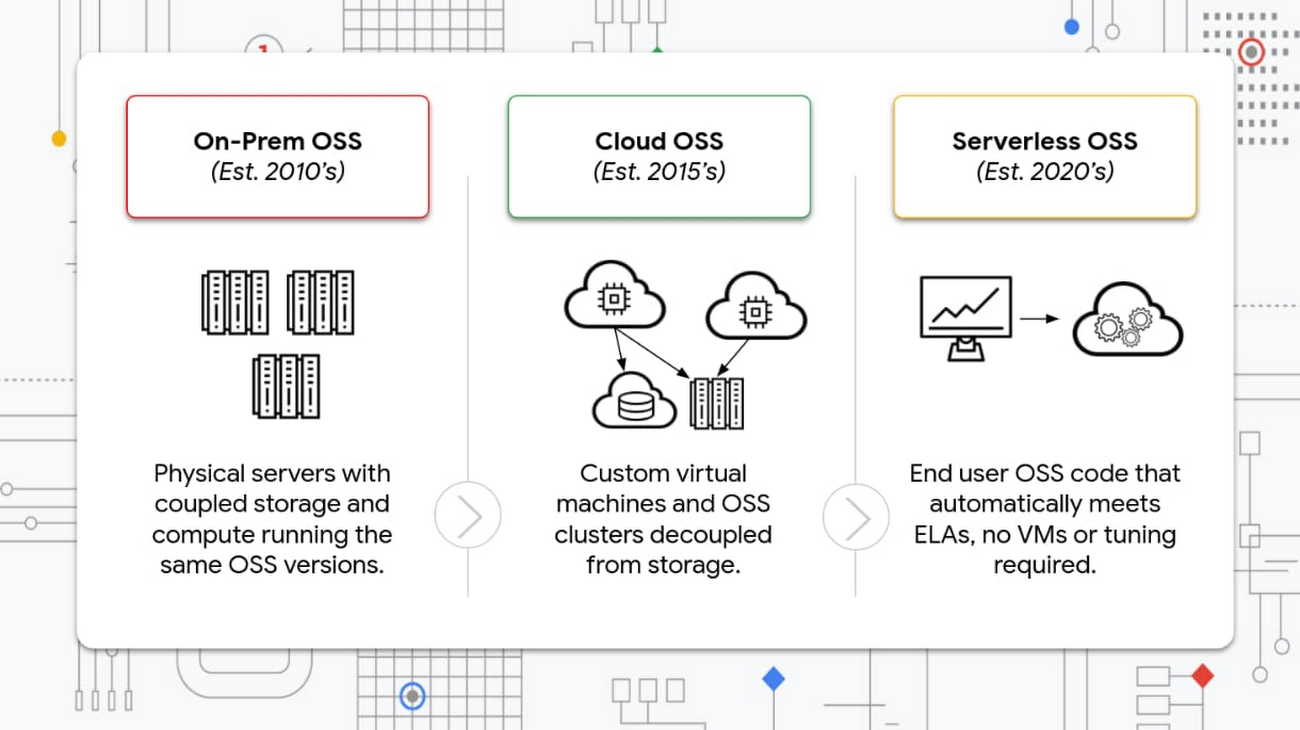
オンプレミス OSS: Google によるサービス開発と課題
ビッグデータ用オープンソース ソフトウェアは、データセンター内のクラスタのハードウェアのセットアップを簡略化し、ハードウェア障害がデータ アプリケーションに与える影響を最小限に抑えることを目的として開発されました。また、ビッグデータ用 OSS は、オープンソース コミュニティ全体のイノベーションも活用しながら、管理を簡素化し、利用可能なすべてのリソースを効率良く活用することで、費用の最適化を実現しています。デベロッパーがデータセンターを再構成することなく、適当だと考える方法で基盤となるハードウェアを自由に活用することを禁止してしまわないよう、上記の戦略は慎重に採用する必要があります。
データを処理に持ち込むという従来の手法ではなく、初期のビッグデータ分析では、処理をデータに持ち込むことで処理の概念が変わりました。その他の設計面の簡素化により、データセンター チームは、Linux を実行するコモディティ サーバーの相互接続ラックのセットアップに集中することができました。これらのラックを引き渡されたビッグデータ デベロッパーは、データ アプリケーションの処理環境を構成して最適化できるようになりました。主要なビッグデータ用オープンソース コンポーネントである Hadoop は、分散ファイル システムと処理フレームワーク(MapReduce)を実装しており、データ アプリケーションの実行を簡素化して、あらゆるハードウェア障害にも適切に対処できます。
これにより、少人数のデータセンター エンジニアのチームで数千台のマシンを管理できるようになりました。
処理とデータが分離された一方で、アプリケーション デベロッパーは、データの近接性に特に注意を払いました。それでも、データ処理アプリケーションに必要な I/O 帯域幅を確保できるかは、なおも物理サーバーの設置場所にかかっていました。その結果、これらの処理環境を構成するには、処理環境の配置がどのようになっているか(物理サーバー構成、ラック内およびラック間のストレージの接続とネットワーク リンク)を詳細に理解する必要がありました。また、デベロッパーは、メモリーの空き容量、I/O 特性、ストレージ、コンピューティングなど、基盤となる物理環境を最大限に活用できるようソフトウェアを設計しました。
しかしながら、これらの環境には独自の課題がありました。
オンプレミス OSS の課題
設備投資とリードタイム: オンプレミスのインフラストラクチャを構築するには、先行投資と長い時間がかかります。データセンターの構築には数年かかり、電源や冷却能力の更新には半年以上、新しいサーバーの設置には構成だけで数か月もかかります。こうした拡大にはすべて、ほとんどのデータ開発者にはこなせない大規模な計画と実行が必要です。
あらゆるニーズに応えるためのハードウェア構成の選択: ハードウェア構成を確定させるためには、さまざまなワークロードに対応した複数のマシン構成で慎重に検証する必要があります。オープンソース ソフトウェアの大部分は標準化されており、新しいビジネスニーズに対応するためにハードウェア構成を変更すると、混乱を招きます。新しい技術を活用するためにハードウェアを更新するときは、ユーザーのエコシステムへの混乱を最小限に抑えるため、慎重に計画を立てる必要もあります。
データセンターの制約管理: データセンターの設計時には、利用率を最大限高めるために、電力、冷却、物理的なスペースの最適化が求められます。
移行: ネットワークを介してデータを移行するための費用が決して小さくないため、データセンターの移転は困難な作業です。データやアプリケーションの移行に余計な費用と労力が掛からないよう、ユーザーはトラック上のハードウェアを手作業で移すこともありました。
災害復旧計画: 多くのデータセンターでは、障害からの復旧を果たしながらネットワークの遅延を最小限に抑えるために十分なネットワーク帯域幅が必要となるため、災害復旧計画が重要となります。もちろん実際に災害が起こる前に、データの引継ぎ方法の設計と検証を行う必要があります。
クラウドベース OSS
仮想化技術の革新により、利用可能な I/O 帯域幅、仮想化ペナルティ、ストレージのパフォーマンスなど、オンプレミス環境の設計上の制約がいくつか解消されました。クラウド コンピューティングのおかげで、ストレージとコンピューティング処理能力をすぐに利用でき、データ デベロッパーはオンデマンドでのスケーリングを行えるようにもなりました。クラウド コンピューティングを導入すると、データ デベロッパーは、処理ニーズに合わせてカスタム環境を選択し、データ アプリケーションにより注力でき、基盤となるインフラストラクチャに対しては従来ほど気を配る必要がなくなります。これらすべての機能を備えていることから、クラウドベースのデータ分析環境の人気が急上昇しています。デベロッパーは、今では上位のアプリケーション構成に注力でき、クラウドがもたらすこれらの新しいコストメリットを生かせるよう、ソフトウェアを設計できます。
クラウドベース OSS の課題
インフラストラクチャの構成: クラウド インフラストラクチャをサービスとして提供することで、データセンターのロジスティクス計画は不要になったものの、クラスタ構成の複雑な作業が依然として課題となっています。ユーザーは、データ処理環境の構成時に、クラウド インフラストラクチャの具体的な課題と制約事項を理解しておく必要があります。
処理環境の構成: クラウドを利用することで、複雑な処理環境を簡単に構成できます。クラウド ユーザーは、処理環境を最適化するには、データやワークロードの特性を詳細に理解する必要があると今も認識しています。データ構成、ストレージ形式、ロケーションの変更など、データまたは処理アルゴリズムを変更すると、環境に影響が及ぶことがあります。
費用の最適化: 実行環境の総費用を最小限に抑えるための構成を行うには、データとワークロードの継続的なモニタリングと管理が必要です。
レイテンシの最適化: ワークロードが時間の経過とともに増大するにつれ、SLO を管理する必要性が高まり、常にモニタリングと微調整を行う必要があります。極端な場合には、SLO を維持するためにストレージ形式または処理パラダイムの再設計が必要となります。
今日の OSS クラウドの課題の改善し、サーバーレスな未来を拓く Dataproc
Dataproc は、Apache Spark クラスタ、Apache Presto クラスタ、Apache Hadoop クラスタなどのマネージド オープンソースを簡単かつコスト効率よく実行できるようにする、使いやすいフルマネージド クラウド サービスです。現在、数多くの企業がビッグデータのワークロードをクラウドに移行し、秒単位の料金設定、アイドル状態のクラスタの削除、自動スケーリングなどにより、コスト面で成果を上げていると伺っています。Dataproc は最近、公開型分析環境の管理を簡素化するために、以下のプレビュー機能を発表しました。
個人用クラスタ認証: クラスタ上のインタラクティブなワークロードをエンドユーザー ID として安全に実行できるようになります。Cloud IAM Notebook ユーザーとして、ワークロードがデータアクセスを実行します。これにより、ID によるアクセス制御やロギングを改善することで、管理者はユーザー アクセス管理を簡素化しながら、管理者の環境のセキュリティを効果的に管理できるようになります。
フレックス モード: Dataproc は、プリエンプティブル VM(PVM)と、予算を賢く使用できるよう必要に応じてクラスタのサイズを調整できる自動スケーリングをサポートしています。フレックス モード機能により、ジョブの失敗を減らしながら、クラスタ運用費用をさらに最適化することができます。フレックス モードを利用すると、一次ワーカーノード上のすべての中間 Spark データを保存でき、積極的な自動スケーリング ポリシーを設定したり、二次ノードにプリエンプティブル VM を活用したりできます。中間シャッフル データは「ワーカー」(MapReduce ではマッパー、Spark ではエグゼキュータ)の外に保存されるため、ジョブ中にワーカーマシンが削除(またはプリエンプション)された後のスケールダウン イベント中にジョブの進行状況が失われることはありません。
永続的な履歴サーバー: クラスタがオフラインの場合でも、ジョブログやクラスタ構成を表示できるようになりました。クラスタがオフラインの場合、エフェメラル クラスタが現在動作していないか、クラスタが削除されていると考えられます。クラウド ストレージにジョブログを保持するようクラスタを構成してから、一連のクラウド ストレージのロケーションからログを表示するよう永続的な履歴サーバーを構成する必要があります。1 台の永続的履歴サーバーを構成して、複数のクラスタからログを集約し、ワークフローとデータ アプリケーションの管理とデバッグを簡略化できます。
Dataproc では、新しい OSS の迅速なテスト、コードの考案、パイプラインとモデルのデプロイが可能なため、企業がより構築に集中し、保守にかける負担が軽くなるようプロセスを自動化することができます。Dataproc が継続的に OSS のテストと開発を強化し、開発サイクルをデプロイおよび自動化する中で、Google は、サーバーレスな未来に備えられるよう、インテリジェントなサービスを今後も開発していきます。
次の段階: サーバーレス OSS
お客様が利用できる選択肢の多さに起因するデータ分析プラットフォーム(処理とストレージ)のチューニングや構成の複雑さゆえに、使用率が高まり、ユースケースが増えるにつれて、データ アプリケーションの利用期間において理想的なプラットフォームを選択することがますます難しくなっています。サーバーレス OSS がこれを変えてくれます。
将来、サーバーレスのコンセプトにより、複雑さや課題を解消することに焦点を当てられ、基盤となるプラットフォームが適切に動作する間に、サービス品質(QoS)により注力できるようになります。これは困難なことに聞こえるかもしれませんが、複数の段階により実現可能です。QoS の確保に取り組むとき、主に次の 3 つの要素を選択できます。
クラスタ: 目的の QoS 実現のためにワークロードを実行する場合の適切なクラスタの選択。
インターフェース: ワークロードに適したインターフェースの選択(Hive、SparkSQL、Presto、Flink など)。
データ: ロケーション、形式、データ構成の選択。
サーバーレスが実現すれば、インフラストラクチャではなくワークロードに意識を集中できます。費用やパフォーマンスなど、お客様にとって重要な指標を中心に最適化するためのクラスタとジョブの自動構成と管理を Google が行います。
サーバーレスは、Google Cloud にとって目新しいものではありません。長年サーバーレス機能を開発しており、初のサーバーレス データ ウェアハウスである BigQuery もすでに発表しています。OSS の時代が到来しました。このビッグデータ OSS の次の段階では、お客様が製品化までの時間を短縮、レイテンシと費用の最適化を自動化して、アプリケーション開発サイクルへの投資を削減することで、構築により注力、保守にかかる負担を軽減できます。Dataproc をお試しいただき、ご意見をお寄せください。サーバーレス時代の OSS の開発に役立ててまいります。
-データ分析担当プロダクト マネージャー Susheel Kaushik



